Image Synthesis in Multi-Contrast MRI With Conditional Generative Adversarial Networks—论文解读
Image Synthesis in Multi-Contrast MRI With Conditional Generative Adversarial Networks
-
- 文章概述及亮点
- 摘要
- 介绍
- 方法
- 数据集
- 数据归一化与图像配准
- 网络训练
- 用于比较的模型
- 实验
-
- 基于GAN的模型比较
- 和SOAT合成方法比较
- 光谱密度分析
- 泛化性
- 抗噪性
- 代码
文章概述及亮点
作者的应用场景单模态的不同对比图像间的转换,是比如给定T1 MRI,合成T2 MRI。作者考虑了两种情况,情况一是源域图像和目标域图像进行了较好的配准,情况二是未进行配准。针对情况一,作者基于pix2pixGAN模型+perceptual Loss提出了pGAN模型,针对情况二,作者基于cycleGAN模型进行转换。
【1】multi-contrast如何理解
【2】registered multi-contrast images和unregistered images如何理解,理解成配准的图像和未配准的图像?逐像素损失和感知损失是如何作用到registered multi-contrast images上的?循环一致性损失又是如何作用到unregistered images上的?
【3】利用相邻截面的信息进一步提升合成质量,将相邻的k张图像都作为输入,那岂不是增加训练集?采用相邻的k张图像作为输入,那么合成的目标图像也是k张还是只用中间那张?
【4】对于pGAN来说,如何设置三种损失的权重?
【5】对于已配准的图像合成而言,cGAN和pGAN哪种结果更好?
摘要
获取具有多个不同对比度的同一解剖结构的图像(比如说,T1、T2、T1-weight、FAILR?)可增加MR检查中可用诊断信息的多样性。然而,扫描时间限制可能会禁止获取某些对比度,并且可能会被噪声和伪影破坏。在这种情况下,合成未知或损坏对比图像可以提高诊断的实用性。对于多对比合成,目前的方法是通过非线性重构或确定性神经网络来学习源图像和目标图像之间的非线性强度变换。这些方法反过来又会使合成图像中的结构细节丢失。本文提出了一种基于条件生成对抗网络的多对比MRI合成新方法。该方法通过对抗性损失保持中高频的细节,并通过对已注册多对比度图像的逐像素和感知损失以及对未注册图像的循环一致性损失来提高合成性能。利用相邻截面的信息进一步提高合成质量。在健康受试者和患者的T1和T2加权图像上的演示清楚地表明,与先前的最新方法相比,所提出的方法具有优越的性能。我们的综合方法有助于提高多对比MRI检查的质量和多功能性,而无需预先检查或重复检查。
介绍
磁共振成像(MRI)由于其能在软组织中捕捉到的对比度的多样性,在临床应用中得到了广泛的应用。定制的MRI脉冲序列能够在成像相同解剖结构时产生不同的对比度。例如,T1加权的大脑图像清楚地描绘了灰质和白质组织,而T2加权的图像描绘了来自皮质组织的液体。反过来,同一受试者获得的多对比度图像增加了临床和研究研究中可用的诊断信息。然而,考虑到长期检查和不合作患者的费用,尤其是在儿童和老年人群中,可能无法收集到完整的对比数据。在这种情况下,最好是获得扫描时间相对较短的对比度。即使如此,获得的对比度的一个子集也可能被过多的噪声或伪影破坏,这些噪声或伪影禁止随后的诊断使用。此外,队列研究通常在成像方案和获得的具体对比方面显示出显著的异质性。因此,从其他成功获得的对比度图像合成缺失或损坏的对比度图像的能力,通过增加诊断相关图像的可用性,以及改进诸如配准和分割等分析任务,对增强多对比度MRI具有潜在的价值。
近年来,医学图像的跨域合成在医学成像领域得到了广泛的应用。给定一个被摄体在x(源域)中的图像x,目的是准确估计同一被摄体在y(目标域)中的各自图像。两种主要的跨模态合成方法是基于配准的方法和基于强度变换的方法。然而,基于配准的方法强烈依赖于源域图像与待转换图像之间的几何对应关系。基于强度变换的方法虽然不依赖于几何对应关系,但它也有自己的局限性。
