机器学习PYTHON实践
目录
- 绪论
-
- 统计机器学习三要素
- 监督学习
- 无监督学习
- 强化学习
- SKLearn介绍
-
- SKLearn模块组织及顶层设计
- 统一API调用接口
- SKLearn数据集操作API
- SKLearn模型选择
-
- 数据集划分策略
- 超参数优化方法
- 模型验证方法
- 模型评估方法
- SKLearn分类器评估
-
- 精确率
- 混淆矩阵
- Precious-Recall-Fmeasur
- ROC曲线
- 损失函数
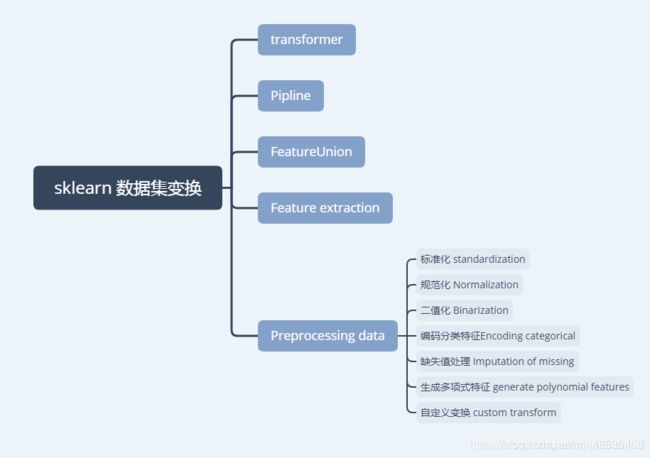
- SKLearn数据集变换
-
- 数据集变换步骤
- Pipline
- FeatureUnion
- 特征抽取
- 数据预处理
绪论
机器学习,它致力于研究如何通过计算(CPU和GPU计算)的手段,利用经验来改善 (计算机)系统自身的性能。
机器学习所研究的主要内容:
- 在计算机上从数据中产生“模型(model)”算法(学习算法)
- 数据+机器学习算法=机器学习模型
统计机器学习的方式:
- 监督学习
- 无监督学习
- 强化学习
统计机器学习三要素
统计学习方法由三要素构成:方法=模型+策略+算法
1. 模型
在监督学习中,模型是所要学习的条件概率分布或决策函数。模型的假设空间包含所有可能的条件概率分布或决策函数。参数向量 θ θ θ取值于n维欧式空间 R n R^n Rn,称为参数空间,假设空间F通常是由一个参数向量决定的函数族:
![]()
假设空间也可以定义为条件概率的集合
![]()
2. 策略
损失函数和风险函数
监督学习中需要用一个损失函数(loss function)或代价函数(cost function)来度量预测错误的程度,常用的损失函数有以下几种:
- 0-1损失函数(0-1 loss function)

- 平方损失函数(quadratic loss function)

- 绝对损失函数(absolute loss function)
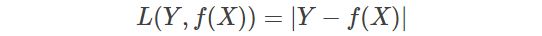
- 对数(似然)损失函数(logarithmic loss function)

期望风险
损失函数值越小,模型就越好。由于模型的输入,输出是随机变量,遵循联合分布P(X,Y),所以损失函数的期望是
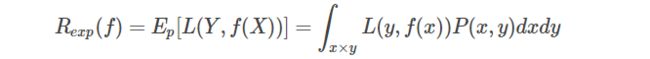
理论上f(X)关于联合分布P(X,Y)的平均意义下的损失,称为风险函数(risk function)或期望损失(expected loss)。
经验风险
给定一个训练数据集,模型f(X)关于训练数据集的平均损失称为经验风险(empirical risk)或经验损失(empirical loss)

