浅谈人脸检测MTCNN以及Pytorch代码
MTCNN网络架构分析
P-net
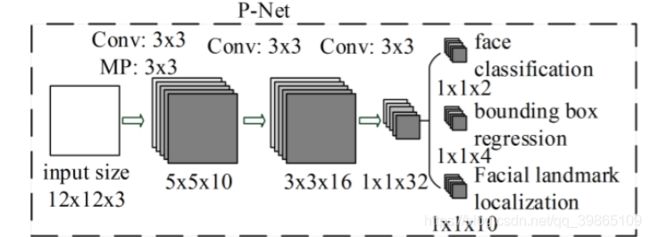
从总体看,网络是全卷积结构,优点是可以输入任意大小的的图片(针对侦测的时候)。训练的时候输入尺寸是12*12,然后经过3*3的卷积核和池化到1*1*32的过程中都是通道增加的,也就是特征融合的过程。最后分3个类别做输出一个是置信度、一个是边框的偏移量,另一个是十个关键点的位置。
R-net
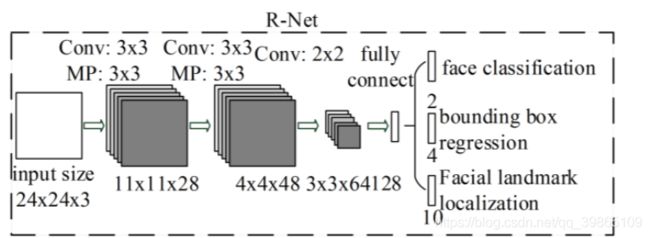
首先R-net是卷积+全链接结构,代表着输入图片大小固定只能是24*24。然后经过卷积池化到特征图3*3*64同样为特征融合过程,最后reshape经过全链接得到结果同样分成三个类,一个是置信度、一个是边框的偏移量,另一个是十个关键点的位置。
O-net

O-net架构大致和R-net差不多,只是输入图片大小为48*48,中间多加了一层卷积结构。
3种网络综合起来看,输入图片分别是12*12,24*24,48*48。图片信息由少到多,有粗糙到精细,体现了级联的思想,P-net全卷积结构,意味着可以侦测任意大小的图片,P-net从12*12到1*1,相当于用12 *12的卷积核在原图(侦测时的输入图片)上滑动,代表着以12*12的先验框为以步长为2在原图上框人脸。所以此网络能侦测到的最小人脸大小为12*12。特别注意的是P-net的训练阶段是用12*12的样本进行训练,侦测的时候用任意大小的图片去侦测。R-net和O-net大致差不多,训练和侦测都是24*24和48*48。
网络架构的代码
import torch.nn as nn
import torch
class PNet(nn.Module):
def __init__(self):
super().__init__()
# 卷积层
self.pre_Conv2d = nn.Sequential(
nn.Conv2d(3, 10, 3, 1),
nn.PReLU(),
nn.MaxPool2d(3, 2, padding=1),
nn.Conv2d(10, 16, 3, 1),
nn.PReLU(),
nn.Conv2d(16, 32, 3),
nn.PReLU()
)
# 置信度1个通道
self.face = nn.Sequential(
nn.Conv2d(32, 1, 1), # 1*1
nn.Sigmoid()
)
# 偏移量4个通道
self.box = nn.Conv2d(32, 4, 1) # 1*1
# 5个关键点
self.landmark = nn.Conv2d(32, 10, 1) # 1*1
def forward(self, *input):
pre_output = self.pre_Conv2d(*input)
# 置信度1个通道
cond = self.face(pre_output)
# 偏移量4个通道
offset = self.box(pre_output)
# 5个关键点
landmark = self.landmark(pre_output)
return cond, offset, landmark
class RNet(nn.Module):
def __init__(self):
super().__init__()
# 卷积层
self.pre_Conv2d = nn.Sequential(
nn.Conv2d(3, 28, 3),
nn.PReLU(),
nn.MaxPool2d(3, 2, padding=1),
nn.Conv2d(28, 48, 3),
nn.PReLU(),
nn.MaxPool2d(3, 2),
nn.Conv2d(48, 64, 2),
nn.PReLU()
)
# 线性层
self.pre_Linear = nn.Sequential(
nn.Linear(3 * 3 * 64, 128),
nn.PReLU()
)
# 置信度
self.face = nn.Sequential(
nn.Linear(128, 1),
nn.Sigmoid()
)
# 偏移量
self.box = nn.Linear(128, 4)
# 5个关键点
self.landmark = nn.Linear(128, 10)
def forward(self, x):
pre_Conv2d_output = self.pre_Conv2d(x)
pre_Linear_input = pre_Conv2d_output.reshape(-1, 3 * 3 * 64)
pre_Linear_output = self.pre_Linear(pre_Linear_input)
# 置信度
cond = self.face(pre_Linear_output)
# 偏移量
offset = self.box(pre_Linear_output)
# 5关键点
landmark = self.landmark(pre_Linear_output)
return cond, offset, landmark
class ONet(nn.Module):
def __init__(self):
super().__init__()
# 卷积层
self.pre_Conv2d = nn.Sequential(
nn.Conv2d(3, 32, 3),
nn.PReLU(),
nn.MaxPool2d(3, 2, padding=1),
nn.Conv2d(32, 64, 3),
nn.PReLU(),
nn.MaxPool2d(3, 2),
nn.Conv2d(64, 64, 3),
nn.PReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 2),
nn.PReLU()
)
# 线性层
self.pre_Linear = nn.Sequential(
nn.Linear(3 * 3 * 128, 256),
nn.PReLU()
)
# 置信度
self.face = nn.Sequential(
nn.Linear(256, 1),
nn.Sigmoid()
)
