人工智能导论学习笔记(考前复习)
文章目录
- 前言
- 正文
-
- 搜索问题的形式化
- 无信息搜索
-
- 什么是树搜索和图搜索
- Uniform Cost Search 一致代价搜索
- 深度受限搜索
- 迭代加深的深度优先搜索
- 双向搜索
- 无信息搜索的评价
- 有信息搜索(启发式)
-
- 贪婪最佳优先搜素 greedy best-first search
- A*搜索
- 可纳性和一致性
-
- A* 搜索中的剪枝
- A* 搜索中的内存不足问题
- 局部搜索算法
-
- 爬山法
-
- 最陡上升
- 随机爬山法
- 首选爬山
- 随机重启爬山法
- 模拟退火搜索
- 局部束搜索
- 遗传算法
- 对抗搜索
- 约束满足问题搜索
- Uncertainty
-
-
- 贝叶斯网络
- 贝叶斯网络推理
-
- 贝叶斯精确推理
- 贝特斯采样
- 隐马尔可夫模型
- 不确定搜索 Non-Deterministic Search
-
- 马尔科夫过程
- 马尔可夫奖励过程
- 马尔可夫决策过程(Markov Decision Process)
- 贝尔曼(Bellman)方程
- 值迭代 (Value Iteration)求解马尔科夫决策过程
- 策略迭代 Policy Iteration求解马尔科夫决策过程
- 强化学习(Reinforcement Learning)
-
- 基于模型的学习
- 基于无模型的学习
- 机器学习
-
- 熵
- 决策树
-
前言
这篇笔记是考试复习前强淦出来的,里面有很多部分都是用的cs188的笔记,其中部分案例和笔记来自
bilibili博主包治百病的小神仙
bilibili博主 Re_miniscence_
知乎博主亦知弦余 翻译的cs188笔记
这篇笔记同样在我的个人网站上
传送门
提示:以下是本篇文章正文内容,下面案例可供参考
正文
搜索问题的形式化
已知:
1.初始状态S
2.状态集S’
3.动作集A
4.路径耗散f(n)
5.目标测试is_goal(n)
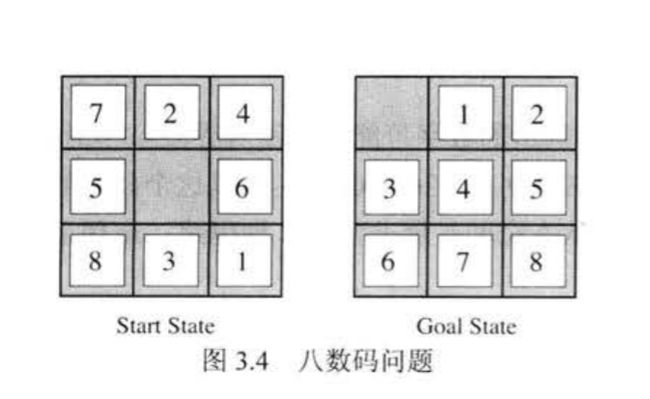
八数码问题

八皇后问题


无信息搜索
什么是树搜索和图搜索
一般的树搜索/图搜索:
①初始化
while
②选择节点n:从open表中选一个节点
③目标测试
④扩展节点n,n从open表中移除,n的后继加入open表
搜索树(search trees) 对于一个状态出现的次数没有限制。
通过移除一个与部分计划对应的节点(用给定的策略来选择)并用它所有的子节点代替它,我们不断地扩展(expand) 我们的边缘。用子节点代缘上的元素,相当于丢弃一个长度为n的计划并考虑所有源于它的长度为(n+1)的计划。我们继续这一操作,直到最终将目标从边缘移除为止。
一般的树搜索
①Frontier<-{s}
while
② if Fronter=null ,return false;
best-node<-min f(n){n|n in Frontier}
Fronter<-Frontier-{best-node}
③if is_goal(best-node)==true
return solution
④List<-suc(best-node)
Frontier<-Frontier+List
图搜索(graph search)跟踪哪些状态已经扩展过,确保每一个节点在扩展前不在这个集合中,并且在扩展后将其加入集合里。经过这种优化的树搜索称为图搜索(graph search)
一般的图搜索
①Frontier<-{s} closed={}
while
② if Fronter=null ,return false;
best-node<-min f(n){n|n in Frontier}
Fronter<-Frontier-{best-node}
closed<-closed+{best-node}
③if is_goal(best-node)==true
return solution
④List<-suc(best-node)
Frontier<-Frontier+List-closed
DFS 深度优先
-
完备性:深度优先搜索并不具有完备性。如果在状态空间图中存在回路,这必然意味着相应搜索树的深度将是无限的。因此,存在这样一种可能性,即DFS老实地在无限大的搜索树中搜索最深的节点而不幸地陷入僵局,注定无法找到解。
-
最优性:深度优先搜索只是在搜索树中找到“最左边”的解,而没有考虑路径的代价,因此不是最优的。
-
时间复杂度:在最坏情况下,深度优先搜索最终可能会搜遍整个搜索树。因此,给定一棵最大深度为m的树,DFS的时间复杂度为
O ( b k ) O(b^k) O(bk) -
空间复杂度:在最坏情况下,DFS在边缘上m个深度级别上都有b个节点。这是一个简单的结果,因为一旦某个父节点的b个子节点进入队列,DFS的本性在任意时间点都只允许研究任意一个子节点的一棵子树。因此,DFS的空间复杂度是
O ( b m ) O(bm) O(bm)
BFS 广度优先
-
完备性:如果存在一个解,那么最浅节点s的深度一定是有限的,所以BFS最终一定会搜索这个深度。所以它是完备的。
-
最优性:BFS一般不是最优的,因为它在选择边缘上被替换的节点时不会考虑代价问题。在所有边的代价都相等的特殊情况下BFS可以保证是最优的,因为这会让BFS退化为一致代价搜索,我们将会在下面讨论这个特殊情况。
-
时间复杂度:在最坏情况下我们必须搜索
1 + b + b 2 + . . . + b s 1+b+b^2+...+b^s 1+b+b2+...+bs
个节点,因为我们得在从1到s每一个深度下都遍历所有节点。因此,时间复杂度是
O ( b s ) O(b^s) O(bs) -
空间复杂度:在最坏情况下,边缘所有节点都在对应最浅解的那一层。由于最浅解位于深度s处,在这一深度有
O ( b s ) O(b^s) O(bs)
个节点。
Uniform Cost Search 一致代价搜索
描述:一致代价搜索(UCS),我们的最后一种方案,总是选择距离起始节点代价最小的边缘节点来扩展。
完备性:一致代价搜索是完备的。如果存在一个目标状态,它一定有一些有限长度最短路径;因此,UCS最终一定能找到这条长度最短路径。
最优性:如果我们假设所有的边都是非负的,那么UCS也是最优的。通过构造,由于我们按照路径代价递增的顺序来搜索节点,我们肯定能找到到达一个目标状态的最低代价路径。一致代价搜索的策略与Dijkstra算法相同,主要区别在于UCS在找到一个解状态时终止,而不是找到通往所有状态的最短路径。
时间复杂度:我们定义最优路径代价为 C* ,状态空间图内两节点之间最小代价为
ξ \xi ξ
。那么,我们得简单粗暴地遍历深度为从 1 到
C ∗ ε \frac{C^{*}}{\varepsilon} εC∗
范围内的所有节点,导致运行时间为
O ( b C ∗ ε ) O(b^{\frac{C^{*}}{\varepsilon}}) O(bεC∗)
空间复杂度:又是简单粗暴地,边缘会包括代价最低解所在层的所有节点,所以UCS空间复杂度大约为
O ( b C ∗ ε ) O(b^{\frac{C^{*}}{\varepsilon}}) O(bεC∗)
对于人类会怎么做,需要更聪明的算法
深度受限搜索
深度优先搜索在无限状态空间会失败,深度受限就是为了解决这一问题的
对深度优先搜索设置深度限制,但是缺失了完备性和最优性。
迭代加深的深度优先搜索
描述:从深度为0开始,深度不断增大,直到找到目标
最优性:具有最优性
完备性:具备完备性
时间复杂度和空间复杂度都是
O ( b d ) O(b^d) O(bd)
双向搜索
描述:一个从初始状态向前搜索,一个从目标状态向后搜索,希望他们在中间某点相遇
具有完备性和最优性
时间复杂度和空间复杂度都是:
O ( b d b 2 ) O(b^{d\frac{b}{2}}) O(bd2b)
无信息搜索的评价

