递归
1、递归基本概念
递归的意思就是不停的调用自己,但是我们要知道的是我们的计算机资源是有限的,一般来说递归的层数不能太深(特别是自己写的程序有问题容易资源耗尽!)。递归通常来说是程序写着简洁但是人的思维量比较大同时计算机的执行效率没有直接写的代码效率高,因为存在函数的不停调用,在计算内部调用函数是开销比较大的。什么是递归什么是自己调用自己,举个简单的例子:
int mul(int x){
x--;
mul(x);
}我们能够清晰的看见上面的程序存在自己调用自己的情况,那么这种就叫做递归,只是上面的递归并不规范!甚至是有问题的,为什么呢?因为我们思考一下这个函数的执行过程如下:
当我们传入x = 5
第一次执行:x-- --------> x变成了4,然后再调用自己,x=4作为参数传入
第二次执行:x-- ---------->x变成了3,然后再调用自己,x=3作为参数传入
。。。
这个程序永远不会结束,
所以从上面的例子我们可以看出来写递归喝循环一样,必须要有个结束条件,我们称之为出口!加入现在我有一道题目是我要求解一个数的阶乘,那么我们的递归程序可以写成:
// 先写一个简单的,这是个全局变量
int result = 1;
void mul(int x){
// 这就是我们说的出口
if(x==0) return;
result *= x;
// 递归
mul(x-1);
}你可能会说上面这个例子我用一个循环就很好的解决了,确实是递归大部分能转化成循环(特别是while循环,但是你的思考量将会提高N倍!!!)递归可以让我们不用纠结于中间的复杂过程,你只用专注于分支条件和出口即可!
现在我们来优化上面的简单的递归程序,通常我们的c语言中不喜欢用全局变量,但是程序再递归的时候,我们需要的有记忆的变量不能直接申请再函数中(有记忆的变量是指函数每次调用自己的时候需要上一次的值,不能被刷新!我还是举例说明吧:),如果上面的程序我写成:
void mul(int x){
if(x == 0) return;
// 不能这么写,每次都被刷新了,
int result = 1;
result *= x;
mul(x-1);
}那么对于这种需要有记忆的变量我们递归通常把其作为参数!让参数帮助我们记忆,所以上面的程序可以优化成:
阶乘递归版本1:
void mul(int x, int result){
if(x == 0) return;
result *= x;
// 这样就每次帮我们记住了乘积并且传入到了下一次
mul(x-1,result);
}当然上面的程序是有问题的,不过问题不在递归,就递归这个问题来说上面的程序是比较优秀的写法了。(问题在于c语言是传值的,穿进去的变量在函数里面修改了在外面是看不出来效果的!)
在提供一个上面的递归版本:
阶乘递归版本2:
int mul(int x){
if(x == 1) return 1;
return x* mul(x-1);
}着两个版本版本2看着好像简单一些,但是版本1的效率要高很多:
版本1:尾递归,递归的程序放在函数的最后面,并且递归不在任何的表达式中,如版本1
版本2:普通递归,递归的程序不在函数肚饿尾部,或者说在一个表达式中,效率不如尾递归。
详细的可以自己百度!!!
至此我们知道了递归最重要的东西:
1、出口
2、如何记住需要有记忆的变量
2、为什么要有递归?
就像刚才的例子你肯定会说递归很麻烦,但是我想说的是你naive了,递归真正的优点是:
1、缩小问题的规模
2、可以让我们不用思考中间过程
直接用题目举例:
100梯的阶梯,我现在每次能走1步或者2步,那么我有多少种走法呢?
解题思路:
从100梯往回思考:
你只能是 99----->100. step(99)+1
98----->100 step(98)+2
在从99往回思考:
98----->99. step(98)+1
97----->99. step(97)+2
我觉得你应该发现什么了,最关键的是
step(i) = step(i-1) + step(i-2)
第i梯只有两种走法能够走到,那就是i-1走一梯,i-2走两梯
所以程序是:
int step(int x){
// 出口有两个
if(x == 1) return 1;
if(x == 2) return 2;
// 这个算什么递归呢?
return step(x-1)+step(x-2);
}上面的代码有两个出口,因为第一梯只有一种走法,我们非常的确定,第二梯有两走走法(1+1 或者 2),我们也非常的确定。然后中间的过程我们就不用考虑了!!!!
