机器学习之数据预处理(均值移除、范围缩放、归一化、二值化、独热编码、标签编码)
标准化分类
1. 0-1标准化(0-1 normalization)
原理: 离差标准化,线性变换 --> [0, 1]
转换函数:
![]()
2. z-score标准化(zero-mean normalization)
原理:均值为0,标准差为1(符合标准正态分布) --> mean=0, std=1
转换函数:
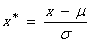
sklearn数据预处理方法
###1. 均值移除
#####概述:
为了统一样本矩阵中不同特恒的基准值和分散度,可以将各个特征的平均值调整为0,标准差调整为1,这个过程称为均值移除。
#####标准化类型:z-score标准化
#####语法:
sklearn.preprocessing.scale(原始样本矩阵) --> return:均值移除后的样本矩阵(mean=0, std=1)
# 代码
import sklearn.preprocessing as sp
import numpy as np
raw_samples = np.array([
[3, -1.5, 2, -5.4],
[0, 4, -0.3, 2.1],
[1, 3.3, -1.9, -4.3]])
sp.scale(raw_samples)
Out[6]:
array([[ 1.33630621, -1.40451644, 1.29110641, -0.86687558],
[-1.06904497, 0.84543708, -0.14577008, 1.40111286],
[-0.26726124, 0.55907936, -1.14533633, -0.53423728]])
# 注意:sp.scale(..).mean / std (axis=0) 中的axis=0 沿轴方向不能少
# python默认行优先即水平方向优先(axis=1), 样本数据为一行一样本 一列一特征
sp.scale(raw_samples).mean(axis=0), sp.scale(raw_samples).std(axis=0)
Out[7]:
(array([ 5.55111512e-17, -1.11022302e-16, -7.40148683e-17, -7.40148683e-17]),
array([1., 1., 1., 1.]))
# help(...scale)
def scale(X, axis=0, with_mean=True, with_std=True, copy=True):
Standardize a dataset along any axis
2. 范围缩放
#####概述:
统一样本矩阵中不同特征的最大值和最小值范围。将属性缩放到一个指定的最大和最小值(通常是1-0)之间,这样处理可对方差非常小的属性增强其稳定性,也可维持稀疏矩阵中为0的条目。
#####标准化类型:0-1标准化
#####转换函数:
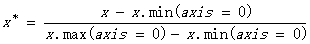
#####语法:
sklearn.preprocessing.MinMaxScaler(feature_range=期望最小最大值, copy=True) --> return: 范围缩放,
范围缩放器.fit_transform(原始样本矩阵) --> return:范围缩放后的样本矩阵
sp.MinMaxScaler(feature_range=(0, 1)) # return: 范围缩放器
Out[8]: MinMaxScaler(copy=True, feature_range=(0, 1))
sp.MinMaxScaler(feature_range=(0, 1)).fit_transform(raw_samples) # 范围缩放后的样本,range(0, 1)
Out[9]:
array([[1. , 0. , 1. , 0. ],
[0. , 1. , 0.41025641, 1. ],
[0.33333333, 0.87272727, 0. , 0.14666667]])
# help(..MinMaxScaler)
Parameters
----------
feature_range : tuple (min, max), default=(0, 1)
Desired range of transformed data.
copy : boolean, optional, default True
Set to False to perform inplace row normalization and avoid a
copy (if the input is already a numpy array).
3. 归一化
概述:
为了用占比表示特征,用每个样本的特征值除以该样本的特征值绝对值之和,以使每个样本的特征值绝对值之和为1(转化为占比 normalized)
语法:
sklearn.preprocessing.normalize(原始样本矩阵,norm='l1') --> return:归一化后的样本矩阵
#####备注:
l1即L1范数,矢量中各元素绝对值之和。
l2即L2范数,矢量元素绝对值的平方和再开方
sp.normalize(raw_samples, norm='l1')
Out[10]:
array([[ 0.25210084, -0.12605042, 0.16806723, -0.45378151],
[ 0. , 0.625 , -0.046875 , 0.328125 ],
[ 0.0952381 , 0.31428571, -0.18095238, -0.40952381]])
# help(...normalize)
def normalize(X, norm='l2', axis=1, copy=True, return_norm=False):
norm : 'l1', 'l2', or 'max', optional ('l2' by default)
The norm to use to normalize each non zero sample (or each non-zero feature if axis is 0).
4. 二值化Binarizer
概述:
用0和1来表示样本矩阵中相对于某个给定阈值高于或低于它的元素
#####语法:
1)生成二值化器
sklearn.preprocessing.Binarizer(threshold=阈值, copy=True) --> return:二值化器,
2)二值化
二值化器.transform(原始样本矩阵) --> return: 二值化后的样本矩阵.
#####备注:
- threshold:
feature <= threshold: feature = 0;
feature > threshold: feature = 1; - 二值化方法不可逆,若希望0-1可逆话 可考虑使用独热编码进行可逆的transform
sp.Binarizer(threshold=1.4)
Out[11]: Binarizer(copy=True, threshold=1.4)
sp.Binarizer(threshold=1.4).transform(raw_samples)
Out[12]:
array([[1., 0., 1., 0.],
[0., 1., 0., 1.],
[0., 1., 0., 0.]])
