通过yolov5训练自己的模型中遇到的一些问题及解决办法
引言
众所周知,跑深度学习的模型是非常需要好显卡的,虽然我的电脑拥有菜菜的显卡(GeForce 920MX),但也能跑起来。最近尝试着用YOLOV5做小项目,因为我菜菜的显卡,容量是真的不够,期间踩了很多坑,现在分享给大家,希望你遇到的时候可以快速解决问题!
问题一:AssertionError: train: No labels in D:\PycharmProjects\yolov5-master\train\image.cache. Can not train without labels.
解决办法:
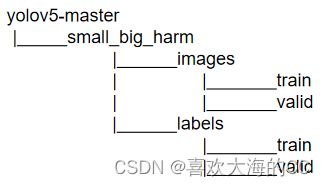
去github源地址,找到自制数据集应该具备的文件目录层级,然后按照这个层级去布置图像文件、标签文件的位置,最后运行的时候程序就能找到图像对应的标签了。比如我修改成这样:
问题二:ImportError: DLL load failed: 页面文件太小,无法完成操作;OSError: [WinError 1455] 页面文件太小,无法完成操作;BrokenPipeError: [Errno 32] Broken pipe;
报错提示:
File “D:\PycharmProjects\yolov5-master\utils\datasets.py”, line 153.
解决办法:
windows下多线程的问题,和pytorch中的DataLoader类有关。找到datasets.py,找到对应函数时的 num_workers 参数设置,把num_workers参数设置改成0。如下图所示:


修改完还是在报“页面文件太小”的错误!
问题三:OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading “D:\Anaconda3\envs\yolov5\lib\site-packages\torch\lib\cudnn_adv_infer64_8.dll” or one of its dependencies.
参考:https://blog.csdn.net/weixin_43959833/article/details/116669523
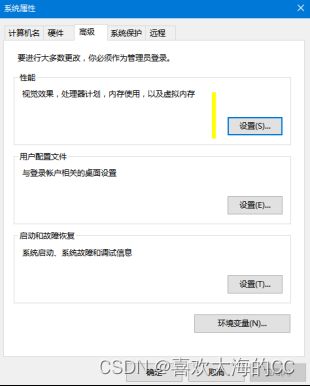
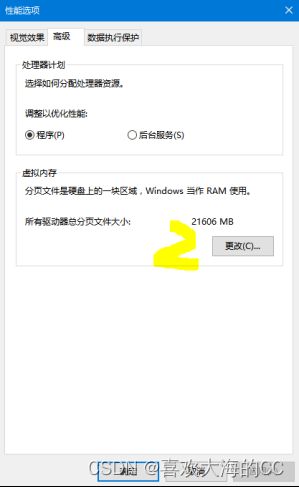
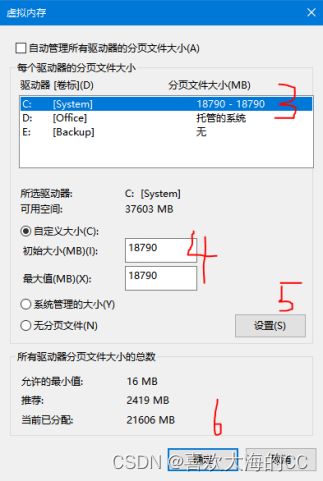
解决办法:修改虚拟内存大小
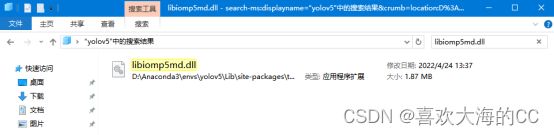
问题四:OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous…
参考:https://blog.csdn.net/weixin_45800887/article/details/123603977
找到你anaconda的安装地址然后找到envs,找到你所用的环境,然后搜索libiomp5md.dll,关键问题在于anaconda的环境下存在两个libiomp5md.dll文件

