【个人学习文章收集】
目录
- 深度学习
-
- 常用的优化方法和常见概念
- 神经网络结构
- tensorflow1.x框架
- 计算机视觉
- 自然语言处理
- Pytorch
- 数据挖掘与机器学习
- 计算机网络
- 传统图像处理
- 网页
- 操作系统
- Linux
- Python语法
-
- 基础语法
- numpy
- scipy.sparse
- C++与STL
- 图神经网络
- 知识图谱
- 其他
深度学习
常用的优化方法和常见概念
验证集和测试集的区别
深度学习中Dropout原理解析
因为神经网络中的梯度下降使用的是链式法则求导,所以被抛弃的神经网络节点(不是权重!!)不仅数值上是0,节点后面的权重w1在反向传播时梯度为0,节点前面的权重w2反向传播的梯度也是0(因为链式求导),根据梯度下降公式,w1和w2在反向传播时都不变,而被抛弃的节点前面的节点从他这里得到的梯度也是0,这个节点看起来非常像隐身。
神经网络Dropout层中为什么dropout后还需要进行rescale?
数据经过Dropout之后的期望值变为p*x,因为对于节点x来讲:
| x取值 | x(原始的x值) | 0(drop掉这个节点) |
|---|---|---|
| 概率 | p | 1-p |
Vanilla Dropout:在训练时,经过dropout层之后,节点的期望变成p*x,所以我们需要在预测时也保持同样的期望,所以我们在预测时也让节点乘p,即x’=p*x’(x’为训练时输入的数据),这样就保证了输入数据在训练和预测时期的期望值相等,都是p*x。
Inverted Dropout:在训练时,因为经过dropout层节点的期望变成p*x,所以我们在训练时就让x=x/p,这样就保证了训练时节点的期望是(p*x)/p = x。这样一来,我们在预测时不需要对Dropout层的节点做任何处理。
简单来说,两种方法都是让训练和预测两个阶段的Dropout层的节点期望值相同。
L1、L2正则化对防止模型过拟合的作用
人工神经网络怎么使用梯度下降进行反向传播
深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
介绍标准化(normalization)的超级好文:深度学习中的Normalization总结(BN/LN/WN/IN/GN)
Batch_Normalization原理及作用
BN用来缓解 Internal Covariate Shift(内在协同偏移)问题,具体在神经网络中可以做到降低输入batch_size个样本间存在的差异性的作用,BN产生的影响如下:
1.缓解DNN训练中的梯度消失问题
2.加快模型收敛速度
如何解决sigmoid函数饱和区问题
数据在sigmoid函数饱和区域的导数非常接近0,所以在反向传播时容易导致梯度消失。我们一般引入批标准化BN解决sigmoid函数饱和区域问题。BN要做的是在输入激活函数之前对数据进行批标准化,在将变换后的数据输入激活函数中。值得注意的是,为了不让sigmoid只在线性区域上发挥作用(失去非线性表达的能力),我们一般在批标准化中,引入 γ \gamma γ和 β \beta β,对规范化后的神经元输出做一次线性映射,得到 y = γ ∗ x + β y=\gamma*x+\beta y=γ∗x+β,x是对batch_size个数据进行规范化后的数据,这batch_size个样本对应的规范化数据的均值是0,方差是1。这样就使得神经网络既保持了非线性变换,保证了其强大的学习能力,也使求导时梯度比较大,加快了训练速度,缓解了梯度消失的问题。
梯度消失和梯度爆炸问题详解
机器学习、NLP面试中常考到的知识点和代码实现
深度学习: greedy layer-wise pre-training (逐层贪婪预训练)
神经网络为什么要使用激活函数?