5. 独热编码One-Hot-Encoding
#####概述:
又称一位有效编码,其方法是使用N位状态寄存器来对特征的N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
即有多少个状态就有多少bit,而且只有一个bit为1,其他全为0的一种码制。
#####作用:
对离散型的分类型数据进行数字化,比如将文本分类属性的性别进行数字化的独热编码。
1)解决了分类器不好处理属性数据的问题,
2)在一定程度上起到了扩充特征的作用
#####解释:
对于离散数据 {sex:{male, female,other}}, 如果单纯使用{1,2,0}进行编码(即标签编码),在模型训练中不同的值可能会使同一特征在样本中的权重发生变化。
采用独热编码,有3个分类值,需要3个bit位表示该特征值,对应bit位为1其他为0对应原特征值,得到的独热编码为 {100, 010, 001}分别表示{male, female, other}
# 如果有多个特征,则需要分别对每个特征进行独热编码,然后拼接起来作为多个特征的独热码:
1)
{sex:{male, female,other}}
{calss:{class-1,class-2, calss-3, class-4}}
# 分别编码:
feature1: {sex:{male, female,other}} --->{100, 010, 001}
feature2: {calss:{class-1,class-2, calss-3, class-4}} --->{1000, 0100, 0010, 0001}
# 完整编码:
feature, feature ---> ohe
{male, class-2} ---> {1000100}
{female, class-1} ---> {0101000}
...
# 2)
# 样本:4*3: 4个样本,3个特征(每一个特征有多少个状态就用多少个bit)
1 3 2
7 5 4
1 8 6
7 3 9
# 第1列特征有2个状态,用2个编码表示
# 第2列特征有3个状态,用3个编码表示
# 第3列特征有4个状态,用4个编码表示
1->10 3->100 2->1000
7->01 5->010 4->0100
8->001 6->0010
9->0001
独热编码构成的稀疏矩阵:
1 3 2 ==> 101001000
7 5 4 ==> 010100100
1 8 6 ==> 100010010
7 3 9 ==> 011000001
此时,给定样本 test=np.array([[2, 4, 8]]), 则实际编码为 array([[1, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)
原因: 上例中 特征1只有(1,7), 特征2只有(3,5,8), 特征3只有(2,4,6,9),.
测试例中特征1为数字2,不在特征1范围内,故编码为 [0, 0];
测试例中特征2为数字4,不在特征2范围内,故编码为 [0, 0, 0];
测试例中特征3为数字8,不在特征3范围内,故编码为 [0, 0, 0, 0];
因此,独热编码中,实际每一列是一个特征,第 i 列特征的数字不能用第 j 列特征相同的数字的编码来编码
#####语法:
1)生成独热编码器
sklearn.preprocessing.OneHoteEncoder(sparse=是否采用压缩格式, dtype=元素类型) --> return:独热编码器,
2)独热编码
独热编码器.fit_transform(原始样本矩阵) --> return:独热编码后的样本矩阵,同时构建编码表字典,
独热编码器.transform(原始样本矩阵) --> return:独热编码后的样本矩阵,使用已有的编码表字典.
a = np.array([[1, 3, 2],[7, 5, 4],[1, 8, 6],[7, 3, 9]]) # 4*3,4个样本,3个特征
ohe = sp.OneHotEncoder(sparse=False, dtype=int) # 独热编码器
ohe.fit_transform(raw_samples2) # 独热编码并构建编码表字典
Out[34]:
array([[1, 0, 1, 0, 0, 1, 0, 0, 0],
[0, 1, 0, 1, 0, 0, 1, 0, 0],
[1, 0, 0, 0, 1, 0, 0, 1, 0],
[0, 1, 1, 0, 0, 0, 0, 0, 1]], dtype=int32)
ohe.transform(raw_samples_test) # 使用已存在的编码表字典进行独热编码
Out[35]: array([[0, 1, 0, 1, 0, 1, 0, 0, 0]], dtype=int32)
# note:
# 使用已构建过的独热编码字典进行编码,前提是特征中的状态必须是已有编码字典里的状态,如果存在未出现过的状态,则编码会出现错误
#####为什么要用独热编码
独热编码(哑变量 dummy variable)是因为大部分算法是基于向量空间中的度量来进行计算的,为了使非偏序关系的变量取值不具有偏序性,并且到圆点是等距的。
使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点,特征之间的距离计算更加合理。
离散特征进行one-hot编码后,编码后的特征,其实每一维度的特征都可以看做是连续的特征。就可以跟对连续型特征的归一化方法一样,对每一维特征进行归一化。比如归一化到[-1,1]或归一化到均值为0,方差为1。
#####为什么特征向量要映射到欧式空间
将离散特征通过one-hot编码映射到欧式空间,是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
#####独热编码优缺点
- 优点:
能够处理非连续型数值特征。
在一定程度上也扩充了特征。比如性别本身是一个特征,经过one hot编码以后,就变成了男或女两个特征。
它的值只有0和1,不同的类型存储在垂直的空间。 - 缺点:
当类别的数量很多时,特征空间会变得非常大,稀疏矩阵会很稀,占内存空间大。
在这种情况下,一般可以用PCA来减少维度。而且 one hot encoding+PCA 这种组合在实际中也非常有用
#####什么情况下 (不) 使用独热编码 - 使用:独热编码用来解决类别型数据的离散值问题
- 不用:
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码(计算距离的合理性方面)
