PPv3-OCR自定义数据从训练到部署
PPv3-OCR自定义数据从训练到部署
- 一、配置Paddle环境
- 二、配置PaddleOCR
-
- 1、安装python包
- 2、测试环境
- 三 模型列表及其对应的配置文件
-
- 1. 文本检测模型
-
- 1.1 中文检测模型
- 1.2 英文检测模型
- 1.3 多语言检测模型
- 2. 文本识别模型
-
- 2.1 中文识别模型
- 2.2 英文识别模型
- 2.3 多语言识别模型(更多语言持续更新中...)
- 3. 文本方向分类模型
- 四、标注工具PPOCRLabel
-
- 1. 安装与运行
-
- 1.1 安装PaddlePaddle
- 1.2 安装与运行PPOCRLabel
-
- 1.2.1 通过whl包安装与运行
-
- Windows
- Ubuntu Linux
- MacOS
- 1.2.2 本地构建whl包并安装
- 1.2.3 通过Python脚本运行PPOCRLabel
- 2. 使用
-
- 2.1 操作步骤
- 2.2 注意
- 3. 说明
-
- 3.1 快捷键
- 3.2 内置模型
- 3.3 导出标记结果
- 3.4 导出部分识别结果
- 3.5 数据集划分
- 3.6 错误提示
- 五、训练检测器
-
- 1、制作数据集
- 2、下载预训练模型
- 3、修改配置文件
- 4、开启训练
-
- 4.1、 断点训练
- 4.2 混合精度训练
- 4.3 分布式训练
- 5、 模型评估与预测
- 5.1 指标评估
- 5.2 测试检测效果
- 6. 模型导出与预测
- 五、训练识别器
-
- 1、图片裁剪与数据集生成
- 2、修改配置文件
- 3、开启训练
- 3.1、 断点训练
- 3.2、 混合精度训练
- 3.3、 分布式训练
- 4 模型评估与预测
- 4.1、指标评估
- 4.2、测试识别效果
- 4. 模型导出与预测
- 六、hubserving部署
-
- 1、准备环境
- 2、安装服务模块
- 3、启动服务
-
- 3.1. 命令行命令启动(仅支持CPU,不推荐)
- 3.2、 配置文件启动(支持CPU、GPU)
- 4、 发送预测请求
- 5、 返回结果格式说明
最近一段时间使用PaddleOCR做了一个OCR相关的项目,本文记录一下项目的实现过程。由于数据集是公司的真是数据,不方便公开,我从网上搜集了一些数据集,给大家做演示。PaddleOCR用的最新的PaddleOCR-release-2.5,模型用的v3模型。
一、配置Paddle环境
创建虚拟环境
conda create --name pp python=3.7
创建完成后激活环境
conda activate pp

登录飞桨的官网下载最新的paddle,官网地址:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
选择合适的CUDA版本,然后会在下面生成对应的命令。
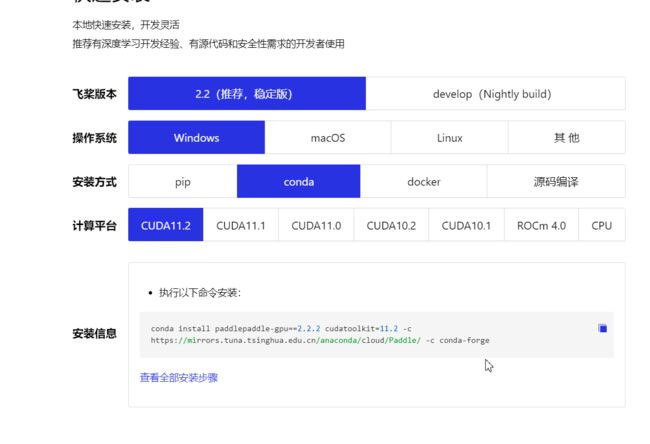
然后,复制命令即可
conda install paddlepaddle-gpu==2.2.2 cudatoolkit=11.2 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
二、配置PaddleOCR
下载地址:(https://gitee.com/paddlepaddle/PaddleOCR
将其下载到本地,然后解压配置环境。
1、安装python包
1、yaml
pip install pyyaml
2、imgaug
pip install imgaug
3、pyclipper
pip install pyclipper
4、lmdb
pip install lmdb
5、Levenshtein
pip install Levenshtein
6、tqdm
pip install tqdm
2、测试环境
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|---|---|---|---|---|---|
| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 预训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 |
| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 |
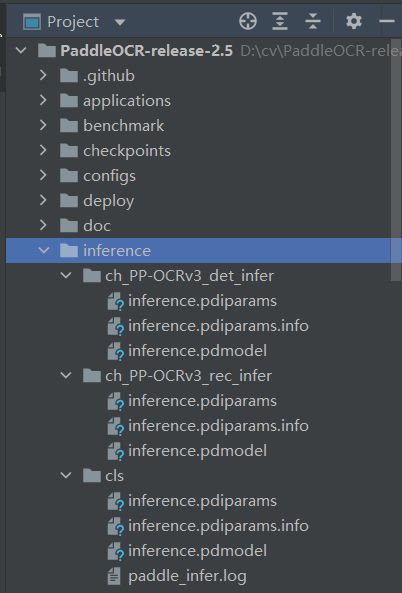
选择上面的一组模型放入到inference文件夹中,注意:是一组,包括:监测模型、方向分类器、识别模型。如下:
PaddleOCR-release-2.5
└─inference
├─ch_PP-OCRv3_det_infer #检测模型
│ ├─inference.pdiparams
│ ├─inference.pdiparams.info
│ └─inference.pdmodel
├─ch_PP-OCRv3_rec_infer #识别模型
│ ├─inference.pdiparams
│ ├─inference.pdiparams.info
│ └─inference.pdmodel
└─cls #方向分类器
├─inference.pdiparams
├─inference.pdiparams.info
└─inference.pdmodel
将待检测的图片放在./doc/imgs/文件夹下面,然后执行命令:
python tools/infer/predict_system.py --image_dir="./doc/imgs/0.jpg" --det_model_dir="./inference/ch_PP-OCRv3_det_infer/" --cls_model_dir="./inference/cls/" --rec_model_dir="./inference/ch_PP-OCRv3_rec_infer/" --use_angle_cls=true
然后在inference_results文件夹中查看结果,例如:
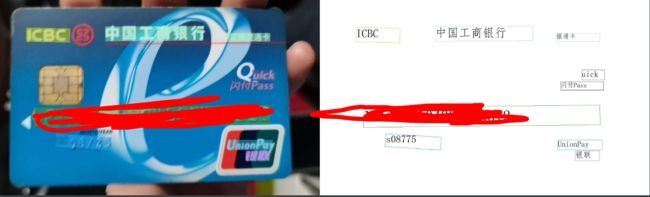
如果能看到结果就说明环境是ok的。
更多的命令,如下:
# 使用方向分类器
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --cls_model_dir="./cls/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=true --rec_image_shape=3,48,320
# 不使用方向分类器
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=false --rec_image_shape=3,48,320
# 使用多进程
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=false --use_mp=True --total_process_num=6 --rec_image_shape=3,48,320
也可以新建test.py脚本进行测试,系统会自动下载预训练模型,代码如下:
import cv2
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './doc/imgs_en/img_10.jpg'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
# 显示结果
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
开始运行:

红框的位置显示了详细的配置信息。
查看结果:

ocr.ocr(img_path, cls=True)这个方法不仅支持传入图片的路径,还支持ndarray和list类型。比如传入ndarray
import cv2
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './doc/imgs_en/img_10.jpg'
# 第一种使用读入图片转为ndarray
from PIL import Image
import numpy as np
img = Image.open(img_path)
img = np.array(img)
result = ocr.ocr(img, cls=True)
# 第二种使用cv2读入图片。
img=cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
result = ocr.ocr(img, cls=True)
上面这两种方式都是可以的,大家自行尝试。
三 模型列表及其对应的配置文件
1. 文本检测模型
1.1 中文检测模型
