使用神经网络(多层感知机)实现心脏病数据集分类任务
步骤
- 1、数据预处理
-
- 读取心脏病数据集
- 对数据集中的缺失值进行处理
- 对数据集进行标准化处理
- 主成分分析
- 把数据集切分成训练集和测试集
- 2、搭建模型
- 3、训练模型
-
- 绘制训练集的损失和准确率
- 4、模型评估
-
- 训练集和测试集的损失和准确率
- 混淆矩阵
- 绘制ROC曲线&AUC面积
- 5、总结
1、数据预处理
数据预处理首先需要到机器学习的网址(https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/)选择processed.cleveland.data这个文件,然后复制到excel中,这个下载下来每一列是没有列名的,需要自己手动添加一下。如下图:

读取心脏病数据集
实验的环境是在jupyter notebook里面,可以及时进行交互,可以看到每一步的操作结果。(实验中会用到一些包,需要自己去下载)
import numpy as np
import pandas as pd
heart_dataset = pd.read_csv('newheart.csv')
print("Keys of heartstd_dataset: \n{}".format(heart_dataset.keys()))
读取数据集,然后输出数据集的属性名称。
对数据集中的缺失值进行处理
pd.set_option('display.max_rows',20) # 展示20行
heart_dataset
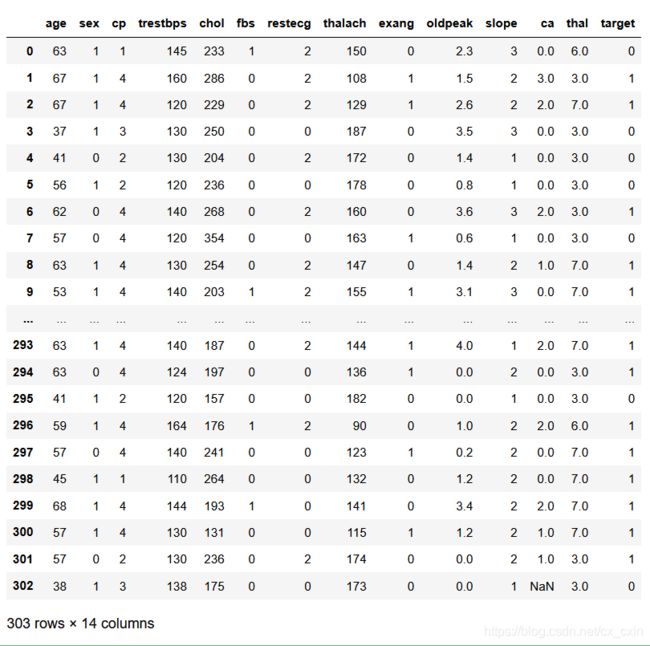 可以观察到最后一行,倒数第三个数是一个缺失值。下面用代码看看,这个数据集里面一共有多少个缺失值。
可以观察到最后一行,倒数第三个数是一个缺失值。下面用代码看看,这个数据集里面一共有多少个缺失值。
heart_dataset.isnull().sum() # 查看数据集是否有缺失值
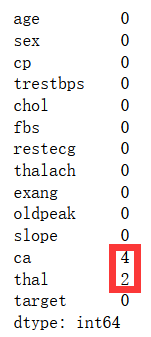
可以看到,一共有6个缺失值,对缺失值的补充要考虑属性,因为属性大多是类别的属性,所以对缺失值的处理就按照上一个值进行填充。代码如下:
## 使用上一个值替代
df=heart_dataset.fillna(method='ffill')
再使用代码查看是否有缺失值
df.isnull().sum() # 查看数据集是否有缺失值

如下代码可以查看数据集的属性:
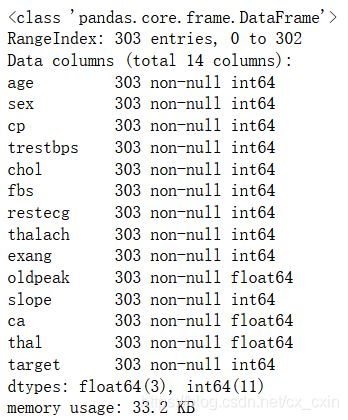
df.info()
结果如下图:
对数据集进行标准化处理
可以发现数据集的各个属性的类型不统一,通过一开始的查看数据集,可以发现数据的取值范围也不统一,为了模型的方便处理,接下来对数据集进行标准化处理。
#标准化处理数据集
from sklearn.preprocessing import StandardScaler
x=df[df.columns[0:13]].values #读取前13列的数据,并转换为array类型
x=StandardScaler().fit(x).transform(x) # 进行标准化处理
dfstd=pd.DataFrame(x) #把处理好的数据重新转为DataFrame类型
names=['age','sex','cp','trestbps','chol','fbs','restecg','thalach','exang','oldpeak','slope','ca','thal']
dfstd.columns=names #给标准化的数据添加列名
df['target'].replace([0,1],['no','yes'],inplace=True) #把target中的0替换为no,1替换为yes
dfstd['target']=df['target'] #把类别添加到标准化的数据集中
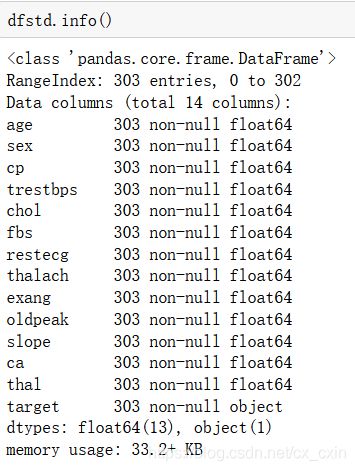
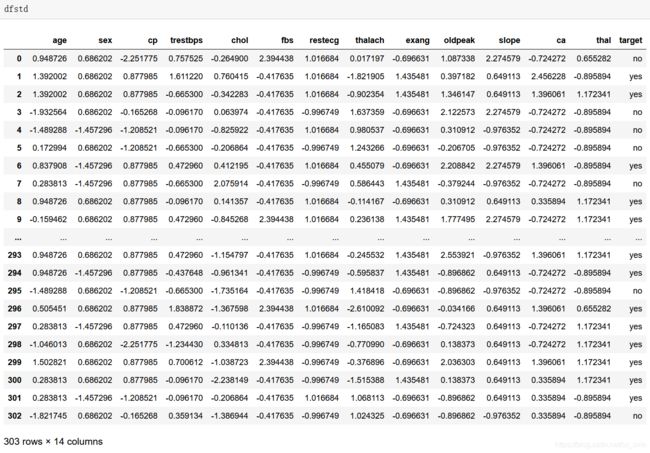