# 偏移量
self.box = nn.Linear(256, 4)
# 5个关键点
self.landmark = nn.Linear(256, 10)
def forward(self, *input):
pre_Conv2d_output = self.pre_Conv2d(*input)
pre_Linear_input = pre_Conv2d_output.reshape(-1, 3 * 3 * 128)
pre_Linear_output = self.pre_Linear(pre_Linear_input)
# 置信度
cond = self.face(pre_Linear_output)
# 偏移量
offset = self.box(pre_Linear_output)
# 5个关键点
landmark = self.landmark(pre_Linear_output)
return cond, offset, landmark
if __name__ == '__main__':
net1 = PNet()
net2 = RNet()
net3 = ONet()
a = torch.randn(2, 3, 12, 12)
b = torch.randn(2, 3, 24, 24)
c = torch.randn(2, 3, 48, 48)
print(net1(a)[0].shape)
print(net2(b)[1].shape)
print(net3(c)[2].shape)
样本制作
问题
从上面网络输入结果来看,输入的有置信度用来判断是不是人脸,边框回归,关键点的位置关系。当神经网络拟合得很好的时时候,神经网络输出的结果是收敛于
收敛于样本标签的结果。那么置信度、边框回归、关键点的位置关系怎么在样本中表现呢?
置信度
通常在边框回归的时候我们都需要先验信息,这个先验信息就是先验框。同时我们用先验框和人工标注框的交并比(IOU)来衡量这个先验框是不是人脸的概率值,也就是置信度。
边框回归和关键点回归
由于一张图中有几个大小不同人脸的情况下大框和小框对损失的要求不同,我们不能直接回归原图框的坐标,而是应该回归先验框和标注框的位置关系。同理关键点也是回归的是位置关系。
先验框的制作
置信度、边框回归、关键点回归都与先验框有关。先验框的制作就至关重要。首先我们有标注的样本,知道了样本框的中心点和宽高。我们把样本的中心点进行移动,样本的宽高进行移动,以IOU为衡量标准,把移动后的框与标注的框做IOU,论文中把IOU>0.65的叫做正样本,置信度为1,把IOU0.45到0.65的叫做部分样本,给个标注值为2,小于0.3的叫做负样本,置信度为0。分别把移动后的框裁剪下来,缩放成12*12,24*24, 48*48的图片。把对应的置信度和偏移量保存,作为样本。这是我们就有了3种尺寸的图片对应的正样本,负样本,部分样本。
制作代码(以负样本为例(这里IOU<0.1为负样本))
import os
import torch
from PIL import Image
from Tool import utils
import random
"""
存放路径:sample/size/negative,sample/size/negative.txt
"""
# 新建文件夹
imgDir_path = r"D:\project and study\pythonstudy\MTCNN_Projrct shuibing\data\img"
imgLabel_path = r"D:\project and study\pythonstudy\MTCNN_Projrct shuibing\data\lable.txt"
sampleDir_path = r"data"
for size in [48, 24, 12]:
negativeDir_path = os.path.join(sampleDir_path, str(size), "negative")
if not os.path.exists(negativeDir_path):
os.makedirs(negativeDir_path)
# print(negativeDir_path)
# exit()
# 新建txt
negativeLabel = open(os.path.join(sampleDir_path, str(size), "negative.txt"), "w")
negative_count = 0
# 读取imgLabel,img
for i, line in enumerate(open(imgLabel_path)):
if i < 2:
continue
strs = line.strip().split()
# 获取图片
strs = strs[0].split(',')
print(strs)
img_path = os.path.join(imgDir_path, strs[0]+'.jpg')
if not os.path.exists(img_path):
continue
img = Image.open(img_path)
img_w, img_h = img.size
# print(img_h,img_w)
# 获取实际框和关键点
x1 = float(strs[1])
y1 = float(strs[2])
w = float(strs[3])
h = float(strs[4])
x2 = x1 + w
y2 = y1 + h
# 十个关键点
# px1 = float(strs[5])
# py1 = float(strs[6])
# px2 = float(strs[7])
# py2 = float(strs[8])
# px3 = float(strs[9])
# py3 = float(strs[10])
# px4 = float(strs[11])
# py4 = float(strs[12])
# px5 = float(strs[13])
# py5 = float(strs[14])
# 检查图片是否过小,数据是否合格
if w < 40 or h < 40 or x1 < 0 or x1 > img_w or x2 > img_w or y1 < 0 or y1 > img_h or y2 > img_h:
continue
# 实际框,用作iou的boxes参数
real_box = torch.Tensor([[x1, y1, x2, y2]])
# 中心点
cx = x1 + w / 2
cy = y1 + h / 2
# 造10张负样本
count = 0
while count < 10:
# 限定样本框边长
side_len = random.uniform(min(w, h) * 0.5, max(w, h) * 1)
# 样本框左上角(中心点-边长)
# sample_x1
sample_x1 = cx - side_len / 2
# 偏移
offset_w = random.uniform(-2 * w, 2 * w)
sample_x1 = utils.clamp(sample_x1 + offset_w, min=0, max=img_w - side_len)
# sample_y1
sample_y1 = cy - side_len / 2
# 偏移
offset_h = random.uniform(-2 * h, 2 * h)
sample_y1 = utils.clamp(sample_y1 + offset_h, min=0, max=img_w - side_len)
# sample_x2,sample_y2
sample_x2 = sample_x1 + side_len
sample_y2 = sample_y1 + side_len
# 样本框,作iou的box参数
sample_box = torch.Tensor([sample_x1, sample_y1, sample_x2, sample_y2])
# iou
iou = utils.iou(sample_box, real_box)
if 0.1 > iou:
# 计算偏移量(单位长度的偏移)
offset_x1 = (x1 - sample_x1) / side_len
offset_y1 = (y1 - sample_y1) / side_len
offset_x2 = (x2 - sample_x2) / side_len
offset_y2 = (y2 - sample_y2) / side_len
# 十个关键点的偏移量
# offset_px1 = (px1 - sample_x1) / side_len
# offset_py1 = (py1 - sample_y1) / side_len
# offset_px2 = (px2 - sample_x1) / side_len
# offset_py2 = (py2 - sample_y1) / side_len
# offset_px3 = (px3 - sample_x1) / side_len
# offset_py3 = (py3 - sample_y1) / side_len
# offset_px4 = (px4 - sample_x1) / side_len
# offset_py4 = (py4 - sample_y1) / side_len
# offset_px5 = (px5 - sample_x1) / side_len
# offset_py5 = (py5 - sample_y1) / side_len
# 扣下样本图,进行缩放
img_sample = img.crop(sample_box.numpy().astype("int"))
img_sample = img_sample.resize((size, size))
# 保存样本图
img_sample.save(os.path.join(negativeDir_path, "
{0}.jpg".format(negative_count)))
# 保存样本图片名、置信度和偏移量
negativeLabel.write(
"negative/{0}.jpg {1} {2} {3} {4} {5}\n"
.format(negative_count, 0, 0, 0, 0, 0))
print(strs[0], negative_count)
count += 1
negative_count += 1
negativeLabel.close()
加载数据集
import torch.utils.data as data
import os
import torch
from PIL import Image
from torchvision import transforms
import numpy as np
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
class dataset(data.Dataset):
def __init__(self, path):
self.path = path
self.dataset = []
self.dataset.extend(open(os.path.join(self.path, "positive.txt")).readlines())
self.dataset.extend(open(os.path.join(self.path, "negative.txt")).readlines())
self.dataset.extend(open(os.path.join(self.path, "part.txt")).readlines())
def __len__(self):
return len(self.dataset)
def __getitem__(self, item):
strs = self.dataset[item].strip().split()
img_name = strs[0]
img = Image.open(os.path.join(self.path, img_name))
img.show()
img_data = transform(img)
cond = torch.from_numpy(np.array([strs[1]]).astype("float32"))