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| ch_PP-OCRv3_det_slim | 【最新】slim量化+蒸馏版超轻量模型,支持中英文、多语种文本检测 | [ch_PP-OCRv3_det_cml.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml) | 1.1M | 推理模型 / 训练模型 / nb模型 |
| ch_PP-OCRv3_det | 【最新】原始超轻量模型,支持中英文、多语种文本检测 | [ch_PP-OCRv3_det_cml.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml) | 3.8M | 推理模型 / 训练模型 |
| ch_PP-OCRv2_det_slim | slim量化+蒸馏版超轻量模型,支持中英文、多语种文本检测 | [ch_PP-OCRv2_det_cml.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml) | 3M | 推理模型 |
| ch_PP-OCRv2_det | 原始超轻量模型,支持中英文、多语种文本检测 | [ch_PP-OCRv2_det_cml.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml) | 3M | 推理模型 / 训练模型 |
| ch_ppocr_mobile_slim_v2.0_det | slim裁剪版超轻量模型,支持中英文、多语种文本检测 | [ch_det_mv3_db_v2.0.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml) | 2.6M | 推理模型 |
| ch_ppocr_mobile_v2.0_det | 原始超轻量模型,支持中英文、多语种文本检测 | [ch_det_mv3_db_v2.0.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml) | 3M | 推理模型 / 训练模型 |
| ch_ppocr_server_v2.0_det | 通用模型,支持中英文、多语种文本检测,比超轻量模型更大,但效果更好 | [ch_det_res18_db_v2.0.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml) | 47M | 推理模型 / 训练模型 |
1.2 英文检测模型
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| en_PP-OCRv3_det_slim | 【最新】slim量化版超轻量模型,支持英文、数字检测 | [ch_PP-OCRv3_det_cml.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml) | 1.1M | 推理模型 / 训练模型 / nb模型 |
| en_PP-OCRv3_det | 【最新】原始超轻量模型,支持英文、数字检测 | [ch_PP-OCRv3_det_cml.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml) | 3.8M | 推理模型 / 训练模型 |
- 注:英文检测模型与中文检测模型结构完全相同,只有训练数据不同,在此仅提供相同的配置文件。
1.3 多语言检测模型
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| ml_PP-OCRv3_det_slim | 【最新】slim量化版超轻量模型,支持多语言检测 | [ch_PP-OCRv3_det_cml.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml) | 1.1M | 推理模型 / 训练模型 / nb模型 |
| ml_PP-OCRv3_det | 【最新】原始超轻量模型,支持多语言检测 | [ch_PP-OCRv3_det_cml.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml) | 3.8M | 推理模型 / 训练模型 |
- 注:多语言检测模型与中文检测模型结构完全相同,只有训练数据不同,在此仅提供相同的配置文件。
2. 文本识别模型
2.1 中文识别模型
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| ch_PP-OCRv3_rec_slim | 【最新】slim量化版超轻量模型,支持中英文、数字识别 | [ch_PP-OCRv3_rec_distillation.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml) | 4.9M | 推理模型 / 训练模型 / nb模型 |
| ch_PP-OCRv3_rec | 【最新】原始超轻量模型,支持中英文、数字识别 | [ch_PP-OCRv3_rec_distillation.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml) | 12.4M | 推理模型 / 训练模型 |
| ch_PP-OCRv2_rec_slim | slim量化版超轻量模型,支持中英文、数字识别 | [ch_PP-OCRv2_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml) | 9M | 推理模型 / 训练模型 |
| ch_PP-OCRv2_rec | 原始超轻量模型,支持中英文、数字识别 | [ch_PP-OCRv2_rec_distillation.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml) | 8.5M | 推理模型 / 训练模型 |
| ch_ppocr_mobile_slim_v2.0_rec | slim裁剪量化版超轻量模型,支持中英文、数字识别 | [rec_chinese_lite_train_v2.0.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml) | 6M | 推理模型 / 训练模型 |
| ch_ppocr_mobile_v2.0_rec | 原始超轻量模型,支持中英文、数字识别 | [rec_chinese_lite_train_v2.0.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml) | 5.2M | 推理模型 / 训练模型 / 预训练模型 |
| ch_ppocr_server_v2.0_rec | 通用模型,支持中英文、数字识别 | [rec_chinese_common_train_v2.0.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml) | 94.8M | 推理模型 / 训练模型 / 预训练模型 |
说明: 训练模型是基于预训练模型在真实数据与竖排合成文本数据上finetune得到的模型,在真实应用场景中有着更好的表现,预训练模型则是直接基于全量真实数据与合成数据训练得到,更适合用于在自己的数据集上finetune。
2.2 英文识别模型
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| en_PP-OCRv3_rec_slim | 【最新】slim量化版超轻量模型,支持英文、数字识别 | [en_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml) | 3.2M | 推理模型 / 训练模型 / nb模型 |
| en_PP-OCRv3_rec | 【最新】原始超轻量模型,支持英文、数字识别 | [en_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml) | 9.6M | 推理模型 / 训练模型 |
| en_number_mobile_slim_v2.0_rec | slim裁剪量化版超轻量模型,支持英文、数字识别 | [rec_en_number_lite_train.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/multi_language/rec_en_number_lite_train.yml) | 2.7M | 推理模型 / 训练模型 |
| en_number_mobile_v2.0_rec | 原始超轻量模型,支持英文、数字识别 | [rec_en_number_lite_train.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/multi_language/rec_en_number_lite_train.yml) | 2.6M | 推理模型 / 训练模型 |