通过上图可以发现,数据集已经进行了标准化的处理。
主成分分析
在一个数据集有众多的属性的时候,必然会有一些属性是用处不大的,都代入模型中,可能会造成模型的过拟合现象和训练时间比较长。可以通过主成分分析来选择出影响比较大的属性。
##主成分分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.font_manager import FontProperties
plt.rcParams['font.sans-serif'] = ['simhei']
## 导入主成分库,并先选择所有主成分
from sklearn.decomposition import PCA
pca = PCA(n_components = x.shape[1])
## 训练数据
pca.fit(x)
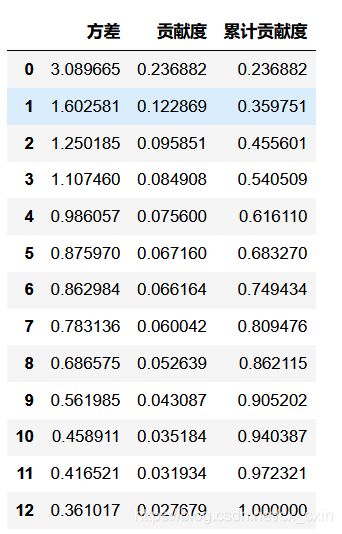
## 展示方差解释力度
pd.DataFrame({'方差': pca.explained_variance_,
'贡献度':pca.explained_variance_ratio_,
'累计贡献度':pca.explained_variance_ratio_.cumsum()})
plt.bar(range(13), pca.explained_variance_ratio_)
plt.title('贡献度');
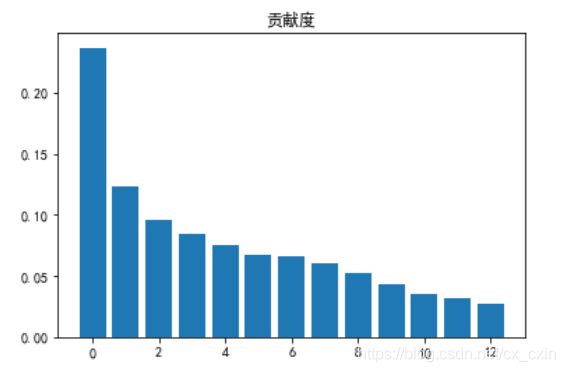
通过对上图的观察,可以发现各个属性相差不是很大,而且属性的个数也不是很大,就保留了所有属性代入到模型之中了。(读者可以自行选择属性的个数,进行对比试验)
把数据集切分成训练集和测试集
#把数据集处理为训练集和测试集
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
target_var = 'target'
features = list(dfstd.columns)
features.remove(target_var)
Class = dfstd[target_var].unique()
Class_dict = dict(zip(Class, range(len(Class))))
dfstd['target'] = dfstd[target_var].apply(lambda x: Class_dict[x])
lb = LabelBinarizer()
lb.fit(list(Class_dict.values()))
transformed_labels = lb.transform(dfstd['target'])
y_bin_labels = [] # 对多分类进行0-1编码的变量
for i in range(transformed_labels.shape[1]):
y_bin_labels.append('y' + str(i))
dfstd['y' + str(i)] = transformed_labels[:, i]
train_x, test_x, train_y, test_y = train_test_split(dfstd[features], dfstd[y_bin_labels],train_size=0.7, test_size=0.3, random_state=0)
数据集的70%是训练集,30%是测试集,并且打乱了顺序。
2、搭建模型
from tensorflow import keras as K
from tensorflow import keras
# 定义模型
init = K.initializers.glorot_uniform(seed=1)
simple_adam = K.optimizers.Adam()
METRICS = [
keras.metrics.TruePositives(name='tp'),
keras.metrics.FalsePositives(name='fp'),
keras.metrics.TrueNegatives(name='tn'),