为了让神经网络从线性方程变成非线性方程,从而使神经网络具有更强的拟合能力。
深度学习案例(二):非线性回归案例,使用神经网络拟合非线性方程
交叉验证(Cross Validation)
1、简单交叉验证:直接将样本随机分为训练集和验证集,没有用到交叉的思想。
2、2-折交叉验证:将数据集平均分为两份,一份是验证集,一份是训练集,这种方法一共需要对模型进行两次训练,在第二次训练时交换训练集和验证集。
3、K折交叉验证:最常用,将数据集平均分成K份,用K-1份当作训练集,用1份当作验证集,然后这K份小数据集分别做一次验证集,其余的K-1份作为训练集,那么一共将训练出K个模型,用这K个模型在他们的验证集上的准确率的均值作为最终性能指标。使用时综合考虑K个模型的预测结果,由此可以实现集成学习。(集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来)
4、留一交叉验证:在数据缺乏的情况下使用,每个样本分别做一次验证集,其余N-1个样本作为训练集,这样最终将得到N个模型,同样,使用N个模型的平均准确率作为模型的性能指标。
理解滑动平均(exponential moving average)

在训练过程中,对神经网络边的权重 weights 使用滑动平均,得到对应的影子变量 shadow_weights。需要注意的是,训练过程仍然使用原来不带滑动平均的权重 weights(一般用梯度下降法对weights进行调整),不然无法得到 weights 下一步更新的值,又怎么求下一步 weights 的影子变量 shadow_weights。之后在测试过程中使用 shadow_weights 来代替 weights 作为神经网络边的权重,这样在测试数据上效果更好。 即训练过程中weights的更新照常进行,使用每一步计算出的weights更新shadow_weights,在测试时使用shadow_weights代替最终的weights。 β \beta β一般取一个很接近1的数字,比如说0.99或者0.999。
Label Smoothing Regularization_LSR原理是什么?
LSR的公式如下:

卷积神经网络为什么具有平移不变性?
神经网络结构
DenseNet网络详解
tensorflow1.x框架
tensorflow自定义激活函数
最近看了几篇关于tensorflow静态图中graph和session的文章,但是最近比较忙,也来不及整理,就先放这吧:
Tensorflow中的Graph和Session概念
Tensorflow同时加载使用多个模型
tensorflow中创建多个计算图(Graph)
tensorflow学习(2):计算图,tf.get_default_graph(),tf.Graph()
graph:
Tensorflow里的Graph类似于数据流图,节点为计算单位(通常为tf.Operation),边通常为用于计算的数据(如tf.Variable)。在建立计算图的时候,通常包括建立tf.Operation (node)和tf.Tensor (edge)对象,然后加入到tf.Graph当中。未声明特定的Graph时则加入到默认图(default graph)中。所以我们一般将神经网络的操作和节点指定在我们创建的某个graph或默认graph中。
session:
由于tensorflow底层是使用C++/写的,所以Tensorflow使用tf.Session类来代表客户端程序(python脚本)和底层C++运行状态的桥梁。
Session是Graph和执行者之间的媒介,Session.run()实际上将graph、fetches、feed_dict序列化到字节数组中,并调用tf_session.TF_Run。通常每一个session都有自己的物理资源(包括GPU,网络连接等等)
我们一般使用with tf.Session(target,graph,config,allow_soft_placement) as sess:创建新session,参数说明如下:
- target:若为空,则Session只能使用本机的device,若为grpc://URL,则可以使用改TF Server控制下的所有devices。
- graph:默认用来运行default graph中的Operations。除非特别声明特定Graph。
- config:一些基础设置
- allow_soft_placement:True,则会忽略tf.device的特定device的声明,例如将CPU-only的运算给GPU
所以我们可以在一个进程中同时运行多个模型,这里用两个模型运行在一个进程中举例,我们现在有一个分类任务,有一个目标检测任务,我们加载分类任务的神经网络时,将网络中所有操作指定为graph1上的操作,同理,将目标检测网络中所有操作指定为graph2上的操作。然后创建一个session1,参数graph=“graph1”,用于运行graph1中定义的操作;创建一个session2,参数graph=“graph2”,用于运行graph2中定义的操作。这是属于静态图的优势,对于动态图来讲,所有操作维护在一个全局的graph和session中,所有操作和计算都在这个全局session下进行,所以不能一个进程加载两个模型,不然会造成网络计算操作时的混乱。
tf设置GPU使用情况
tensorflow在训练时默认占用所有GPU的显存。 不管机器中有一块或多块GPU,tensorflow会默认吃掉所有能用的显存,可以通过以下方式解决该问题:
1.显式地指定需要分配的显存比例,比如说12G的显卡,你设置per_process_gpu_memory_fraction为0.25,则会分配3G的显存,但它只能均匀作用于所有GPU,无法对不同GPU设置不同的上限,比如你的机器有两块12G的显卡,比例设置为0.25时,每块卡都拿出来25%的显存(0.25*12=3),最终得到6G(3*2=6)显存。在tf中可以这样写:
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.25)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
2.指定使用的GPU编号:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" #表示只使用第一块GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 2" #表示使用第一, 三块GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "-1" #禁止使用所有GPU,使用CPU计算
3.设置GPU按需分配
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config,...)