有信息搜索(启发式)
启发式搜索是允许估计到目标状态距离的驱动力——它们是将状态作为输入并输出相应估计的函数。由这样一个函数执行的计算是专门针对所解决的搜索问题的。例如采用曼哈顿距离计算下一节点是否距离目标节点更近,这就是有信息搜索的一个例子
曼哈顿距离法(Manhattan Distance),对于两个点 (x1,y1)!和 (x2,y2)的定义为:
M a n h a t t a n ( x 1 , y 1 , x 2 , y 2 ) = ∣ x 1 − x 2 ∣ + ∣ y 1 + y 2 ∣ Manhattan(x_1,y_1,x_2,y_2)=|x_1-x_2|+|y_1+y_2| Manhattan(x1,y1,x2,y2)=∣x1−x2∣+∣y1+y2∣
贪婪最佳优先搜素 greedy best-first search
描述:贪婪搜索总是选择有**最小启发值(lowest heuristic value)**的节点来扩展,这些节点对应的是它认为最接近目标的状态。
通过一个启发式函数估算我们离目标有多近,并且注意启发式函数并不代表实际到达的步数,有墙可能会更远
完备性和最优性:如果存在一个目标状态,贪婪搜索无法保证能找到它,它也不是最优的,尤其是在选择了非常糟糕的启发函数的情况下。在不同场景中。它的行为通常是不可预测的,有可能一路直奔目标状态,也有可能像一个被错误引导的DFS一样并遍历所有的错误区域。
A*搜索
在下面的图中,如果使用贪婪最优算法,并不会选择最优路径,原因是在于贪婪最优只考虑了距离终点的距离,而不会考虑到达当前节点所需要的的代价,在后续节点中代价逐渐增大,但贪婪最优无法作出调整
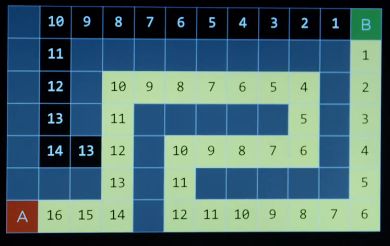
如何改进?判断权值是否再选择一个较小的结果后,又发现回升。
A*搜索不仅考虑启发式函数,还考虑多长时间达到特定状态。
f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n)
g(n)代表到达当前节点的代价,
h(n)代表从n到达目标解的代价的启发函数
f(n):A*搜索使用的估计总代价函数
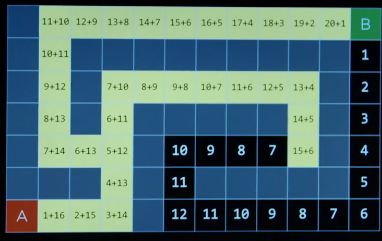
如果启发式函数不高估实际成本,那么它是可接受的,每个节点的结果或者与实际相同,或者小于实际值,但是不能认为我离目标比实际更远。。选择启发式函数,是挑战,启发式函数越好越容易解决问题。A*通常需要大量内存。
完备性和最优性:在给定一个合适的启发函数(我们很快就能得到)时,A*搜索既是完备的又是最优的。它结合了目前我们发现的所有其他搜索策略的优点,兼备贪婪搜索的高搜索速度以及UCS的完备性和最优性。
可纳性和一致性
可纳性:
使用A*树搜索时,最优性所需的条件称为可纳性(admissibility)。可纳性约束表明,用一个可纳的启发式估算的值既不是负的,也不会被高估。定义
h ∗ ( n ) h^*(n) h∗(n)
为从一个给定节点n到达目标状态的真正的最佳前进代价,我们能将可纳性约束数学表示为:
∀ n , 0 ≤ h ( n ) ≤ h ∗ ( n ) \forall n, 0 \leq h(n) \leq h^{*}(n) ∀n,0≤h(n)≤h∗(n)
定理. 对于一个给定的搜索问题,如果一个启发式函数h满足可纳性约束,使用含有h的A*树搜索能得到最优解。
一致性
一致性的核心思想在于,我们不仅仅强制让启发式算法低估从任意给定节点到目标的总距离,还低估了图中每一条边的代价/权重。由启发式函数度量的边的代价只是两个连接的节点的启发值的差异。一致性约束的数学表示如下:
∀ A , C , h ( A ) − h ( C ) ≤ cost ( A , C ) \forall A, C, h(A)-h(C) \leq \operatorname{cost}(A, C) ∀A,C,h(A)−h(C)≤cost(A,C)
定理. 对于一个给定的搜索问题,如果启发式函数h满足一致性约束,对这个搜索问题使用有h的A*图搜索能得到一个最优解。
A* 搜索中的剪枝
假如C* 是最优解路径的真实代价值,那么A* 算法是不会考虑f(n)>C* 的节点的,也就是该节点被剪枝了。
A* 搜索中的内存不足问题
A* 通常需要大量内存,有可能出现内存不足的问题,这时需要迭代加深的A* 算法(IDA* )
局部搜索算法
局部搜索算法是从单个节点出发,通常只移动到它的临近状态,一般情况下不保留搜索路径。虽然局部搜索算法不是系统化的,但是有两个关键的优点:
- 他们通常使用很少的内存–通常是常数
- 他们经常能在系统化算法不适用的很大或无限的(连续的)状态空间中找到合理的解
爬山法
爬山法有时称为贪婪局部搜索,因为它只选择邻居中状态最好的一个,而不考虑下一步该怎么走。
爬山法经常会陷入困境,比如局部最大值和山脊(有一系列局部最大值)和高原(平的局部最大值)
最陡上升
不断向值增加的方向移动,可以看成是一个登高的过程、在到达一个峰顶的时候结束(邻接状态下没有比它更高的)。算法不会考虑与当前状态不相邻的状态,算法不维护搜索树,当前节点的数据结构只是记录当前状态和目标函数值。
随机爬山法
在上山移动中随机地选择下一步
随机爬山法在上山移动中随机选择下一步;被选中的概率可能随着上山移动的陡峭程度不同而不同。这种算法通常比最陡上升算法的收敛速度慢不少,但是在某些状态空间地形图上它能找到更好的解。
首选爬山
实现了随机爬山法,随机地生成后继节点直到生成一个优于当前节点的后继。这个算法在后继节点很多的时候(比如上千个)是个好策略。
随机重启爬山法
之前的三个爬山法都是不完备的,经常会在局部极大值卡住。
随机重启爬山法(random restart hill climbing),
它通过随机生成初始状态来导引爬山法搜索,直到找到目标。
这种算法完备的概率接近1
原因:它最终会生成一个目标状态来作为初始状态。
模拟退火搜索
模拟退火搜索时爬山法和随机行走以某种方式结合,也就是一个允许下山的随机爬山法
Simulated Annealing 模拟退火算法
为什么名字这么奇怪,因为这是一个由金属退火启发的算法。
金属退火是将金属加热到一定温度,保持足够时间,然后以适宜速度冷却(通常是缓慢冷却,有时是控制冷却)的一种金属热处理工艺。模拟退火算法来源于固体退火原理,将固体加温至充分高,再让其徐徐冷却,加温时,固体内部粒子随温升变为无序状,内能增大,而徐徐冷却时粒子渐趋有序,在每个温度都达到平衡态,最后在常温时达到基态,内能减为最小。
模拟退火算法的核心思想是,与爬山法类似,只是它没有选择最佳移动,选择的是随机移动,如果该移动使情况改善,则该移动被接受,否则,算法以某个小于1的概率接受该移动。如果移动状态使情况变坏切被接受,则概率成指数级下降,即评估函数△E变坏。这个概率也随“温度”T降低而下降,开始T高的时候可能允许坏的移动,但是T越低这个可能越低,如果调度让T下降的足够慢,算法找到全局最优解的概率也就趋近于1。
局部束搜索
a、随机产生k个状态,然后每一步从所有的后继状态中选择k个最佳的后继状态(也有健康度函数,详见下文)直到找到目标状态(内存中同时保留k个状态),增大了找到全局最优的概率。
b、相当于多个人去找,或者多次爬山法。
c、状态越多,找到最优的可能性越大
d、空间复杂度高;时间复杂度大;来自同一个父节点的子节点可能非常相似,可能导致同样的一个局部最优,从而减小了找到全局最优的可能性。
e、可以通过每个状态各产生一个最佳后继状态(待验证)
遗传算法
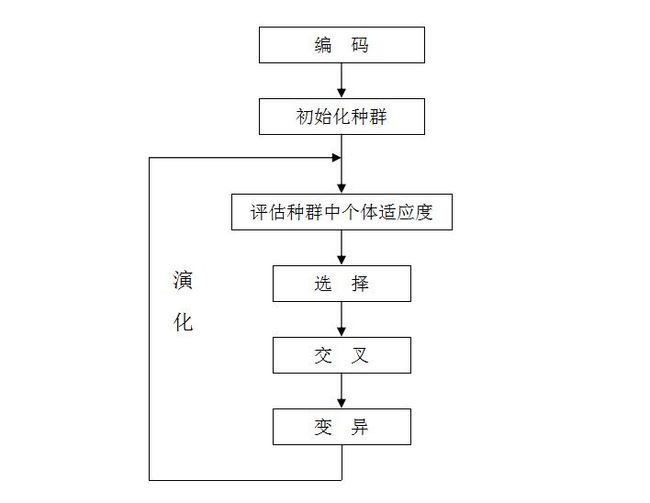
遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作
对抗搜索
Minimax 极大极小算法
通过编码使计算机明白min和max,也就是把输赢的结果转化为数字的大小,min尽可能的使数字更小,而max尽可能地使数字更大

α-β剪枝 Alpha-Beta Pruning
在寻找极大极小值时我们发现,有些节点可以不用搜索,因为在min选择极小值时需要考虑下一步的max是否会选择当前节点,如果当前的值比其他的节点值更小,那么我们可以认为该节点不会被下一次的max所选择,也就没有继续搜索下去的必要了。