keras.metrics.FalseNegatives(name='fn'),
keras.metrics.BinaryAccuracy(name='accuracy'),
keras.metrics.Precision(name='precision'),
keras.metrics.Recall(name='recall'),
keras.metrics.AUC(name='auc'),
]
model = K.models.Sequential()
model.add(K.layers.Dense(units=13, input_dim=13, kernel_initializer=init, activation='relu'))
model.add(K.layers.Dense(units=14, kernel_initializer=init, activation='relu'))
model.add(K.layers.Dense(units=10, kernel_initializer=init, activation='relu'))
model.add(K.layers.Dense(units=8, kernel_initializer=init, activation='relu'))
model.add(K.layers.Dense(units=6, kernel_initializer=init, activation='relu'))
model.add(K.layers.Dense(units=2, kernel_initializer=init, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy', optimizer=simple_adam, metrics=METRICS)
categorical_crossentropy为交叉熵损失函数,迭代的优化器(optimizer)选择Adam,metrics指定衡量模型的指标,最初各个层的连接权重(weights)和偏重(biases)是随机生成的.
Adam 这个名字来源于自适应矩估计(Adaptive Moment Estimation),也是梯度下降算法的一种变形,但是每次迭代参数的学习率都有一定的范围,不会因为梯度很大而导致学习率(步长)也变得很大,参数的值相对比较稳定。
3、训练模型
# 训练模型
b_size = 3
max_epochs = 200
print("Starting training ")
h = model.fit(train_x, train_y, batch_size=b_size, epochs=max_epochs, shuffle=True, verbose=1,validation_data=(test_x, test_y))
print("Training finished \n")
batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
epochs:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置initial_epoch时,它就是训练的总轮数,否则训练的总轮数为epochs - inital_epoch
shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录。
validation_data:指定前面切分出来的验证集
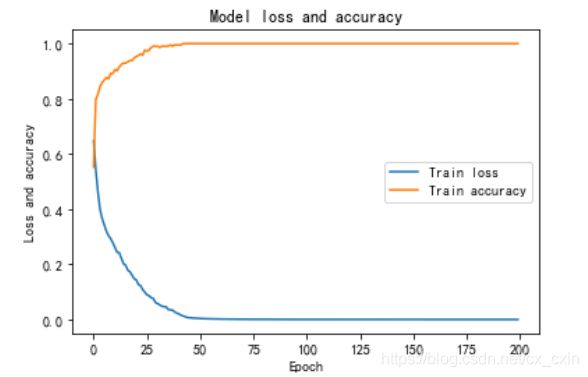
绘制训练集的损失和准确率
# 绘制训练集的损失和准确率
plt.plot(h.history['loss'])
plt.plot(h.history['accuracy'])
plt.title('Model loss and accuracy')
plt.ylabel('Loss and accuracy')
plt.xlabel('Epoch')