当allow_growth设置为True时,分配器不会让tf程序一开始就占用所有的GPU内存,而是根据需求增长。也就是说allow_growth 选项,它试图根据运行时的需要来分配 GPU 内存。
深度学习模型函数执行完毕后显存不释放问题解决方案
用多进程解决单进程中预测后GPU资源不释放的问题(只有将进程结束才能释放),但是这样会出现另外一个问题,那就是每个进程都要从新分配GPU空间,重新加载模型,这样就很麻烦,每次执行预测都要重新加载模型。究其原因,这是因为tf的session不是进程安全的,所以不能在多个进程中使用一个session,这就要求我们为每个进程创建一个session,并在每个session中初始化权重。如果想只加载一次session并且使用这个session进行多次预测,建议使用多线程。
总结:
1、使用多线程的优点是可以只需要在主进程中加载一次模型参数(具体是在主进程中创建一个session并加载训练好的模型参数),这样可以用这个session进行多次预测。缺点是如果不结束主进程,那么给主进程分配的GPU资源将会一直被占用,即使不在预测状态也会被占用,所以这是一个十分耗费空间的方法。
2、使用多进程的优点是在子进程中每执行一次预测都会释放掉对应的资源,即仅在预测时占用资源,预测后就会随着子进程结束而自动释放。缺点是每次子进程执行预测时都要重新加载一个session然后初始化权重,从硬盘上读出模型权重并将网络按照训练好的权重初始化需要很长时间,所以这是一个十分耗费时间的方法。
这里再解释一下,为什么给进程分配好的资源只能由结束进程才能释放资源:
目前GPUDevice中的Allocator属于ProcessState,它本质上是一个跟随着进程的全局单例。在进程中使用GPU的第一个会话初始化它,并分配显存资源,在进程关闭时释放进程占用的资源,不然这个进程会一直占用这些资源。为了不让预测后程序中的tf一直占用显存,我们选择在子进程中进行预测,因为子进程中使用的GPU资源会随着子进程结束而释放。如果在主进程中直接使用predict函数,即使predict函数执行结束也会一直占用着显存,直到主进程结束才能释放它占有的GPU资源。
计算机视觉
图像卷积和池化操作后的特征图大小计算方法
空洞卷积(dilated convolution)理解
空洞卷积的出现就是为了在不过分降低分辨率的情况下,扩大感受野。使用池化层可以扩大理论感受野,但是大大降低了分辨率,损失了很多细节,使用空洞卷积就可以在基本不降低分辨率的情况下(stride=1)扩大感受野。
上采样之反卷积和转置卷积的理解
残差网络学习心得
目标检测之Loss:FasterRCNN中的SmoothL1Loss
使用神经网络的高性能图像放大算法——waifu2x方法
waifu2x的Github地址
如何用自己的图像数据集训练yolov3模型
目标检测中的mAP是什么
FPN(feature pyramid networks)算法讲解
作者提出的多尺度的object detection算法:FPN(feature pyramid networks)。原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
自然语言处理
清晰理顺从词袋到Word2Vec的文本表示,内涵维基百科的Word2Vec代码
LSTM结构详解
词嵌入模型浅析——Word2vec与glove
理解GloVe模型(Global vectors for word representation)
Pytorch
Pytorch详解NLL_Loss和CrossEntropyLoss
Pytorch的NNL_Loss函数中不需要用one-hot矩阵作为分类标签矩阵,而是直接将物体标签index作为labels。比如[[1,0,0],[0,0,1]]是标准的one-hot矩阵,那么在pytorch中,labels应该是[0,2],表示第0行第0列是1,第1行第2列是1,其余位置都是0。所以CrossEntropyLoss= Softmax + Log + NLL_Loss。