2.3 多语言识别模型(更多语言持续更新中…)
| 模型名称 | 字典文件 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|---|
| korean_PP-OCRv3_rec | ppocr/utils/dict/korean_dict.txt | 韩文识别 | [korean_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/multi_language/korean_PP-OCRv3_rec.yml) | 11M | 推理模型 / 训练模型 |
| japan_PP-OCRv3_rec | ppocr/utils/dict/japan_dict.txt | 日文识别 | [japan_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/multi_language/japan_PP-OCRv3_rec.yml) | 11M | 推理模型 / 训练模型 |
| chinese_cht_PP-OCRv3_rec | ppocr/utils/dict/chinese_cht_dict.txt | 中文繁体识别 | [chinese_cht_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/multi_language/chinese_cht_PP-OCRv3_rec.yml) | 12M | 推理模型 / 训练模型 |
| te_PP-OCRv3_rec | ppocr/utils/dict/te_dict.txt | 泰卢固文识别 | [te_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/multi_language/te_PP-OCRv3_rec.yml) | 9.6M | 推理模型 / 训练模型 |
| ka_PP-OCRv3_rec | ppocr/utils/dict/ka_dict.txt | 卡纳达文识别 | [ka_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/multi_language/ka_PP-OCRv3_rec.yml) | 9.9M | 推理模型 / 训练模型 |
| ta_PP-OCRv3_rec | ppocr/utils/dict/ta_dict.txt | 泰米尔文识别 | [ta_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/multi_language/ta_PP-OCRv3_rec.yml) | 9.6M | 推理模型 / 训练模型 |
| latin_PP-OCRv3_rec | ppocr/utils/dict/latin_dict.txt | 拉丁文识别 | [latin_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/multi_language/latin_PP-OCRv3_rec.yml) | 9.7M | 推理模型 / 训练模型 |
| arabic_PP-OCRv3_rec | ppocr/utils/dict/arabic_dict.txt | 阿拉伯字母 | [arabic_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/multi_language/rec_arabic_lite_train.yml) | 9.6M | 推理模型 / 训练模型 |
| cyrillic_PP-OCRv3_rec | ppocr/utils/dict/cyrillic_dict.txt | 斯拉夫字母 | [cyrillic_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/multi_language/cyrillic_PP-OCRv3_rec.yml) | 9.6M | 推理模型 / 训练模型 |
| devanagari_PP-OCRv3_rec | ppocr/utils/dict/devanagari_dict.txt | 梵文字母 | [devanagari_PP-OCRv3_rec.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/rec/PP-OCRv3/multi_language/devanagari_PP-OCRv3_rec.yml) | 9.9M | 推理模型 / 训练模型 |
查看完整语种列表与使用教程请参考: [多语言模型](file:/D:/cv/PaddleOCR-release-2.5/doc/doc_ch/multi_languages.md)
3. 文本方向分类模型
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| ch_ppocr_mobile_slim_v2.0_cls | slim量化版模型,对检测到的文本行文字角度分类 | [cls_mv3.yml](file:/D:/cv/PaddleOCR-release-2.5/configs/cls/cls_mv3.yml) | 2.1M | 推理模型 / 训练模型 / nb模型 |
| ch_ppocr_mobile_v2.0_cls | 原始分类器模型,对检测到的文本行文字角度分类 |
四、标注工具PPOCRLabel
PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注和四点标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
由于PaddleOCR已经包含PPOCRLabel,可以直接运行,命令如下:
cd ./PPOCRLabel # 切换到PPOCRLabel目录
python PPOCRLabel.py --lang ch

点击自动标注后就能看到自动标注的结果,用户根据自己的需求微调和修改,非常简单。
如果标注的结果和自己预想的差别比较大,可以在标注一定量的数据集后,使用标注的数据集训练出来一个模型,用来替换官方的模型。模型位置:

上图是我的模型的位置,大家可以试着找找自己模型的位置。
更多的方式和注意事项,详见下面
1. 安装与运行
1.1 安装PaddlePaddle
pip3 install --upgrade pip
# 如果您的机器安装的是CUDA9或CUDA10,请运行以下命令安装
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
# 如果您的机器是CPU,请运行以下命令安装
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
更多的版本需求,请参照安装文档中的说明进行操作。
1.2 安装与运行PPOCRLabel
PPOCRLabel可通过whl包与Python脚本两种方式启动,whl包形式启动更加方便,python脚本启动便于二次开发
1.2.1 通过whl包安装与运行
Windows
pip install PPOCRLabel # 安装
PPOCRLabel --lang ch # 运行
注意:通过whl包安装PPOCRLabel会自动下载
paddleocrwhl包,其中shapely依赖可能会出现[winRrror 126] 找不到指定模块的问题。的错误,建议从这里下载并安装
Ubuntu Linux
pip3 install PPOCRLabel
pip3 install trash-cli
PPOCRLabel --lang ch
MacOS
pip3 install PPOCRLabel
pip3 install opencv-contrib-python-headless==4.2.0.32 # 如果下载过慢请添加"-i https://mirror.baidu.com/pypi/simple"
PPOCRLabel --lang ch # 启动
如果上述安装出现问题,可以参考3.6节 错误提示
1.2.2 本地构建whl包并安装
cd PaddleOCR/PPOCRLabel
python3 setup.py bdist_wheel
pip3 install dist/PPOCRLabel-1.0.2-py2.py3-none-any.whl -i https://mirror.baidu.com/pypi/simple
1.2.3 通过Python脚本运行PPOCRLabel
如果您对PPOCRLabel文件有所更改,通过Python脚本运行会更加方面的看到更改的结果
cd ./PPOCRLabel # 切换到PPOCRLabel目录
python PPOCRLabel.py --lang ch
2. 使用
2.1 操作步骤
- 安装与运行:使用上述命令安装与运行程序。
- 打开文件夹:在菜单栏点击 “文件” - “打开目录” 选择待标记图片的文件夹[1].