plt.legend(['Train loss', 'Train accuracy'], loc='center right')
plt.show()
4、模型评估
# 评估模型
eval = model.evaluate(test_x, test_y, verbose=0)
print("Evaluation on test data: loss = %0.6f accuracy = %0.2f%% \n" % (eval[0], eval[1] * 100) )
输出为:Evaluation on test data: loss = 5.551485 accuracy = 79.12%
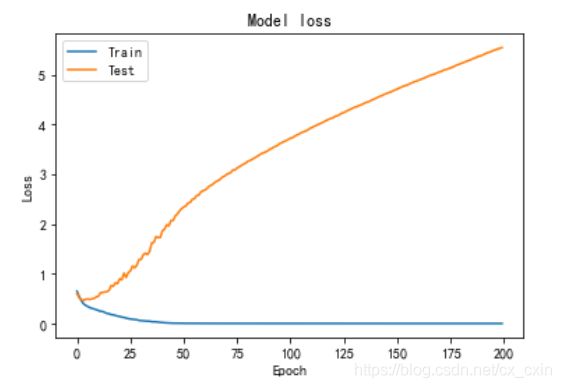
训练集和测试集的损失和准确率
# 绘制训练 & 验证的损失值
plt.plot(h.history['loss'])
plt.plot(h.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
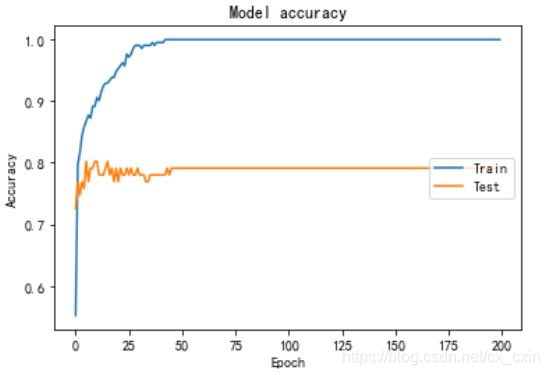
# 绘制训练 & 验证的准确率
plt.plot(h.history['accuracy'])
plt.plot(h.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='center right')
plt.show()
混淆矩阵
pred_y=model.predict(test_x,batch_size=b_size)
for i in range(len(pred_y)):
max_value=max(pred_y[i])
for j in range(len(pred_y[i])):
if max_value==pred_y[i][j]:
pred_y[i][j]=1
else:
pred_y[i][j]=0
pred=[0. for x in range(len(pred_y))]
for i in range(len(pred_y)):
if pred_y[i][0]==0:
pred[i]=1
else:
pred[i]=0
from sklearn.metrics import classification_report
print(classification_report(test_y,pred))
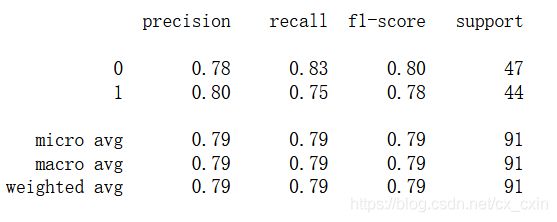
准确率Accuracy:通俗地说就是所有样本被正确预测的占比。
精确率Precison:通俗地说就是预测为正类的样本中,实际为正类的占比。
召回率Recall:通俗地说就是实际为正类的样本中,正确预测为正类的占比。
F1得分F-Measure:F1相当于精确率和召回率的调和平均数
绘制ROC曲线&AUC面积
from sklearn.metrics import roc_curve, auc ###计算roc和auc
fpr,tpr,threshold = roc_curve(test_y, pred)
roc_auc = auc(fpr,tpr) ###计算auc的值
plt.figure()
lw = 2
plt.figure(figsize=(10,10))
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc) ###假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
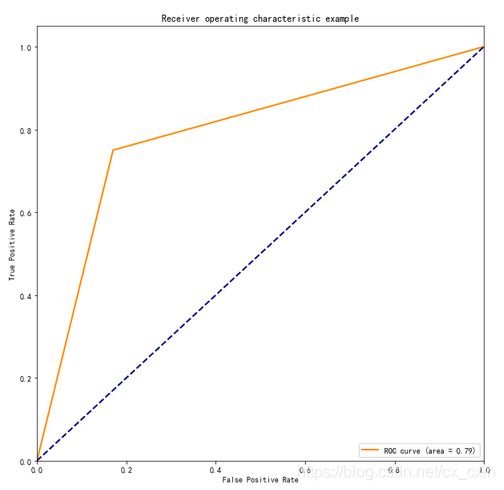
TPR—真阳性,同召回率
FPR—假阳性,负样本中错误预测为正的占比
二分类模型返回一个概率值,通过调整阈值,即大于该阈值为正类,反之负类,可以得到多个(FPR,TPR)点,描点画图得到的曲线即为ROC曲线。
AUC为ROC曲线下的面积,越接近1说明分类效果越好。
5、总结
模型最后的效果可能不是很好,造成这样的原因一般是数据集比较少,或者神经网络的结构不太合适。对于分类任务也可以使用其他的机器学习算法(决策树、贝叶斯网络、支持向量机等)。