浅谈目标检测RCNN,SPPNET,Fast-RCNN,Faster-RCNN
RCNN
目标检测-R-CNN模型
●CVPR 2014
●候选区域方法(region proposal method) :提供了额物体检测的一个重要思路
●RCNN步骤:
。1、对于一张图片,找出默认2000个候选区域
。2、2000个候选区域做大小变换(crop+warp),输入AlexNet当中, 得到特征向量:[2000, 4096]
。3、经过20个类别的SVM分类器,对于2000个候选区域做判断,得到[2000, 20]得分矩阵
。4、2000个候选区域做非极大抑制(NMS),去除不好的,重叠度高的一些候选区域,得到剩下分数高,结果好的框
。5、修正候选框,bbox的回归微调
候选区域(Region of Interest (ROI) )得出(了解)
。SelectiveSearch在一 张图片上提取出来约2000个侯选区域
。由于长宽不定,不能直接输入alexNet
。2000个候选区域做大小变换(crop+warp)
特征向量训练分类器SVM
。R-CNN选用SVM进行二分类。假设检测20个类别,那么会提供20个不同类别的SVM分类器,每个分类器都会对2000个候选区域的特征向量分别判断一次,这样得出[2000, 20]的得分矩阵
。猫分类:对:2000个候选区域做判断,得到2000个属于猫的类别
。狗分类:对2000个候选区域做判断,得到2000个 属于猫的类别
…
。[2000, 20]
非最大抑制NMS)
。目的:筛选候选区域,目标是一个物体只保留一个最优的框,来抑制那些冗余的候选框
。RCNN预测2000个候选框,得到3个(比如有3个ground truth) 比较准确的候选框
。迭代过程;
■1、对于所有的2000个候选区域得分进行概率筛选,0.5
■2000-》5个
■2、剩余的候选框
对于每个候选框找到自己对应GT
■3、第一轮:对于右边车辆,假设B是得分最高的,与B的IoU> 0.5删除。现在与B计算IoU, DE结果>0.5,剔除DE,B作为一个预测结果
第二轮:对于左边车辆,AC中,A的得分最高,与A计算IoU,C的结果>0.5,剔除C,A作为一个结果
■最终结果:理想状态,每一个Ground truth都有一个候选框预测

(图一)
4.3.2.6修正候选区域
。为了让候选框标注更准确率,去修正原来的位置
。A是候选框,G是目标GT框
。让A与G做回归训练,得到四个参数
RCNN输出:一张图片预测一个X候选框,xxw=y_ locate
。y_locate:是真正算法输出的位置
R-CNN测试过程
●辅入一张图像,利用selective search得到2000个region proposal。
●对所有region proposal变换到固定尺寸并作为已训练好的CNN网络的输入,每个候选框得到的4096维特征
●采用已训练好的每个类别的svm分类器对提取到的特征打分,所以SVM的weight matrix是4096N, N是类别数,这里一共有20个SVM,得分矩阵 是200020
●采用non-maximun suppression (NMS) 去掉候选框
●第上一步得到region proposal进行回归。
SPPNET
 (图二)
(图二)
R-CNN的问题解决思路1:速度慢,图片变形
○ SPPNet:一张图片直接全部卷积计算,去除crop+warp
○ 映射:
■ image --> SS -->候选区域
■ image --> CNN -->特征图
■ 将候选区域映射到特征图当中,得出每个候选区域的特征向量
● 公式:左上角的点:x = [x/S]+1 右下角的点:x = [x/S]-1
○ SPP :spatial pyramid pooling
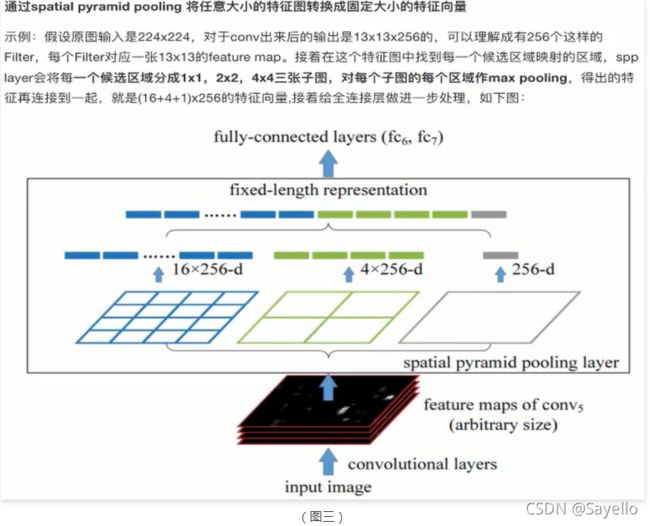 ●优点
●优点
。SPPNet在R-CNN的基础上提出了改进,通过候选区域和feature map的映射,配合SPP层的使用,从而达到了CNN层的共享计算,减少了运算时间、后面的Fast R-CNN等也是受SPPNet的启发
●缺点
。训练依然过慢、效率低,特征需要写入磁盘(因为SVM的存在)
。分阶段训练网络:选取候选区域、训练CNN、训练SVM、训练bbox回归器, SPP-Net在fine-tuning阶段无法使用反向传播微调SPP-Net前面的Conv层
Fast-RCNN
改进的地方:提出一个Rol pooling,然后整合整个模型,把CNN、 SPP变换层、分类器、bbox回归几个模块一起训练
 ●步骤
●步骤
● 首先将整个图片输入到一个基础卷积网络,得到整张图的feature map
● 将region proposal (Rol) 映射到feature map中
● Rol pooling layer提取一个固定长度的特征向量,每个特征会输入到一系列全连接层,得到一个Rol特征向量(此步骤是对每一个候选区域都会进行同样的操作)
○ 其中一个是传统softmax层进行分类,输出类别有K个类别加上”背景”类
○ 另一个是bounding box regressor
ROI是Region of Interest的简写,指的是在“特征图上的框”