- 自动标注:点击 ”自动标注“,使用PPOCR超轻量模型对图片文件名前图片状态[2]为 “X” 的图片进行自动标注。
- 手动标注:点击 “矩形标注”(推荐直接在英文模式下点击键盘中的 “W”),用户可对当前图片中模型未检出的部分进行手动绘制标记框。点击键盘Q,则使用四点标注模式(或点击“编辑” - “四点标注”),用户依次点击4个点后,双击左键表示标注完成。
- 标记框绘制完成后,用户点击 “确认”,检测框会先被预分配一个 “待识别” 标签。
- 重新识别:将图片中的所有检测画绘制/调整完成后,点击 “重新识别”,PPOCR模型会对当前图片中的所有检测框重新识别[3]。
- 内容更改:双击识别结果,对不准确的识别结果进行手动更改。
- 确认标记:点击 “确认”,图片状态切换为 “√”,跳转至下一张。
- 删除:点击 “删除图像”,图片将会被删除至回收站。
- 导出结果:用户可以通过菜单中“文件-导出标记结果”手动导出,同时也可以点击“文件 - 自动导出标记结果”开启自动导出。手动确认过的标记将会被存放在所打开图片文件夹下的Label.txt中。在菜单栏点击 “文件” - "导出识别结果"后,会将此类图片的识别训练数据保存在crop_img文件夹下,识别标签保存在rec_gt.txt中[4]。
2.2 注意
[1] PPOCRLabel以文件夹为基本标记单位,打开待标记的图片文件夹后,不会在窗口栏中显示图片,而是在点击 “选择文件夹” 之后直接将文件夹下的图片导入到程序中。
[2] 图片状态表示本张图片用户是否手动保存过,未手动保存过即为 “X”,手动保存过为 “√”。点击 “自动标注”按钮后,PPOCRLabel不会对状态为 “√” 的图片重新标注。
[3] 点击“重新识别”后,模型会对图片中的识别结果进行覆盖。因此如果在此之前手动更改过识别结果,有可能在重新识别后产生变动。
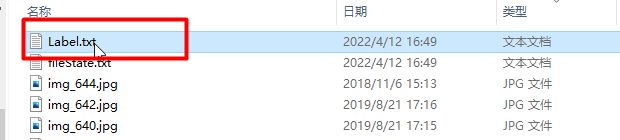
[4] PPOCRLabel产生的文件放置于标记图片文件夹下,包括一下几种,请勿手动更改其中内容,否则会引起程序出现异常。
| 文件名 | 说明 |
|---|---|
| Label.txt | 检测标签,可直接用于PPOCR检测模型训练。用户每确认5张检测结果后,程序会进行自动写入。当用户关闭应用程序或切换文件路径后同样会进行写入。 |
| fileState.txt | 图片状态标记文件,保存当前文件夹下已经被用户手动确认过的图片名称。 |
| Cache.cach | 缓存文件,保存模型自动识别的结果。 |
| rec_gt.txt | 识别标签。可直接用于PPOCR识别模型训练。需用户手动点击菜单栏“文件” - "导出识别结果"后产生。 |
| crop_img | 识别数据。按照检测框切割后的图片。与rec_gt.txt同时产生。 |
3. 说明
3.1 快捷键
| 快捷键 | 说明 |
|---|---|
| Ctrl + shift + R | 对当前图片的所有标记重新识别 |
| W | 新建矩形框 |
| Q | 新建四点框 |
| Ctrl + E | 编辑所选框标签 |
| Ctrl + R | 重新识别所选标记 |
| Ctrl + C | 复制并粘贴选中的标记框 |
| Ctrl + 鼠标左键 | 多选标记框 |
| Backspace | 删除所选框 |
| Ctrl + V | 确认本张图片标记 |
| Ctrl + Shift + d | 删除本张图片 |
| D | 下一张图片 |
| A | 上一张图片 |
| Ctrl++ | 缩小 |
| Ctrl– | 放大 |
| ↑→↓← | 移动标记框 |
3.2 内置模型
- 默认模型:PPOCRLabel默认使用PaddleOCR中的中英文超轻量OCR模型,支持中英文与数字识别,多种语言检测。
- 模型语言切换:用户可通过菜单栏中 “PaddleOCR” - “选择模型” 切换内置模型语言,目前支持的语言包括法文、德文、韩文、日文。具体模型下载链接可参考PaddleOCR模型列表.
- 自定义模型:如果用户想将内置模型更换为自己的推理模型,可根据自定义模型代码使用,通过修改PPOCRLabel.py中针对PaddleOCR类的实例化,通过修改PPOCRLabel.py中针对PaddleOCR类的实例化) 实现,例如指定检测模型:
self.ocr = PaddleOCR(det=True, cls=True, use_gpu=gpu, lang=lang),在det_model_dir中传入 自己的模型即可。
3.3 导出标记结果
PPOCRLabel支持三种导出方式:
-
自动导出:点击“文件 - 自动导出标记结果”后,用户每确认过一张图片,程序自动将标记结果写入Label.txt中。若未开启此选项,则检测到用户手动确认过5张图片后进行自动导出。
默认情况下自动导出功能为关闭状态
-
手动导出:点击“文件 - 导出标记结果”手动导出标记。
-
关闭应用程序导出
3.4 导出部分识别结果
针对部分难以识别的数据,通过在识别结果的复选框中取消勾选相应的标记,其识别结果不会被导出。被取消勾选的识别结果在标记文件 label.txt 中的 difficult 变量保存为 True 。
注意:识别结果中的复选框状态仍需用户手动点击确认后才能保留
3.5 数据集划分
在终端中输入以下命令执行数据集划分脚本:
cd ./PPOCRLabel # 将目录切换到PPOCRLabel文件夹下
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ../train_data
参数说明:
-
trainValTestRatio是训练集、验证集、测试集的图像数量划分比例,根据实际情况设定,默认是6:2:2 -
datasetRootPath是PPOCRLabel标注的完整数据集存放路径。默认路径是PaddleOCR/train_data分割数据集前应有如下结构:|-train_data |-crop_img |- word_001_crop_0.png |- word_002_crop_0.jpg |- word_003_crop_0.jpg | ... | Label.txt | rec_gt.txt |- word_001.png |- word_002.jpg |- word_003.jpg | ...
