1. 引入所有需要的包
# -*- coding:utf-8 -*-
# 忽略警告
import warnings warnings.filterwarnings('ignore') # 引入数据处理包 import numpy as np import pandas as pd # 引入算法包 from sklearn.tree import DecisionTreeClassifier from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import BaggingRegressor from sklearn.svm import SVC, LinearSVC from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier from sklearn.ensemble import GradientBoostingRegressor from sklearn.linear_model import Perceptron from sklearn.linear_model import SGDClassifier from sklearn.linear_model import Perceptron from xgboost import XGBClassifier # 引入帮助分析数据的包 from sklearn.preprocessing import Imputer,Normalizer,scale from sklearn.cross_validation import train_test_split,StratifiedKFold,cross_val_score from sklearn.feature_selection import RFECV import sklearn.preprocessing as preprocessing from sklearn.learning_curve import learning_curve from sklearn.metrics import accuracy_score # 可视化 import matplotlib as mpl import matplotlib.pyplot as plt import matplotlib.pylab as pylab import seaborn as sns %matplotlib inline # 配置可视化 mpl.style.use('ggplot') sns.set_style('white') pylab.rcParams['figure.figsize'] = 8,6
2. 读入数据源
train = pd.read_csv('base_data/train.csv')
test = pd.read_csv('base_data/test.csv') full = train.append(test, ignore_index=True) # 保证train和test的数据格式一样 titanic = full[:891] titanic_pre = full[891:] del train, test print ('DataSets: ', 'full: ', full.shape, 'titanic: ', titanic.shape)
3. 分析数据
# 查看有哪些数据
titanic.head()
# 数据的整体情况
titanic.describe() # 只能查看数字类型的整体情况 >>> Age Fare Parch PassengerId Pclass SibSp Survived count 714.000000 891.000000 891.000000 891.000000 891.000000 891.000000 891.000000 mean 29.699118 32.204208 0.381594 446.000000 2.308642 0.523008 0.383838 std 14.526497 49.693429 0.806057 257.353842 0.836071 1.102743 0.486592 min 0.420000 0.000000 0.000000 1.000000 1.000000 0.000000 0.000000 25% 20.125000 7.910400 0.000000 223.500000 2.000000 0.000000 0.000000 50% 28.000000 14.454200 0.000000 446.000000 3.000000 0.000000 0.000000 75% 38.000000 31.000000 0.000000 668.500000 3.000000 1.000000 1.000000 max 80.000000 512.329200 6.000000 891.000000 3.000000 8.000000 1.000000 titanic.describe(include=['O']) # 查看字符串类型(非数字)的整体情况 >>> Cabin Embarked Name Sex Ticket count 204 889 891 891 891 unique 147 3 891 2 681 top C23 C25 C27 S Graham, male CA. 2343 freq 4 644 1 577 7
# 查看整体数据的情况(包含训练数据和预测数据,看哪些字段有缺失值,需要填充)
# 查看缺失值情况
titanic.info()
titanic.isnull().sum().sort_values(ascending=False) # 发现以下字段有缺失值 >>> Cabin 687 Age 177 Embarked 2 full.info() full.isnull().sum().sort_values(ascending=False) # 发现以下字段有缺失值 Cabin 1014 Age 263 Embarked 2 Fare 1
总结:所有的数据中一共包括12个变量,其中7个是数值变量,5个是属性变量
PassengerId(忽略):这是乘客的编号,显然对乘客是否幸存完全没有任何作用,仅做区分作用,所以我们就不考虑它了。
Survived(目标值):乘客最后的生存情况,这个是我们预测的目标变量。不过从平均数可以看出,最后存活的概率大概是38%。