PyTorch(1) torch.nn与torch.nn.functional之间的区别和联系
如果操作内有变量(权重weight),那么用torch.nn定义(因为它是一个类),反之,则用torch.nn.functional定义(因为它是一个函数)。
原因是如果使用后者进行卷积或者全连接等需要权重的操作,则要自己手动定义变量,如weights,bias等,非常不方便,而前者是一个类,已经在类中定义好了权重变量,不需要我们手动定义变量。
pytorch损失函数binary_cross_entropy和binary_cross_entropy_with_logits的区别
binary_cross_entropy就是普通的交叉熵,和NLL_Loss不同,这个函数要求神经网络输出的结果和标签矩阵拥有相同的shape,他计算的是每个位置上的元素损失值总和。
区别:binary_cross_entropy_with_logits = sigmoid激活函数 + binary_cross_entropy。
Pytorch中的自动求导函数backward()所需参数含义
数据挖掘与机器学习
数据挖掘领域十大经典算法之—AdaBoost算法(超详细附代码)
Adaboost算法是一种提升方法,将多个弱分类器,组合成强分类器。
准确率、精准率和召回率的理解
准确率是衡量模型在多类上分类的综合性能,精确率是衡量模型对于一类物体的查准率,召回率是衡量模型对样本空间中这一类物体的查全率。
浅析机器学习:线性回归 & 逻辑回归
逻辑回归是加了联系函数(联系函数是非线性的Sigmoid函数)的线性回归模型,线性回归和逻辑回归都是广义线性回归模型。逻辑回归用于分类,线性回归用于拟合。
一般线性模型、混合线性模型、广义线性模型
从KKT条件下的拉格朗日乘法到拉格朗日对偶问题
上文介绍了KKT条件的由来,将广义拉格朗日乘法推广到拉格朗日对偶问题。
Python3《机器学习实战》学习笔记(一):k-近邻算法(史诗级干货长文)
Python3《机器学习实战》学习笔记(二):决策树基础篇之让我们从相亲说起
Python3《机器学习实战》学习笔记(三):决策树实战篇之为自己配个隐形眼镜
Python3《机器学习实战》学习笔记(四):朴素贝叶斯基础篇之言论过滤器
Python3《机器学习实战》学习笔记(五):朴素贝叶斯实战篇之新浪新闻分类
Python3《机器学习实战》学习笔记(六):Logistic回归基础篇之梯度上升算法
Python3《机器学习实战》学习笔记(七):Logistic回归实战篇之预测病马死亡率
【机器学习】【K-Means】算法详解+样本集实例讲解
【机器学习】【PCA-1】PCA基本原理和原理推导 + PCA计算步骤讲解 + PCA实例展示数学求解过程(还没看)
主成分分析(PCA)原理总结
PCA原理:为什么用协方差矩阵
SVM:任意点到超平面的距离公式
SVM学习(五):松弛变量与惩罚因子
SVM的函数距离和几何距离
自动编码器(Auto Encoder)
自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如y(x)=x ,然后使用降维后的隐藏层作为输入数据的特征。
对小数据集使用Bootstrap方法(自助法)进行抽样
自助法是一种从给定数据集中有放回的均匀抽样,也就是说,每当选中一个样本,他等可能地被再次选中,并被再次添加到训练集中。
作用:在数据集小的情况下,利用Bootstrap方法进行抽样,得到多个数据集,分别训练多个模型再进行组合,是为集成学习准备数据集的一种方法。
线性回归——lasso回归和岭回归(ridge regression)
文章作者从拉格朗日乘子法的角度分析了为什么lasso回归比岭回归更能使参数等于0。lasso回归的目的是让部分参数等于0,岭回归的目的是让部分参数趋于0,lasso回归得出的参数权重更加稀疏,更有利于特征筛选。
t-SNE算法详解,一种经常用于可视化数据的降维算法
计算机网络
HTTP协议与HTTPS协议讲解
使用广播信道的数据链路层以及以太网详解!!!