3.6 错误提示
-
如果同时使用whl包安装了paddleocr,其优先级大于通过paddleocr.py调用PaddleOCR类,whl包未更新时会导致程序异常。
-
PPOCRLabel不支持对中文文件名的图片进行自动标注。
-
针对Linux用户:如果您在打开软件过程中出现**objc[XXXXX]**开头的错误,证明您的opencv版本太高,建议安装4.2版本:
pip install opencv-python==4.2.0.32 -
如果出现
Missing string id开头的错误,需要重新编译资源:pyrcc5 -o libs/resources.py resources.qrc -
如果出现
module 'cv2' has no attribute 'INTER_NEAREST'错误,需要首先删除所有opencv相关包,然后重新安装4.2.0.32版本的headless opencvpip install opencv-contrib-python-headless==4.2.0.32
五、训练检测器
1、制作数据集
完成数据的标注就可以看是训练检测器了。找到Lable.txt,将其中一部分放到train_label.txt ,将一部分放到test_label.txt,将图片放到ppocr(这个文件夹的名字和标注时的图片文件夹的名字一致),如下:
PaddleOCR-release-2.5/train_data/icdar2015/text_localization/
└─ ppocr/ 图片存放的位置
└─ train_label.txt icdar数据集的训练标注
└─ test_label.txt icdar数据集的测试标注

自定义切分数据集代码。我在这里没有使用官方给的切分方式,是自定义的切分方式。
import os
import shutil
from sklearn.model_selection import train_test_split
label_txt='./ppocr/Label.txt' #标注数据的路径
if not os.path.exists('tmp'):
os.makedirs('tmp')
with open(label_txt, 'r') as f:
txt_List=f.readlines()
trainval_files, val_files = train_test_split(txt_List, test_size=0.1, random_state=42)
print(trainval_files)
f = open("train_label.txt", "w")
f.writelines(trainval_files)
f.close()
f = open("test_label.txt", "w")
f.writelines(val_files)
f.close()
for txt in txt_List:
image_name=txt.split('\t')[0]
new_path="./tmp/"+image_name.split('/')[1]
shutil.move(image_name, new_path)
print(image_name)
如果路径不存在,请手动创建。执行完成后将tmp文件夹里面的图片放到PaddleOCR-release-2.5/train_data/icdar2015/text_localization/ppocr/文件夹下面。如果不存在则自己创建。
2、下载预训练模型
然后下载预训练模型,将其放到pretrain_models文件夹中,命令如下:
# 根据backbone的不同选择下载对应的预训练模型
# 下载MobileNetV3的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams
# 或,下载ResNet18_vd的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/ResNet18_vd_pretrained.pdparams
# 或,下载ResNet50_vd的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/ResNet50_vd_ssld_pretrained.pdparams
不同的预训练模型对应不同的配置文件,详见第3节。
这次我选用如下图的配置:

3、修改配置文件
然后修改该config文件,路径: configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,打开文件对里面的参数进行修改该。
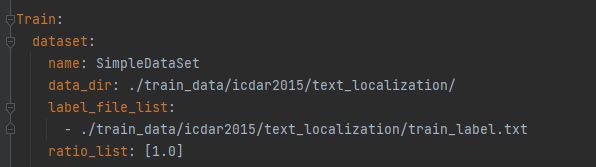
按照自己定义的路径,修改训练集的路径。
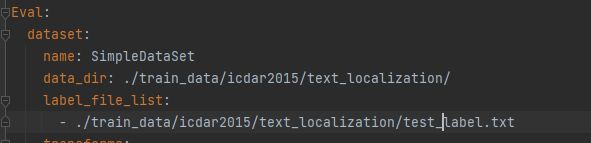
按照自己定义的路径,修改验证集的路径。
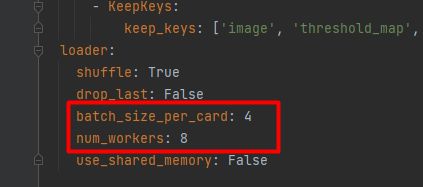
对BatchSize的修改。
如果训练出来的检测框偏小,可以修改参数unclip_ratio,将其调大即可。

4、开启训练
完成上面的工作就可以启动训练了,在pycharm的Terminal中输入命令:
注意:在PaddleOCR的根目录执行命令。
# 单机单卡训练
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model=./pretrain_models/
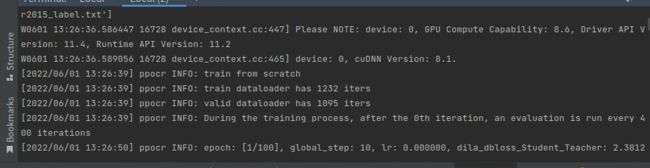
更多的训练方式如下:
# 单机单卡训练 mv3_db 模型
python3 tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
# 单机多卡训练,通过 --gpus 参数设置使用的GPU ID
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
# 多机多卡训练,通过 --ips 参数设置使用的机器IP地址,通过 --gpus 参数设置使用的GPU ID
python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
4.1、 断点训练
如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
python3 tools/train.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./your/trained/model
注意:Global.checkpoints的优先级高于Global.pretrained_model的优先级,即同时指定两个参数时,优先加载Global.checkpoints指定的模型,如果Global.checkpoints指定的模型路径有误,会加载Global.pretrained_model指定的模型。
4.2 混合精度训练
如果您想进一步加快训练速度,可以使用自动混合精度训练, 以单机单卡为例,命令如下:
python3 tools/train.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
4.3 分布式训练
多机多卡训练时,通过 --ips 参数设置使用的机器IP地址,通过 --gpus 参数设置使用的GPU ID:
python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
注意: 采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通。另外,训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为ifconfig。
分布式训练,我没有试过,主要是没有钞能力。
5、 模型评估与预测
5.1 指标评估
PaddleOCR计算三个OCR检测相关的指标,分别是:Precision、Recall、Hmean(F-Score)。
训练中模型参数默认保存在Global.save_model_dir目录下。在评估指标时,需要设置Global.checkpoints指向保存的参数文件。
python tools/eval.py -c configs/det/det_mv3_db.yml -o Global.checkpoints="{path/to/weights}/best_accuracy"
5.2 测试检测效果
测试单张图像的检测效果:
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.pretrained_model="./output/det_db/best_accuracy"
测试DB模型时,调整后处理阈值:
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.pretrained_model="./output/det_db/best_accuracy" PostProcess.box_thresh=0.6 PostProcess.unclip_ratio=2.0
- 注:
box_thresh、unclip_ratio是DB后处理参数,其他检测模型不支持。
测试文件夹下所有图像的检测效果:
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/" Global.pretrained_model="./output/det_db/best_accuracy"
6. 模型导出与预测
inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
检测模型转inference 模型方式:
官方的例子:
# 加载配置文件`det_mv3_db.yml`,从`output/det_db`目录下加载`best_accuracy`模型,inference模型保存在`./output/det_db_inference`目录下
python3 tools/export_model.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model="./output/det_db/best_accuracy" Global.save_inference_dir="./output/det_db_inference/"
自己用的命令:
python tools/export_model.py -c output/db_mv3/config.yml -o Global.pretrained_model="./output/db_mv3/best_accuracy" Global.save_inference_dir="./output/det_db_inference/"
DB检测模型inference 模型预测:
python3 tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="./output/det_db_inference/" --image_dir="./doc/imgs/" --use_gpu=True