最近,一个端到端的核磁共振图像合成框架被提出,即基于深度神经网络的Multimodal(Multimodal MR synthesis via modality-invariant latent representation)。但它使用的平均绝对误差损失函数在捕捉更高空间频率的误差方面表现不佳。
本文提出了一种基于生成性对抗网络(GAN)结构的多对比MRI图像合成新方法。对抗性损失函数最近已被证明可用于各种医学成像应用,并能可靠地捕获高频纹理信息。在跨模态图像合成领域,重要的应用包括CT到PET合成、MR到CT合成、CT到MR合成等等。在这一成功的启发下,我们引入条件GAN模型来从单个模态上合成不同的对比图像,并在正常人和胶质瘤患者的多对比脑部MRI上进行验证。为了提高精度,该方法还利用了三维影像中相邻横截面的相关信息。当多对比度图像直接在空间上进行了配准(pGAN)和当它们未进行配准(cGAN)时,我们提供了两种实现方式。对于第一种情况(已配准),我们训练在合成图像和真实图像(如下图所示)之间具有逐像素损失和感知损失的pGAN。对于第二种情况(未配准),我们在用循环一致性替换逐像素损失后训练cGAN,循环损失增强了从合成的目标图像中重建原始图像的能力(如下图所示)。对正常人和胶质瘤患者的多对比度MRI图像(包括T1和T2加权)进行了广泛的评估。与目前最先进的方法相比,该方法在多对比度磁共振成像合成中获得了定性和定量的精度增强。
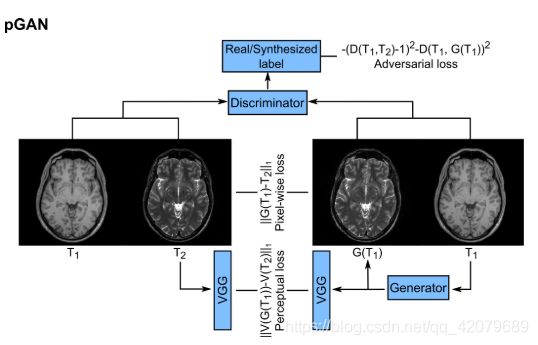
用于已配准的图像合成的pGAN模型示意图,它基于一个条件生成对抗网络,由生成器G、预训练好的VGG16网络和一个判别器网络组成。给定一个源域对比图像的输入(比如T1加权图像),G学习生成相同部位的相应目标域图像(比如T2加权图像)。同时,D学习去判断合成对(T1+合成T2)和真实对(T1+真实T2)的真假。所有的子网络被同时训练,其中G的目标在于最小化一个逐像素损失、感知损失和对抗损失,D的目标在于最大化对抗损失。
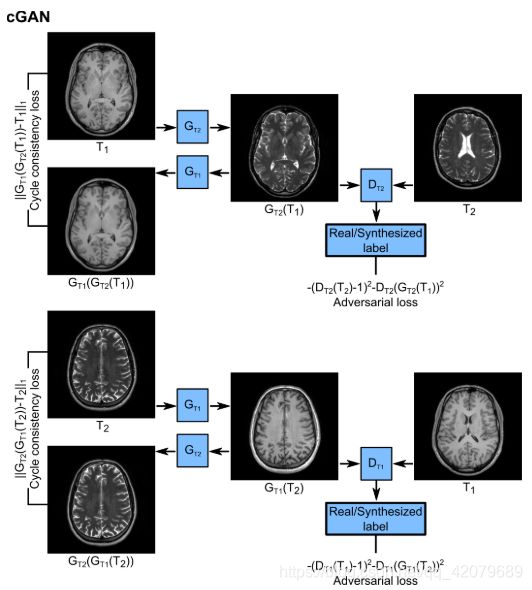
用于未配准的图像合成的cGAN模型示意图,基于cycleGAN的框架。
方法
对于基于pix2pix的pGAN,由于观察到G会忽略潜层向量,作者直接移除了潜层向量(即噪声)输入。并且引入了perceptual loss。cGAN则完全按照cycleGAN的结构。
数据集
对已配准的图像,我们同时训练了pGAN模型和cGAN模型;而对于未配准的图像,我们只训练了cGAN模型。
使用了三个公开数据集,对每个数据集都分别单独训练一个模型:
【1】MIDAS dataset:仅含有健康受试者的T1加权和T2加权图像,一共选取了66名受试者,训练:验证:测试的划分比例大概是7:1:2。对于每一名受试者,手工选取不存在显著伪影的大约78张相邻的包含脑组织的轴向slices作为数据。
【2】IXI dataset:仅含有健康受试者的T1加权和T2加权图像,一共选取了40名受试者,当用T1图像配准到T2图像时,手工选取大约90张轴向slices作为数据,当用T2图像配准到T1图像时,手工选取大约110张轴向slices作为数据。
【3】BRATS dataset:包含了患者的可见病变区域的T1加权和T2加权图像,对于每一名受试者,大约100张轴向slices被选取作为数据。
最后,为了平衡每个数据集的数据,我们改变了每个数据集中受试者的数量。最终,每个数据集大约有4000-5000张图像。
为了消除受试者数量带来的差异(控制变量),在模型的对比中,我们从每个数据集中选择了40个受试者。并且使用了4折交叉验证。
数据归一化与图像配准
图像数据的强度归一化到[0,1]。
使用FSL进行图像配准。
网络训练
两种网络的训练步骤不同:
对于pGAN模型而言,注意到相邻的MR切片预计有很强的相关性。因此作者推断在源域相邻的切片可以提供额外的信息来提升合成质量。因此作者分别使用了 k = 3 , 5 , 7 k=3,5,7 k=3,5,7三种数量的图像作为pGAN的输入,其输出?
