(深度学习)前馈神经网络—全连接网络的一般流程
一、神经网络
-
引言:
神经网络是一种大规模的并行分布式处理器,天然具有存储并使用经验知识的能力,它从两个方面上模拟大脑:网络获取的知识是通过学习来获取的;内部神经元的连接强度,即突出权重,用于存储获取的知识。 ——西蒙·赫金(Simon Haykin) -
定义:
神经网络是指一系列受生物学和神经科学启发的数学模型。这些模型主要是通过对人脑的神经元网络进行抽象,构建人工神经元,并按照一定拓扑结构来建立人工神经元之间的连接,来模拟生物神经网络。 -
基础模型:
前馈神经网络、卷积神经网络(CNN)、循环神经网络(RNN)等 -
学习框架:
Pytorch:学生和科研工作者
TensorFlow:企业工程师等开发者 -
资料推荐:
神经网络与深度学习——邱锡鹏(GitHup有开源资料)
机器学习学习——周志华
统计学习方法—— 李航
斯坦福大学的公开课:链接
台大的深度学习入门300页PPT(全英文)
二、建模流程(结构化数据)

三、相关算法和函数
- 损失函数:
分为经验风险损失函数和结构风险损失函数,经验风险损失函数反映的是预测结果和实际结果之间的差别,结构风险损失函数则是经验风险损失函数加上正则项(L0、L1(Lasso)、L2(Ridge)。
机器学习模型关于单个样本的预测值与真实值的差称为损失。损失越小,模型越好,如果预测值与真实值相等,就是没有损失。同理,在神经网络中,损失函数越小,模型的性能越好。
(1)常见的损失函数有:
交叉熵分式函数:用于二分类或多分类任务。
平方损失函数:预测值和真实值差的平方。误差越大,损失越大。一般用于回归问题
绝对值损失函数:预测值和真实值差的绝对值。
对数损失函数:对预测值是概率的问题,取对数损失。 - 激活函数
神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数。激活函数的作用:简答来说,模型的每一层节点的输入都是上层输出的线性函数,即输出都是输入的线性组合,那么网络的逼近能力就是有限的,因此输出是线性的,而有些问题的解决是非线性问题,引入激活函数的作用就是解决模型的非线性。
(1)常见的激活函数:
Sigmoid函数: f ( z ) = 1 1 + e − z f(z)=\frac{1}{1+e^-z} f(z)=1+e−z1
图像如下:

作用:它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1
tanh函数: t a n h ( x ) = e x − e − x e x + e − x tanh(x)=\frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x
图像如下:

作用:解决了Sigmoid函数的不是zero-centered输出问题,但是,梯度消失的问题和幂运算的问题仍然存在。
Relu函数: R e l u = m a x ( 0 , x ) Relu = max(0,x) Relu=max(0,x)

作用:克服梯度消失的问题,加快训练速度;收敛速度远快于sigmoid和tanh。
3. 反向传播算法(又“BP算法“和“误差逆传播算法”):
BP算法采取基于梯度下降的策略,以目标的负梯度方向对参数进行调整,其目标是最小化训练误差。
通俗讲,反向传播的字面理解是将数据从后(输出)向前(输入)传递,数据的具体形式是损失函数对其超参数(权重(W)和偏置(b))的偏导数,反向传播的目的是使损失函数达到最小。
四、实战
本次结构化数据建模利用kaggle上的泰坦尼克号数据集(模型性能一般,利用机器学习对泰坦尼克号预测的精度是最好的,本次案例只是举例,相关问题还是用相关模型来预测),本案例利用pytorch框架来搭建模型。
1. 导入相关的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader,TensorDataset
2. 读取数据:
dftrain_raw=pd.read_csv('train.csv')
dftest_raw=pd.read_csv('test.csv')
3.数据处理(利用独热编码处理):
def prepeocessing(dfdata):
dfresult=pd.DataFrame()
# 票类进行独热编码
dfPclass=pd.get_dummies(dfdata['Pclass'])
dfPclass.columns=['Pclass_'+ str(x) for x in dfPclass.columns]
dfresult=pd.concat([dfresult,dfPclass],axis=1)
#Sex 性别进行独热编码
dfSex = pd.get_dummies(dfdata['Sex'])
dfresult = pd.concat([dfresult,dfSex],axis = 1)
#Age年龄进行缺失值进行0填充
dfresult['Age'] = dfdata['Age'].fillna(0)
# 将空值设置为1,真实值设为0
dfresult['Age_null'] = pd.isna(dfdata['Age']).astype('int32')
#SibSp,Parch,Fare添加到dfresult中
dfresult['SibSp'] = dfdata['SibSp']
dfresult['Parch'] = dfdata['Parch']
dfresult['Fare'] = dfdata['Fare']
#Carbin 客舱
dfresult['Cabin_null'] = pd.isna(dfdata['Cabin']).astype('int32')
#Embarked乘客登船港口进行独热编码
dfEmbarked = pd.get_dummies(dfdata['Embarked'],dummy_na=True)
dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns]
dfresult = pd.concat([dfresult,dfEmbarked],axis = 1)
return(dfresult)
# 获取训练集和测试集的数值
x_train=prepeocessing(dftrain_raw).values