约束满足问题搜索
约束满足问题(constraint satisfaction problems)(CSPSs).与搜索问题不同,CSP是一种识别问题(identification problem),对这种问题,我们只需要识别一个状态是否是目标状态,不用管我们如何到达那个目标。CSPs由三个要素定义:
-
变量Variables:CSP拥有一个集合,其中有N个变量
X 1 , X 2 , . . . , X N X_1,X_2,...,X_N X1,X2,...,XN
,每一个都可以从定义的一组值中取一个值。 -
域Domain:一个CSP变量所有可能取值的集合
{ x 1 , x 2 , . . . , x d } \{x_1,x_2,...,x_d\} {x1,x2,...,xd} -
约束Constrains:约束定义了变量取值的限制条件,这可能与其他变量有关。
约束满足问题求解
约束满足问题的传统解法是使用一种叫做**回溯搜索(Backtracking search)**的算法
Uncertainty
概率的加法公式
p ( a + b ) = p ( a ) + p ( b ) p(a+b)=p(a)+p(b) p(a+b)=p(a)+p(b)
概率的乘法公式
p ( a b ) = p ( a ∣ b ) p ( b ) p(ab)=p(a|b)p(b) p(ab)=p(a∣b)p(b)
Bayes’ Rule 贝叶斯公式
p ( b ∣ a ) = p ( a ∣ b ) p ( b ) p ( a ) p(b|a)=\frac{p(a|b)p(b)}{p(a)} p(b∣a)=p(a)p(a∣b)p(b)
例子,已知如下
早上有云,下午下雨的概率
上午有云,下午有0.8的概率下雨
有0.4日子是早上有云
有0.1日子是下午有雨
p ( r a i n ∣ c l o u d ) = p ( c l o u d ∣ r a i n ) p ( r a i n ) p ( c l o u d ) = 0.8 ∗ 0.1 0.4 = 0.2 p(rain|cloud)=\frac{p(cloud|rain)p(rain)}{p(cloud)}=\frac{0.8*0.1}{0.4}=0.2 p(rain∣cloud)=p(cloud)p(cloud∣rain)p(rain)=0.40.8∗0.1=0.2
我们已经知道,通过联合概率分布表和列举推理我们可以得到任何查询的概率,但是在计算机中表示整个联合分布式不现实的。
贝叶斯网络
贝叶斯网通过利用条件概率的概念来避免这个问题·概率不是存储在一个互大的表中,而是分布在大量较小的局部概率表中,同时还有一个捕捉变量间关系的有向无环图(DAG)。局部概率表和共同编码了足够的信息来计算任何概率分布,而我们本可以在给定整个联合分布的情况下进行计算.
图中每个节点代表一个随机变量,每条边代表我们选择存储的条件概率分布之一(即从节点A到节点B的边表示我们存储P(B|A)的概率)
Each node is conditionally independent of all its ancestor nodes in the graph, given all of its parents. Thus, if we have a node representing variable X, we store P(X|A1,A2,…,AN), where A1,…,AN are the parents of X.
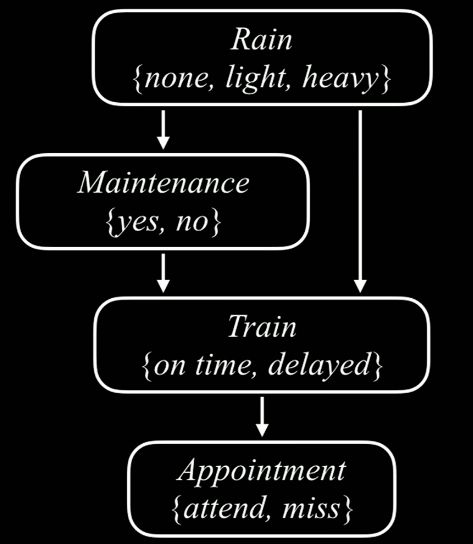
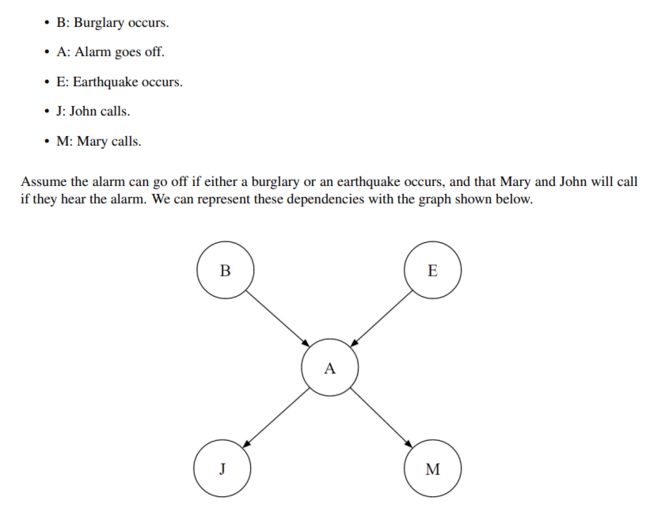
贝叶斯网络的组成
-
A directed acyclic graph of nodes, one per variable X.
-
A conditional distribution for each node P(X|A1 …An), where Ai is the i th parent of X, stored as a conditional probability table or CPT. Each CPT has n+2 columns: one for the values of each of the n parent variables A1 …An, one for the values of X, and one for the conditional probability of X.
在上面的表中,我们将存储s P(B),P(E),P(A | B,E),P(J | A) 和 P(M | A)
贝叶斯网络中的条件独立性:
父节点已知时, 该节点与其所有非后代的节点(non-descendants) 条件独立。
这里可以结合一个例子理解
案例来自bilibili博主包治百病的小神仙
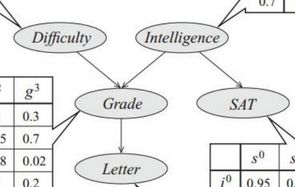

这里给出条件独立与非条件独立的几种情况
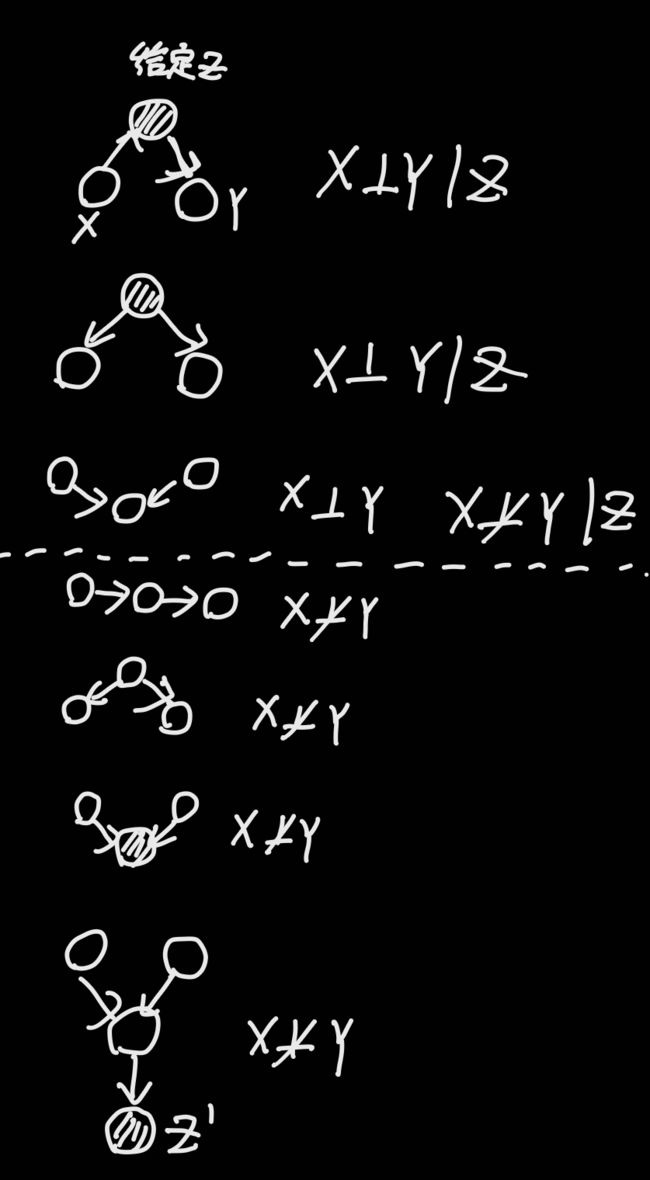
马尔可夫覆盖
刚刚给出的独立性定义是:父节点已知时, 该节点与其所有非后代的节点(non-descendants) 条件独立。
而马尔可夫覆盖则将独立性的范围扩大
那什么是马尔可夫覆盖呢?
- Xi的父节点
- Xi的子节点
- Xi的子节点及其他父节点
这里的xi指的是给定条件的节点,以上所列节点都是独立的(实际上这个范围是根据原来的局部范围得到的)这样的话可以考虑更多的独立性
贝叶斯网络推理
贝叶斯精确推理
贝特斯采样
什么是采样?
| C | P© |
|---|---|
| red | 0.6 |
| green | 0.1 |
| blue | 0.3 |
这里给出一个概率分布表,然后我们规定一个规则,比如给出一个参数x。当x在0-0.3时取红色,x在0.3-0.6时取绿色,其余时取蓝色,这就是一个简单的采样。
为什么要有采样?
贝叶斯网络的推理的复杂度是由深度决定的,当贝叶斯网络很深时,这个计算就会变得很复杂,采样是让采样的概率近似于精确值,这样做是为了简化推理。要注意,通过采样得到的结果是个近似值,要使近似值更加精确,就要增大采样数量.
采样主要分为
- 直接采样
- 拒绝采样
- 似然加权采样
- 吉布斯采样
直接采样
生成全联合概率分布,这里可以理解为路上的随机采访,因为每个节点的值概率是不一样的,所以在每个节点采样值和概率相关,我们就是通过直接采样,就像街上的直接采访一样,一个一个采样,最后生成一个概率分布表。
要经过充分采样才能使近似值更接近真实值
拒绝采样
在直接采样中,我们得到的一些样本值是不必要的,比如我要计算p(+w|-r),那么对于+r的样本,我们就不需要采样了。
似然加权
对证据变量不采样,直接利用条件分布表的概率,给每个样本一个权重,也称作似然。
贝叶斯网络用似然加权采样得到的样本序列。
| 序号 | 样本点 | 似然 |
|---|---|---|
| 1 | J = 52, S = 21, B = 10, X = 5 | 0.1 |
| 2 | J = 34, S = 21, B = 4, X = 5 | (1) |
| 3 | J = 87, S = 12, B = 10, X = 5 | 0.1 |
| 4 | J = 41, S = 12, B = 5, X = 5 | (2) |
| 5 | J = 91, S = 32, B = 3, X = 5 | 0.0 |
比如这个例子,这是一随机生成数的例子,即后一个的值由前一个随机生成且不能大于前一个,在已知X=5的情况下。
(1)的位置应该是0.因为4不可能生成5,所以权重是0
(2)的位置应是0.2,因为由5生成5的概率是1/5,也就是0.2.
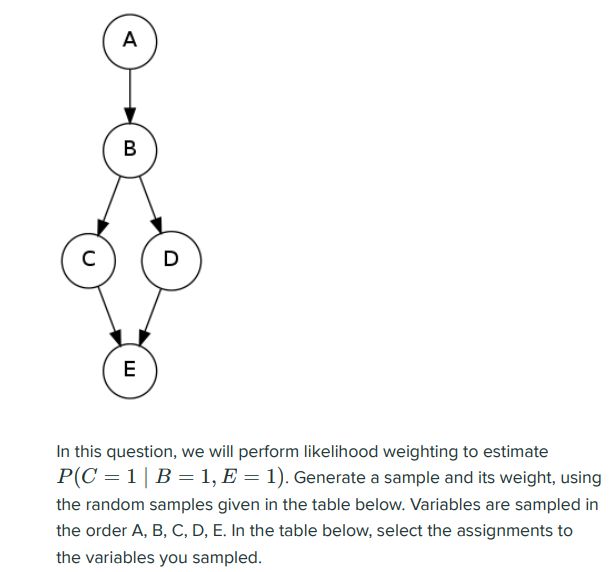
这个样例让我们计算根据P(C=1|B=1,E=1)来进行似然加权采样,首先我们要知道取样时不取B和E,直接让B和E等于1,然后看P(B|A)的概率作为该样本的一个权重,P(E|C,D)的概率作为另一个权重。然后其他值根据随机数生成。
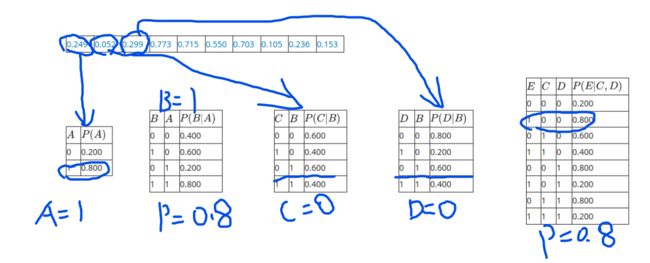
以上就是一个似然加权采样的样本,0.8*0.8就是该样本的权重。
那么,在得到似然加权采样后的样本后,我们怎么根据权值计算概率呢?