监督学习的目标就是选择期望风险最小的模型,由于联合分布P(X,Y)是未知的,无法得到真实的期望风险。经验风险是模型关于训练样本集的平均损失,根据大数定理,当样本容量N趋于无穷时,经验风险趋于期望风险。所以一个很自然的想法是用经验风险估计期望风险,但是由于现实中训练样本数目有限,甚至很小,所以用经验风险估计期望风险常常不理想,需要对经验风险进行一定的矫正。
3. 算法
算法是指学习模型的具体计算方法,以求解最优模型。如果最优化问题有显式的解析解,这个最优化问题比较简单,但是通常解析解不存在,这就需要用数值计算的方法求解。如何保证找到全局最优解,并使求解的过程高效,是需要考虑的一个重要问题。
监督学习
在监督学习中,将输入与输出所有可能取值的集合分别称为输入空间与输出空间。输入空间与输出空间可以是无限元素的集合,也可以是整个欧式空间,输入空间与输出空间可以是同一个空间,也可以是不同的空间,但通常输出空间远远小于输入空间。
每个具体的输入就是一个实例,通常有特征向量表示,所有特征向量存在的空间称为特征空间。特征空间的每一维对应一个特征,模型实际上都是定义在特征空间上的。
监督学习从训练数据集合中学习模型,对测试数据进行预测,训练数据由输入与输出对(样本/样本点)组成。输入输出变量可以是连续的,也可以是离散的,根据不同类型建立不同模型,输出变量为连续变量时,预测问题为回归问题;输出变量为离散变量时,预测问题为分类问题;输入与输出均为变量序列的预测问题为标注问题。

无监督学习
在无标记的数据上进行学习,重在发现数据中潜在的结构化信息,寻找数据的新视图。
输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。通俗点将就是实际应用中,不少情况下无法预先知道样本的标签,也就是说没有训练样本对应的类别,因而只能从原先没有样本标签的样本集开始学习分类器设计。
无监督学习的方法分为两大类:
(1)一类为基于概率密度函数估计的直接方法:指设法找到各类别在特征空间的分布参数,再进行分类。
(2)另一类是称为基于样本间相似性度量的简洁聚类方法:其原理是设法定出不同类别的核心或初始内核,然后依据样本与核心之间的相似性度量将样本聚集成不同的类别。
利用聚类结果,可以提取数据集中隐藏信息,对未来数据进行分类和预测。应用于数据挖掘,模式识别,图像处理等。

强化学习
一个能够感知环境的自治智能体(Agent),如何通过学习来选择能够达到目标的最优动作,即强化学习Agent的要解决的问题就是学习从环境到动作的映射。
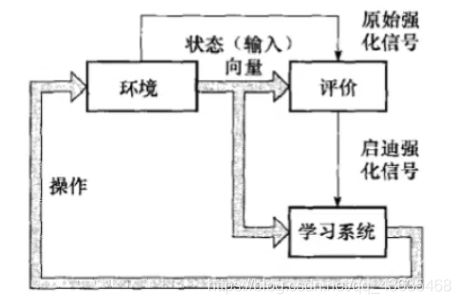
强化学习的特征:
- Agent不是静止的,被动的等待而是主动的对环境做出试探;
- 环境对试探动作反馈的信息是评价性的(好或坏);
- Agent在行动-评价的环境中获得知识,改进行动方案以适应环境,达到预期目的。

