【C】指针与结构体---初阶
✨博客主页:心辛向荣
✨系列专栏:【从0到1,C语言学习】
✨一句短话:你若盛开,蝴蝶自来!
✨博客说明:尽己所能,把每一篇博客写好,帮助自己熟悉所学知识,也希望自己的这些内容可以帮助到一些在学习路上的伙伴,文章中如果发现错误及不足之处,还望在评论区留言,我们一起交流进步!


前言
这篇博客总结指针与结构体的基本知识和用法,较为基础,这篇博客可以让你搞明白这些知识,并可以初步在一些场景下应用。
之后还会更新对于结构体和指针部分的深入理解与应用。
对于这部分内容一些更为基础的介绍和理解可以看我的另一篇博客找到对应部分 C语言入门——带你从0开始 。
目录
一.指针
——1. 指针是什么
——2. 指针类型与其意义
——3. 野指针
——4. 指针运算
——5. 通过指针访问数组
——6. 二级指针
——7. 指针数组
——8. 对于指针类型 type*中 * 和type的理解
二.结构体
——1. 结构体的声明、定义、初始化
——2. 结构体成员的访问
——3. 结构体传参
一.指针
1.指针是什么!
指针理解的2个要点:
- 指针是内存中一个最小单元的编号,也就是地址
- 平时口语中说的指针,通常指的是指针变量,是用来存放内存地址的变量
总结:指针就是地址,口语中说的指针通常指的是指针变量,指针变量用来存放地址(指针)。
结合以下进行理解:
计算机当中的内存,

指针变量:
我们可以通过&(取地址操作符)取出变量的内存(其实是地址),把地址可以存放到一个变量中,这个变量就是指针变量
#include指针(指针变量)是用来存放地址的(存放在指针中的值都被当成地址处理),地址是唯一标示一块地址空间的;
指针的大小取决于这个地址的大小,在32位平台是4个字节,在64位平台是8个字节。
2. 指针类型与其意义
我们都知道,变量有不同的类型,整形,浮点型等;同样的指针也是有类型的。
指针变量的类型是要与其解引用之后所指向的变量相对应的,如:
int num = 10;
p = #
这里的p就是一个指针变量,我们这里给出其相对应的类型
int* p = &num
指针的定义方式是: type + *
char * 类型的指针是为了存放 char 类型变量的地址。
short * 类型的指针是为了存放 short 类型变量的地址。
int * 类型的指针是为了存放 int 类型变量的地址。
char *pc = NULL;
int *pi = NULL;
short *ps = NULL;
long *pl = NULL;
float *pf = NULL;
double *pd = NULL;
下面刨析指针类型的意义,结合代码分析;
对比第一组:
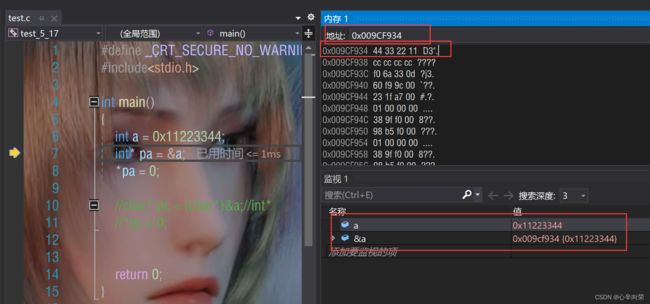
改变了四个字节的内容!