村通网之俺也来学HTTPS
传统图像处理
python-opencv函数总结之(一)threshold、adaptiveThreshold、Otsu 二值化
灰度图像的自动阈值分割(Otsu 法)
提高动画图像分辨率算法Anime4K
上采样之双线性插值法
上采样之双三次插值(Bicubic Interpolation)
图像的膨胀和腐蚀
图像的膨胀与腐蚀其实也是一种类似的卷积操作,其卷积操作非常简单,对于图像的每个像素,取其一定的邻域,计算包含在这个区域中,像素的最大值/最小值作为新图像对应像素位置的像素值。其中,取最大值就是膨胀,取最小值就是腐蚀。
Sobel算子的理解
Soble算子经常被用来求图像的一阶梯度的近似(所以说这个值不是一阶导数,只是一阶导数的近似值),常见的应用和物理意义是边缘检测。
Canny边缘检测步骤
先用高斯滤波及逆行降噪,然后使用Sobel算子求梯度幅值以及梯度方向,接下来使用非极大值抑制,排除非边缘像素,仅仅保留一些比较细的线条,叫做候选边缘,最后使用滞后阈值,根据幅值和两个阈值(高阈值和低阈值)进行筛选。
OpenCV霍夫梯度找圆算法
OpenCV 中图像坐标系统与Python中NumPy Arrays之间的关系
网页
Sql Server数据库如何通过命令行使用——sqlcmd 命令使用
js实现定时调用的函数setInterval()
AJAX的出现与跨域处理
为什么form表单提交没有跨域问题,但ajax提交有跨域问题?
笔记:ES6新特性-函数的简写(箭头函数)
操作系统
操作系统 外部内部碎片的区别(经典)
堆与栈的区别
如何理解虚拟地址空间
32位和64位的区别
64位是指cpu在一个时间单位内能处理的数据的最大位数,也就是说cpu一次可以处理64bit(8bytes)的数据,相对应的,需要64位指令集、64位的操作系统以及64位的软件配合。32位的cpu一次可以处理32bit的数据。
64位的CPU,相比较32位的CPU来说,64位CPU最为明显的变化就是增加了8个64位的通用寄存器,内存寻址能力提高到64位,以及寄存器和指令指针升级到64位等。所以假定没有内存管理单元(MMU)的支持下,对于64位操作系统而言,你给到CPU的地址是64位的,所以最大的寻址能力就是264bit,理论上这个cpu可以使用264bit=234GB(大概171亿GB)大小的内存条,因为寻址空间有这么大,实际上128G的内存已经很大了,用不了那么大。同理,32位的cpu理论上可以使用232bit=4GB的内存条,因为寻址空间就这么大。
即64位操作系统中一个指针(即变量的地址)的大小为64bit=8bytes,32位的系统为32bit=4bytes,但是有些64位操作系统中的应用程序的编译器为了兼容32位操作系统,会将指针大小设置为4bytes。
内存寻址(一) —— 基本概念与机制
【转】操作系统–虚拟内存、逻辑地址、线性地址、物理地址
逻辑地址 ----(段表)—> 线性(逻辑)地址 — (页表)—> 物理地址
Linux
关于在vim中的查找和替换
tar压缩的使用
ls命令的使用
linux命令中的 < 和 |、>符号作用就解释
注意:>与>>都用来重定向输出,不同的是>将覆盖原有内容,而>>则会追加内容。
linux中的分号&&和&,|和||说明与用法
Python语法
基础语法
Python Lambda函数的用法
装饰器详解
python装饰器就是用于拓展原来函数功能的一种函数,这个函数的特殊之处在于它的返回值也是一个函数,使用python装饰器的好处就是在不用更改原函数的代码前提下给函数增加新的功能。
StringIO和BytesIO模块的使用
很多时候,数据读写操作的对象不一定是硬盘中的文件,也可以在内存中读写。StringIO顾名思义就是在内存中读写字符串,如果要操作二进制数据在内存中读写,就需要使用BytesIO。
Tips:当使用f.write()方法将字符串写入StringIO对象时,对象内部维护的指针会指向字符串最后一个字符再往后一个位置在内存中的位置(可以用tell()函数查看当前指针所在位置),而readline()函数就是从指针开始处往后移动,直到移动到末尾为止,这就导致我们使用readline()函数无法读取出字符串。这时我们需要使用f.seek()函数将指针移回开始处,这个函数有两个参数,第二个参数是指针开始位置,默认为0,表示从文件开头,1表示相对于当前的位置,2表示文件末尾,第一个参数是指针偏移量,表示需要从指针开始位置向前或向后移动指针的字节数,正为向后,负为向前。