现在问个问题:上面的递归属于尾递归还是普通递归????
总结:递归通常来说就是由分支条件+出口+状态的递归构成!
题目1、
输入一个数组,输出数组中数据的所有全排列组合!!
例如:
输入:[1,2]
输出:[1,2]、[2,1]
样例2、
输入:[1,2,3]
输出:[1,2,3]、[1,3,2]、[2,1,3]、[2,3,1]、[3,1,2]、[3,2,1]
一次类推
上面的题目一只是运用了递归的不用考虑中间过程
3、递归与暴力美学
通常来说我们的递归可以暴力解决很多的题目并且不需要我们过多的纠结与中间的过程,这就是递归的优点,什么叫暴力呢?对于任何一个编程问题,我们认为其有解那么必定就是存在一种从开始到结束的状态序列。 举例说明我们下围棋,为什么机器能够战胜人类?其实机器战胜人类是必然的,为什么呢?如果步考虑计算机资源的限制我直接暴力列举出从开始下棋到结束下棋的每个局面,然后根据人的走不自动匹配路径即可。这里的棋局就可以看成一个状态:

如上图是围棋的开局,我们可以看成是一个其实状态,那么接下来的一个状态就可能有19*19种可能(围棋的棋盘式19*19),当人走出了第一步之后,现在棋局又回归到了相同的问题:在一个棋盘上计算机需要走出最有利(或者说更加接近赢面的棋局,这就是递归)。此时计算机又19*19-1(种可能)

任何问题的解都可以抽象成上述的一个树形的解空间,像这种我们用循环式无法求解的,因为首先是训话你的次数不知道,其次循环无法表示这种层级的结构,如果每个状态都是相似的问题或者局面,那么我们使用递归肯定能构造出(列举出)解空间的所有可能,因此必定能解决这个问题,只是时间复杂度可能有时候比较高,但是这并不能阻挡这个美丽的方法!
3.1、使用举例:
我们就着上面的讲解做一个题目,假定现在在一个棋盘上下五子棋,你执白,计算机执黑,现在要求你判断某个局面你们谁赢了。
每个棋局的局面用一个二位数组输入,白棋用1代表,黑棋用2代表,空位置用0代表
样例1、
输入:(12*12的数组)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 2, 2, 2, 1, 0, 0, 0]
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 1, 1, 2, 2, 0, 0, 0, 0]
[0, 0, 2, 1, 0, 1, 1, 2, 0, 0, 0, 0]
[0, 0, 2, 0, 1, 0, 1, 2, 0, 0, 0, 0]
[0, 0, 0, 1, 0, 0, 0, 2, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
上面的棋局黑方连成5个,那么计算机获胜!!!
输出:计算机胜
现在我们一起来分析这个题目:
TIPS:注意五子棋可以斜着来的!!!
解题思路:
我们直接用一个循环遍历所有的位置,当遇见当前位置不是0,那么说明有人下棋了,假定下棋的是你,也就是该位置是1,那么你就需要判断周围的情况,那么此时你就可以假设你自己会试探型的去挪动到周围的一位位置,挪动后你会发现你又面临相同的问题------判断周围的情况!显然这就是递归,那么借助上面的思路我们的代码大概可以长成这样:
int n = 12;
for(int i = 0;i < n;i++){
for(int j = 0;j < n;j++){
if(chess[i][j] == 1){
//需要递归
whiteWin(chess,i,j,1);
}
}
}
//递归的函数
//第一个参数是棋盘数组
//第二个参数是行,第三个参数是列
//第四个参数是,数我们已经几颗棋子连在一起了
bool whiteWin(int [][]chess,int i,int j,int count){
if(chess[i][j] != 1){
//已经5子连珠
if(count == 5) return true;
else return false; //没有,但是前面也不是白棋了,不能继续前进了
}
// 向左边前进,这就是递归,我们传入的棋盘数组是不会改变的,不停改变的就是我们当前处于
// 哪一颗棋子,也就是i和j,那么这次往左边走就是 j-1,count+1代表的是当前路径连接的
// 棋子增加了一颗
bool left = whiteWin(chess,i,j-1,count+1);
//同理自己写其余几个方向!!!!