以上就是一个案例,B和E我们不需要考虑,因为我们已经给定他们都是1,然后我们看所有C=1的权值加起来除以所有权值之和就是我们要求的概率。也就是:
0.64 + 0.64 + 0.48 0.64 + 0.64 + 0.32 + 0.16 + 0.48 \frac {0.64+0.64+0.48}{0.64+0.64+0.32+0.16+0.48} 0.64+0.64+0.32+0.16+0.480.64+0.64+0.48
吉布斯采样
先随机给出一个样本,然后从第一个变量开始,第一个样本由后面的给定值根据马尔可夫覆盖生成对应值,接着第二个变量依然如此。也就是每一次只关注一个变量。
吉布斯采样是效率较高的一种采样方法

隐马尔可夫模型
什么是隐马尔可夫模型?
隐马尔可夫模型(Hidden Markov model, HMM)是一种结构最简单的动态贝叶斯网的生成模型,它也是一种著名的有向图模型。它是典型的自然语言中处理标注问题的统计机器学模型。
具体请参考下方链接,讲的十分清晰
传送门
隐马尔可夫模型由初始状态概率向量C,状态转移概率矩阵A和观测概率矩阵B决定,C和A决定状态序列,B决定观测序列,因此隐马尔可夫模型可以用三元符号表示为:
λ = { A , B , C } \lambda = \{A,B,C\} λ={A,B,C}
A、B和C也被称为隐马尔科夫模型的三要素。
隐马尔可夫模型作了两个基本假设:
(1) 其次马尔可夫性假设,即假设隐藏的马尔可夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其它时刻的状态及观测无关,也与时刻t无关,
p ( i t ∣ i t − 1 , o t − 1 , . . . , i 1 . o 1 ) = p ( i t ∣ i t − 1 ) , t = 1 , 2 , . . . , T p(i_t|i_{t-1},o_{t-1},...,i_1.o_1)=p(i_t|i_{t-1}),t=1,2,...,T p(it∣it−1,ot−1,...,i1.o1)=p(it∣it−1),t=1,2,...,T
(2) 观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关。
p ( o t ∣ i T , o T , i T − 1 , o T − 1 , . . . , i t + 1 , o t + 1 , . . . , i 1 , o 1 ) = p ( o t ∣ i t ) p(o_t|i_T,o_T,i_{T-1},o_{T-1},...,i_{t+1},o_{t+1},...,i_1,o_1)=p(o_t|i_t) p(ot∣iT,oT,iT−1,oT−1,...,it+1,ot+1,...,i1,o1)=p(ot∣it)
这些是马尔科夫家族之间的关系,后面还会有马尔科夫决策过程