五、训练识别器
1、图片裁剪与数据集生成
在训练识别器之间,我们还有一步要做,就是将标注的数据裁剪出来。裁剪代码如下:
import json
import os
import numpy as np
import cv2
def get_rotate_crop_image(img, points):
'''
img_height, img_width = img.shape[0:2]
left = int(np.min(points[:, 0]))
right = int(np.max(points[:, 0]))
top = int(np.min(points[:, 1]))
bottom = int(np.max(points[:, 1]))
img_crop = img[top:bottom, left:right, :].copy()
points[:, 0] = points[:, 0] - left
points[:, 1] = points[:, 1] - top
'''
assert len(points) == 4, "shape of points must be 4*2"
# 求范数,得到宽度
img_crop_width = int(
max(
np.linalg.norm(points[0] - points[1]),
np.linalg.norm(points[2] - points[3])))
# # 求范数,得到高度
img_crop_height = int(
max(
np.linalg.norm(points[0] - points[3]),
np.linalg.norm(points[1] - points[2])))
pts_std = np.float32([[0, 0], [img_crop_width, 0],
[img_crop_width, img_crop_height],
[0, img_crop_height]])
#计算得到转换矩阵
M = cv2.getPerspectiveTransform(points, pts_std)
#实现透视变换
dst_img = cv2.warpPerspective(
img,
M, (img_crop_width, img_crop_height),
borderMode=cv2.BORDER_REPLICATE,
flags=cv2.INTER_CUBIC)
dst_img_height, dst_img_width = dst_img.shape[0:2]
if dst_img_height * 1.0 / dst_img_width >= 1.5:
dst_img = np.rot90(dst_img)
return dst_img
def write_txt_img(src_path,label_txt):
with open(src_path, 'r', encoding='utf-8') as f:
for line in f.readlines():
print(line)
content = line.split('\t')
print(content[0])
imag_name = content[0].split('/')[1]
image_path = './train_data/icdar2015/text_localization/' + content[0]
img = cv2.imread(image_path)
list_dict = json.loads(content[1])
nsize = len(list_dict)
print(nsize)
num = 0
for i in range(nsize):
print(list_dict[i])
lin = list_dict[i]
info = lin['transcription']
info=info.replace(" ","")
points = lin['points']
points = [list(x) for x in points]
points = np.float32([list(map(float, item)) for item in points])
imag_name=str(num)+"_"+imag_name
save_path = './train_data/rec/train/' + imag_name
dst_img = get_rotate_crop_image(img, points)
cv2.imwrite(save_path, dst_img)
label_txt.write('train/'+imag_name+'\t'+info+'\n')
num=num+1
if not os.path.exists('train_data/rec/train/'):
os.makedirs('train_data/rec/train/')
src_path = r"./train_data/icdar2015/text_localization/train_icdar2015_label.txt"
label_txt=r"./train_data/rec/rec_gt_train.txt"
src_test_path = r"./train_data/icdar2015/text_localization/test_icdar2015_label.txt"
label_test_txt=r"./train_data/rec/rec_gt_test.txt"
with open(label_txt, 'w') as w_label:
write_txt_img(src_path,w_label)
with open(label_test_txt, 'w') as w_label:
write_txt_img(src_test_path, w_label)
获取标注区域的图像主要用到了getPerspectiveTransform计算转换的矩阵和warpPerspective函数透视转换的组合。
获取到图像和标注的内容,生成文字识别通用数据集(SimpleDataSet)。
数据集的格式:
注意: txt文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
" 图像文件名 图像标注信息 "
train/word_001.jpg 简单可依赖
train/word_002.jpg 用科技让复杂的世界更简单
生成数据集的路径如下:
2、修改配置文件
修改配置文件,在configs/rec/中,用rec_icdar15_train.yml 举例:

设置训练集的路径。
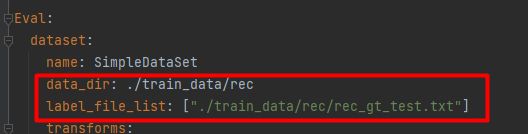
设置验证集的路径。

调整训练集和验证集的图片尺寸
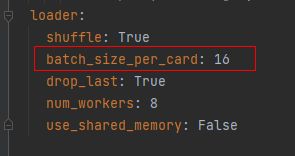
设置训练和验证的batchsize。

设置字典,根据任务不同设置的字典也不同。
内置字典如下:
PaddleOCR内置了一部分字典,可以按需使用。
ppocr/utils/ppocr_keys_v1.txt 是一个包含6623个字符的中文字典
ppocr/utils/ic15_dict.txt 是一个包含36个字符的英文字典
ppocr/utils/dict/french_dict.txt 是一个包含118个字符的法文字典
ppocr/utils/dict/japan_dict.txt 是一个包含4399个字符的日文字典
ppocr/utils/dict/korean_dict.txt 是一个包含3636个字符的韩文字典
ppocr/utils/dict/german_dict.txt 是一个包含131个字符的德文字典
ppocr/utils/en_dict.txt 是一个包含96个字符的英文字典
3、开启训练
完成上面的参数的设置,然后开始训练,命令如下:
python tools/train.py -c configs/rec/rec_icdar15_train.yml

更多的训练方式:
#单卡训练(训练周期长,不建议)
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
#多卡训练,通过--gpus参数指定卡号
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
3.1、 断点训练
如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
python tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.checkpoints=./your/trained/model
注意:Global.checkpoints的优先级高于Global.pretrained_model的优先级,即同时指定两个参数时,优先加载Global.checkpoints指定的模型,如果Global.checkpoints指定的模型路径有误,会加载Global.pretrained_model指定的模型。
3.2、 混合精度训练
如果您想进一步加快训练速度,可以使用自动混合精度训练, 以单机单卡为例,命令如下:
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml \
-o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy \
Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
3.3、 分布式训练
多机多卡训练时,通过 --ips 参数设置使用的机器IP地址,通过 --gpus 参数设置使用的GPU ID:
python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml \
-o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
注意: 采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通。另外,训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为ifconfig。
4 模型评估与预测
4.1、指标评估
训练中模型参数默认保存在Global.save_model_dir目录下。在评估指标时,需要设置Global.checkpoints指向保存的参数文件。评估数据集可以通过 configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml 修改Eval中的 label_file_path 设置。
# GPU 评估, Global.checkpoints 为待测权重
python -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.checkpoints={path/to/weights}/best_accuracy
4.2、测试识别效果
使用 PaddleOCR 训练好的模型,可以通过以下脚本进行快速预测。