Pclass(考虑):社会经济地位,这个很明显和生存结果相关啊,有钱人住着更加高级船舱可能会享受着更加高级的服务,因此遇险时往往会受到优待。所以这显然是我们要考虑的一个变量。分为123等级,1等级获救率更高。
Name(考虑):这个变量看起来好像是没什么用啊,因为毕竟从名字你也不能看出能不能获救,但是仔细观察数据我们可以看到,所有人的名字里都包括了Mr,Mrs和Miss,从中是不是隐约可以看出来一些性别和年龄的信息呢,所以干脆把名字这个变量变成一个状态变量,包含Mr,Mrs和Miss这三种状态,但是放到机器学习里面我们得给它一个编码啊,最直接的想法就是0,1,2,但是这样真的合理吗?因为从距离的角度来说,这样Mr和Mrs的距离要小于Mr和Miss的距离,显然不合适,因为我们把它看成平权的三个状态。
所以,敲黑板,知识点来了,对于这种状态变量我们通常采取的措施是one-hot编码,什么意思呢,有几种状态就用一个几位的编码来表示状态,每种状态对应一个一位是1其余各位是0的编码,这样从向量的角度来讲,就是n维空间的n个基准向量,它们相互明显是平权的,此例中,我们分别用100,010,001来表示Mr,Mrs和Miss。
Sex(考虑):性别这个属性肯定是很重要的,毕竟全人类都讲究Lady First,所以遇到危险的时候,绅士们一定会先让女士逃走,因此女性的生存几率应该会大大提高。类似的,性别也是一个平权的状态变量,所以到时候我们同样采取one-hot编码的方式进行处理。
Age(考虑):这个变量和性别类似,都是明显会发挥重要作用的,因为无论何时,尊老爱幼总是为人们所推崇,但年龄对是否会获救的影响主要体现在那个人处在哪个年龄段,因此我们选择将它划分成一个状态变量,比如18以下叫child,18以上50以下叫adult,50以上叫elder,然后利用one-hot编码进行处理。不过这里还有一个问题就是年龄的值只有714个,它不全!这么重要的东西怎么能不全呢,所以我们只能想办法补全它。
又敲黑板,知识点又来了,缺失值我们怎么处理呢?最简单的方法,有缺失值的样本我们就扔掉,这种做法比较适合在样本数量很多,缺失值样本舍弃也可以接受的情况下,这样虽然信息用的不充分,但也不会引入额外的误差。然后,假装走心的方法就是用平均值或者中位数来填充缺失值,这通常是最简便的做法,但通常会带来不少的误差。最后,比较负责任的方法就是利用其它的变量去估计缺失变量的值,这样通常会更靠谱一点,当然也不能完全这样说,毕竟只要是估计值就不可避免的带来误差,但心理上总会觉得这样更好……
SibSp(考虑):船上兄弟姐妹或者配偶的数量。这个变量对最后的结果到底有什么影响我还真的说不准,但是预测年纪的时候说不定有用。
Parch(考虑):船上父母或者孩子的数量。这个变量和上个变量类似,我确实没有想到特别好的应用它的办法,同样的,预测年龄时这个应该挺靠谱的。
Ticket(忽略):船票的号码。恕我直言,这个谜一样的数字真的是不知道有什么鬼用,果断放弃了。
Fare(考虑):船票价格,这个变量的作用其实类似于社会地位,船票价格越高,享受的服务越高档,所以遇难获救的概率肯定相对较高,所以这是一个必须要考虑进去的变量。
Cabin(忽略):船舱号,这个变量或许透露出了一点船舱等级的信息,但是说实话,你的缺失值实在是太多了,我要是把它补全引入的误差感觉比它提供的信息还多,所以忍痛割爱,和你say goodbye!
Embarked(考虑):登船地点,按道理来说,这个变量应该是没什么卵用的,但介于它是一个只有三个状态的状态变量,那我们就把它处理一下放进模型,万一有用呢对吧。另外,它有两个缺失值,这里我们就不大动干戈的去预测了,就直接把它定为登船人数最多的S吧。
4. 分析数据和结果之前的关系(可视化)
4.1 相关系数图
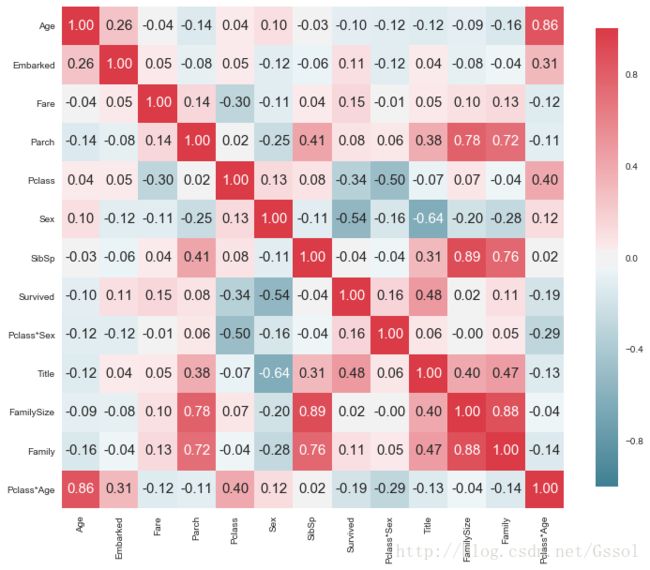
def plot_correlation_map(df):
corr = df.corr()
_, ax = plt.subplots(figsize=(12, 10))
cmap = sns.diverging_palette(220, 10, as_cmap=True)
_ = sns.heatmap( corr, cmap=cmap, square=True, cbar_kws={'shrink': .9}, ax=ax, annot=True, annot_kws={'fontsize': 15}, fmt='.2f' ) plot_correlation_map(titanic)

4.2 数据透视图以及对数据的处理
# 数据处理:
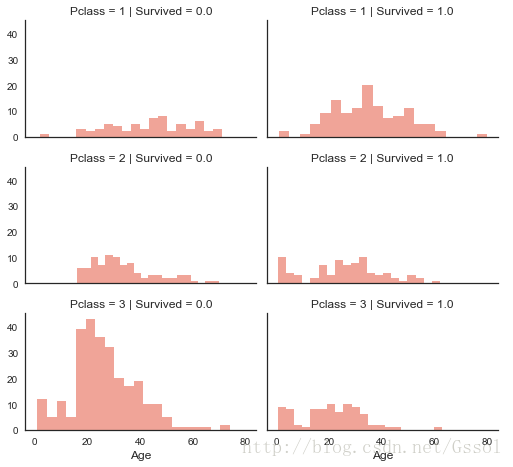
titanic = titanic.drop(['Cabin', 'PassengerId', 'Ticket'], axis=1) # 看等级和Survived之间的关系 titanic[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False) >>Pclass Survived 0 1 0.629630 1 2 0.472826 2 3 0.242363 >>> 可以看出1等级的幸存率较高 >>> 等级的幸存率分别为1>2>3 titanic[["Sex", "Survived"]].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False) >>> Sex Survived 0 female 0.742038 1 male 0.188908 >>> 可以看出女性的幸存率高于男性的幸存率 titanic[['Pclass', 'Sex', 'Survived']].groupby(['Pclass', 'Sex'], as_index=False).mean() >>> Pclass Sex Survived 0 1 female 0.968085 1 1 male 0.368852 2 2 female 0.921053 3 2 male 0.157407 4 3 female 0.500000 5 3 male 0.135447 >>> 性别和等级可以做一下特征各部分组合,比起单独的更容易划分 # 数据处理 titanic['Sex'] = titanic['Sex'].map({'female': 1, 'male': 4}).astype(int) # 如果设置为0,1 的话后面做特征组合会不好做 # titanic['Sex'] = pd.factorize(titanic.Sex)[0] >>> 把性别转化为1,4 