y_train=dftrain_raw['Survived'].values
x_test=prepeocessing(dftest_raw).values
y_test=dftest_raw['Survived'].values
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
4.数据管道
# 构造数据加载器,打乱顺序在分组,每一个小组打包为8条数据
dl_train = DataLoader(TensorDataset(torch.tensor(x_train).float(),torch.tensor(y_train).float()),
shuffle = True, batch_size = 8)
dl_valid = DataLoader(TensorDataset(torch.tensor(x_test).float(),torch.tensor(y_test).float()),
shuffle = False, batch_size = 8)
4.模型构造 利用nn.Sequential()来构造
def create_net():
#定义模型容器,有序
net=nn.Sequential()
#设置为全连接层网络
net.add_module('Linear1',nn.Linear(15,20))
#设置激活函数
net.add_module('relu1',nn.ReLU())
net.add_module('Linear2',nn.Linear(20,15))
net.add_module('relu2',nn.ReLU())
net.add_module('Linear3',nn.Linear(15,1))
net.add_module('relu',nn.Sigmoid())
return net
5.定义损失函数、优化器及评估指标
from sklearn.metrics import accuracy_score
# 定义损失函数,二分类问题利用交叉熵损失函数
loss_func=nn.BCELoss()
# 定义优化器,学习率为0.01
optimizer = torch.optim.Adam(params=net.parameters(),lr = 0.01)
# 分类准确率指标
metric_func = lambda y_pred,y_true: accuracy_score(y_true.data.numpy(),y_pred.data.numpy()>0.5)
metric_name = "accuracy"
6.训练模型(脚本形式)
import datetime
# 迭代次数
epochs = 10
# 跳跃步数
log_step_freq = 30
dfhistory = pd.DataFrame(columns = ["epoch","loss",metric_name,"val_loss","val_"+metric_name],dtype=object)
print("Start Training...")
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("=========="*8 + "%s"%nowtime)
for epoch in range(1,epochs+1):
# 训练循环
net.train()
loss_sum=0.0
metric_sum=0.0
step=1
for step,(features,labels) in enumerate(dl_train,1):
# 梯度清零
optimizer.zero_grad()
# 正向传播求损失
predictions=net(features)
loss=loss_func(predictions[:,0],labels)
metric=metric_func(predictions,labels)
# 反向传播求梯度
loss.backward()
# 更新迭代参数
optimizer.step()
# 打印batch级别日志
# 损失求和
loss_sum += loss.item()
# 分类准确率求和
metric_sum += metric.item()
# 每30个batch打印输出一次
if step%log_step_freq == 0:
print(("[step = %d] loss: %.3f, "+metric_name+": %.3f") %
(step, loss_sum/step, metric_sum/step))
# 验证循环
net.eval()
val_loss_sum=0.0
val_metric_sum=0.0
val_step=1
for val_step,(features,labels) in enumerate(dl_valid,1):
# 关闭梯度计算
with torch.no_grad():
predictions=net(features)
# 损失函数
val_loss=loss_func(predictions[:,0],labels)
# 分类准确率
val_metric=metric_func(predictions,labels)
# 求和
val_loss_sum+=val_loss.item()
val_metric_sum+=val_metric.item()
# 3,记录日志-------------------------------------------------
# 迭代次数,训练损失值,训练准确值,验证损失值,验证准确率
info = (epoch, loss_sum/step, metric_sum/step,
val_loss_sum/val_step, val_metric_sum/val_step)
dfhistory.loc[epoch-1] = info
# 打印epoch级别日志
print(("\nEPOCH = %d, loss = %.3f,"+ metric_name + \
" = %.3f, val_loss = %.3f, "+"val_"+ metric_name+" = %.3f")
%info)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
print('Finished Training...')