默认预测图片存储在 infer_img 里,通过 -o Global.checkpoints 加载训练好的参数文件:
根据配置文件中设置的 save_model_dir 和 save_epoch_step 字段,会有以下几种参数被保存下来:
output/rec/
├── best_accuracy.pdopt
├── best_accuracy.pdparams
├── best_accuracy.states
├── config.yml
├── iter_epoch_3.pdopt
├── iter_epoch_3.pdparams
├── iter_epoch_3.states
├── latest.pdopt
├── latest.pdparams
├── latest.states
└── train.log
其中 best_accuracy.* 是评估集上的最优模型;iter_epoch_3.* 是以 save_epoch_step 为间隔保存下来的模型;latest.* 是最后一个epoch的模型。
# 预测英文结果
python tools/infer_rec.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
预测使用的配置文件必须与训练一致,如您通过 python tools/train.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml 完成了中文模型的训练, 您可以使用如下命令进行中文模型预测。
# 预测中文结果
python tools/infer_rec.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/ch/word_1.jpg
4. 模型导出与预测
inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
识别模型转inference模型与检测的方式相同,如下:
官方的例子:
# -c 后面设置训练算法的yml配置文件
# -o 配置可选参数
# Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
# Global.save_inference_dir参数设置转换的模型将保存的地址。
python tools/export_model.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy Global.save_inference_dir=./inference/en_PP-OCRv3_rec/
**注意:**如果您是在自己的数据集上训练的模型,并且调整了中文字符的字典文件,请注意修改配置文件中的character_dict_path为自定义字典文件。
自己执行的命令:
python tools/export_model.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./output/v3_en_mobile/best_accuracy Global.save_inference_dir=./inference/en_PP-OCRv3_rec/
转换成功后,在目录下有三个文件:
inference/en_PP-OCRv3_rec/
├── inference.pdiparams # 识别inference模型的参数文件
├── inference.pdiparams.info # 识别inference模型的参数信息,可忽略
└── inference.pdmodel # 识别inference模型的program文件
-
自定义模型推理
如果训练时修改了文本的字典,在使用inference模型预测时,需要通过
--rec_char_dict_path指定使用的字典路径python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words_en/word_336.png" --rec_model_dir="./your inference model" --rec_image_shape="3, 48, 320" --rec_char_dict_path="your text dict path"
六、hubserving部署
hubserving服务部署目录下包括文本检测、文本方向分类,文本识别、文本检测+文本方向分类+文本识别3阶段串联,表格识别和PP-Structure六种服务包,请根据需求选择相应的服务包进行安装和启动。目录结构如下:
deploy/hubserving/
└─ ocr_cls 文本方向分类模块服务包
└─ ocr_det 文本检测模块服务包
└─ ocr_rec 文本识别模块服务包
└─ ocr_system 文本检测+文本方向分类+文本识别串联服务包
└─ structure_table 表格识别服务包
└─ structure_system PP-Structure服务包
每个服务包下包含3个文件。以2阶段串联服务包为例,目录如下:
deploy/hubserving/ocr_system/
└─ __init__.py 空文件,必选
└─ config.json 配置文件,可选,使用配置启动服务时作为参数传入
└─ module.py 主模块,必选,包含服务的完整逻辑
└─ params.py 参数文件,必选,包含模型路径、前后处理参数等参数
1、准备环境
# 安装paddlehub
# paddlehub 需要 python>3.6.2
pip install paddlehub==2.1.0 --upgrade -i https://mirror.baidu.com/pypi/simple
2、安装服务模块
PaddleOCR提供5种服务模块,根据需要安装所需模块。
- 在Linux环境下,安装示例如下:
# 安装检测服务模块:
hub install deploy/hubserving/ocr_det/
# 或,安装分类服务模块:
hub install deploy/hubserving/ocr_cls/
# 或,安装识别服务模块:
hub install deploy/hubserving/ocr_rec/
# 或,安装检测+识别串联服务模块:
hub install deploy/hubserving/ocr_system/
# 或,安装表格识别服务模块:
hub install deploy/hubserving/structure_table/
# 或,安装PP-Structure服务模块:
hub install deploy/hubserving/structure_system/
- 在Windows环境下(文件夹的分隔符为``),安装示例如下:
# 安装检测服务模块:
hub install deploy\hubserving\ocr_det\
# 或,安装分类服务模块:
hub install deploy\hubserving\ocr_cls\
# 或,安装识别服务模块:
hub install deploy\hubserving\ocr_rec\
# 或,安装检测+识别串联服务模块:
hub install deploy\hubserving\ocr_system\
# 或,安装表格识别服务模块:
hub install deploy\hubserving\structure_table\
# 或,安装PP-Structure服务模块:
hub install deploy\hubserving\structure_system\
我使用了检测+方向+识别,所以只需要安装
hub install deploy/hubserving/ocr_system/
注意:在PaddleOCR-release-2.5目录下执行
3、启动服务
3.1. 命令行命令启动(仅支持CPU,不推荐)
启动命令:
$ hub serving start --modules [Module1==Version1, Module2==Version2, ...] \
--port XXXX \
--use_multiprocess \
--workers \
参数:
| 参数 | 用途 |
|---|---|
| –modules/-m | PaddleHub Serving预安装模型,以多个Module==Version键值对的形式列出 当不指定Version时,默认选择最新版本 |
| –port/-p | 服务端口,默认为8866 |
| –use_multiprocess | 是否启用并发方式,默认为单进程方式,推荐多核CPU机器使用此方式 Windows操作系统只支持单进程方式 |
| –workers | 在并发方式下指定的并发任务数,默认为2*cpu_count-1,其中cpu_count为CPU核数 |
如启动串联服务: hub serving start -m ocr_system
这样就完成了一个服务化API的部署,使用默认端口号8866。
3.2、 配置文件启动(支持CPU、GPU)
启动命令:
hub serving start -c config.json
其中,config.json格式如下:
{
"modules_info": {
"ocr_system": {
"init_args": {
"version": "1.0.0",
"use_gpu": true
},
"predict_args": {
}
}
},
"port": 8868,
"use_multiprocess": false,
"workers": 2
}
init_args中的可配参数与module.py中的_initialize函数接口一致。其中,当use_gpu为true时,表示使用GPU启动服务。predict_args中的可配参数与module.py中的predict函数接口一致。
注意:
- 使用配置文件启动服务时,其他参数会被忽略。
- 如果使用GPU预测(即,
use_gpu置为true),则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,如:export CUDA_VISIBLE_DEVICES=0,否则不用设置。 use_gpu不可与use_multiprocess同时为true。
如,使用GPU 3号卡启动串联服务:
export CUDA_VISIBLE_DEVICES=3
hub serving start -c deploy/hubserving/ocr_system/config.json
4、 发送预测请求
配置好服务端,可使用以下命令发送预测请求,获取预测结果:
python tools/test_hubserving.py server_url image_path
test_hubserving.py代码:
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
__dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
sys.path.append(os.path.abspath(os.path.join(__dir__, '..')))