有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。
Tree Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
#####什么情况下(不)需要归一化 - 需要:
基于参数的模型或基于距离的模型,都是要进行特征的归一化 - 不需要:
基于树的方法是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等
以上五个个问题截取自:OneHotEncoder独热编码和 LabelEncoder标签编码
6. 标签编码
概述:
将离散型变量转换成连续的数值型变量,即对不连续的数字或者文本进行编号。
对于不同的特征,其编码表不同且相互独立;编码和解码都要使用对应特征的编码表。
语法:
1)生成标签编码器
sklearn.preprocessing.LabelEncoder() --> return:标签编码器,
2)标签编码和解码
标签编码器.fit_transform(原始样本矩阵) --> return:编码样本矩阵,构建编码字典,
标签编码器.transform(原始样本矩阵) --> return:编码样本矩阵,使用已有编码字典,
标签编码器.inverse_transform(编码样本矩阵) --> return:原始样本矩阵,使用已有编码字典.
label_str = np.array(['audi', 'ford', 'ford', 'bmw', 'toyota', 'ford', 'audi'])
label_encoder = sp.LabelEncoder() # 生成标签编码器
label_encoder.fit_transform(label_str) # 标签编码且构建标签编码表字典
Out[38]: array([0, 2, 2, 1, 3, 2, 0], dtype=int64)
label_test = np.array(['bmw','ford','audi','ford'])
label_coded_test = label_encoder.transform(label_test) # 使用已有的标签编码表对test数据进行编码
label_coded_test
Out[42]: array([1, 2, 0, 2], dtype=int64)
label_inv = label_encoder.inverse_transform(label_coded) # 逆编码即解码会label_str中的原始离散型数据
label_inv
Out[44]: array(['bmw', 'ford', 'audi', 'ford'], dtype=' 0` to check that an array is not empty
#####局限
Label encoding在某些情况下很有用,但是场景限制很多。比如有[dog,cat,dog,mouse,cat],我们把其转换为[1,2,1,3,2]。这里就产生了一个奇怪的现象:dog和mouse的平均值是cat
###独热编码原理
'''
独热编码原理code:
'''
# 独热编码的code原理实现:
code_tables = []
for col in raw_samples2.T:
code_table = {}
# dict-key:每个元素作为dict的key
for val in col:
code_table[val] = None
code_tables.append(code_table)
# print(code_table.keys()) # dict_keys([1, 7]), dict_keys([3, 5, 8]), dict_keys([2, 4, 6, 9])
#print(code_tables)
# [{1: None, 7: None}, {3: None, 5: None, 8: None}, {2: None, 4: None, 6: None, 9: None}]
for code_table in code_tables:
# 编码的个数
size = len(code_table)
for one, key in enumerate(sorted(code_table.keys())): # 遍历有序键
# print(key,one, sep='|')
code_table[key] = np.zeros(shape=size, dtype=int) # 每取出1个key,为其创建1个shape=size的零数组
# print('code_table[key]:',code_table[key])
code_table[key][one] = 1 # 取出的顺序作为零数组的下标,对应赋值为1
# print('code_table[key]:',code_table[key]) # [1,7] --> (i=0,key=1) (i=1,key=7)
# [0,0] --> [1,0] [0,1]
# code_table[key]: [1 0]
# code_table[key]: [0 1]
# code_table[key]: [1 0 0]
# code_table[key]: [0 1 0]
# code_table[key]: [0 0 1]
# code_table[key]: [1 0 0 0]
# code_table[key]: [0 1 0 0]
# code_table[key]: [0 0 1 0]
# code_table[key]: [0 0 0 1]
ohe_samples = []
for raw_sample in raw_samples2:
# print(raw_sample)
ohe_sample = np.array([], dtype=int)
# 编码并存入ohe_sample
for i, key in enumerate(raw_sample):
ohe_sample = np.hstack((ohe_sample, code_tables[i][key])) # 行内依次取出水平拼接
# 沿行方向即raw_sample如[1 3 2]编码完成后将行完整编码添加到ohe_samples列表中
ohe_samples.append(ohe_sample)
ohe_samples = np.array(ohe_samples)
#print(ohe_samples)
#[[1 0 1 0 0 1 0 0 0]
# [0 1 0 1 0 0 1 0 0]
# [1 0 0 0 1 0 0 1 0]
# [0 1 1 0 0 0 0 0 1]]