Scrapy各种反反爬机制你都知道吗?
爬虫之Scrapy系列文章
欢迎点赞评论学习交流~
各位看官多多关注哦~

目录
内容介绍
Scrapy如何设置请求头?
Scrapy获取数据过快被封ip该如何处理?
Scrapy如何动态获取数据你知道吗?
Scrapy程序出现Bug给你发邮件想学习吗?
Scrapy请求头设置
Scrapy设置时间间隔
Scrapy动态获取数据
Scrapy发邮件
结束
内容介绍
Scrapy如何设置请求头?
Scrapy获取数据过快被封ip该如何处理?
Scrapy如何动态获取数据你知道吗?
Scrapy程序出现Bug给你发邮件想学习吗?

芜湖 起飞~
Scrapy请求头设置
学过爬虫的和没学过爬虫的都应该听说过请求头。请求头它是访问一个网站时,发送请求时所携带的一种用户标识,哈哈,明白这些就行了,那用Scrapy框架时该如何把固定的请求头换成我们想要的请求头呢?往下看~

创建一个项目,找到TextSpiderMiddleware,这个是爬虫中间键。
#随机user-agents
import random
class RandomUserAgentMiddleware():
def __init__(self):
self.user_agents = [
'Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2',
'Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1'
]
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(self.user_agents)我们添加以上代码,这里我只写了三个请求头,可自行添加。作用是设置随机请求头。

添加了代码后我们要去settings.py中放开DOWNLOADER_MIDDLEWARES,再将我们的类名写入并指定优先级。
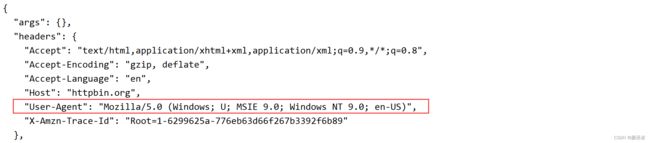
网址:https://httpbin.org/get
我们访问它可以得到我们请求服务器的一些参数,我们发现这时User-Agent已经变成了我们设置的随机请求头中的一个。
Scrapy设置时间间隔
对于一些做过反爬的网站,可能你去用Scrapy去获取数据时他可能会限制你的爬取速度,你一旦触及到了它设置的反爬机制你就爬不到数据了,对于Scrapy框架这种神级框架它也有对此的应对策略。

同样的我们进入到这个包中。
import time
import logging
# 设置随机延时
class RandomDelayMiddleware(object):
def __init__(self, delay):
self.delay = delay
@classmethod
def from_crawler(cls, crawler):
delay = crawler.spider.settings.get("DOWNLOAD_DELAY", 1) #setting里设置的时间,注释默认为1s
if not isinstance(delay, int):
raise ValueError("RANDOM_DELAY need a int")
return cls(delay)
def process_request(self, request, spider):
# delay = random.randint(0, self.delay)
delay = random.uniform(0, self.delay)
delay = float("%.1f" % delay)
logging.debug("### time is random delay: %s s ###" % delay)
time.sleep(delay)添加以上代码。作用是对访问进行随机延时处理。

进入到settings.py文件,添加text.middlewares.RandomDelayMiddleware,设置优先级即可,再找到DOWNLOAD_DELAY = 3放开。我们测试一波~

控制台帮我们打印出了延迟的时间2.2s,这个延迟范围为(0,3)。
Scrapy动态获取数据
爬虫基础学习中我们学过selenium自动化处理一些模拟登录和静态html数据的获取的案例。Scrapy框架该如何设置动态获取数据呢?
#配置动态数据采集
from selenium import webdriver
from logging import getLogger
from scrapy.http import HtmlResponse
from pyppeteer import launch
import asyncio
class SeleniumMiddleware():
def __init__(self):
self.logger = getLogger(__name__)
# self.timeout = random.randint(1,3)
#PhantomJS.exe的路径
self.browser = webdriver.PhantomJS(executable_path=r'D:\Phantomjs\phantomjs-2.1.1-windows\phantomjs-2.1.1-windows\bin\phantomjs.exe')
self.browser.set_window_size(1400, 700)
# self.browser.set_page_load_timeout(self.timeout)
# chrome浏览器
def process_request(self, request, spider):
self.logger.debug('PhantomJS is Starting')
self.browser.get(request.url)
body = self.browser.page_source
return HtmlResponse(url=request.url, body=body, request=request, encoding='utf-8',status=200)
# ppeteer浏览器
# def process_request(self, request, spider):
# page_html = asyncio.get_event_loop().run_until_complete(self.main(request.url))
# return HtmlResponse(url=request.url, body=page_html, request=request, encoding='utf-8', status=200)
#
# async def main(self, url):
# browser = await launch()
# page = await browser.newPage()
# await page.goto(url)
# text = await page.content()
# return text
#关闭浏览器
def __del__(self):
self.browser.close()这里我们结合PhantomJS无头浏览器来获取数据,下面有两种打开方式一种是Chrome浏览器,还有一种是ppeteer浏览器。