titanic['Pclass*Sex'] = titanic.Pclass * titanic.Sex titanic['Pclass*Sex'] = pd.factorize(titanic['Pclass*Sex'])[0] titanic['Title'] = titanic.Name.str.extract(' ([A-Za-z]+)\.', expand=False) pd.crosstab(titanic['Title'], titanic['Sex']) >>> Sex 1 4 Title Capt 0 1 Col 0 2 Countess 1 0 Don 0 1 Dr 1 6 Jonkheer 0 1 Lady 1 0 Major 0 2 Master 0 40 Miss 182 0 Mlle 2 0 Mme 1 0 Mr 0 517 Mrs 125 0 Ms 1 0 Rev 0 6 Sir 0 1 titanic['Title'] = titanic['Title'].replace(['Capt', 'Col', 'Don', 'Dr','Jonkheer','Major', 'Rev', 'Sir'], 'Male_Rare') titanic['Title'] = titanic['Title'].replace(['Countess', 'Lady','Mlle', 'Mme', 'Ms'], 'Female_Rare') pd.crosstab(titanic['Title'], titanic['Sex']) >>> Sex 1 4 Title Female_Rare 6 0 Male_Rare 1 20 Master 0 40 Miss 182 0 Mr 0 517 Mrs 125 0 # 转化为数字,虽然不太合理,只是最后画相关矩阵的适合可以看到,最终训练的适合还是需要get_dummies处理 title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Female_Rare": 5, 'Male_Rale':6} titanic['Title'] = titanic['Title'].map(title_mapping) titanic['Title'] = titanic['Title'].fillna(0) titanic.head() # 兄弟姐妹的数量 titanic[["SibSp", "Survived"]].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False) >>> SibSp Survived 1 1 0.535885 2 2 0.464286 0 0 0.345395 3 3 0.250000 4 4 0.166667 5 5 0.000000 6 8 0.000000 # 中间的界限不是很明显 # 父母和孩子的数量 titanic[["Parch", "Survived"]].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived', ascending=False) Parch Survived 3 3 0.600000 1 1 0.550847 2 2 0.500000 0 0 0.343658 5 5 0.200000 4 4 0.000000 6 6 0.000000 # 可以考虑父母和孩子的总和 titanic[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False) >>> FamilySize Survived 3 4 0.724138 2 3 0.578431 1 2 0.552795 6 7 0.333333 0 1 0.303538 4 5 0.200000 5 6 0.136364 7 8 0.000000 8 11 0.000000 titanic.loc[titanic['FamilySize'] == 1, 'Family'] = 0 titanic.loc[(titanic['FamilySize'] > 1) & (titanic['FamilySize'] < 5), 'Family'] = 1 titanic.loc[(titanic['FamilySize'] >= 5), 'Family'] = 2 grid = sns.FacetGrid(titanic, col='Survived', row='Pclass', size=2.2, aspect=1.6) grid.map(plt.hist, 'Age', alpha=.5, bins=20) grid.add_legend();
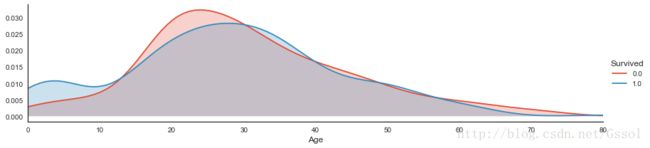
dataset = titanic[['Age', 'Sex', 'Pclass']] guess_ages = np.zeros((2, 3)) l = [1, 4] for i in range(len(l)): for j in range(0, 3): guess_df = dataset[(dataset['Sex'] == l[i]) & (dataset['Pclass'] == j + 1)]['Age'].dropna() # age_mean = guess_df.mean() # age_std = guess_df.std() # age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std) age_guess = guess_df.median() # Convert random age float to nearest .5 age guess_ages[i, j] = int(age_guess / 0.5 + 0.5) * 0.5 print(guess_ages) for i in range(len(l)): for j in range(0, 3): dataset.loc[(dataset.Age.isnull()) & (dataset.Sex == l[i]) & (dataset.Pclass == j + 1), 'Age'] = guess_ages[i, j] titanic['Age'] = dataset['Age'].astype(int) titanic.head(10) def plot_distribution(df, var, target, **kwargs): row = kwargs.get('row', None) col = kwargs.get('col', None) facet = sns.FacetGrid(df, hue=target, aspect=4, row=row, col=col) facet.map(sns.kdeplot, var, shade=True) facet.set(xlim=(0, df[var].max())) facet.add_legend() plot_distribution(titanic, var='Age', target='Survived')