from ppocr.utils.logging import get_logger
logger = get_logger()
import cv2
import numpy as np
import time
from PIL import Image
from ppocr.utils.utility import get_image_file_list
from tools.infer.utility import draw_ocr, draw_boxes, str2bool
from ppstructure.utility import draw_structure_result
from ppstructure.predict_system import to_excel
import requests
import json
import base64
def cv2_to_base64(image):
return base64.b64encode(image).decode('utf8')
def draw_server_result(image_file, res):
img = cv2.imread(image_file)
image = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
if len(res) == 0:
return np.array(image)
keys = res[0].keys()
if 'text_region' not in keys: # for ocr_rec, draw function is invalid
logger.info("draw function is invalid for ocr_rec!")
return None
elif 'text' not in keys: # for ocr_det
logger.info("draw text boxes only!")
boxes = []
for dno in range(len(res)):
boxes.append(res[dno]['text_region'])
boxes = np.array(boxes)
draw_img = draw_boxes(image, boxes)
return draw_img
else: # for ocr_system
logger.info("draw boxes and texts!")
boxes = []
texts = []
scores = []
for dno in range(len(res)):
boxes.append(res[dno]['text_region'])
texts.append(res[dno]['text'])
scores.append(res[dno]['confidence'])
boxes = np.array(boxes)
scores = np.array(scores)
draw_img = draw_ocr(
image, boxes, texts, scores, draw_txt=True, drop_score=0.5)
return draw_img
def save_structure_res(res, save_folder, image_file):
img = cv2.imread(image_file)
excel_save_folder = os.path.join(save_folder, os.path.basename(image_file))
os.makedirs(excel_save_folder, exist_ok=True)
# save res
with open(
os.path.join(excel_save_folder, 'res.txt'), 'w',
encoding='utf8') as f:
for region in res:
if region['type'] == 'Table':
excel_path = os.path.join(excel_save_folder,
'{}.xlsx'.format(region['bbox']))
to_excel(region['res'], excel_path)
elif region['type'] == 'Figure':
x1, y1, x2, y2 = region['bbox']
print(region['bbox'])
roi_img = img[y1:y2, x1:x2, :]
img_path = os.path.join(excel_save_folder,
'{}.jpg'.format(region['bbox']))
cv2.imwrite(img_path, roi_img)
else:
for text_result in region['res']:
f.write('{}\n'.format(json.dumps(text_result)))
def main(args):
image_file_list = get_image_file_list(args.image_dir)
is_visualize = False
headers = {"Content-type": "application/json"}
cnt = 0
total_time = 0
for image_file in image_file_list:
img = open(image_file, 'rb').read()
if img is None:
logger.info("error in loading image:{}".format(image_file))
continue
img_name = os.path.basename(image_file)
# seed http request
starttime = time.time()
data = {'images': [cv2_to_base64(img)]}
r = requests.post(
url=args.server_url, headers=headers, data=json.dumps(data))
elapse = time.time() - starttime
total_time += elapse
logger.info("Predict time of %s: %.3fs" % (image_file, elapse))
res = r.json()["results"][0]
logger.info(res)
if args.visualize:
draw_img = None
if 'structure_table' in args.server_url:
to_excel(res['html'], './{}.xlsx'.format(img_name))
elif 'structure_system' in args.server_url:
save_structure_res(res['regions'], args.output, image_file)
else:
draw_img = draw_server_result(image_file, res)
if draw_img is not None:
if not os.path.exists(args.output):
os.makedirs(args.output)
cv2.imwrite(
os.path.join(args.output, os.path.basename(image_file)),
draw_img[:, :, ::-1])
logger.info("The visualized image saved in {}".format(
os.path.join(args.output, os.path.basename(image_file))))
cnt += 1
if cnt % 100 == 0:
logger.info("{} processed".format(cnt))
logger.info("avg time cost: {}".format(float(total_time) / cnt))
def parse_args():
import argparse
parser = argparse.ArgumentParser(description="args for hub serving")
parser.add_argument("--server_url", type=str, required=True)
parser.add_argument("--image_dir", type=str, required=True)
parser.add_argument("--visualize", type=str2bool, default=False)
parser.add_argument("--output", type=str, default='./hubserving_result')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
main(args)
需要给脚本传递2个参数:
- server_url:服务地址,格式为
http://[ip_address]:[port]/predict/[module_name]
例如,如果使用配置文件启动分类,检测、识别,检测+分类+识别3阶段,表格识别和PP-Structure服务,那么发送请求的url将分别是:
http://127.0.0.1:8865/predict/ocr_det
http://127.0.0.1:8866/predict/ocr_cls
http://127.0.0.1:8867/predict/ocr_rec
http://127.0.0.1:8868/predict/ocr_system
http://127.0.0.1:8869/predict/structure_table
http://127.0.0.1:8870/predict/structure_system - image_dir:测试图像路径,可以是单张图片路径,也可以是图像集合目录路径
- visualize:是否可视化结果,默认为False
- output:可视化结果保存路径,默认为
./hubserving_result
访问示例:
python tools/test_hubserving.py --server_url=http://127.0.0.1:8868/predict/ocr_system --image_dir=./doc/imgs/ --visualize=false
运行结果:
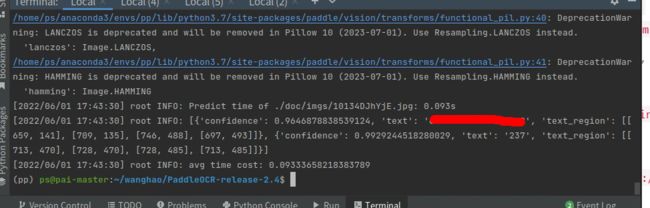
5、 返回结果格式说明
返回结果为列表(list),列表中的每一项为词典(dict),词典一共可能包含3种字段,信息如下:
| 字段名称 | 数据类型 | 意义 |
|---|---|---|
| angle | str | 文本角度 |
| text | str | 文本内容 |
| confidence | float | 文本识别置信度或文本角度分类置信度 |
| text_region | list | 文本位置坐标 |
| html | str | 表格的html字符串 |
| regions | list | 版面分析+表格识别+OCR的结果,每一项为一个list,包含表示区域坐标的bbox,区域类型的type和区域结果的res三个字段 |
不同模块返回的字段不同,如,文本识别服务模块返回结果不含text_region字段,具体信息如下:
| 字段名/模块名 | ocr_det | ocr_cls | ocr_rec | ocr_system | structure_table | structure_system |
|---|---|---|---|---|---|---|
| angle | ✔ | ✔ | ||||
| text | ✔ | ✔ | ✔ | |||
| confidence | ✔ | ✔ | ✔ | |||
| text_region | ✔ | ✔ | ✔ | |||
| html | ✔ | ✔ | ||||
| regions | ✔ | ✔ |
说明: 如果需要增加、删除、修改返回字段,可在相应模块的module.py文件中进行修改,完整流程参考下一节自定义修改服务模块。