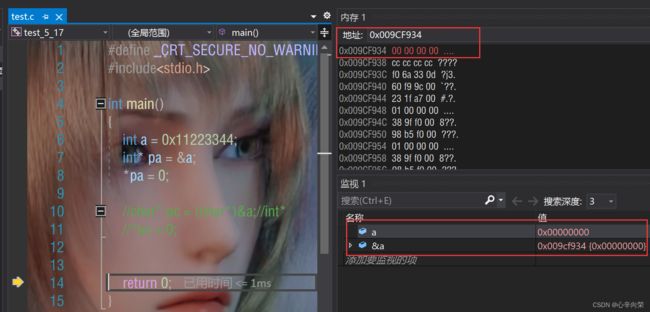
对比第二组:
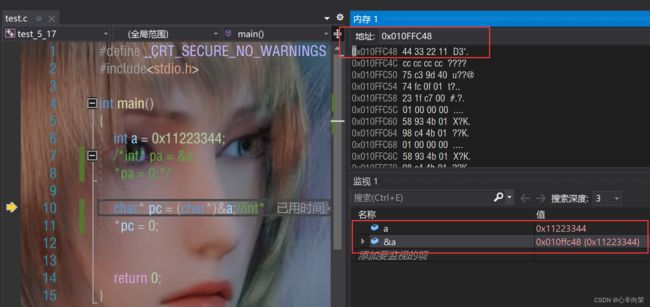
只改变了一个字节的内容。
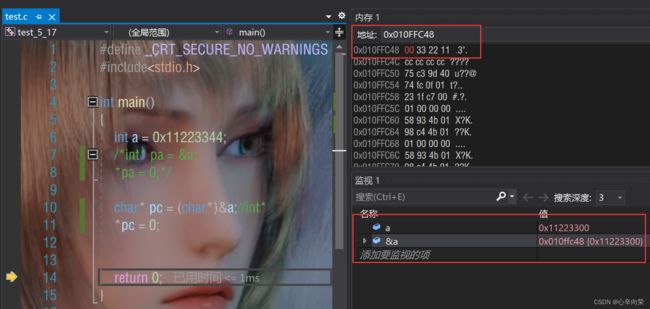
结论1:
指针的类型决定了,对指针解引用的时候有多大的权限(能操作几个字节)。
如果是int的指针,解引用访问4个字节。
如果是char的指针,解引用访问1个字节。
推广到其他类型类似。
再看下面代码的效果!
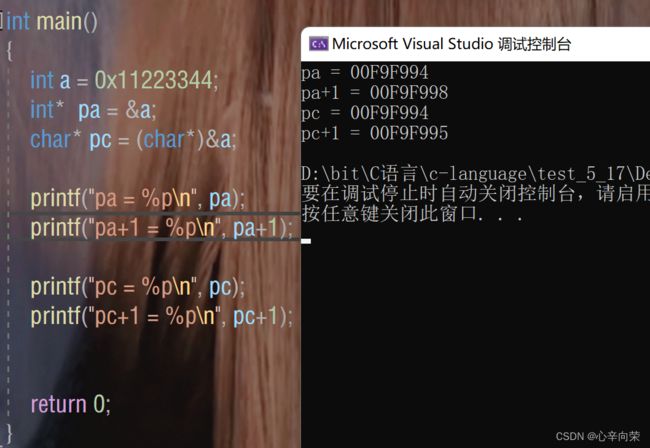
结论2:
指针的类型决定了指针±1操作的时候,跳过几个字节。
也就是类型决定了指针的步长。
有人可能还有一个疑问,当类型不同但它们访问的权限是一样的,对它们解引用可不可以得到相同的效果?
对比可以发现当类型相对应的时候,可以实现改变a的值,当不对应时就出问题了,所以区分不同的指针类型还是非常重要的!
3.野指针
概念: 野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的),也就是对指针解引用其指向的空间不在给程序分配的范围内。
野指针成因
- 指针未初始化
2. 指针越界访问
- 指针指向的空间释放

如何规避野指针
- 指针初始化(赋为空指针)
- 小心指针越界
- 指针指向空间释放即使置NULL
- 避免返回局部变量的地址
- 指针使用之前检查有效性
4. 指针运算
指针±整数
上面在解释指针类型的意义时进行的就是 指针±整数 的运算,不局限于1,可以±更大的数,但要时刻注意出现野指针的情况!