输出:
Start Training...
================================================================================2022-03-04 10:31:57
[step = 30] loss: 0.682, accuracy: 0.629
[step = 60] loss: 0.666, accuracy: 0.654
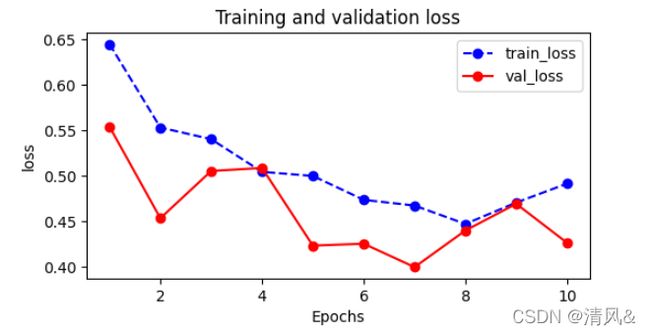
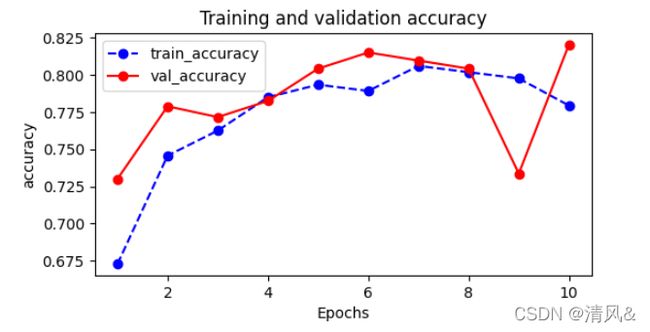
EPOCH = 1, loss = 0.645,accuracy = 0.673, val_loss = 0.554, val_accuracy = 0.730
================================================================================2022-03-04 10:31:58
[step = 30] loss: 0.623, accuracy: 0.704
[step = 60] loss: 0.580, accuracy: 0.723
EPOCH = 2, loss = 0.553,accuracy = 0.746, val_loss = 0.453, val_accuracy = 0.779
================================================================================2022-03-04 10:31:58
[step = 30] loss: 0.542, accuracy: 0.750
[step = 60] loss: 0.533, accuracy: 0.769
EPOCH = 3, loss = 0.540,accuracy = 0.763, val_loss = 0.505, val_accuracy = 0.772
================================================================================2022-03-04 10:31:59
[step = 30] loss: 0.510, accuracy: 0.746
[step = 60] loss: 0.540, accuracy: 0.750
EPOCH = 4, loss = 0.504,accuracy = 0.785, val_loss = 0.508, val_accuracy = 0.783
================================================================================2022-03-04 10:31:59
[step = 30] loss: 0.546, accuracy: 0.796
[step = 60] loss: 0.506, accuracy: 0.802
EPOCH = 5, loss = 0.500,accuracy = 0.794, val_loss = 0.423, val_accuracy = 0.804
================================================================================2022-03-04 10:31:59
[step = 30] loss: 0.457, accuracy: 0.796
[step = 60] loss: 0.466, accuracy: 0.785
EPOCH = 6, loss = 0.473,accuracy = 0.789, val_loss = 0.425, val_accuracy = 0.815
================================================================================2022-03-04 10:31:59
[step = 30] loss: 0.497, accuracy: 0.771
[step = 60] loss: 0.487, accuracy: 0.808
EPOCH = 7, loss = 0.467,accuracy = 0.806, val_loss = 0.399, val_accuracy = 0.810
================================================================================2022-03-04 10:31:59
[step = 30] loss: 0.426, accuracy: 0.821
[step = 60] loss: 0.439, accuracy: 0.812
EPOCH = 8, loss = 0.447,accuracy = 0.802, val_loss = 0.440, val_accuracy = 0.804
================================================================================2022-03-04 10:31:59