>>> from io import StringIO
>>> f = StringIO()
>>> f.write("hello world")
11
>>> f.getvalue()
'hello world'
>>> f.readline() # 不能将内容通过readline()函数读出来,因为此时指针在末尾
''
>>> f.tell() # 使用tell()函数查看目前指针所在位置,发现在最末尾
11
>>> f.seek(0,0)
0
>>> f.tell()
0
>>> f.readline()
'hello world'
Python通过对象名调用方法(对象名后面括号和参数)
通过在类中实现__call__()方法,使得类实例化出来的对象是可调用的(callable)。
numpy
【Python 模块学习】NumPy中的维度(dimension)、轴(axis)、秩(rank)的含义
np.newaxis函数的作用
np.newaxis函数的作用就是在这某位置增加一个一维。
Python学习之numpy常用函数diagonal()函数
返回由矩阵对角线元素组成的一维向量。
numpy.triu()||numpy.tril()结构及用法||参数详解
该函数用于获取矩阵的上/下三角部分。
Numpy:numpy.ceil()函数和numpy.floor()函数
Python NumPy.all()与any()函数理解
scipy.sparse
scipy.sparse的csr_matrix和csc_matrix函数详解
Scipy.sparse中coo_matrix、csc_matrix、csr_matrix、lil_matrix区别与特点
scipy: eliminate_zeros()的用途
把矩阵中所有是0的值去掉。
scipy.sparse维护的数据结构:coo_matrix、dok_matrix、lil_matrix、dia_matrix、csr_matrix、csc_matrix、bsr_matrix
C++与STL
c++ 将一个char 转化为string
使用string的push_back()函数将单个字符添加到string后。
图神经网络
为什么傅里叶变换可以把时域信号变为频域信号?
如何理解 Graph Convolutional Network(GCN)?
图卷积网络 GCN Graph Convolutional Network(谱域GCN)的理解和详细推导-持续更新
2020年,我终于决定入门GCN(GCN基础知识+图节点分类的小例子)
networkx 复杂网络分析笔记
pytorch版本的GCN代码解析
Weisfeiler-Leman test与WL subtree kernel算法详解
知识图谱
用Python+neo4j构建知识图谱-初学
其他
CSDN 里面的Markdown 添加数学公式
神经网络可视化工具:PlotNeuralNet
神经网络可视化工具:Netscope
如何理解关系型数据库的常见设计范式?
python3新特性函数注释Function Annotations用法分析
Python——plt.scatter各参数详解
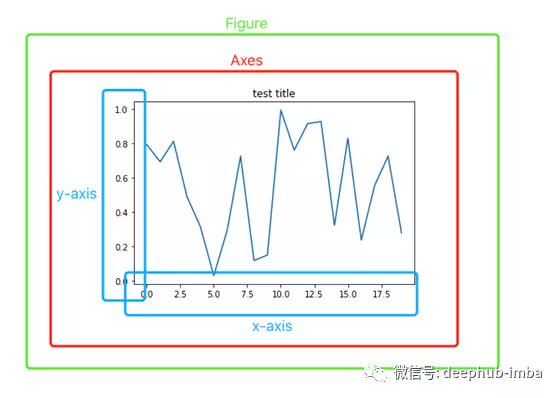
Matplotlib中的“plt”、“fig”、“ax”到底是什么?
- plt是matplotlib的一个常见别名,pyplot被大多数人使用,当我们使用plt(比如plt.scatter())绘制一些东西时,我们隐式地创建了一个图形实例(Figure)和图形对象内部的坐标轴(AxesSubplot)。当我们只想画一个图的时候,这是非常方便的。
- Figure就是一张空白纸,可以画任何想画的东西。
- 除了直接使用plt绘制图形,我们可以显式地调用plt .subplot()或plt.subplots()等函数来获得Figure对象和Axes对象,以便对它们执行更多的操作。当我们想在一个图形上画多个子图时,通常需要使用这种方法。