指针-指针
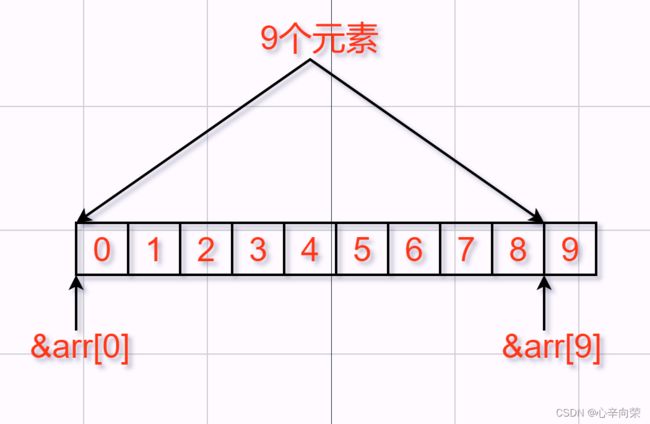
指针-指针求出的是俩个指针之间元素的个数!

要注意指针 - 指针得有意义才行,也就是俩个指针在同一片空间内,否则计算是没有意义的,比如下面这个错误示范,它的计算结果毫无意义。

用指针 - 指针的方式实现模拟strlen函数!
int my_strlen(char* str)
{
char* start = str;
while (*str != '\0')
{
str++;
}
return (str - start);
}
int main()
{
int len = my_strlen("abcdef");
printf("%d\n", len);
return 0;
}
指针的关系运算
#define _CRT_SECURE_NO_WARNINGS 1
#define N_VALUES 5
int main()
{
float values[N_VALUES];
float* vp;
//指针+-整数;指针的关系运算
for (vp = &values[0]; vp < &values[N_VALUES];)
{//将数组中的元素都赋为0
*vp++ = 0;
}
return 0;
}
代码简化, 这将代码修改如下:
for(vp = &values[N_VALUES-1]; vp >= &values[0];vp--)
{
*vp = 0;
}
实际在绝大部分的编译器上是可以顺利完成任务的,然而我们还是应该避免这样写,因为标准并不保证它可行。
标准规定:
允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较,但是不允许与指向第一个元素之前的那个内存位置的指针进行比较。
5. 通过指针访问数组
把数组名当成地址存放到一个指针中,我们使用指针来访问一个数组。
看下面俩种写法其实是等价的!
#include6. 二级指针
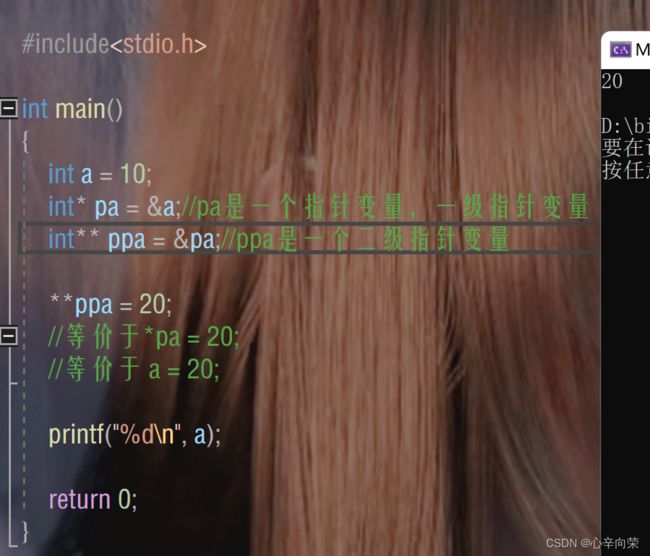
指针变量也是变量,是变量就有地址,而指针变量的地址再存放在指针变量中,这就是二级指针 。
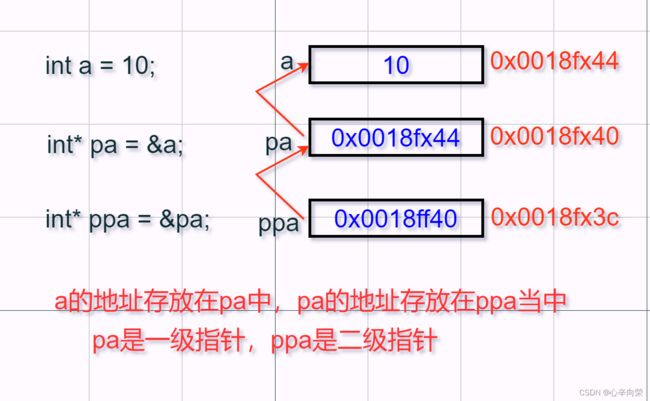
*ppa 通过对ppa中的地址进行解引用,这样找到的是 pa , *ppa 其实访问的就是 pa ;**ppa 先通过 *ppa 找到 pa ,然后对 pa 进行解引用操作: *pa ,那找到的是 a .