不确定搜索 Non-Deterministic Search
Agent所在的环境会迫使agent的行为变得不确定(nondeterministic),意味着在某一状态下采取的一个行动会有多个可能的后继状态。实际上,这就是许多像扑克牌或是黑杰克这样的卡牌游戏中会出现的情况,存在着由发牌的随机性导致的固有的不确定性。这种在世界中存在一定程度的不确定性的问题被称为不确定搜索问题(nondeterministic search problems),可以用**马尔科夫决策过程(Markov decision processes)**或者称为MDPs来解决。
马尔科夫过程
什么是马尔科夫过程,简单来说,马尔科夫过程就是一个无记忆的随机过程,这个过程的未来只有当前有关而与过去无关。比如明天是否睡觉取决于今天的状态而与过去的状态无关,这就是马尔科夫过程。
马尔科夫过程包含一个状态转移矩阵,表示从状态s转移到后继状态s‘的概率
马尔科夫过程(或马尔科夫链)是一个二元组
- S:有限状态集
- P:状态转移概率矩阵
P s s ′ = P [ S t + 1 = s ′ ∣ S t = s ] P_{ss'}=P[S_{t+1}=s'|S_{t}=s] Pss′=P[St+1=s′∣St=s]
马尔可夫奖励过程
马尔可夫奖励过程是一个四元组
S:有限状态集
P:状态转移概率矩阵
R:奖励函数
R S = E [ R t + 1 ∣ S t = s ] R_{S}=E[R_{t+1}|S_{t}=s] RS=E[Rt+1∣St=s]
γ:折扣因子
γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1]
为什么要有折扣因子呢?
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . . G_{t}=R_{t+1}+\gamma R_{t+2}+\gamma ^{2}R_{t+3}+.... Gt=Rt+1+γRt+2+γ2Rt+3+....
Gt代表从时间t开始的总折扣奖励,因为未来还很长远,是不确定的,因此未来的收益应该占的比重小一些,越是往后所占权重越小,逐渐趋于零,而当前的奖励应该占权重最大
马尔可夫决策过程(Markov Decision Process)
马尔可夫决策过程是一个五元组
S:有限状态集
A:有限动作集
P:状态转移矩阵 (也有的地方是T)
R:奖励函数
γ:折扣因子
π 是 给 定 状 态 的 动 作 分 布 π ( a ∣ s ) = P [ A t = a ∣ S t = s ] \pi 是给定状态的动作分布 \pi (a|s)=P[A_{t}=a|S_{t}=s] π是给定状态的动作分布π(a∣s)=P[At=a∣St=s]
状态值函数:
V π ( s ) = E π [ G t ∣ S t = s ] V_{\pi}(s)=E_{\pi}[G_{t}|S_{t}=s] Vπ(s)=Eπ[Gt∣St=s]
动作值函数:
q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] q_{\pi}(s,a)=E_{\pi}[G_{t}|S_{t}=s,A_{t}=a] qπ(s,a)=Eπ[Gt∣St=s,At=a]
状态值函数的贝尔曼期望方程:某一个状态的价值可以用该状态下所有动作的价值表述
V π ( s ) = E π [ R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ] V_{\pi} (s)=E_{\pi}[R_{t+1}+\gamma v_{\pi}(S_{t+1})|S_{t}=s] Vπ(s)=Eπ[Rt+1+γvπ(St+1)∣St=s]
动作值函数的贝尔曼期望方程: 某一个动作的价值可以用该状态后继状态的价值表述,及 发生了动作a的价值
q π ( s , a ) = E π [ R t + 1 + γ q π ( S t + 1 , A t + 1 ) ∣ S t = s , A t = a ] q_\pi (s,a) = E_\pi[R_{t+1}+\gamma q_\pi (S_{t+1},A_{t+1})|S_t=s,A_t=a] qπ(s,a)=Eπ[Rt+1+γqπ(St+1,At+1)∣St=s,At=a]
贝尔曼(Bellman)方程
-
一个状态s的最优值
V ∗ ( s ) V^*(s) V∗(s)——s的最优值是一个从s出发的agent在其余下寿命中采取最优行动能获得的效益的期望值。
-
一个q状态(s,a)的最优值,
Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a)——(s,a)的最优值是一个agent从状态s采取行动a之后获得的效益的期望值,并且该agent从此以后采取的都是最优行动。
通过这两个值,以及在此之前讲到的MDP中其他的值,Bellman方程定义如下:
V ∗ ( s ) = m a x a ∑ s ′ T ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ V ∗ ( s ′ ) ] V^*(s)=max_a \sum_{s'} {T(s,a,s')[R(s,a,s')+\gamma V^* (s')]} V∗(s)=maxas′∑T(s,a,s′)[R(s,a,s′)+γV∗(s′)]
在我们解释这个方程的含义之前,我们还要定义一下表示一个q状态的最优值的方程(也就是最优q值(q-value)):
Q ∗ ( s , a ) = ∑ s ′ T ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ V ∗ ( s ′ ) ] Q^*(s,a)= \sum_{s'} {T(s,a,s')[R(s,a,s')+\gamma V^* (s')]} Q∗(s,a)=s′∑T(s,a,s′)[R(s,a,s′)+γV∗(s′)]
Bellman方程是**动态规划方程(dynamic programming equation)**的一个例子,这种方程能通过其内在的递归结构将一个问题分解成一些小问题。我们能在关于一个状态的q值的方程中看到这种内在递归,形如
[ R ( s , a , s ′ ) + γ V ∗ ( s ′ ) ] \left[R\left(s, a, s^{\prime}\right)+\gamma V^{*}\left(s^{\prime}\right)\right] [R(s,a,s′)+γV∗(s′)]
这个式子表示一个agent从状态s采取行动a到达状态s’,并从此一直采取最优行动所获得的总效益。采取行动a之后立即获得的奖励,
R ( s , a , s ′ ) R\left(s, a, s^{\prime}\right) R(s,a,s′)
加上从状态s’出发能获得的最优奖励
V ∗ ( s ′ ) V^{*}\left(s^{\prime}\right) V∗(s′)
为了考虑采取a所花费的时间步,对其用γ对取了折扣。虽然在大多数情况下,从s’出发到某一最终状态的状态和行动序列有非常多的可能性,全部的这些细节都被抽象并概括为一个迭代值
V ∗ ( s ′ ) V^{*}\left(s^{\prime}\right) V∗(s′)
。
已知
[ R ( s , a , s ′ ) + γ V ∗ ( s ′ ) ] \left[R\left(s, a, s^{\prime}\right)+\gamma V^{*}\left(s^{\prime}\right)\right] [R(s,a,s′)+γV∗(s′)]
表示在从q状态(s,a)到达状态s’之后一直采取最优行动获得的效益
现在很明显了,以下这个值
∑ s ′ T ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ V ∗ ( s ′ ) ] \sum_{s^{\prime}} T\left(s, a, s^{\prime}\right)\left[R\left(s, a, s^{\prime}\right)+\gamma V^{*}\left(s^{\prime}\right)\right] s′∑T(s,a,s′)[R(s,a,s′)+γV∗(s′)]
就是效益的加权和。每个效益的权重就是其出现的概率。这正是从q状态(s,a)出发并一直采取最优行动的期望效益!我们的分析到此完整了,并且我们能由此解释完整的Bellman方程——一个状态的最优值,
V ∗ ( s ) V^*(s) V∗(s)
,就是从s出发的所有可能的行动所能得到的最大期望效益。
值迭代 (Value Iteration)求解马尔科夫决策过程
现在我们有了一个能验证MDP中各状态的值的最优性的框架,接下来自然就想知道如何能精确计算出这些最优值。为此我们需要限时值(time-limited values)(强化有限界得到的结果)。限制时间步数为k的一个状态s的限时值表示为
V k ( s ) V_k(s) Vk(s)
,代表着在已知当前MDP会在k时间步后终止的情况下,从s出发能得到的最大期望效益。这也正是一个在MDP的搜索树上执行的k层expectimax所返回的东西。
简单来说,值迭代就是给定k,也就是步数为k,在这k步之内,我们希望值迭代已经到达稳定状态,即下一次迭代与这一次的完全相同,这时我们就得到一个最优决策,也就是从哪里出发能够得到最大期望效益。
值迭代(Value iteration)是一种动态规划算法(dynamic programming algorithm),通过一个迭代加长的时间限制来计算限时值,直到收敛(也就是说,直到每个状态的V值都与其之前的迭代一样:
∀ s ∈ S , V ( s ) = V ∗ ( s ) \forall s \in S,V(s)=V^*(s) ∀s∈S,V(s)=V∗(s)
。执行流程如下:
∀ s ∈ S ∀ s\in S ∀s∈S
设初值
V 0 ( s ) = 0 V_0(s)=0 V0(s)=0
。这个很直观,因为把时间限制设为0代表着在终止之前无法执行任何操作,所以也无法获得任何奖励。
2.重复如下更新操作,直至收敛:
∀ s ∈ S , V k + 1 ( s ) ← m a x a ∑ s ′ T ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ V ∗ ( s ′ ) ] ∀ s\in S ,V_{k+1}(s)\leftarrow max_a \sum_{s'} {T(s,a,s')[R(s,a,s')+\gamma V^* (s')]} ∀s∈S,Vk+1(s)←maxas′∑T(s,a,s′)[R(s,a,s′)+γV∗(s′)]
在值迭代的第k轮,我们给每个状态使用时限为k的限时值来生成时限为(k+1)的限时值。本质上来说,我们通过计算子问题的解(所有的
V k ( s ) V_k(s) Vk(s)
来迭代的得到更高一级的子问题的解(所有的
V k + 1 ( s ) V_{k+1}(s) Vk+1(s)
;这就让值迭代成为了一个动态规划算法。
也就是在初始时,所有的状态价值V0(s)都是0,在然后进行价值迭代,对每个节点,按照第二步的公式进行计算其状态价值,每进行一次迭代就会更新每个节点的状态价值
这里引用**bilibili博主 Re_miniscence_ **的例子
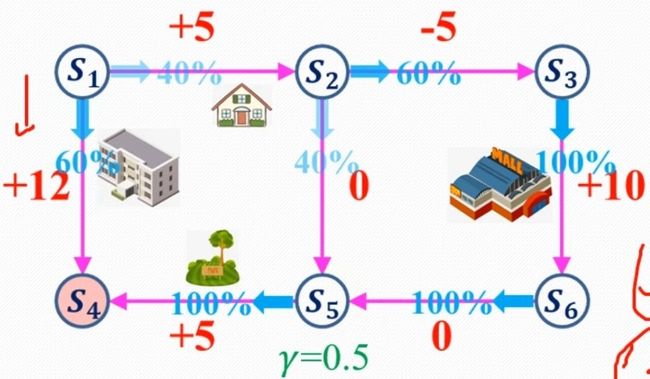
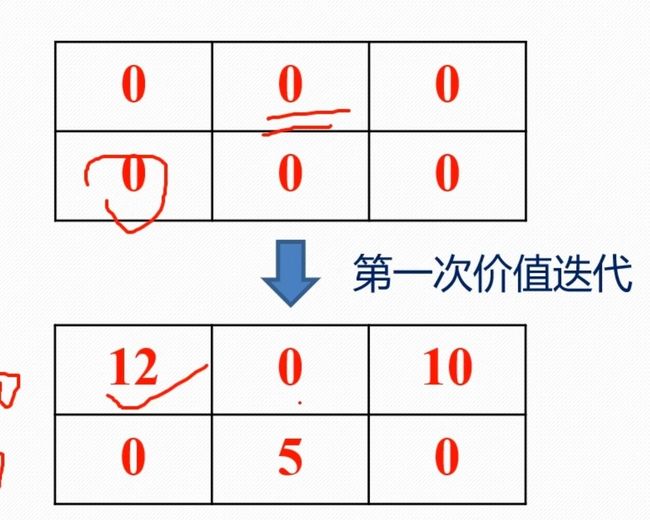
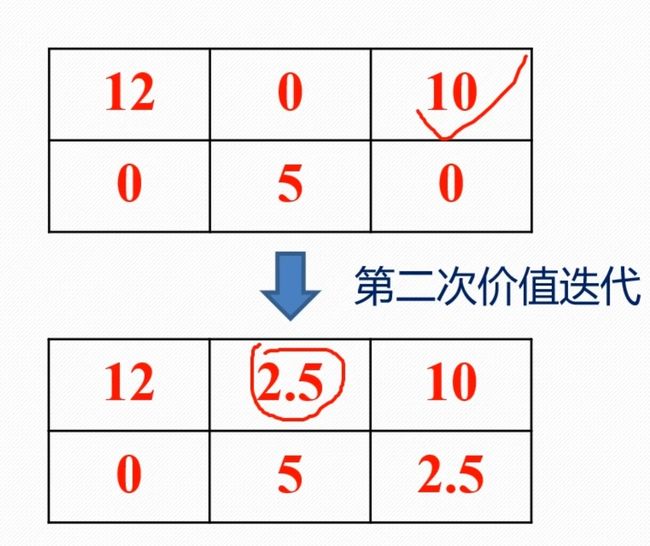
后续将按照第二步进行迭代,直到收敛,也就是下一次迭代与上一次一致,这时就可以做出决策
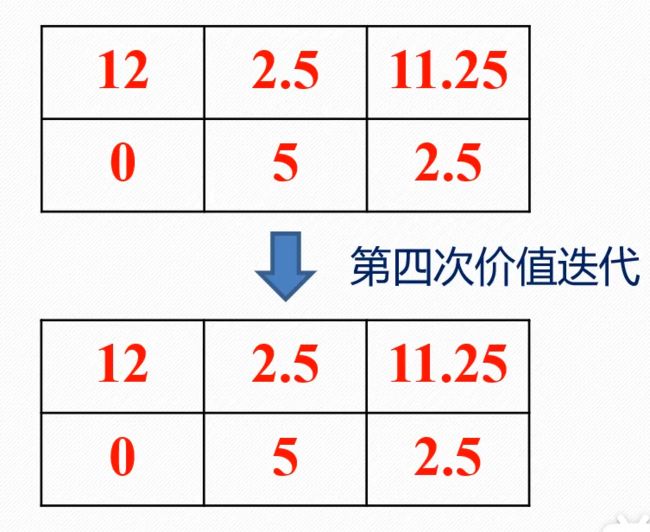
这时我们发现12是其中最大的,也就是最优决策对应的状态价值,所以得出结论,从此位置出发将得到最大收益
以下是**知乎博主亦知弦余**的例子
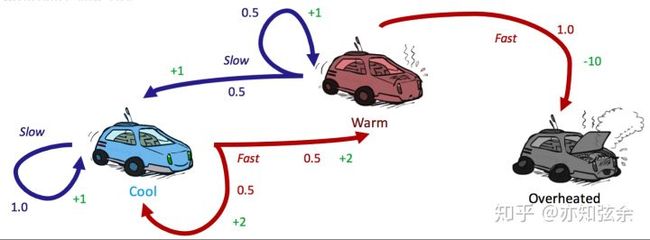
迭代过程1
V 1 ( cool ) = max { 1 ⋅ [ 1 + 0.5 ⋅ 0 ] , 0.5 ⋅ [ 2 + 0.5 ⋅ 0 ] + 0.5 ⋅ [ 2 + 0.5 ⋅ 0 ] } = max { 1 , 2 } = 2 V_{1}(\text { cool })=\max \{1 \cdot[1+0.5 \cdot 0], 0.5 \cdot[2+0.5 \cdot 0]+0.5 \cdot[2+0.5 \cdot 0]\}=\max \{1,2\}=2 V1( cool )=max{1⋅[1+0.5⋅0],0.5⋅[2+0.5⋅0]+0.5⋅[2+0.5⋅0]}=max{1,2}=2
V 1 ( warm ) = max { 0.5 ⋅ [ 1 + 0.5 ⋅ 0 ] , 0.5 ⋅ [ 1 + 0.5 ⋅ 0 ] + 1 ⋅ [ − 10 + 0.5 ⋅ 0 ] } = max { 1 , − 10 } = 1 V_{1}(\text { warm })=\max \{0.5 \cdot[1+0.5 \cdot 0], 0.5 \cdot[1+0.5 \cdot 0]+1 \cdot[-10+0.5 \cdot 0]\}=\max \{1,-10\}=1 V1( warm )=max{0.5⋅[1+0.5⋅0],0.5⋅[1+0.5⋅0]+1⋅[−10+0.5⋅0]}=max{1,−10}=1