offset = torch.from_numpy(np.array([strs[2], strs[3], strs[4], strs[5]]).astype("float32"))
# landmark = torch.from_numpy(np.array([strs[6], strs[7], strs[8], strs[9], strs[10], strs[11],
# strs[12], strs[13], strs[14], strs[15]]).astype("float32"))
return img_data, cond, offset
if __name__ == '__main__':
path = r"D:\project and study\pythonstudy\MTCNN_Projrct shuibing\MakingSample\data\48"
mydata = dataset(path)
print(mydata[0])
网络训练
训练主要是损失函数,论文中分类用的交叉熵,两个位置回归用的是均方差,分别给以1,0.5的损失权重。下面是代码。
from Dataset import dataset
import torch
import os
import torch.utils.data as data
import torch.nn as nn
import torch.optim as optim
class trainer:
# 网络存放位置:E:\MTCNN_Save\epoches\PNet.pth
"""传参:(net=PNet(),save_dir=r"E:\MTCNN_Save",save_name="PNet.pth",
dataset_path = r"E:\MTCNN_sample\12",conf_loss_coefficient=0.5)
"""
def __init__(self, net, save_dir, save_name, dataset_path, conf_loss_coefficient):
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.save_dir = save_dir
self.save_name = save_name
self.net = net.to(self.device)
# if os.path.exists(save_path):
# self.net = torch.load(save_path).to(self.device)
# else:
# self.net = net.to(self.device)
self.dataset_path = dataset_path
self.batch_size = 512
self.conf_loss_coefficient = conf_loss_coefficient
def train(self):
cond_lossFn = nn.BCELoss()
offset_lossFn = nn.MSELoss()
landmark_lossFn = nn.MSELoss()
optimizer = optim.Adam(self.net.parameters())
face_dataset = dataset(self.dataset_path)
train_data = data.DataLoader(face_dataset, batch_size=self.batch_size,
shuffle=True, num_workers=0)
epoches = 0
while True:
epoches += 1
for i, (img_data, cond, offset, landmark) in enumerate(train_data):
img_data = img_data.to(self.device)
cond = cond.to(self.device)
offset = offset.to(self.device)
landmark = landmark.to(self.device)
# print(cond.shape,offset.shape,landmark.shape)
output_cond, output_offset, output_landmark = self.net(img_data)
output_cond = output_cond.view(-1, 1)
# print(output_cond)
output_offset = output_offset.view(-1, 4)
# print(offset)
output_landmark = output_landmark.view(-1, 10)
# cond< 2的行的索引
index = torch.nonzero(cond < 2)[:, 0]
# 置信度作损失
_cond = cond[index]
_output_cond = output_cond[index]
# print(_cond)
# print(_output_cond)
cond_loss = cond_lossFn(_output_cond, _cond)
# cond>0的行的索引
idx = torch.nonzero(cond > 0)[:, 0]
# 偏移量作损失
output_offset = output_offset[idx]
offset = offset[idx]
offset_loss = offset_lossFn(output_offset, offset)
# 关键点损失
output_landmark = output_landmark[idx]
landmark = landmark[idx]
landmark_loss = landmark_lossFn(output_landmark, landmark)
# 总的损失
loss = self.conf_loss_coefficient * cond_loss + offset_loss +
landmark_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 20 == 0:
print("[epoches{0}]totalloss:{1} cond_loss:{2} offset_loss:{3}
landmark_loss:{4} ".format(epoches, cond_loss + offset_loss,
cond_loss, offset_loss, landmark_loss))
# 网络存放位置:E:\MTCNN_Save\epoches\PNet.pth
# self.save_dir=r"E:\MTCNN_Save"
epoches_dir = os.path.join(self.save_dir, str(epoches))
if not os.path.exists(epoches_dir):
os.makedirs(epoches_dir)
torch.save(self.net, os.path.join(epoches_dir, self.save_name))
print("[epoches:{0} successfully save]".format(epoches))
from Nets import ONet
from Trainer import trainer
if __name__ == '__main__':
net = ONet()
# 网络存放位置:E:\Final_MTCNN\MTCNN_params\ONet.pth
save_dir = r"E:\Final_MTCNN\MTCNN_params"
save_name = "ONet.pth"
conf_loss_coefficient=0.1
# 训练样本路径
dataset_path = r"E:\Final_MTCNN\MTCNN_Sample\48"
#训练
o_train = trainer(net, save_dir, save_name, dataset_path, conf_loss_coefficient)
o_train.train()
net = PNet()
# 网络存放位置:E:\Final_MTCNN\MTCNN_params\epoches\PNet.pth
save_dir = r"E:\Final_MTCNN\MTCNN_params"
save_name = "PNet.pth"
conf_loss_coefficient = 0.1
# 训练样本路径
dataset_path = r"E:\Final_MTCNN\MTCNN_Sample\12"
# 训练
p_train = trainer(net, save_dir, save_name, dataset_path, conf_loss_coefficient)
p_train.train()
net = ONet()
# 网络存放位置:E:\Final_MTCNN\MTCNN_params\ONet.pth
save_dir = r"E:\Final_MTCNN\MTCNN_params"
save_name = "ONet.pth"
conf_loss_coefficient=0.1
# 训练样本路径
dataset_path = r"E:\Final_MTCNN\MTCNN_Sample\48"
#训练
o_train = trainer(net, save_dir, save_name, dataset_path, conf_loss_coefficient)
o_train.train()
三种网络可单独训练。
侦测
简单的说,侦测过程就是数据制作过程的反运算,P-net输出的结果是置信度和偏移量,这里我们要知道置信度是相当于什么的置信度,偏移量相对于谁的偏移量,前面已经说了P-net相当于12*12的卷积核,以步长为2在原图上滑动,若置信度满足要求,说明就有12*12的框与原图相对应,这里的12*12就是P-net的先验框。由于12*12大小的在原图上基本不可能框到人脸,于是图像每输入到网络都要进行缩放,记录缩放的倍数,直到图像小于等于12为止。那么就有了N*N大小的图进行输入,每次就输出C*C*15的特征图,15个通道分为1个置信度,4个位置偏移量,10个关键点偏移量。输出的特征图可根据置信度,取出满足要求的置信度的索引得到所在特征图的先验框,然后根据先验框和输出的偏移量,找到P-Net的真实框。把P-Net输出的真实框裁剪下来,若不是正方形,就通过图像填充成正方形,主要是为了缩放时,图像信息不丢失。然后缩放成24*24,传入R-Net,R-Net最后输出(N,V)结构,找到阈值(置信度)对应的输出的偏移量,注意这里的先验框变成了24*24的P-Net裁剪下来的框。同理O-Net与R-Net反算是一致的。
下面是代码
import torch
import numpy as np
from Tool import Function_2 as Fn
import time
from PIL import Image
from torchvision import transforms
import Nets
class Detcetor:
def __init__(self, pnet_path=r"Params/pnet.pth", rnet_path=r"Params/rnet.pth",
onet_path=r"Params/onet.pth"):
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.pnet = Nets.PNet().to(self.device)
self.rnet = Nets.RNet().to(self.device)
self.onet = Nets.ONet().to(self.device)
self.pnet.load_state_dict(torch.load(pnet_path, map_location=torch.device('cpu')))
self.rnet.load_state_dict(torch.load(rnet_path, map_location=torch.device('cpu')))
self.onet.load_state_dict(torch.load(onet_path, map_location=torch.device('cpu')))