SKLearn介绍
scikit-learn,又写作sklearn,是一个开源的基于python语言的机器学习工具包。它通过NumPy, SciPy和Matplotlib等python数值计算的库实现高效的算法应用,并且涵盖了几乎所有主流机器学习算法。
在工程应用中,用python手写代码来从头实现一个算法的可能性非常低,这样不仅耗时耗力,还不一定能够写出构架清晰,稳定性强的模型。更多情况下,是分析采集到的数据,根据数据特征选择适合的算法,在工具包中调用算法,调整算法的参数,获取需要的信息,从而实现算法效率和效果之间的平衡。而sklearn,正是这样一个可以帮助我们高效实现算法应用的工具包。
SKLearn模块组织及顶层设计
SKLearn包含三大模块:监督学习、无监督学习及数据变换。
1、监督学习
- neighbors:近邻算法
- svm:支持向量机算法
- kernal_ridge:核岭回归
- neighbors:近邻算法
- discriminant_analysis:判别分析
- linear_model:广义线性模型
- ensemble:集成方法
- tree:决策树
- naive_bayes:朴素贝叶斯
- cross_decomposition:交叉分解
- gaussian_process:高斯过程
- neural_network:多层神经网络
- calibration:概率校准
- isotonic:保序回归
- feature_selection:监督特征选择
- multiclass:多类多标签算法
2、无监督学习
- decomposition:矩阵因子分解
- cluster:聚类分析
- manifold:流形学习
- mixture:高斯混合模型
- neural_network:无监督神经网络
- density:密度估计
- covariance:协方差估计
3、数据变换
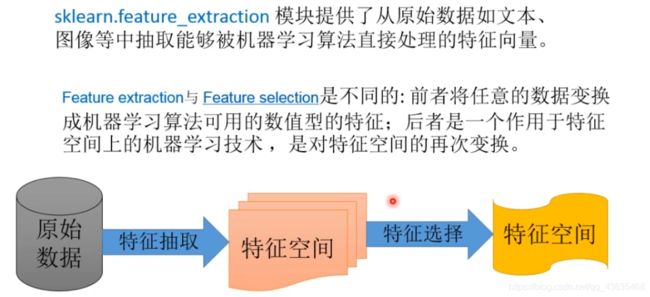
- feature_extraction:特征抽取
- feature_selection:特征选择
- preprocessing:数据预处理
- random_projection:随机投影
- kernel_approximation:核逼近
- pipline:管道流
算法类的顶层设计图
- baseEstimator:所有评估器的父类
- ClassifierMixin:所有分类器的父类,其子类必须实现一个score函数
- RegressorMixin:所有回归器的父类,其子类必须实现一个score函数
- ClusterMixin:所有聚类的父类,其子类必须实现一个fit_predict函数
- TransformerMixin:所有数据变换的父类,其子类必须实现一个fit_transform函数
- DensityMixin:所有密度估计相关的父类,其子类必须实现一个score函数
以svm为例:
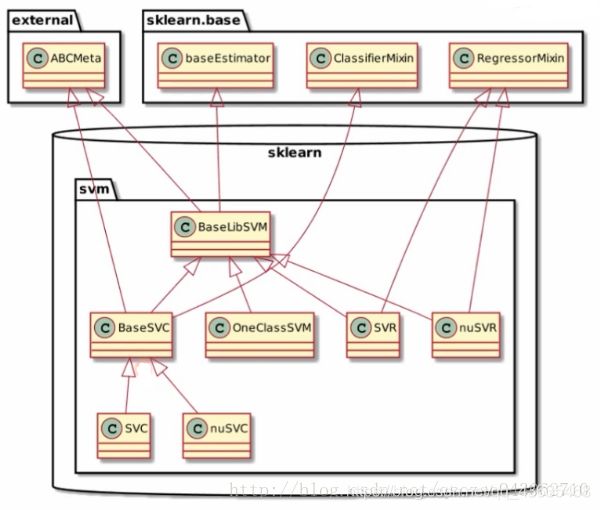
这里SVC即support vector classifier,SVR即support vector regression,svm既可以作为分类器,也可以作为回归器,所以,它们分别继承实现了ClassifierMixin和RegressorMixin。
统一API调用接口
在sklearn里面,我们可以使用完全一样的接口来实现不同的机器学习算法。
- 数据加载和预处理
- 定义分类器(回归器等等),譬如svc = svm.svc()
- 用训练集对模型进行训练,只需调用fit方法,svc.fit(X_train, y_train)
- 用训练好的模型进行预测:y_pred=svc.predict(X_test)
- 对模型进行性能评估:svc.score(X_test, y_test)
模型评估中,可以通过传入一个score参数来自定义评估标准,该函数的返回值越大代表模型越好。sklearn有一些预定义的score方法,这些方法名在sklearn.metrics.SCORERS中定义,调用时只需传入相应的字符串即可。
SKLearn数据集操作API
1、sklearn自带的小数据集的加载(Packaged Dataset)
sklearn.datasets.load_datanema自带的小数据集如下:
- 鸢尾花数据集: load-iris()
- 乳腺癌数据集: load-breast-cancer()
- 手写数字数据集: load_digits()
- 糖尿病数据集: load_diabetes()
- 波士顿房价数据集: load_boston()
- 体能训练数据集: load-linnerud()
- 图像数据集: load-sample-image(name)
2、在线下载的数据集(Downloadable Dataset)
sklearn.datasets.fetch_dataname3、计算机生成的数据集(Generated_Dataset)
sklearn.datasets.make_dataname4、svmlight/libsvm 格式的数据集
sklearn.datasets.load_svmlight_file这种格式比较适合存放稀疏数据,svmlight /libsvm的每一行样本的存放格式:
![]()
5、从mldata.org(一个机器学习数据集网站)在线下载获取数据集
sklearn.datasets.fetch_mldata(dataname)SKLearn模型选择
数据集划分策略
1.交叉验证
kFold、GroupFold、StratifiedFold
划分的策略如下:
- 数据集S划分成K个不相交的子集;
- 从K个里面选一个作为测试数据,K-1个训练数据;
- 在K-1个训练数据上训练模型;
- 把这个模型放到测试数据集,得到分类率;
- 计算K次得到平均值,作为该模型或者假设函数的真是分类率。
过程繁琐,需要k此训练和K次测试
2.留一/P法
leaveoneout(留一法)、leavegroupout,leavepout(留P法)、leavegroupsout
划分策略如下:
假设N个样本,将每个样本作为测试样本,其他N-1个为训练样本,这样得到N个分类器,N个测试结构,用着N个结果的平均值来衡量模型的性能。
留P法则是每P个样本作为测试样本,N-P个位训练集。
3.随机划分
shuffesplit、groupshufflesplit、stratifiedshufflesplit
划分策略如下:
shufflesplit产生独立的train-test数据集划分,首先对样本全体随机打乱,然后划分train-test对,可以使用随机种子random-state来控制随机数序列发生器使得运算结果的重现;
stratifiedshufflesplit是shufflesplit的变形,返回层次划分,也就是在创建划分的时候,保证每个划分中类的样本比例与整体数据集中的原始比例保持一致。
超参数优化方法
超参数是指我们无法直接从数据集获取的参数。
超参数的选择是通过搜索超参数的取值空间来选择的,我们可以使用estimator.get_params()来获取当前的参数,但是一般不会一步一步靠获取当前参数来选择最优结果。所以我们经常用到参数空间的搜索这一概念。
一个参数搜索空间由5个部分组成:
- 一个estimator(回归器或分类器)
- 一个参数的空间
- 一个搜索或采样方法来获取参数组合
- 一个交叉验证机制
- 一个评分函数
寻找最优超参数的方法有两种:网格搜索和随机采样,两个优化方法均在sklearn.model_selection.里面,两种超参数的搜索方法均实现了统一的API。
1、网格搜索(GridsearchCV)
特点:我们在指定搜索的参数要求时,其取值只能是连续的(随机采样可以使用scipy.stats指定任意分布)