[step = 30] loss: 0.463, accuracy: 0.800
[step = 60] loss: 0.445, accuracy: 0.817
EPOCH = 9, loss = 0.470,accuracy = 0.798, val_loss = 0.469, val_accuracy = 0.734
================================================================================2022-03-04 10:31:59
[step = 30] loss: 0.482, accuracy: 0.771
[step = 60] loss: 0.471, accuracy: 0.787
EPOCH = 10, loss = 0.491,accuracy = 0.779, val_loss = 0.426, val_accuracy = 0.821
================================================================================2022-03-04 10:31:59
Finished Training...
7.模型评估:
# 查看一下模型在训练集和验证集上的效果
dfhistory
输出:

定义函数,查看预测值和真实值的差异,可视化:
import matplotlib.pyplot as plt
def plot_metric(dfhistory, metric):
plt.figure(figsize=(6,3),dpi=100)
train_metrics = dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
# 查看训练集合验证集的损失函数的对比
plot_metric(dfhistory,'loss')
输出:
# 查看训练集和验证集的分类准确率的对比
plot_metric(dfhistory,'accuracy')
输出:
8.模型使用:
#预测概率
y_pred_probs = net(torch.tensor(x_test[0:10]).float()).data
y_pred_probs
输出:
tensor([[0.2680],
[0.5225],
[0.3500],
[0.7730],
[0.5011],
[0.8644],
[0.2637],
[0.7063],
[0.5382],
[0.1724]])
查看预测出的标签:
torch.where(condition, x, y)
condition是条件,x 和 y 是同shape 的矩阵, 针对矩阵中的某个位置的元素, 满足条件就返回x,不满足就返回y
torch.ones_like:返回一个填充为1标量值的张量
torch.zeros_like:返回一个填充为0标量值的张量
y_pred = torch.where(y_pred_probs>0.5,torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs))
y_pred
输出:
tensor([[0.],
[1.],
[0.],
[1.],
[1.],
[1.],
[0.],
[1.],
[1.],
[0.]])
9.保存模型:
Pytorch 有两种保存模型的方式,都是通过调用pickle序列化方法实现的。一种方法只保存模型参数。第二种方法保存完整模型。
Pytorch中,torch.nn.Module模块中的state_dict(只包含卷积层和全连接层)变量存放训练过程中需要学习的权重和偏执系数,以字典对象的形式将每一层的参数映射成tensor张量
# 查看全连接层的各个参数
print(net.state_dict().keys())
输出:
odict_keys(['Linear1.weight', 'Linear1.bias', 'Linear2.weight', 'Linear2.bias', 'Linear3.weight', 'Linear3.bias'])
# 保存模型
# 保存模型各个参数
torch.save(net.state_dict(),'net_parameter.pkl')
net_clone=create_net()
# 将预训练的参数权重加载到新的模型中
net_clone.load_state_dict(torch.load("net_parameter.pkl"))
# 测试数据
net_clone.forward(torch.tensor(x_test[0:10]).float()).data
输出:
tensor([[0.2680],
[0.5225],
[0.3500],
[0.7730],
[0.5011],
[0.8644],
[0.2637],
[0.7063],
[0.5382],
[0.1724]])
作者声明,部分代码引用自“和鲸社区中的
沉静中的流年作者的20天吃掉Pytorch”
鄙人初窥神经网络门槛,才疏学浅,还望圈内大佬及时指正。
下次更新卷积神经网络。