V 1 ( o v e r h e a t e d ) = m a x = 0 V_1(overheated)=max{}=0 V1(overheated)=max=0
迭代过程2
V 2 ( cool ) = max { 1 ⋅ [ 1 + 0.5 ⋅ 2 ] , 0.5 ⋅ [ 2 + 0.5 ⋅ 2 ] + 0.5 ⋅ [ 2 + 0.5 ⋅ 1 ] } = max { 2 , 2.75 } = 2.75 V_{2}(\text { cool })=\max \{1 \cdot[1+0.5 \cdot 2], 0.5 \cdot[2+0.5 \cdot 2]+0.5 \cdot[2+0.5 \cdot 1]\}=\max \{2,2.75\}=2.75 V2( cool )=max{1⋅[1+0.5⋅2],0.5⋅[2+0.5⋅2]+0.5⋅[2+0.5⋅1]}=max{2,2.75}=2.75
V 2 ( cool ) = max { 1 ⋅ [ 1 + 0.5 ⋅ 2 ] , 0.5 ⋅ [ 2 + 0.5 ⋅ 2 ] + 0.5 ⋅ [ 2 + 0.5 ⋅ 1 ] } = max { 2 , 2.75 } = 2.75 V 2 ( warm ) = max { 0.5 ⋅ [ 1 + 0.5 ⋅ 2 ] , 0.5 ⋅ [ 1 + 0.5 ⋅ 1 ] + 1 ⋅ [ − 10 + 0.5 ⋅ 0 ] } = max { 1.75 , − 10 } = 1.75 V_{2}(\text { cool })=\max \{1 \cdot[1+0.5 \cdot 2], 0.5 \cdot[2+0.5 \cdot 2]+0.5 \cdot[2+0.5 \cdot 1]\}=\max \{2,2.75\}=2.75V_{2}(\operatorname{warm})=\max \{0.5 \cdot[1+0.5 \cdot 2], 0.5 \cdot[1+0.5 \cdot 1]+1 \cdot[-10+0.5 \cdot 0]\}=\max \{1.75,-10\}=1.75 V2( cool )=max{1⋅[1+0.5⋅2],0.5⋅[2+0.5⋅2]+0.5⋅[2+0.5⋅1]}=max{2,2.75}=2.75V2(warm)=max{0.5⋅[1+0.5⋅2],0.5⋅[1+0.5⋅1]+1⋅[−10+0.5⋅0]}=max{1.75,−10}=1.75
V 2 ( o v e r h e a t e d ) = m a x = 0 V_2(overheated)=max{}=0 V2(overheated)=max=0
| cool | warm | overheated | |
|---|---|---|---|
| V0 | 0 | 0 | 0 |
| V1 | 2 | 1 | 0 |
| V2 | 2.75 | 1.75 | 0 |
任何最终状态的
V ∗ ( s ) V^*(s) V∗(s)
都一定是0,因为无法从最终状态进行任何行动来获得奖励。
策略迭代 Policy Iteration求解马尔科夫决策过程
策略提取 Policy Extraction
还记得我们解决MDP的最终目标是要确定一个最优策略。只需要确定所有状态的最优值就能达成这一目标,这可以通过一种叫**策略提取(policy extraction)**的方法来实现。策略提取的背后的思想非常简单:如果你处于一种状态s,你应该采取会产生最大期望效益的行动a。不难想到,a正是会将我们带到具有最大q值的q状态的操作,于是最优策略可以表达为:
∀ s ∈ S , π ∗ ( s ) = a r g m a x a Q ∗ ( s , a ) = a r g m a x a ∑ s ′ T ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ V ∗ ( s ′ ) ] \forall s\in S,\pi^*(s)=argmax_aQ^*(s,a)=argmax_a\sum_{s'}T(s,a,s')[R(s,a,s')+\gamma V^*(s')] ∀s∈S,π∗(s)=argmaxaQ∗(s,a)=argmaxas′∑T(s,a,s′)[R(s,a,s′)+γV∗(s′)]
为了取得最好的效益,状态的最优q值对策略提取来说是最好的,因为在这种情况下,只需要一次argmax就能确定从一个状态出发的最优行动。仅保存每个
V ∗ ( s ) V^*(s) V∗(s)
意味着我们必须在取argmax之前用Bellman方程重新计算所有必须的q值,相当于进行一次深度为1的expectimax。
策略迭代 Policy Iteration
值迭代可能会很慢。在每次迭代中,我们必须更新所有|S|个状态的值(|n|表示集合中元素的个数),其中每个都要求在我们计算每个行动的q值时对所有|A|个行动进行迭代。对这些每个q值的计算,需要轮流对|S|个状态再次进行迭代,导致时间成本过高
O ( ∣ S ∣ 2 ∣ A ∣ ) O(|S|^2|A|) O(∣S∣2∣A∣)
。此外,当我们只想确定MDP的最优策略时,值迭代会进行大量多余的计算,因为由策略提取得到的策略通常会比值本身更快地收敛。修正这些缺陷的方法就是选择策略迭代,这种算法可以在保持值迭代的最优性的同时还能对表现进行大幅提升。策略迭代的操作如下:
- 定义一个初始策略。这个可以随意定,但是如果初始策略越接近最优策略,策略迭代收敛得也就越快。
- 重复以下操作,直至收敛:
-
用策略评估对当前策略进行评估。对于一个策略π,策略评估意味着计算所有状态s的Vπ(s),其中Vπ(s)表示按照策略π从状态s出发的期望效益:
-
V π ( s ) = ∑ s ′ T ( s , π ( s ) , s ′ ) [ R ( s , π ( s ) , s ′ ) + γ V π ( s ′ ) ] V^\pi(s)=\sum_{s'}T(s,\pi(s),s')[R(s,\pi(s),s')+\gamma V^\pi(s')] Vπ(s)=s′∑T(s,π(s),s′)[R(s,π(s),s′)+γVπ(s′)]
-
把策略迭代的第i次迭代成为πi。由于我们正在对每个状态的一个行动进行修正,我们不再需要取最大的操作max operator,这样我们得到的系统就能有效由以上规则生成的|S|个方程构成的。然后每个
V π i ( s ) V^{\pi_i}(s) Vπi(s)
就可以通过解决这个系统来计算得到。另外,我们还可以选择通过执行以下更新规则直到收敛来计算V π i ( s ) V^{\pi_i}(s) Vπi(s)
。跟值迭代中的操作异曲同工:
V k + 1 π i ( s ) ← ∑ s ′ T ( s , π ( s ) , s ′ ) [ R ( s , π i ( s ) , s ′ ) + γ V π ( s ′ ) ] V^{\pi_{i}}_{k+1}(s)\leftarrow \sum_{s'}T(s,\pi(s),s')[R(s,\pi_i(s),s')+\gamma V^\pi(s')] Vk+1πi(s)←s′∑T(s,π(s),s′)[R(s,πi(s),s′)+γVπ(s′)]
然而,这里第二种方法使其应用起来是明显会慢很多。 -
评估完当前策略后,用策略改进(policy improvement) 来生成更好的策略。策略改进通过对由策略评估生成的状态的值进行策略提取,生成以下改进提升后的策略:
-
π i + 1 ( s ) = a r g m a x a ∑ s ′ T ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ V π i ( s ′ ) ] \pi_{i+1}(s)=argmax_a\sum_{s'}T(s,a,s')[R(s,a,s')+\gamma V^{\pi_i}(s')] πi+1(s)=argmaxas′∑T(s,a,s′)[R(s,a,s′)+γVπi(s′)]
其中,当
π i + 1 = π i \pi_{i+1}=\pi_{i} πi+1=πi
时,算法成功收敛,我们就能得出
π i + 1 = π i = π ∗ \pi_{i+1}=\pi_{i}=\pi_{*} πi+1=πi=π∗
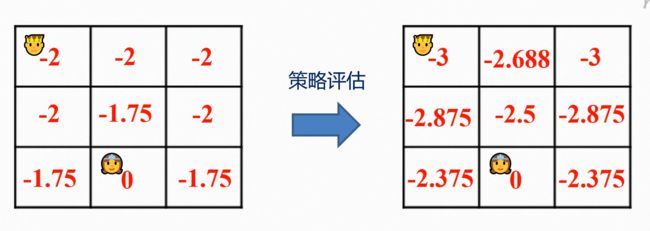
策略迭代就是给定初始策略,不断进行策略评估->策略提取->策略改进直至收敛
这里再次使用知乎博主亦知弦余 的例子, 这个例子的迭代策略是第一种方式
我们把初始策略设为“一直慢速”:
| cool | warm | overheated | |
|---|---|---|---|
| π0 | slow | slow | - |
由于终点状态没有输出的行动,无法给一个终点状态赋值。因此,我们可以从之前的考虑中直接忽略overheated状态,直接对于所有终点状态s都赋值为 slow。下一步就是对于 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K1O8dq12-1652949452813)(https://www.zhihu.com/equation?tex=%5Cpi_%7B0%7D)] 进行一轮策略评估:
V π 0 ( c o o l ) = 1 ∗ [ 1 + 0.5 V π 0 ( c o o l ) ] V^{\pi0}(cool)=1*[1+0.5V^{\pi0}(cool)] Vπ0(cool)=1∗[1+0.5Vπ0(cool)]
V π 0 ( w a r m ) = 0.5 [ 1 + 0.5 V π 0 ( c o o l ) ] + 0.5 [ 1 + 0.5 V π 0 ( w a r m ) ] V^{\pi_0}(warm)=0.5[1+0.5V^{\pi_0}(cool)]+0.5[1+0.5V^{\pi_0}(warm)] Vπ0(warm)=0.5[1+0.5Vπ0(cool)]+0.5[1+0.5Vπ0(warm)]
对这一些列关于
V π 0 ( c o o l ) 和 V^{\pi_0}(cool)和 Vπ0(cool)和
V π 0 ( w a r m ) 的 V^{\pi_0}(warm)的 Vπ0(warm)的
的方程求解可以得到:
| cool | warm | overheated | |
|---|---|---|---|
| Vπ0 | 2 | 2 | 0 |
现在我们就能用这些值进行策略提取了:
π 1 ( c o o l ) = a r g m a x { s l o w : 1 [ 1 + 0.5 ∗ 2 ] + 0.5 ∗ [ 1 + 0.5 ∗ 2 ] , f a s t : 0.5 ∗ [ 2 + 0.5 ∗ 2 ] + 0.5 ∗ [ 2 + 0.5 ∗ 2 ] } = a r g m a x { s l o w : 2 , f a s t : 3 } = f a s t \pi_1(cool)=argmax\{slow:1[1+0.5*2]+0.5*[1+0.5*2],fast:0.5*[2+0.5*2]+0.5*[2+0.5*2]\}=argmax\{slow:2,fast:3\}=fast π1(cool)=argmax{slow:1[1+0.5∗2]+0.5∗[1+0.5∗2],fast:0.5∗[2+0.5∗2]+0.5∗[2+0.5∗2]}=argmax{slow:2,fast:3}=fast
π 1 ( w a r m ) = a r g m a x { s l o w : 0.5 [ 1 + 0.5 ∗ 2 ] + 0.5 ∗ [ 1 + 0.5 ∗ 2 ] , f a s t : 0.5 ∗ [ − 10 + 0.5 ∗ 0 ] } = a r g m a x { s l o w : 2 , f a s t : − 10 } = s l o w \pi_1(warm)=argmax\{slow:0.5[1+0.5*2]+0.5*[1+0.5*2],fast:0.5*[-10+0.5*0]\}=argmax\{slow:2,fast:-10\}=slow π1(warm)=argmax{slow:0.5[1+0.5∗2]+0.5∗[1+0.5∗2],fast:0.5∗[−10+0.5∗0]}=argmax{slow:2,fast:−10}=slow
进行第二轮策略迭代可以得到
π 2 ( c o o l ) = f a s t \pi_2(cool)=fast π2(cool)=fast
以及
π 2 ( w a r m ) = s l o w \pi_2(warm)=slow π2(warm)=slow
。由于这跟 Π1 是一样的策略,我们能得出
π 1 = π 2 = π ∗ \pi_1=\pi_2=\pi^* π1=π2=π∗
。证毕!
| cool | warm | |
|---|---|---|