2、随机采样超参数的优化
指定参数的采样范围和分布可以用一个字典表来完成,需要指定计算次数,通过n_iter来指定,取值范围可以离散也可以时连续分布,连续分布需包含当前所有的取值。
优化技巧
- 指定一个合适的目标测度对模型进行评估,使用estimator.score函数
(分类器sklearn.metrics.accuracy_score回归器sklearn.metrics.r2_score) - 使用sklearn的pipline对estimator和参数空间组合
- 合理化数据集,使用model_selection.train_test_split()划分
- 并行运算,指定n_jobs的大小,受硬件的值约
- 提供某些错误节点上的鲁棒性,错误参数给出警告,可以通过error_score=0(or=np.Nan)来指定
模型验证方法
- 通过交叉验证得分:
model_sleection.cross_val_score(estimator,X) - 对每个输入数据点产生交叉验证估计:
model_selection.cross_val_predict(estimator,X) - 计算并绘制模型的学习率曲线:
model_selection.learning_curve(estimator,X,y) - 计算并绘制模型的验证曲线:
model_selection.validation(estimator,…) - 通过排序评估交叉验证的得分在重要性:
model_selection.permutation_test_score(…)
模型评估方法
1、Estimator对象的score方法
score(self,X,y,y_true)函数在内部会调用predict函数获得预测响应y_predict,然后与传人的真实响应进行比较,计算得分。
使用estimator的score函数来评估模型的性能,默认情况下:
分类器对应于准确率:sklearn.metrics.accuracy_score
回归器对应于R2得分:sklearn.metrics.r2_score
2、在交叉验证中使用scoring参数
上面的两个模型选择工具中都有一个参数“scoring”,该参数用来指定在进行网格搜索或计算交叉验证得分的时候,用什么标准度量“estimator”的预测性能。
默认情况下,该参数为“None”就表示“GridSearchCV”与“cross_val_score”都会去调用“estimator”自己的“score”函数,我们也可以为“scoring”参数指定别的性能度量标准,他必须是一个可调用对象,sklearn.metric不仅为我们提供了一系列预定义的可调用对象,而且还支持自定义评估标准。
SKLearn分类器评估
sklearn分类器评估指标有:精确率、混淆矩阵、Precious-Recall-Fmeasur、ROC曲线、损失函数。
精确率
accuracy_score函数计算分类准确率:返回被正确分类的样本比例或者数量。当多标签分类任务中,该函数返回子集的准确率,对于给定的样本,如果预测得到的标签集合与该样本真正的标签集合吻合,那么subset accuracy=1否则为零。