sns.FacetGrid(titanic, col='Survived').map(plt.hist, 'Age', bins=20)
- 1

titanic['AgeBand'] = pd.cut(titanic['Age'], 4)
titanic[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True) >>> AgeBand Survived 0 (0.34, 20.315] 0.458101 1 (20.315, 40.21] 0.397403 2 (40.21, 60.105] 0.390625 3 (60.105, 80.0] 0.227273 >>> 按照上面的年龄段来进行划分 # 数据处理 titanic.loc[titanic['Age'] <= 20, 'Age'] = 4 titanic.loc[(titanic['Age'] > 20) & (full['Age'] <= 40), 'Age'] = 5 titanic.loc[(titanic['Age'] > 40) & (full['Age'] <= 60), 'Age'] = 6 titanic.loc[titanic['Age'] > 60, 'Age'] = 7
titanic[['Age', 'Survived']].groupby(['Age'], as_index=False).mean()
>>> Age Survived 0 4.0 0.458101 1 5.0 0.397403 2 6.0 0.390625 3 7.0 0.227273 titanic[['Pclass', 'Age', 'Survived']].groupby(['Pclass', 'Age'], as_index=False).mean() Pclass Age Survived 0 1 4.0 0.809524 1 1 5.0 0.741573 2 1 6.0 0.580645 3 1 7.0 0.214286 4 2 4.0 0.742857 5 2 5.0 0.423077 6 2 6.0 0.387097 7 2 7.0 0.333333 8 3 4.0 0.317073 9 3 5.0 0.223958 10 3 6.0 0.057143 11 3 7.0 0.200000 titanic['Pclass*Age'] = titanic.Pclass * titanic.Age titanic[['Pclass*Age', 'Survived']].groupby(['Pclass*Age'], as_index=False).mean().sort_values(by='Survived', ascending=False) >>>Pclass*Age Survived 0 4.0 0.809524 4 8.0 0.742857 1 5.0 0.741573 2 6.0 0.580645 5 10.0 0.423077 7 14.0 0.333333 6 12.0 0.331169 8 15.0 0.223958 3 7.0 0.214286 10 21.0 0.200000 9 18.0 0.057143 titanic[['Sex', 'Age', 'Survived']].groupby(['Sex', 'Age'], as_index=False).mean().sort_values(by='Survived', ascending=False) >>> Sex Age Survived 3 1 7.0 1.000000 1 1 5.0 0.786765 2 1 6.0 0.755556 0 1 4.0 0.688312 4 4 4.0 0.284314 6 4 6.0 0.192771 5 4 5.0 0.184739 7 4 7.0 0.105263
def plot_bar(df, cols):
# 看看各乘客等级的获救情况 fig = plt.figure() fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_0 = df[cols][df.Survived == 0].value_counts() Survived_1 = df[cols][df.Survived == 1].value_counts() data = pd.DataFrame({u'Survived': Survived_1, u'UnSurvived': Survived_0}) data.plot(kind='bar', stacked=True) plt.title(cols + u"_survived") plt.xlabel(cols) plt.ylabel(u"count") plt.show() plot_bar(titanic, cols='Embarked')

def plot_categories(df, cat, target, **kwargs):
row = kwargs.get('row', None) col = kwargs.get('col', None) facet = sns.FacetGrid(df, row=row, col=col) facet.map(sns.barplot, cat, target) facet.add_legend() plot_categories(titanic, cat='Embarked', target='Survived')

# 因为全部数据中Embarked,所以,可以用众数来填充, 并将其转化为数字
freq_port = titanic.Embarked.dropna().mode()[0]
titanic['Embarked'] = titanic['Embarked'].fillna(freq_port)