| π0 | slow | slow |
| π1 | fast | slow |
| π2 | fast | slow |
下面是bilibili博主 Re_miniscence_ 的例子
强化学习(Reinforcement Learning)
在上一篇笔记中,我们讨论了马尔科夫决策过程,我们使用价值迭代和策略迭代等技术来解决这个问题,以计算状态的最优值并提取最优策略·解决马尔可夫决策过程是离线规划的一个例子。agent对过渡函数和奖励函数都有充分的了解,他们需要所有的信息来预先计算由mdp编码的世界中的最佳行动,而不需要实际采取任何行动·在本说明中,我们将讨论在线规划,在此期间,agent对世界(仍表示为mdp)中的奖励或过渡没有预先知识·在在线规划中,代理必须尝试探索,在此期间,它执行行动并接收反馈,反馈的形式是它所到达的后续状态和它所获得的相应奖励.agent通过一个被称为强化学习的过程,使用这种反馈来估计一个最佳政策,然后再使用这个估计的政策进行开发,或奖励最大化.
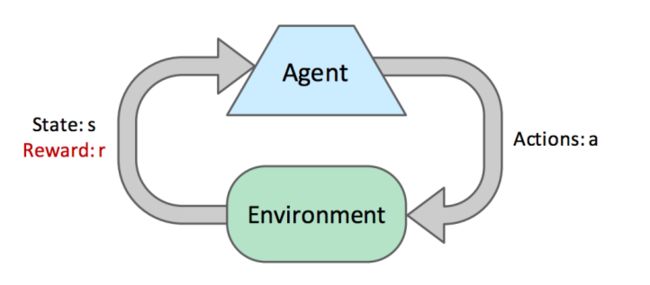
强化学习有两种类型,基于模型的学习和无模型的学习.基于模型的学习试图用探索过程中获得的样本估计过渡和奖励函数,然后用这些估计值或策略迭代来解决mdp.另一方面,无模型学习试图直接估计状态的值或Q值,而不使用任何记忆来构建MDP中的奖励和过渡模型.
基于模型的学习
In model-based learning an agent generates an approximation of the transition function, Tˆ(s,a,s’ ), by keeping counts of the number of times it arrives in each state s 0 after entering each q-state (s,a). The agent can then generate the the approximate transition function Tˆ upon request by normalizing the counts it has collected - dividing the count for each observed tuple (s,a,s’ ) by the sum over the counts for all instances where the agent was in q-state (s,a). Normalization of counts scales them such that they sum to one, allowing them to be interpreted as probabilities. Consider the following example MDP with states S = {A,B,C,D,E, x}, with x representing the terminal state, and discount factor γ = 1:
在基于模型学习中,agent产生一个过渡函数的近似值Tˆ(s,a,s’ )。通过对它进入每一个q状态(s,a)后达到每个状态s’,的次数进行计数,agent可以生成一个近似过度函数T^,方法就是记录每一元组的计数并转化为概率。
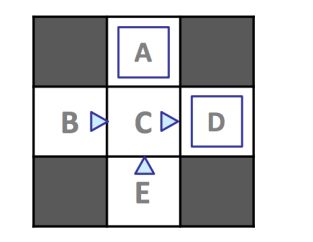
假设我们允许我们的agent根据上述策略π* explore( * 方向三角形表示三角形点方向的运动,蓝色正方形表示选择退出)探索MDP四集,并得出以下结果:
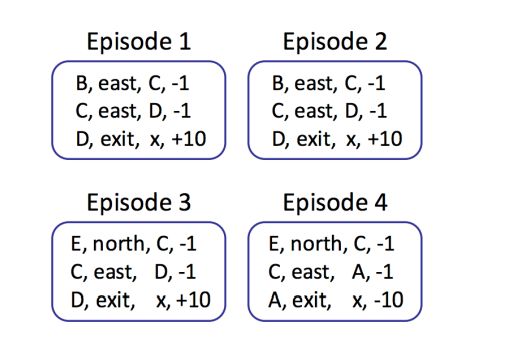
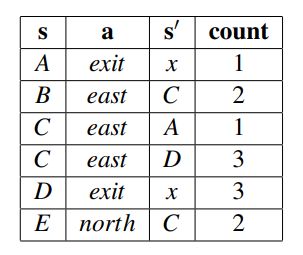
• Transition Function:
Tˆ(s,a,s 0 ) – Tˆ(A, exit, x) = #(A,exit,x) #(A,exit) = 1/ 1 = 1
– Tˆ(B, east,C) = #(B,east,C) #(B,east) = 2 /2 = 1
– Tˆ(C, east,A) = #(C,east,A) #(C,east) = 1/ 4 = 0.25
– Tˆ(C, east,D) = #(C,east,D) #(C,east) = 3 /4 = 0.75
– Tˆ(D, exit, x) = #(D,exit,x) #(D,exit) = 3 /3 = 1
– Tˆ(E,north,C) = #(E,north,C) #(E,north) = 2/ 2 = 1
• Reward Function:
Rˆ(s,a,s 0 ) – Rˆ(A, exit, x) = −10
– Rˆ(B, east,C) = −1
– Rˆ(C, east,A) = −1
– Rˆ(C, east,D) = −1
– Rˆ(D, exit, x) = +10
– Rˆ(E,north,C) = −1
By the law of large numbers, as we collect more and more samples by having our agent experience more episodes, our models of Tˆ and Rˆ will improve, with Tˆ converging towards T and Rˆ acquiring knowledge of previously undiscovered rewards as we discover new (s,a,s 0 ) tuples. Whenever we see fit, we can end our agent’s training to generate a policy πexploit by running value or policy iteration with our current models for Tˆ and Rˆ and use πexploit for exploitation, having our agent traverse the MDP taking actions seeking reward maximization rather than seeking learning. We’ll soon discuss methods for how to allocate time between exploration and explotation effectively. Model-based learning is very simple and intuitive yet remarkably effective, generating Tˆ and Rˆ with nothing more than counting and normalization. However, it can be expensive to maintain counts for every (s,a,s 0 ) tuple seen, and so in the next section on model-free learning we’ll develop methods to bypass maintaining counts altogether and avoid the memory overhead required by model-based learning.
基于无模型的学习
离线学习(off-line)也通常称为批学习,是指对独立数据进行训练,将训练所得的模型用于预测任务中。将全部数据放入模型中进行计算,一旦出现需要变更的部分,只能通过再训练(retraining)的方式,这将花费更长的时间,并且将数据全部存在服务器或者终端上非常占地方,对内存要求高。Q学习就是离线学习
在线学习(in-line)也称为增量学习或适应性学习,是指对一定顺序下接收数据,每接收一个数据,模型会对它进行预测并对当前模型进行更新,然后处理下一个数据。这对模型的选择是一个完全不同,更复杂的问题。需要混合假设更新和对每轮新到达示例的假设评估。换句话说,你只能访问之前的数据,来回答当前的问题。
T-D学习(Temporal Difference Learning)被动强化学习
TD学习的基本思想是从每一次经验中学习(这里我的理解是从v中学习,一定程度上也可以称为v学习),而不是像直接评估那样简单地记录总奖励和访问状态并在最后学习。在策略评估中,我们使用固定策略和贝尔曼方程产生的方程评估该策略下的状态值:
V π = ∑ s ′ T ( s , π ( s ) , s ′ ) [ R ( s , π ( s ) , s ′ ) + γ V π ( s ′ ) ] V^\pi = \sum \limits_{s'}T(s,\pi(s),s')[R(s,\pi(s),s')+\gamma V^\pi(s')] Vπ=s′∑T(s,π(s),s′)[R(s,π(s),s′)+γVπ(s′)]
等号后面的含义是后继者的折现值的加权平均值加上过渡到这些状态获得的奖励。我们可以从V(s)=0开始,在每个时间段,agent从状态s采取行动Π(s)过渡到S^t,并获得一个奖励R(s,Π,st)。我们可以通过将策略Π下收到折现的奖励与收到的奖励求和得到样本值:
s a m p l e = R ( s , π ( s ) , s ′ ) + γ V π ( s ′ ) sample=R(s,\pi (s),s')+\gamma V^\pi (s') sample=R(s,π(s),s′)+γVπ(s′)
这个sample是VΠ(s)的一个新估计。下一步是将估计值纳入我们现有的移动平均数的VΠ(s)模型,该模型遵守以下更新规则:
V Π ( s ) ← ( l − α ) V π ( s ) + α s a m p l e V^Π(s)\leftarrow (l-\alpha)V^\pi (s)+\alpha sample VΠ(s)←(l−α)Vπ(s)+αsample
α是一个称为学习率的参数,指定了我们要新采样的权重为α,现有模型的权重为(1-α)
这是一个迭代更新的过程:
V k Π ( s ) ← ( l − α ) V k π ( s ) + α . s a m p l e k V^Π_{k}(s)\leftarrow (l-\alpha)V^\pi_{k} (s)+\alpha .sample_{k} VkΠ(s)←(l−α)Vkπ(s)+α.samplek
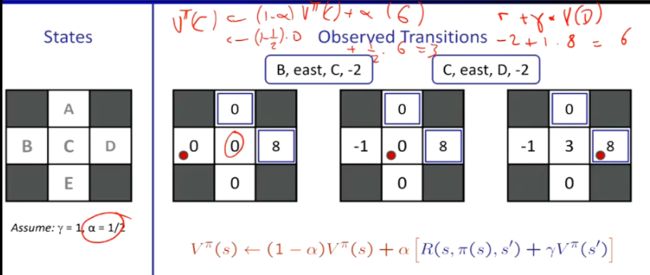
这里结合一张ppt给出的实例
Q-学习(Q-Learning)主动强化学习
T-D学习最终会学到他们所遵循的policy下所有状态的真实价值。
但是我们想为agent找到一个最佳政策,这还需要知道状态的q值,也就是动作值,正如贝尔曼方程中的q状态的最优值的方程:
Q ∗ ( s , a ) = ∑ s ′ T ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ V ∗ ( s ′ ) ] Q^*(s,a)= \sum_{s'} {T(s,a,s')[R(s,a,s')+\gamma V^* (s')]} Q∗(s,a)=s′∑T(s,a,s′)[R(s,a,s′)+γV∗(s′)]
q值迭代 q-value iteration:
Q k + 1 ( s , a ) ← ∑ s ′ T ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ m a x s ′ Q k ( s ′ , a ′ ) ] Q_{k+1}(s,a)\leftarrow\sum\limits_{s'}{T(s,a,s')[R(s,a,s')+\gamma max_{s'} Q_k(s',a')]} Qk+1(s,a)←s′∑T(s,a,s′)[R(s,a,s′)+γmaxs′Qk(s′,a′)]
With this new update rule under our belt, Q-learning is derived essentially the same way as TD learning, by acquiring q-value samples:
s a m p l e = R ( s , a , s ′ ) + γ m a x a ′ q ( s ′ , a ′ ) sample=R(s,a,s')+\gamma max_{a'}q(s',a') sample=R(s,a,s′)+γmaxa′q(s′,a′)
and incoporating them into an exponential moving average.
Q ( s , a ) ← ( 1 − α ) Q ( s , a ) + α . s a m p l e Q(s,a) \leftarrow (1-\alpha)Q(s,a)+\alpha.sample Q(s,a)←(1−α)Q(s,a)+α.sample
只要我们花足够长的时间进行探索,并以适当速率降低学习率α,Q学习就能学习到每个q状态的最优q值。