import numpy as np
from sklearn.metrics import accuracy_score
y_pred=[0,2,1,3]
y_true=[0,1,2,3]
print(accuracy_score(y_true,y_pred,normalize=False))
2
print(accuracy_score(y_true,y_pred))
0.5混淆矩阵

TP(True Positive):将正类预测为正类数,真实为0,预测也为0
FN(False Negative):将正类预测为负类数,真实为0,预测为1
FP(False Positive):将负类预测为正类数, 真实为1,预测为0
TN(True Negative):将负类预测为负类数,真实为1,预测也为1
from sklearn.metrics import confusion_matrix
y_true=[2,0,2,2,0,1]
y_pred=[0,0,2,2,0,2]
print(confusion_matrix(y_true,y_prednlabels=[]))Precious-Recall-Fmeasur

通过混淆矩阵可以很明白看出各个参数的公式

常见的衡量参数的名字及求解方法

精确度是指测试结果与测量点很精确
准确度是指测试结果与真实值接近
参数F=(1+β²)prerecall/(β²prec+recall)
β越小,prec的权重大,反之recall权重大,β==1时代表两者同等重要
from sklearn import metrics
y_pred = [0, 1, 0, 1, 0, 0]
y_true = [1, 0, 0, 1, 0, 0]
print(metrics.precision_score(y_true, y_pred))
#precision_score仅支持二元分类,及0,1分类
print(metrics.recall_score(y_true, y_pred))
print(metrics.fbeta_score(y_true, y_pred,beta=1))
#f参数需要指定β的大小
print(metrics.precision_recall_fscore_support(y_true, y_pred,beta=1))import numpy as np
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
y_true = np.array([0, 0, 1, 1])
y_score = np.array((0.1, 0.4, 0.35, 0.8))
prec, recall, threshold = precision_recall_curve(y_true, y_score)
print(prec)
print(recall)
print(threshold)
print(precision_recall_curve(y_true, y_score))python中为了观测这三个指标,将其封装在一个函数中:classification_report
from sklearn.metrics import classification_report
y_pred = [0, 1, 0, 1, 0, 0]
y_true = [1, 1, 0, 1, 0, 0]
target = ['class1', 'class2']
print(classification_report(y_true, y_pred, target_names=target))
#上述代码中class的个数取决于数据集的维数,二元分类就只有两个class,三元就3个,无法多设置或少设置,说明report可以操作多元分类默认情况下只有正标签被用来计算指标,为了将这些指标扩展到多类,我们将多类视为二元分类的集合,并对数据集划分。同时计算这些子分类的二元指标,并将所有子分类问题上的得分平值平均起来,通常使用average。
5种处理权重的方法:macro,weighted,mirco,samples,average
ROC曲线
ROC空间(又叫sensitivityVS1-sensitivity plot)以TPR(又叫sensitivity)作为T轴, 对于给定的输入X,学习器模型预测得到对应的结果,这个预测响应与真实响应之间的差距,通过损失函数来描述。 1、Pipline方法 1、 标准化 一般会把train和test集放在一起做标准化,或者在train集上做标准化后,用同样的标准化器去标准化test集,此时可以用scaler 3、规范化(Normalization) 得到: 4、特征二值化 5、标签二值化 6、类别特征编码 7、标签编码 8、特征中含异常值时 9、生成多项式特征
FPR(1-sensitivity)作为X轴,构成的一个二维坐标空间,ROC空间描述了了TP和FP之间做折中权衡的原理。点集在左上方说明情况较好,右下方表示更差
在二元分类问题中,每个样本实例的类别预测通常是基于一个连续的随机变量X做出的,这个从样本实例中计算出的随机变量X被称为score,给定一个阈值参数T,X>T则为positive类服从F1(X),Xsklearn.metrics.roc_curve(y_ture,y_score,pos_label=None,
sample_weight=None,drop_intermediate=True)import numpy as np
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2)
print(fpr)
print(tpr)
print(thresholds)
print(roc_auc_score(y,scores))#计算AUC值损失函数