self.pnet.eval()
self.rnet.eval()
self.onet.eval()
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
def detect(self, image):
# P网络侦查
start_time = time.time()
pnet_boxes = self.pnet_detect(image)
if pnet_boxes.shape[0] == 0:
return torch.Tensor([]) # 结束侦查
end_time = time.time()
t_pnet = end_time - start_time
# return pnet_boxes
# R网络侦查
start_time = time.time()
rnet_boxes = self.rnet_detect(image, pnet_boxes)
if rnet_boxes.shape[0] == 0:
return torch.Tensor([]) # 结束侦查
end_time = time.time()
t_rnet = end_time - start_time
# return rnet_boxes
# O网络侦查
start_time = time.time()
onet_boxes = self.onet_detect(image, rnet_boxes)
if onet_boxes.shape[0] == 0:
return torch.Tensor([]) # 结束侦查
end_time = time.time()
t_onet = end_time - start_time
# 全部侦查所用时间
t_sum = t_pnet + t_rnet + t_onet
print("total:{0} pnet:{1} rnet:{2} onet:{3}".format(t_sum, t_pnet, t_rnet, t_onet))
return onet_boxes
def pnet_detect(self, image):
img = image
w, h = img.size
min_side_len = min(w, h)
scale = 1
boxes = []
while min_side_len > 12:
# img_data = self.transform(img) - 0.5
img_data = self.transform(img)
# unsqueeze升维;squeeze降维
img_data = torch.unsqueeze(img_data, dim=0).to(self.device)
_conf, _offset, _landmark = self.pnet(img_data)
print(_offset.shape)
# _conf[1,1,h,w],conf取h,w
# _offset[1,c,h,w],offset取c,h,w
conf, offset = _conf[0][0], _offset[0]
# conf,offset都为张量
conf = conf.cpu().detach()
offset = offset.cpu().detach()
# 从P网络特征图返回到原图区域
_boxes = self.P_Boxes(conf, offset, scale, thresh=0.95, stride=2, side_len=12)
# _boxes两个维度
# extend将_boxes按0维拆开再追加到boxes列表中
boxes.extend(_boxes)
# 缩放img
scale *= 0.7
_w = int(w * scale)
_h = int(h * scale)
img = img.resize((_w, _h))
# 更新循环条件
min_side_len = min(_w, _h)
if len(boxes) == 0:
return torch.Tensor([])
# 将boxes列表组装成2维张量
boxes = torch.stack(boxes)
# 非极大值抑制
return Fn.nms(boxes, 0.3)
def rnet_detect(self, image, pnet_boxes):
img_dataset = []
# 把侦查P网络得到的框调整成正方形
_pnet_boxes = Fn.convert_to_square(pnet_boxes)
"""
根据_pnet_boxes提供的n个框,抠n张图,全部resize成28*28,
组装成n个批次,[n,c,h,w],传入R网络,得到n个新的置信度和偏移量
用R_box()筛选出m个置信度大于阈值的_pnet_boxes中对应的框以及对应的偏移量,反算到原图
R_box()返回新的m个框的位置和置信度
"""
for _box in _pnet_boxes:
_x1 = int(_box[0])
_y1 = int(_box[1])
_x2 = int(_box[2])
_y2 = int(_box[3])
img = image.crop((_x1, _y1, _x2, _y2))
img = img.resize((24, 24))
img_data = self.transform(img)
# img_data = self.transform(img) - 0.5
img_dataset.append(img_data)
img_dataset = torch.stack(img_dataset) # 组装批次[n,c,h,w]
img_dataset = img_dataset.to(self.device)
# pnet_boxes中n个框对应n个图片,传入R网络得到n个置信度和偏移量
# _conf[n,1],offset[n,4]
conf, offset, _landmark = self.rnet(img_dataset)
conf = conf.cpu().detach()
offset = offset.cpu().detach()