titanic[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False) titanic['Embarked'] = titanic['Embarked'].map({'S': 0, 'C': 1, 'Q': 2}).astype(int) titanic.head()
# Fare预测数据特征里面也有缺失值,需要填充
# 用中位数进行填充, 然后划分Fare段
titanic['Fare'].fillna(titanic['Fare'].dropna().median(), inplace=True)
def plot_distribution(df, var, target, **kwargs):
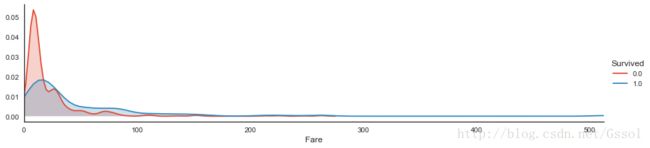
row = kwargs.get('row', None) col = kwargs.get('col', None) facet = sns.FacetGrid(df, hue=target, aspect=4, row=row, col=col) facet.map(sns.kdeplot, var, shade=True) facet.set(xlim=(0, df[var].max())) facet.add_legend() plot_distribution(titanic, var='Fare', target='Survived')
titanic['FareBand'] = pd.cut(titanic['Fare'], 4) titanic[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True) >>> FareBand Survived 0 (-0.512, 128.082] 0.368113 1 (128.082, 256.165] 0.724138 2 (256.165, 384.247] 0.666667 3 (384.247, 512.329] 1.000000 titanic.loc[titanic['Fare'] <= 128.082, 'Fare'] = 0 titanic.loc[(titanic['Fare'] > 128.082) & (titanic['Fare'] <= 256.165), 'Fare'] = 1 titanic.loc[(titanic['Fare'] > 256.165) & (titanic['Fare'] <= 384.247), 'Fare'] = 2 titanic.loc[titanic['Fare'] > 384.247, 'Fare'] = 3 titanic['Fare'] = titanic['Fare'].astype(int) titanic = titanic.drop(['Name', 'FareBand'], axis=1) plot_correlation_map(titanic)
titanic['Sex'] = titanic['Sex'].astype('int').astype('str') titanic = pd.get_dummies(titanic, prefix='Sex') titanic.head() titanic['Embarked'] = titanic['Embarked'].astype('str') titanic = pd.get_dummies(titanic, prefix='Embarked') titanic['Title'] = titanic['Title'].astype('str') titanic = pd.get_dummies(titanic, prefix='Title') plot_correlation_map(titanic)

5. 完整的数据处理过程
train = pd.read_csv('base_data/train.csv')
test = pd.read_csv('base_data/test.csv') full = train.append(test, ignore_index=True) # 保证train和test的数据格式一样 titanic = full[:891] titanic_pre = full[891:] del train, test print ('DataSets: ', 'full: ', full.shape, 'titanic: ', titanic.shape) full = full.drop(['Cabin', 'PassengerId', 'Ticket'], axis=1) full['Sex'] = full['Sex'].map({'female': 1, 'male': 4}).astype(int) full['Pclass*Sex'] = full.Pclass * full.Sex full['Pclass*Sex'] = pd.factorize(full['Pclass*Sex'])[0] full['Title'] = full.Name.str.extract(' ([A-Za-z]+)\.', expand=False) full['Title'] = full['Title'].replace(['Capt', 'Col', 'Don', 'Dr','Jonkheer','Major', 'Rev', 'Sir'], 'Male_Rare') full['Title'] = full['Title'].replace(['Countess', 'Lady','Mlle', 'Mme', 'Ms'], 'Female_Rare') title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Female_Rare": 5, 'Male_Rale':6} full['Title'] = full['Title'].map(title_mapping) full['Title'] = full['Title'].fillna(0) full.head() full['FamilySize'] = full['Parch'] + full['SibSp'] + 1 full.loc[full['FamilySize'] == 1, 'Family'] = 0 full.loc[(full['FamilySize'] > 1) & (full['FamilySize'] < 5), 