7. 指针数组
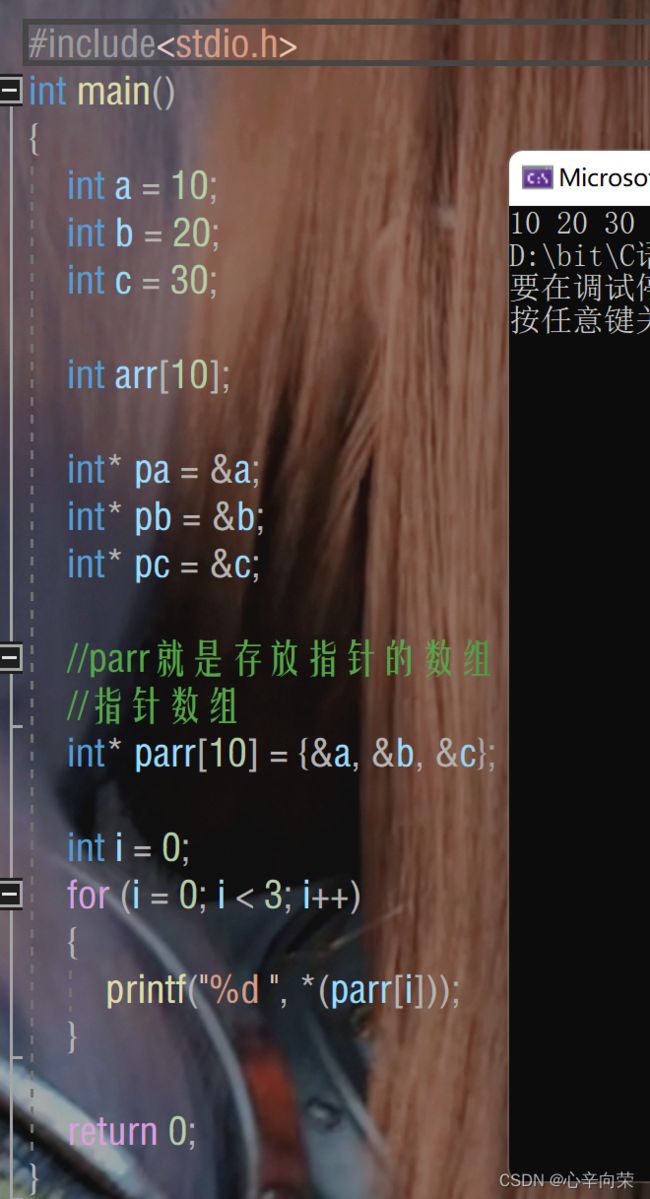
存放指针的数组就是指针数组。
int* arr3[5];
arr3是一个数组,有五个元素,每个元素是一个整形指针。
代码实例:
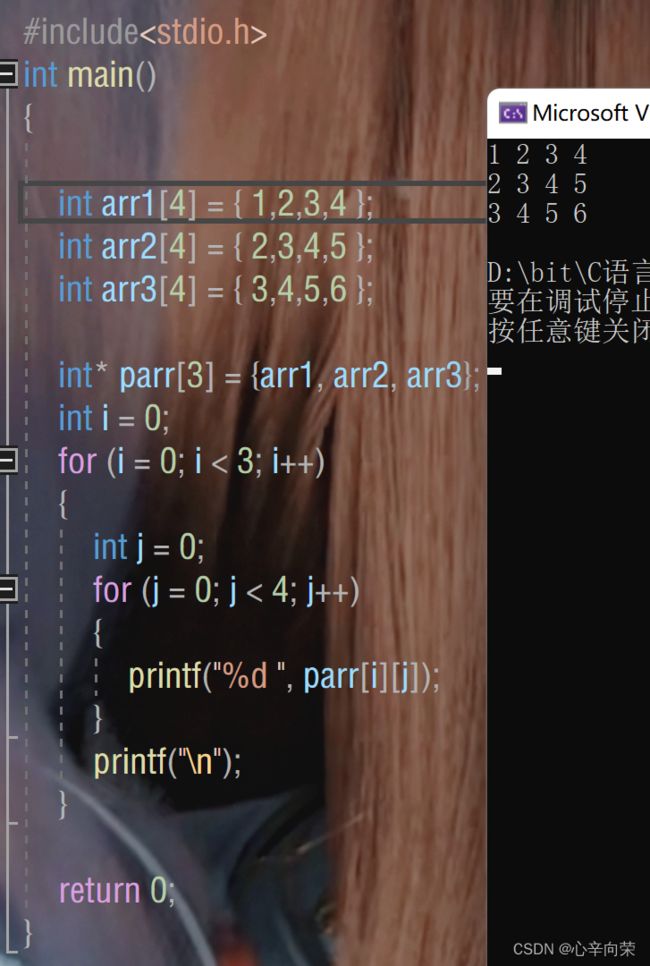
下面用指针数组模拟实现一个二维数组!