# 利用R_Boxes()返回到原图区域
rnet_boxes = self.oR_Boxes(conf, offset, _pnet_boxes, thresh=0.9)
# 非极大值抑制
return Fn.nms(rnet_boxes, 0.3)
def onet_detect(self, image, rnet_boxes):
img_dataset = []
# 把侦查R网络得到的框调整成正方形
_rnet_boxes = Fn.convert_to_square(rnet_boxes)
# print(_rnet_boxes.shape)
for _box in _rnet_boxes:
_x1 = int(_box[0])
_y1 = int(_box[1])
_x2 = int(_box[2])
_y2 = int(_box[3])
# 抠图,resize,
img = image.crop((_x1, _y1, _x2, _y2))
img = img.resize((48, 48))
img_data = self.transform(img)
img_dataset.append(img_data)
img_dataset = torch.stack(img_dataset) # 组装[n,c,h,w]
# print(img_dataset.shape)
img_dataset = img_dataset.to(self.device)
conf, offset, _landmark = self.onet(img_dataset) # n,v结构
# # 取出元素转成numpy
conf = conf.cpu().detach()
offset = offset.cpu().detach()
# 利用oR_Boxes()返回到原图区域
onet_boxes = self.oR_Boxes(conf, offset, _rnet_boxes, thresh=0.999)
# 非极大值抑制
return Fn.nms(onet_boxes, 0.3, ismin=True)
# 从特征图返回到原图区域
# 置信度conf,阈值thresh,偏移量offset,原图缩放比例scale
def P_Boxes(self, conf, offset, scale, thresh=0.9, stride=2, side_len=12):
# 保留比阈值大的置信度,以及对应的偏移量,用于反算对应到原图的区域(boxes)
mask = conf > thresh
# 保留比阈值大的置信度
conf = conf[mask] # 一维
# print(conf, '<<<<<<<<<<')
# 获取对应置信度的索引
idxes = torch.nonzero(mask)
# print(idxes)
# 获取置信度对应的偏移量
# 偏移量在0维,需要换轴到2维[c,h,w]到[h,w,c]
offset = offset.permute(1, 2, 0)
# 得到偏移量,2维数组,1维长度4
offset = offset[mask]
# 置信度有了,对应的索引有了,对应的偏移量有了
# 1、用索引idxes、步长stride,卷积核边长side_len和缩放比例scale,反算建议框在原图的区域
# xx1,yy1,xx2,yy2都为一维数组
# 建议框
xx1 = (idxes[:, 1] * stride).float() / scale
yy1 = (idxes[:, 0] * stride).float() / scale
xx2 = (idxes[:, 1] * stride + side_len).float() / scale
yy2 = (idxes[:, 0] * stride + side_len).float() / scale
# 2、用偏移量offset(单位长度的偏移量)、建议框的宽w高h,反算实际框的区域
# x1,y1,x2,y2都为一维数组
w = xx2 - xx1
h = yy2 - yy1
x1 = xx1 + w * offset[:, 0]
y1 = yy1 + h * offset[:, 1]
x2 = xx2 + w * offset[:, 2]
y2 = yy2 + h * offset[:, 3]
# 将x1,y1,x2,y2和对应置信度组合到一起
box = torch.stack([x1, y1, x2, y2, conf.float()], dim=1)
return box
# 用oR_box()筛选出m个置信度大于阈值的框,用P_boxes提供的框和新的偏移量,反算到原图
# oR_box()返回新的m个框的位置和置信度
def oR_Boxes(self, conf, offset, _pnet_box, thresh=0.9):
# pnet_box[n,5],conf[n,1],offset[n,4]
mask = conf > thresh # [n,1]
# 满足条件的置信度对应的框以及新的偏移量
conf = conf[mask] # [m]
# 非0索引
index = torch.nonzero(mask) # 两个维度[m,2]
idx = index[:, 0] # 获得0维上的索引[m]
_pnet_box = _pnet_box[idx] # [m,5]
offset = offset[idx] # [m,4]
# 反算到原图
# 1、建议框坐标以及h,w
w = _pnet_box[:, 2] - _pnet_box[:, 0]
h = _pnet_box[:, 3] - _pnet_box[:, 1]
# 2、反算到原图
xx1 = _pnet_box[:, 0] + w * offset[:, 0]
yy1 = _pnet_box[:, 1] + h * offset[:, 1]
xx2 = _pnet_box[:, 2] + w * offset[:, 2]
yy2 = _pnet_box[:, 3] + h * offset[:, 3]
# 组装
boxes = [xx1, yy1, xx2, yy2, conf]
boxes = torch.stack(boxes, dim=1)
return boxes
效果展示
.