RoI pooling
ROIs Pooling顾名思义,是Pooling层的一种,而且是针对RoIs的Pooling,他的特点是输入特征图尺寸不固定,但是输出特征图尺寸固定 ,目的:首先Rol pooling只是一个简单版本的SPP,目的是为了减少计算时间并且得出固定长度的向量。
○ 原来SPP是:金字塔形4 4.22.1 1 改成了:单个块:44,K * M
○ 问题: K和M过小,全连接层要求输出比较大 -> 6*6,但是FC要求7 * 7的输入要求 -> 动态调整,长6/7, 宽: 6/7
○ 相比SPPnet的采取方式
■ 涉及到single scale与multi scale两者的优缺点,muti scale精度确实高一些,但是并没有高很多,相比之下,single scale速度会快很多
■ 速度与精度的权衡,选择了single scaleRol pooling
○ 修改SVM分类为softmax分类,输出N个类别+ 1个背景
○ softamx + roi pooling,进行统一训练
Faster-RCNN
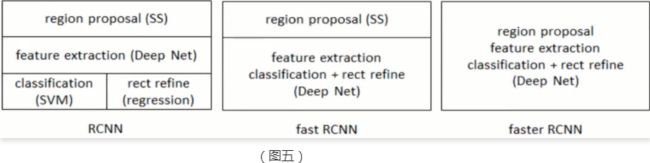 改进Faster RCNN:
改进Faster RCNN:
○ 区域生成网络(RPN) +Fast RCNN网络
○ 步骤:
● 1、输入任意大小图片,经过CNN网络输出特征图,特征图共享于后面两步
● 2、特征图经过RPN生成候选区域
● 3、候选区域与特征图共同输入到Rol pooling,得到每个候选区域的特征图,然后进行softmax分类,bbox回归预测
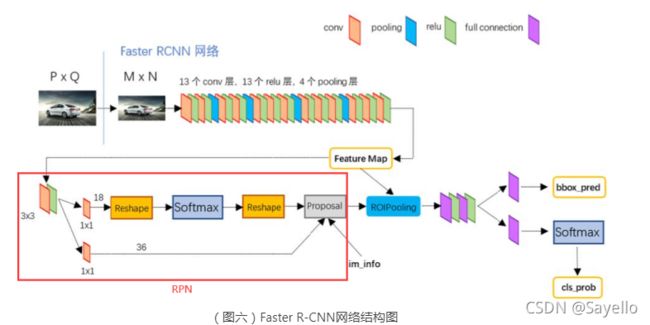 上图展示了RPN网络的具体结构。可以看到RPN网络实际分为2条线,上面一条通过softmax分类anchors获得positive和negative分类,下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。
上图展示了RPN网络的具体结构。可以看到RPN网络实际分为2条线,上面一条通过softmax分类anchors获得positive和negative分类,下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。
其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能
相关名词解释:
原像素空间–>feature map ->经过RPN–>得到proposals
■ anchor: Anchor是大小和纵横比固定的候选框
● 9种anchor:对应着3种大小(128,256,512)和3种纵横比(0.5,1,2)。如上图所示,蓝色对应128,红色对应256,绿色对应512。此时anchor的宽和高的数量级是针对于原始image的
● anchor数量:Extractor输出的feature中,每个pixel上有9个anchor,因此共有(H/16)× (W/16)×9个anchor。对于1个形状为(512,62,37)的feature,有62×37×9大概20000个anchor。
● 作用:multi-scale anchor的设计是共享特征而无需为处理multi-scale增加额外成本的关键
● 生成:首先根据预定义的scale和aspect ratio将scale*aspect ratio = k(default =9) 个anchor定义为相对于当前pixel(以该pixel为anchor的中心)的ymin, xmin, ymax, xmax,注意此时anchor的宽和高的数量级是针对于原始image的;然后计算(乘以相应比例)出Extractor输出的feature map中每个pixel对应的原始image中的位置,与anchor相加,即得到anchor在原始image中的ymin, xmin, ymax, xmax。
■ proposals: (符合条件的anchor称为proposal)
● 当anchor生成以后就要生成最终的Proposal了。首先对anchor有两部分的操作:分类和边框回归。
● 分类是上图中上面的分支,通过softmax进行二分类,将anchor分为前景和背景,分别对应positive和negative。
● 边框回归获取anchor针对ground truth的偏移。得到这两个信息后开始选取符合条件的anchor作为Proposal。
● 主要分为以下几步:
○ 第一步:先将前景的anchor按照softmax得到的score进行排序,然后取前N个positive anchor;
○ 第二步:利用im_info((图六)中保存的信息,将选出的anchor由MxN的尺度还原回PxQ的尺度,刨除超出边界的anchor,M N P Q参考图六;
○ 第三步:执行NMS(nonmaximum suppression,非极大值抑制);
○ 第四步:将NMS的结果再次按照softmax的score进行排序,取N个anchor作为最终的Proposal;
● 至此Proposal的生成就结束了,需要注意的是最后的Proposal是这对应MxN的尺度。
RPN原理