超参数的设置与调整:对于深度学习来说,调参是需要花很多心思的。一般来说,超参数往往有两种方式设置,一种是一折交叉验证(即将数据划分成训练、验证和测试,然后在验证集上调整超参数,在测试集上报告结果),另一种是按照已发表工作提供的超参数设置。损失函数的权重根据验证集上的结果在{10,100,150}三者中选择,最终权重为GAN的损失权重为1,L1 Loss和Perceptual Loss的权重均为100。使用了Instance Normalization,batch-size设置为1。训练100个epoch,前50个epoch的学习率为0.0002,后50个epoch逐渐线性下降到0。所有权重的初始化都使用均值为0和0.02标准差的正态分布初始化。
用于比较的模型
选择了两种SOAT的MRI合成模型。用于比较的模型在相同的训练集和测试集上进行比较。
实验
基于GAN的模型比较
在这里,我们首先质疑多对比度图像之间的配准方向是否会影响合成的质量。特别是,我们从T1和T2加权图像生成了多个配准数据集。在第一组中,T2加权图像被配准到T1加权图像上(产生T2#)。在第二组中,T1加权图像被配准到T2加权图像上(产生T1#)。除了配准方向外,我们还考虑了两个可能的合成方向(T1的T2;T2的T1)。
对于每种情况,pGAN和cGAN都基于两种变体进行训练,一种接收单个横截面,另一种接收多个(3、5和7)连续横截面作为输入。这一共产生了32个pGAN和12个cGAN模型。注意,单横截面cGAN包含两个对比度的生成器,并训练一个可以在两个方向上合成的模型。然而,对于多截面cGAN,需要训练一个单独的模型来确定合成方向。对于BRAT,不需要注册,这只导致两个不同的情况需要考虑:a)T1→T2和d)T2→T1。考虑了pGAN(k=3)和cGAN(k=1)的单一变体。
和SOAT合成方法比较
和两个SOAT方法——Replica模型和Multimodal模型进行了比较,在相同的训练集和测试集上运行,且使用PSNR和SSIM作为评估指标。
光谱密度分析
虽然PSNR和SSIM是评估整体质量的常用方法,但它们主要捕获由较低空间频率支配的特征。为了在更广泛的频率范围内检验合成质量,我们使用了光谱密度相似性(SDS)度量。SDS的基本原理与[66]中所示的误差谱图相似,其中误差分布是跨空间频率分析的。为了计算SDS,合成和参考图像被转换成k空间,并分成四个单独的频带:低(0 - 25%),中间(25 - 50%),高中间(50 - 75%),和高(75 - 100%的最大空间频率在k空间中)。在每个波段内,SDS作为合成图像和参考图像的震级k空间样本向量之间的Pearson相关。为了避免背景噪声的影响,在计算质量度量之前,我们将背景区域屏蔽为零。
泛化性
为了验证所提方法的通用性,我们在IXI数据集上训练了pGAN、cGAN、Replica和mulmodal,并在MIDAS数据集上测试了训练好的模型。
抗噪性
为了检验图像噪声综合的可靠性,我们基于含噪图像(人工加入噪声)训练了pGAN模型和Multimodal模型。
代码
pGAN和cGAN的代码是基于Pytorch编写的,可单击获取。