// 最后返回8个方向的综合后的结果,只要有一个满足就行了
return left || right ||...
}请你下去不全剩余的代码!!!!!!
4、递归与问题规模的缩小
上面的暴力美学美归美,但是并不是任何时候都是可取的,比如就是下棋的时候,列举所有棋局的可能至少在目前的计算机内存肯定是远远不够的,那么我们在解决其他的问题也是类型的,我们需要将问题的规模逐步缩小,然后求解缩小后的规模,比如我举个例子,我们可以使用递归的方式来遍历一个数组!
假定数组是:1,2,3,4,5,6,7,8,9
void dis(int []data,int index){
printf("%3d",data[index]);
//当然这里不是很贴切,数组index前面的部分就已经没用了,我们接下来面对的问题规模就是
//数组长度-index
dis(data,index+1);
}我们每次输出一个数据后,假定该数据就不见了,那么数组的长度在不停的变短,这就是问题规模的缩小!!!
很简单的例子上面的爬梯子就是这类型的,问题规模被我们不断的缩小,下面我再给出一个案例:
假定我现在要对一个数组进行排序:
8,11,9,12,3,23,32,17,5
我们都学过冒泡排序,但是这个并不够快,我提供一个思路:
我们是否可以将数据分组,然后再分组内排序后再合并,因为分组和两边的工作是可以同时进行的(现实中确实这样比你一个计算机排序快,这就好比我可以用多台计算机一起协作的做同一个事情),我们先分为:
8,11,9,12,3
23,32,17,5
然后再分:
8,11,9
12,3
23,32
17,5
上面4组就非常的好排序,我们将一个问题规模比较大的问题分解为了几个规模较小的问题,我们先解决小问题然后再合并解就行了。
合并过程举例:
例如排好序后是:
8,9,11
3,12
23,32
5,17
然后我们两来那个合并:
---》3,8,9,11,12
---》5,17,23,32
然后再合并
我们可以看出来分解问题和合并解的过程都是一个递归的过程(每个状态面度爹问题规模都是一样的!)
5、递归与回溯
什么叫回溯呢?举个简单的例子就是你走迷宫,最古老有效的办法就是在你身上拴一根绳子,然后你遇见岔路口就随便选一个,走到头出不去,那么就回头沿着绳子的方向回到上一个岔路口再选择下一个路口继续前进!对没错沿着原路返回,时空倒流这就是回溯,为什么要有这个呢,例如这道题目:

到底走到了一个位置我应该怎么走呢?(有两种选择),你不可能保证你每次的选择就是最优秀的,有的人说我可以选择当前代价最小的方向前进呀!!但是问题是当前代价最小的位置后面的位置可能让你付出惨痛的代价,不要目光短浅,要全局考虑!因此最好的办法就是每次走到头,发现不行了再倒回去,把前面做的所有的事情全部回归原样,这样就好像时光倒流了一样(回溯),但是你已经可以知道这个岔路口出不去了,我们不要走它....以此类推,这就是回溯,类似上面的全排列我们也做了回溯的操作!