下面来具体计算一个案例

这里给出收益和惩罚的计算过程



-
Model-based and model-free RL agents both use exploration to learn about the environment (rewards and transitions)
-
Model-free learning can be either off-policy or on-policy depending on the type of algorithm (ex. TD learning vs Q-learning).
-
Both model-based and model-free rerquire online interaction with the environment.
机器学习
熵
首先我们要知道,信息的作用是什么,信息的作用是消除不确定性
生活中,我们也会遇到各种各样的信息,而信息一般都有信息量,什么是信息量呢,比如我们评价一句话是废话,那么这个信息的信息量就很少甚至没有,评价一句话精辟,说明这个信息的信息量比较大。
该部分参考bilibili博主RethinkFun
传送门

比如上面的例子,可以看出,信息量是逐渐增大的。第一句话没有消除投掷骰子的不确定性,第二句话消除了一半的不确定性,而第三句话直接消除了不确定性。
那什么是信息的价值?
信息量
I = − l o g 2 p I=-log_2p I=−log2p
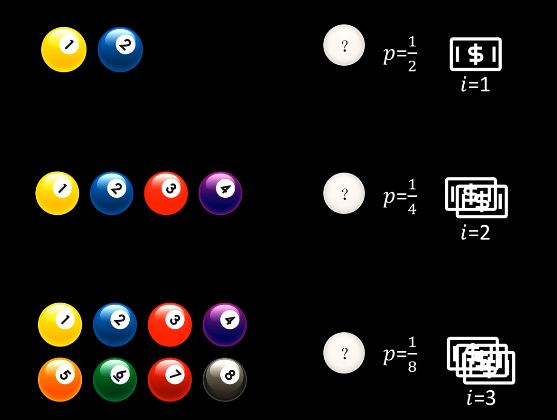
在以上案例中,我们根据信息猜出所取到的小球,那么每个信息的价值就可以通过以上公式计算出来,可以看出,信息消除的不确定性越大,也就是概率越低的事件,其对应的信息价值也就越高,这也是符合常理的。
以上公式的底数是2,原因就是信息中只有两个选择,yes或no,根据这个提示我们才选出的结果。所以最后信息的价值单位为bit,这里的单位和公式中的底数是对应的,只是衡量价值大小,就像米和千米那样的关系
有了这个公式,我们可以计算上面骰子的例子中三个信息的价值,第一句发生的概率为1,也就是p=1,得出I=0,也就是信息价值为0,相应的,第二句话信息价值为1(bit),第三句话信息价值为2.58(bit)。
熵
有了以上基础,我们就可以认识熵,首先我们认识信息熵的公式:
H ( x ) = ∑ i = 1 n p ( x i ) I ( x ) H(x)=\sum _{i=1}^{n}p(x_i)I(x) H(x)=i=1∑np(xi)I(x)
从公式上理解,信息熵其实就是一个系统中所有事件所有事件发生时提供的信息量与它发生概率的乘积进行累加。
也即是说,如果一个系统里是由大量小概率事件构成,那么他的信息熵就很大。
信息熵描述的就是一个系统的复杂或者混乱程度
热力学中的熵同样如此,系统越混乱,熵就越大
H ( x ) = E x [ l o g 1 p ( x ) ] = ∑ x p ( x ) l o g 1 p ( x ) H(x)=E_x[log\frac{1}{p(x)}]=\sum_{x}p(x)log\frac{1}{p(x)} H(x)=Ex[logp(x)1]=x∑p(x)logp(x)1
两个离散随机变量 X 和 Y的联合熵 (Joint Entropy) 为:
H ( X , Y ) = E x , y ∼ p ( X , Y ) [ l o g 1 p ( X , Y ) ] = ∑ x , y p ( x , y ) l o g 1 p ( x , y ) H(X,Y)=E_{x,y\sim p(X,Y)}[log\frac{1}{p(X,Y)}]=\sum_{x,y}p(x,y)log\frac{1}{p(x,y)} H(X,Y)=Ex,y∼p(X,Y)[logp(X,Y)1]=x,y∑p(x,y)logp(x,y)1
联合熵表征了两事件同时发生系统的不确定度。
以下条件熵 (Conditional Entropy) 表示在已知随机变量 Y的条件下随机变量 X 的不确定性。
H ( X ∣ Y = y ) = E x ∣ y ∼ p ( X ∣ y ) [ l o g 1 p ( X ∣ y ) ] = ∑ x , y p ( x , y ) l o g 1 p ( x ∣ y ) H(X|Y=y)=E_{x|y\sim p(X|y)}[log\frac{1}{p(X|y)}]=\sum_{x,y}p(x,y)log\frac{1}{p(x|y)} H(X∣Y=y)=Ex∣y∼p(X∣y)[logp(X∣y)1]=x,y∑p(x,y)logp(x∣y)1
H ( X ∣ Y ) = E x , y ∼ p ( X , Y ) [ l o g 1 p ( X ∣ Y ) ] = ∑ x , y p ( x , y ) l o g 1 p ( x ∣ y ) H(X|Y)=E_{x,y\sim p(X,Y)}[log\frac{1}{p(X|Y)}]=\sum_{x,y}p(x,y)log\frac{1}{p(x|y)} H(X∣Y)=Ex,y∼p(X,Y)[logp(X∣Y)1]=x,y∑p(x,y)logp(x∣y)1
KL散度
K ⊥ ( p ( x ) ∣ ∣ q ( x ) ) = ∑ x p ( x ) log 1 q ( x ) K \perp(p(x)||q(x))=\sum_x p(x)\log{\frac{1}{q(x)}} K⊥(p(x)∣∣q(x))=x∑p(x)logq(x)1
互信息
I ( X , Y ) = ∑ X ∑ Y p ( x , y ) log 1 p ( x ) p ( y ) − ∑ X ∑ Y p ( x , y ) log 1 p ( x , y ) I(X,Y)=\sum_X\sum_Y p(x,y)\log \frac{1}{p(x)p(y)}-\sum_X\sum_Y p(x,y)\log \frac{1}{p(x,y)} I(X,Y)=X∑Y∑p(x,y)logp(x)p(y)1−X∑Y∑p(x,y)logp(x,y)1
熵,联合熵,条件熵,互信息之间的关系
H ( X , Y ) ≥ H ( X ) , H ( Y ) H(X,Y)\geq H(X),H(Y) H(X,Y)≥H(X),H(Y)
H ( X ) ≥ H ( X ∣ Y ) H(X)\geq H(X|Y) H(X)≥H(X∣Y)
H ( X , Y ) = H ( X ∣ Y ) + H ( Y ∣ X ) + I ( X , Y ) H(X,Y)=H(X|Y)+H(Y|X)+I(X,Y) H(X,Y)=H(X∣Y)+H(Y∣X)+I(X,Y)
这里给出他们之间的关系图

我们再来看在一个系统中熵随概率p的变化曲线
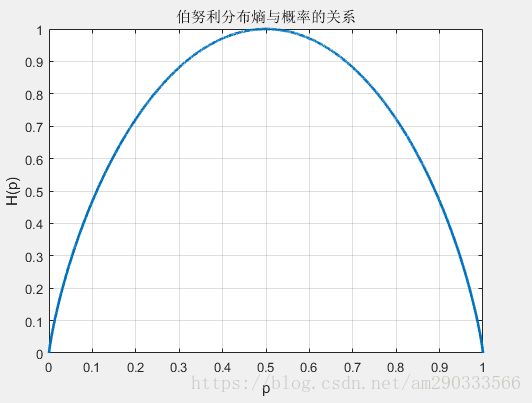
明显看出,当p=0.5时,信息熵是最大的,也就是说所有事件发生可能性相同,也就代表这系统的不确定越大,系统越混乱,随之信息熵也就越大。
决策树
什么是决策树?
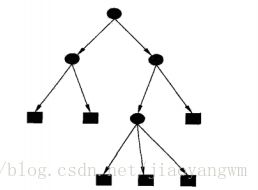
首先我们来看决策树的形式,以上就是一个决策树,圆形节点是内部节点,方形节点是页节点。
决策树的目的
给定训练数据集构建决策树模型,使他能够对实例进行正确分类,并预测最后的结果。
如何构建决策树
这里用到了我们之前的熵的概念,我们能根据熵来判断这个系统的混乱程度,也就是不确定度,我们希望在根节点进行划分时,得到的结果的熵尽可能的小,也就是划分的结果要尽可能的清晰而不是混乱。
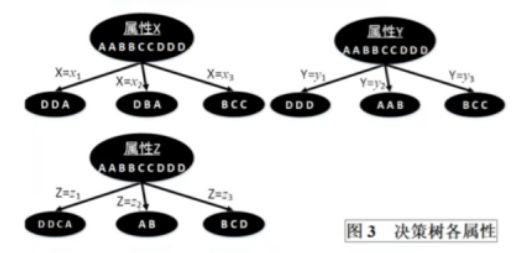
下面是计算信息熵的过程

上面的结果可以得出,第一步要根据Y来划分,这样可以使得系统的不确定性最低。