'Family'] = 1 full.loc[(full['FamilySize'] >= 5), 'Family'] = 2 dataset = full[['Age', 'Sex', 'Pclass']] guess_ages = np.zeros((2, 3)) l = [1, 4] for i in range(len(l)): for j in range(0, 3): guess_df = dataset[(dataset['Sex'] == l[i]) & (dataset['Pclass'] == j + 1)]['Age'].dropna() # age_mean = guess_df.mean() # age_std = guess_df.std() # age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std) age_guess = guess_df.median() # Convert random age float to nearest .5 age guess_ages[i, j] = int(age_guess / 0.5 + 0.5) * 0.5 print(guess_ages) for i in range(len(l)): for j in range(0, 3): dataset.loc[(dataset.Age.isnull()) & (dataset.Sex == l[i]) & (dataset.Pclass == j + 1), 'Age'] = guess_ages[i, j] full['Age'] = dataset['Age'].astype(int) full.loc[full['Age'] <= 20, 'Age'] = 4 full.loc[(full['Age'] > 20) & (full['Age'] <= 40), 'Age'] = 5 full.loc[(full['Age'] > 40) & (full['Age'] <= 60), 'Age'] = 6 full.loc[full['Age'] > 60, 'Age'] = 7 full.head() full['Pclass*Age'] = full.Pclass * full.Age freq_port = full.Embarked.dropna().mode()[0] full['Embarked'] = full['Embarked'].fillna(freq_port) full[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False) full['Embarked'] = full['Embarked'].map({'S': 0, 'C': 1, 'Q': 2}).astype(int) full.head() # Fare预测数据特征里面也有缺失值,需要填充 # 用中位数进行填充, 然后划分Fare段 full['Fare'].fillna(full['Fare'].dropna().median(), inplace=True) full.loc[full['Fare'] <= 128.082, 'Fare'] = 0 full.loc[(full['Fare'] > 128.082) & (full['Fare'] <= 256.165), 'Fare'] = 1 full.loc[(full['Fare'] > 256.165) & (full['Fare'] <= 384.247), 'Fare'] = 2 full.loc[full['Fare'] > 384.247, 'Fare'] = 3 full['Fare'] = full['Fare'].astype(int) full = full.drop(['Name'], axis=1) full = full.drop(['Parch', 'SibSp', 'FamilySize'], axis=1) full['Sex'] = full['Sex'].astype('int').astype('str') full = pd.get_dummies(full, prefix='Sex') full.head() full['Embarked'] = full['Embarked'].astype('str') full = pd.get_dummies(full, prefix='Embarked') full.head() full['Title'] = full['Title'].astype('str') full = pd.get_dummies(full, prefix='Title') full = full.drop(['Survived'], axis=1)
6. 选择模型
def COMPARE_MODEL(train_valid_X, train_valid_y):
def cross_model(model, train_X, train_y):
cvscores = cross_val_score(model, train_X, train_y, cv=3, n_jobs=-1)
return round(cvscores.mean() * 100, 2) train_X, valid_X, train_y, valid_y = train_test_split(train_valid_X, train_valid_y, train_size=.78, random_state=0) def once_model(clf): clf.fit(train_X, train_y) y_pred = clf.predict(valid_X) return round(accuracy_score(y_pred, valid_y) * 100, 2) logreg = LogisticRegression() acc_log = cross_model(logreg, train_valid_X, train_valid_y) acc_log_once = once_model(logreg) xgbc = XGBClassifier() acc_xgbc = cross_model(xgbc, train_valid_X, train_valid_y) acc_xgbc_once = once_model(xgbc) svc = SVC() acc_svc = cross_model(svc, train_valid_X, train_valid_y) acc_svc_once = once_model(svc) knn = KNeighborsClassifier(n_neighbors=3) acc_knn = cross_model(knn, train_valid_X, train_valid_y) acc_knn_once = once_model(knn) gaussian = GaussianNB() acc_gaussian = cross_model(gaussian, train_valid_X, train_valid_y) acc_gaussian_once = once_model(gaussian) perceptron = Perceptron() acc_perceptron = cross_model(perceptron, train_valid_X, train_valid_y) acc_perceptron_once = once_model(perceptron) linear_svc = LinearSVC() acc_linear_svc = cross_model(linear_svc, train_valid_X, train_valid_y) acc_linear_svc_once = once_model(linear_svc) sgd = SGDClassifier() acc_sgd = cross_model(sgd, train_valid_X, train_valid_y) acc_sgd_once = once_model(sgd) decision_tree = DecisionTreeClassifier() acc_decision_tree = cross_model(decision_tree, train_valid_X, train_valid_y) acc_decision_tree_once = once_model(decision_tree) random_forest = RandomForestClassifier(n_estimators=100) acc_random_forest = cross_model(random_forest, train_valid_X, train_valid_y) acc_random_forest_once = once_model(random_forest) gbc = GradientBoostingClassifier() acc_gbc = cross_model(gbc, train_valid_X, train_valid_y) acc_gbc_once = once_model(gbc) models = pd.DataFrame({ 'Model': ['XGBC', 'Support Vector Machines', 'KNN', 'Logistic Regression', 'Random Forest', 'Naive Bayes', 'Perceptron', 'Stochastic Gradient Decent', 'Linear SVC', 'Decision Tree', 'GradientBoostingClassifier'], 'Score': [acc_xgbc, acc_svc, acc_knn, acc_log, acc_random_forest, acc_gaussian, acc_perceptron, acc_sgd, acc_linear_svc, acc_decision_tree, acc_gbc]}) models_once = pd.DataFrame({ 'Model': ['XGBC', 'Support Vector Machines', 'KNN', 'Logistic Regression', 'Random Forest', 'Naive Bayes', 'Perceptron', 'Stochastic Gradient Decent', 'Linear SVC', 'Decision Tree', 'GradientBoostingClassifier'], 'Score': [acc_xgbc_once, acc_svc_once, acc_knn_once, acc_log_once, acc_random_forest_once, acc_gaussian_once, acc_perceptron_once, acc_sgd_once, acc_linear_svc_once, acc_decision_tree_once, acc_gbc_once]}) models = models.sort_values(by='Score', ascending=False) models_once = models_once.sort_values(by='Score', ascending=False) return models, models_once train_valid_X = full[0:891] train_valid_y = titanic.Survived test_X = full[891:] train_X, valid_X, train_y, valid_y = train_test_split(train_valid_X, train_valid_y, train_size=.78, random_state=0) print(full.shape, train_X.shape, valid_X.shape, train_y.shape, valid_y.shape, test_X.shape) models_cross, models_once = COMPARE_MODEL(train_valid_X, train_valid_y) xgbc = XGBClassifier() xgbc.fit(train_valid_X, train_valid_y) test_Y_xgbc = xgbc.predict(test_X) passenger_id = titanic_pre.PassengerId test = pd.DataFrame({'PassengerId': passenger_id, 'Survived': np.round(test_Y_xgbc).astype('int32')}) print test.head() test.to_csv('titanic_pred_gbdc_sc.csv', index=False)