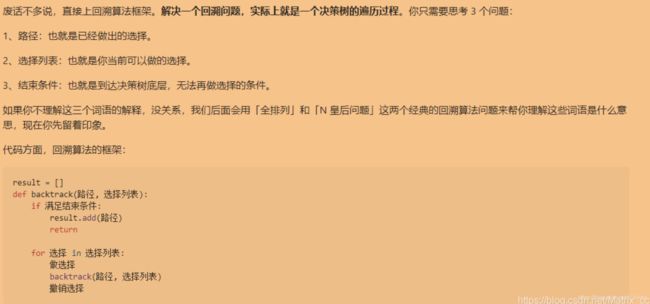
关键点就在最后一个for循环里面,我们把所有的代选择的决策全部放在里面遍历,经典的回溯题目举例:
题目1、
自己百度leetcode,进入英文的那个,不要进入力扣中文的!需要你注册账号
leetcode 第51题 (这个刷题网站题目比较难,我叫你做多少你就做多少)
TIPS:记住我和你说的写递归的代码风格:
递归的函数:
出口结束条件
违法判断
作出选择
递归
撤销选择
请务必按照上面的风格进行编写代码!!!!!!!
还有就是带返回值的递归比不带返回值的递归难,如果不是很清楚就把想返回的值放在参数重,用指针传递,想要获取或者修改的时候都能反应到外部!!
6、递归的加速---剪枝
剪枝的由来其实很简答, 任何问题的解都可以抽象成一个解空间,那么解空间就长这样,其中的一个解就是从根节点到叶子节点的整个路径。但是我们肯定遇见过这种问题:在搜索答案的时候已经发现了当前的这个分支已经不存在了,那么还有必要继续往下匹配下去吗?答案是显然的,我们有时会要学会放弃,就好比你刮奖,如果刮出来了一个谢字那么久没必要往下面刮下去了。
可能看到这里你已经明白了,剪枝剪枝顾名思义就是把整个解空间树给剪掉一些压根就不可能的节点,因为树状结构的特点,我们的树你越早发现是否合适那么就会节省越多的时间!!因此剪枝要趁早!!越早确认一个节点不行,那么后面少遍历的节点可能是成千上万的,本来递归不停的调用函数效率就低!!
6.1、剪枝常见手段1----设置阈值
对于常见的需要我们递归的遍历找最大值和最小值的情况,我们通常在外面(可以是全局变量,也可以通过参数传入)设置一个变量来记录最大值和最小值,如果在遍历的途中就超过这个阈值那么就可以直接舍弃掉后续的遍历,这个的搜索效率会不停的提高,越到后面剪枝的幅度越大,脑补前面剪枝的阈值并不严格,但是随着剪枝次数越来越多,选出来的阈值越来越优秀,这就类似正太分布,大部分的节点都是大于阈值的。
典型题目:
https://leetcode.com/problems/cherry-pickup/
自己百度leetcode,进入英文的那个,不要进入力扣中文的!
leetcode 第741题(这个刷题网站题目比较难,我叫你做多少你就做多少)
leetcode 第64题
6.2、剪枝常见手段2---设置标志量
在有的题目中,我们通常在统计的时候为了避免出现环路,重复的走,会给每个走过的格子都打上标记。举例说明:
题目1:
给定一个二维数组,其中全部是0和1,1代表岛屿,0代表海洋,连着的岛屿被认为是一个岛屿(这些岛屿有个特点,都是往右边或者下边延伸的),我们现在要求面积最大的岛屿面积!
往右边或者下边延伸的意思就是值不会出现:
输入:
二维数组:
1 0 0 1 0 0 0 1
1 0 1 1 0 0 0 1
0 0 0 0...
(具体案例自己举几个测试,我没找到这个题目)
上面这个的解题思路是,设置一个标志量,bool flag[][];走过的地方都打上true,要是递归遇见了就回去,说明已经走过了!!(因为这道题目并没有说只能往哪个方向走!!)
题目2:
https://www.nowcoder.com/practice/c61c6999eecb4b8f88a98f66b273a3cc?tpId=13&&tqId=11218&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking
上面的是牛客网,这个也可以刷一些题目,这道题目是关于回溯比较经典的
6.3、剪枝常见手段3---利用高速算法找出较好的解
因为我们的递归通常来说比较慢,我们的初始剪枝速度可能会比较缓慢,如果我们能找到一个高速的算法(解不一定要最优),那么先用高速的算法计算出一个阈值,然后再利用这个阈值剪枝,效果是比较良好的!通常来说我们的高速算法可以选择贪心算法!
例题:暂时没找到合适的