控制台打印出这句话时,说明你已经启动了PhantomJS无头浏览器。
Scrapy发邮件
当我们在用Scrapy框架爬取大量数据时,程序可能要运行很久,当程序出现bug时如何及时告知爬虫程序有bug呢?我们可以接入python自带的邮件发送库,当程序出错时自动发送一封邮件到你的手机上告诉你程序出错了,是不是很神奇~
讲这个内容前我先说一说如何开启qq邮箱的POP3/SMTP服务,就是你开启了这个服务后,可以通过代码来给别人发邮件,当然也可以给自己发~

登录电脑版的qq邮箱--->账户--->POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务
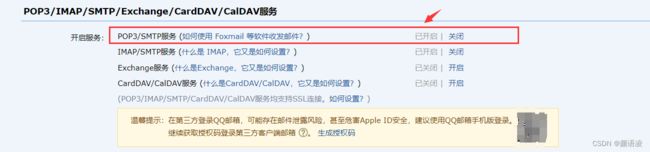
按照提示步骤开启就行,记住短信发送来的授权码。做完这些后我们来测试一波~
import scrapy
from pydispatch import dispatcher
from scrapy import cmdline, signals
from scrapy.mail import MailSender
#配置邮件发送功能
class XxxSpider(scrapy.Spider):
name = 'xxx'
# allowed_domains = ['xx.com']
# start_urls = ['https://careers.tencent.com/search.html?keyword=python']
start_urls = 'https://careers.tencent.com/search.html?index={}&keyword=python'
start_urls = 'https://httpbin.org/get'
mailers = MailSender(smtphost="smtp.qq.com", # 发送邮件的服务器
mailfrom="[email protected]", # 邮件发送者
smtpuser="[email protected]", # 用户名
smtppass="*", # 发送邮箱的密码不是你注册时的密码,而是授权码!!!切记!
smtpport=25 # 端口号
) # 初始化邮件模块
def __init__(self):
""" 监听信号量 """
super(XxxSpider, self).__init__() # 当收到spider_closed信号的时候,调用下面的close方法来发送通知邮件
dispatcher.connect(self.spider_closed, signals.spider_closed)
def spider_closed(self, spider, reason):
# 上方的信号量触发这个方法
stats_info = self.crawler.stats._stats # 爬虫结束时控制台信息
body = "爬虫[%s]已经关闭,原因是: %s.\n以下为运行信息:\n %s" % (spider.name, reason, stats_info)
subject = "[%s]爬虫关闭提醒" % spider.name
self.mailers.send(to={"[email protected]"},
subject=subject,
body=body)
def start_requests(self):
for i in range(1, 3):
yield scrapy.Request(url=self.start_urls.format(i), callback=self.parse)
# yield scrapy.Request(url=self.start_urls,callback=self.parse)
def parse(self, response):
print(response.text)
以上是测试代码~
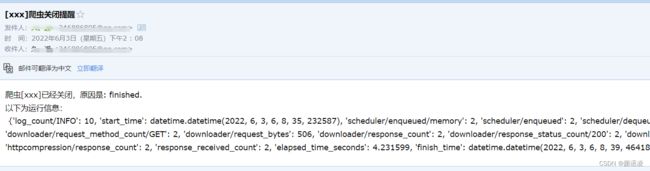
已收到爬虫结束的邮件
结束