RPN网络的主要作用是得出比较准确的候选区域。整个过程分为两步
○ 用nxn(默认3x3=9)的大小窗 口去扫描特征图,每个滑窗位置映射到一个低维的向量(默认256维), 并为每个滑窗位置考虑k种(在论文设计中k=9)可能的参考窗口(论文中称为anchors)
○ 低维特征向量输入两个并行连接的1 x 1卷积层然后得出两个部分: reg窗口回归层(用于修正位置)和cls窗口分类层(是否为前景或背景概率)
其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的positive anchor,哪些是没目标的negative anchor。所以,仅仅是个二分类而已!
RPN网络结构总结起来就是:生成anchors -> softmax分类器提取positvie anchors -> bbox reg回归positive anchors -> Proposal Layer生成proposals
- Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks(RPN)。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
Conv layers
Conv layers包含了conv,pooling,relu三种层。以python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构为例,Conv layers部分共有13个conv层,13个relu层,4个pooling层。
在Conv layers中:(导致Conv layers中的conv层不改变输入和输出矩阵大小)
- 所有的conv层都是:kernel_size=3,pad=1,stride=1
- 所有的pooling层都是:kernel_size=2,pad=0,stride=2
Conv layers中的pooling层kernel_size=2,stride=2。这样每个经过pooling层的MxN矩阵,都会变为(M/2)x(N/2)大小。综上所述,在整个Conv layers中,conv和relu层不改变输入输出大小,只有pooling层使输出长宽都变为输入的1/2。
那么,一个MxN大小的矩阵经过Conv layers固定变为(M/16)x(N/16)!这样Conv layers生成的feature map中都可以和原图对应起来。
对多通道图像做1x1卷积,其实就是将输入图像于每个通道乘以卷积系数后加在一起,即相当于把原图像中本来各个独立的通道“联通”在了一起(多通道融合)
YOLO
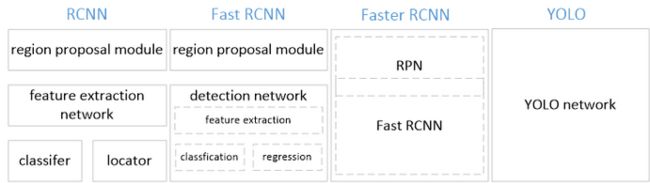
YOLO检测网络包括24个卷积层和2个全连接层,如下图所示。
 其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
YOLO将输入图像分成SxS个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。如下图所示,图中物体狗的中心点(红色原点)落入第5行、第2列的格子内,所以这个格子负责预测图像中的物体狗
 每个格子输出B个bounding box(包含物体的矩形区域)信息,以及C个物体属于某种类别的概率信息。
每个格子输出B个bounding box(包含物体的矩形区域)信息,以及C个物体属于某种类别的概率信息。
Bounding box信息包含5个数据值,分别是x,y,w,h,和confidence。
其中x,y是指当前格子预测得到的物体的bounding box的中心位置的坐标。
w,h是bounding box的宽度和高度。注意:实际训练过程中,w和h的值使用图像的宽度和高度进行归一化到[0,1]区间内;
x,y是bounding box中心位置相对于当前格子位置的偏移值,并且被归一化到[0,1]。
confidence反映当前bounding box是否包含物体以及物体位置的准确性
confidence计算方式如下:
confidence = P(object)* IOU, 其中,若bounding box包含物体,则P(object) = 1;否则P(object) = 0.
IOU(intersection over union)为预测bounding box与物体真实区域的交集面积/并集面积(以像素为单位,用真实区域的像素面积归一化到[0,1]区间)。
因此,YOLO网络最终的全连接层的输出维度是 SS(B5 + C)。
YOLO论文中,作者训练采用的输入图像分辨率是448x448,S=7,B=2;采用VOC 20类标注物体作为训练数据,C=20。因此输出向量为77*(20 + 2*5)=1470维。
作者开源出的YOLO代码中,全连接层输出特征向量各维度对应内容如下:

*由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。
*虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。(这也是为什么上图是7x7x20个物体类别概率值)