解决办法:
仔细观察,一个在Lib\site-packages\torch\lib下,另一个在Library\bin下,第一个是torch下的,留下这个,第二个是conda的,新建文件夹将它剪切到这个文件夹,暂存一下。(暂存路径:D:\conda_libiomp5md\libiomp5md.dll)
最后确认一下,只有一个libiomp5md.dll即可。
问题五:RuntimeError: CUDA out of memory. Tried to allocate 14.00 MiB (GPU 0; 2.00 GiB total capacity; 1.21 GiB already allocated; 1.68 MiB free; 1.24 GiB reserved in total by PyTorch)
参考:https://www.jb51.net/article/242140.htm
解决办法:问题在于显卡内存不够,所以尝试将batch-size减小,修改为4(我的电脑配置,设置成8,也会报错),就可以解决此问题。
问题六:RuntimeError: All input tensors must be on the same device. Received cpu and cuda:0
是耗费我最多时间才得以解决的问题,一定要好好记录!
报错提示:stats = [torch.cat(x, 0).cpu().detach().numpy() for x in zip(*stats)] # to numpy
我的误解:根据报错提示进行思考,是因为Numpy是CPU-only的(在CUDA下训练中的数据不能直接转化为numpy),所以在我们先把GPU tensor张量转换成Numpy数组的时候,需要把GPU tensor转换到CPU tensor去,才导致tensor一会在GPU上跑,一会在CPU上跑。于是我尝试了三种方案:
方案一:numpy数组转化为GPU tensor
stats = [torch.from_numpy(torch.cat(x, 0).cpu().detach().numpy()).cuda() for x in zip(*stats)]

运行之后发现还是报原来的错,仍然是在cpu和gpu两个设备上跑。
.to(device) 可以指定CPU或GPU;.cuda()只能指定GPU
方案二:尝试寻找一种方法,将GPU tensor转换为Numpy变量时,仍在GPU上跑,不用转换到CPU上去。
Cupy是一个通过利用CUDA GPU库在Nvidia GPU上实现Numpy数组的库
下载安装Cupy库,参考:https://wenku.baidu.com/view/ff9563f175eeaeaad1f34693daef5ef7ba0d12db.html

方案三:当把GPU tensor转换为CPU tensor此步骤去掉后,我发现还是会报原来的错误。所以推断应该不是torch.cat(x, 0).cpu().numpy()的问题。
stats = [torch.cat(x, 0) for x in zip(*stats)]
我的猜测:stats问题?
根据报错提示,出错语句在stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)],其中唯一的数据来源就是stats列表,stats列表结构如下:
①stats列表中包含很多个元组类型数据;
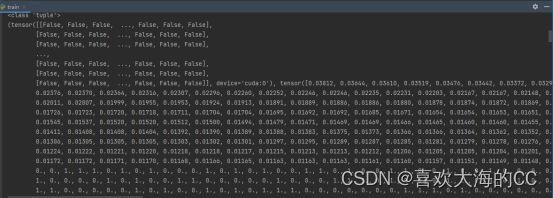
②每个元组中包含几个tensor张量;
用tensor.is_cuda判断其中每个tensor是否在GPU上




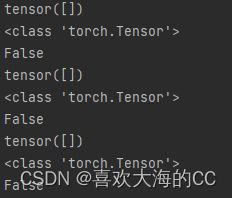
终于,发现问题所在,其中有几个tensor(tensor([]))是在CPU上,且通过判断这些tensor都不为空
解决办法:将在CPU上的tensor都转移到GPU上
写了一段代码,保证能够将CPU上的tensor转移到GPU上,代码如下:
# 把在CPU上的tensor转移到GPU上,使用range在for循环中修改list值
for i in range(len(stats)):
stats[i] = list(stats[i]) # 修改元组中的元素:遵循”元组不可变,列表可变“,因此将元组转化为列表再进行修改
for j in range(len(stats[i])):
if stats[i][j].is_cuda == False:
stats[i][j] = stats[i][j].cuda()
# print(stats[i][j].is_cuda)
stats[i] = tuple(stats[i])
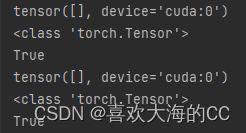
验证:成功将CPU上的tensor转移到GPU上
问题七:windows上无法下载pycocotools包?
解决办法:
从Anaconda Prompt进入yolov5环境下输入命令
pip install pycocotools-windows
以上就是我遇到的所有问题,终于可成功通过YOLOV5训练自己的模型。
致谢
常年游走在互联网寻求问题的解决办法,每遇到一篇文章,遇见一个博主,就多了一次尝试的机会,感谢问题,让我看见你的文章,让你们看见我的文章,一起成长吧!