SKLearn数据集变换
数据集变换步骤

sklearn中的transformer类,有fit和transform函数。Pipline
Pipline将多个estimator级联成一个estimator。这样做考虑了数据处理一系列前后相继的固定流。
比如:feature extraction ——> normalization ——> classification


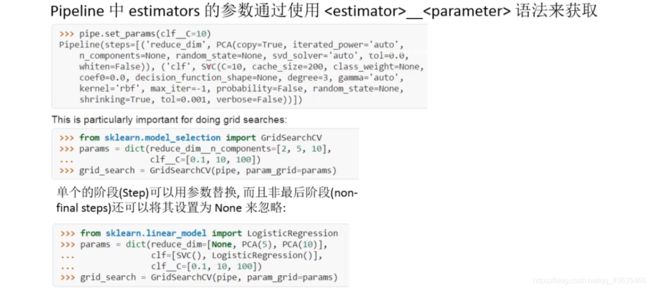
2、make_pipline方法

FeatureUnion


设定参数:

特征抽取
1、字典向量化

2、哈希变换


3、文本特征抽取

数据预处理
变换后各维特征有0均值,单位方差。也叫z-score规范化(零均值规范化)。计算方式是将特征值减去均值,除以标准差。sklearn.preprocessing.scale(X)
2、最小-最大规范化
对原始数据进行线性变换,变换到[0,1]区间(也可以是其他固定最小最大值的区间)。min_max_scaler = sklearn.preprocessing.MinMaxScaler()
min_max_scaler.fit_transform(X_train)
将不同变化范围的值映射到相同的固定范围,常见的是[0,1],此时也称为归一化。X = [[ 1, -1, 2],[ 2, 0, 0], [ 0, 1, -1]]
sklearn.preprocessing.normalize(X, norm='l2')array([[ 0.40, -0.40, 0.81], [ 1, 0, 0], [ 0, 0.70, -0.70]])
给定阈值,将特征转换为0/1。binarizer = sklearn.preprocessing.Binarizer(threshold=1.1)
binarizer.transform(X)lb = sklearn.preprocessing.LabelBinarizer()
有时候特征是类别型的,而一些算法的输入必须是数值型,此时需要对其编码。enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
enc.transform([[0, 1, 3]]).toarray() #array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])le = sklearn.preprocessing.LabelEncoder()
le.fit([1, 2, 2, 6])
le.transform([1, 1, 2, 6]) #array([0, 0, 1, 2])
#非数值型转化为数值型
le.fit(["paris", "paris", "tokyo", "amsterdam"])
le.transform(["tokyo", "tokyo", "paris"]) #array([2, 2, 1])sklearn.preprocessing.robust_scalepoly = sklearn.preprocessing.PolynomialFeatures(2)
poly.fit_transform(X)