8. 对于指针类型 type*中 * 和type的理解
一级指针
比如:int* pa = &a;
这里的 * 表名p是一个指针变量,而int表明对pa解引用后,* pa指向的的对象是int类型的。
二级指针
比如:int** ppa = &pa;
从左往右数,第二颗 * 表明ppa是一个指针变量,而而int * 表明对ppa解引用后,* ppa指向的的对象是 int * 类型的。
如果往后延伸还有三级、四级指针等…同样这样理解,但这些n级指针一般是用不到的。
二.结构体
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。结构体用来描述一个复杂对象,比如一个人的各种信息、一本书的各项说明…
1. 结构体的声明、定义、初始化
结构的声明
struct tag
{
member-list;
}variable-list;
这里的struct tag就是声明的一个结构体类型!
例如描述一个人的信息:
struct Peo
{
char name[20];//姓名
char tele[12];//电话
char sex[5];//性别:女/男/保密
int high;//身高
}p1, p2;//p1和p2是两个全局的结构体变量
//分号不能丢
结构成员的类型
结构的成员可以是标量、数组、指针,甚至是其他结构体。
struct Peo
{
char name[20];
char tele[12];
char sex[5];
int high;
}p3, p4;
struct St
{
struct Peo p;//结构成员为结构体
int num;
float f;
};
结构体变量的定义和初始化
struct Point
{
int x;
int y;
}p1; //声明类型的同时定义变量p1
struct Point p2; //定义结构体变量p2
//初始化:定义变量的同时赋初值。
struct Point p3 = { x, y };
struct Stu //类型声明
{
char name[15];//名字
int age; //年龄
};
struct Stu s = { "zhangsan", 20 };//初始化
struct Node
{
int data;
struct Point p;
struct Node* next;
}n1 = { 10, {4,5}, NULL }; //结构体嵌套初始化
struct Node n2 = { 20, {5, 6}, NULL };//结构体嵌套初始化
2. 结构体成员的访问
结构体变量访问成员
结构变量的成员是通过点操作符(.)访问的。
点操作符接受两个操作数。

结构体指针访问指向变量的成员
有时候我们得到的不是一个结构体变量,而是指向一个结构体的指针;可以通过对指针解引用在使用 . 操作符,或者使用 -> 操作符!
3. 结构体传参
#include其实在我们写代码的过程中,一般采用的是print2函数这种写法;
函数传参的时候,参数是需要压栈的,如果这里有疑惑,可以看一看我的另一篇博客 关于函数栈帧
如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。
所以哦,结构体传参的时候,一般传结构体的地址。
结语
各位小伙伴,看到这里就是缘分嘛,希望我的这些内容可以给你带来那么一丝丝帮助,可以的话三连支持一下呗(关注✌️点赞✌️评论✌️)!!!
感谢每一位走到这里的小伙伴,我们可以一起学习交流,一起进步!!!加油!!!
