【数字IC】从零开始的Verilog SPI设计
从零开始的Verilog SPI协议设计
-
- 一、写在前面
-
- 1.1 协议标准
- 1.2 数字IC组件代码
- 1.3 设计要求
- 1.4 其他协议解读
- 二、设计思想
-
- 2.1 从设备读写时序(reg_array)
-
- 2.1.1 写时序
- 2.1.2 读时序
- 2.2 从设备的控制器设计思想(SPI_slave_controller)
- 2.3 主设备设计思想
-
- 2.3.1 波特率分频器设计思想(BaudratePrescaler)
- 2.3.2 数据发送的控制器(SPI_master_contorller)
- 三、从设备(reg_array)
-
- 3.1 状态机跳变
- 3.2 设计文件
- 3.3 仿真文件
- 3.4 仿真结果
- 四、从设备控制器设计(SPI_slave_controller)
-
- 4.1 设计文件(SPI_slave_controller)
- 4.2 仿真文件(SPI_slave)
- 4.3 仿真结果
- 四、波特率分频器(BaudratePrescaler)
-
- 4.1 设计文件
- 4.2 仿真文件
- 4.3 仿真结果
- 五、SPI主设备控制器(SPI_master_controller)
-
- 5.1 状态机跳变(SPI_master_controller)
- 5.2 设计文件(SPI_master_controller)
-
- 5.2.1如何让SPI pipeline起来
- 5.2 仿真文件
- 5.3 仿真结果
- 六、本设计与工业级SPI的差距
一、写在前面
上一节中,我们详细讨论了SPI的协议内容并从设计组件的角度给出了SPI协议中所需要的诸多内容,以供读者参考
这一节中,我们自定义如下标准的SPI主从设备进行设计,需要注意的是,本篇文章中所涉及的SPI仅供初学者学习参考,并没有采用实际工业开发中所涉及到的代码标准和思考,也并未进行综合与后仿。
1.1 协议标准
- 【数字IC】深入浅出理解SPI协议
1.2 数字IC组件代码
- 【数字IC手撕代码】Verilog奇数分频|题目|原理|设计|仿真
- 【数字IC手撕代码】Verilog偶数分频|题目|原理|设计|仿真
- 【数字IC手撕代码】Verilog半整数分频|题目|原理|设计|仿真
- 【数字IC手撕代码】Verilog小数分频|题目|原理|设计|仿真
1.3 设计要求
- 一个主设备,一个从设备的SPI全双工通信,从设备是一个寄存器组
- 全局时钟100Mhz
- CPOL = 0,CPHA = 1
- 可支持波特率2,4,8,16分频四种状态
- 数据传输为MSB(高位优先)
- 数据位宽固定8位
1.4 其他协议解读
- 【数字IC】深入浅出理解UART
- 【数字IC】从零开始的Verilog UART设计
二、设计思想
2.1 从设备读写时序(reg_array)
我们想要在本篇博客中用SPI的方式操控从设备:一个位宽为8bit,深度为16位的寄存器组,寄存器组在数字IC设计中颇为常见,也颇为基础,非常适合在本篇博客中用以展示SPI串行总线的奥妙,CPU的内部就需要寄存器组作为最低level的存储层级,因为SPI协议的数据通信单方向只有一条线,因此我们需要使用这一根线来控制寄存器组的读写时序,本寄存器组的读写逻辑由作者自行定义。
2.1.1 写时序
需要两拍才能执行完毕,第一拍从data_in发送地址和模式,其中地址为前四位,模式为后四位,若需要往寄存器组中写数据,第一拍的后四位需要为“1111”,写模式第二拍从data_in发送需要写入的发送数据
(需要注意的是,受限于SPI的串型接口,一拍的相当于SCK的八倍频时钟信号,即需要八个时钟周期接收到一个字节,为一拍)
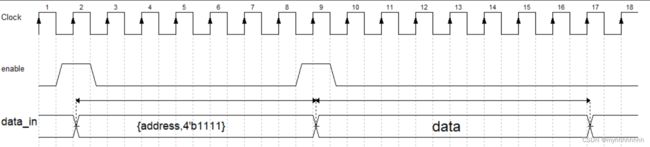
2.1.2 读时序
需要两拍才能执行完毕,第一拍从data_in发送地址和模式,其中读地址为前四位,模式为后四位,若需要从寄存器组中读数据,第一拍的后四位需要为“0000”,读模式第二拍从data_out发送需要读出的发送数据
(需要注意的是,受限于SPI的串型接口,一拍的相当于是SCK的八倍频时钟信号,即需要八个时钟周期接收到一个字节,为一拍)

2.2 从设备的控制器设计思想(SPI_slave_controller)
单独的reg_array没有办法按照SPI协议直接相连,因为SPI是一款串行总线,而我们上面提到的reg_array使用的是并行接口,因此我们需要一个SPI的控制器来与reg_array连接,根据协议的内容,这个控制器的功能为
- 串并转换:即将接收到的来自主设备的MOSI串行信号翻译成reg_array可懂的并行信号,以此供从设备采集
- 并串转换:即将来自从设备的输出值(并行量)翻译为串型量,发送到MISO位置处,传递给主设备
- 输出从设备的控制信号:比如上文读写时序中,寄存器组状态跳变的就需要enable信号的控制,enable信号什么时候输出,这个是来自SPI_slave的控制的
2.3 主设备设计思想
2.3.1 波特率分频器设计思想(BaudratePrescaler)
在【数字IC】深入浅出理解SPI协议,我们探讨了为什么要对SPI时钟信号进行分频,并确定了2,4,8,16分频的四个参数,按照偶数分频的思想,我们可以采用寄存器级联法或计数器法的方法进行分频,二者均可满足目的,作者选择了更为简单的寄存器级联法来进行分频操作
2.3.2 数据发送的控制器(SPI_master_contorller)
在主设备端,我们同样需要一个控制器来发送数据,这个控制器首先需要对MCU/CPU来的数据进行串并转换,其次,它也需要告诉SPI的四条线,什么时候nss拉低,什么时候发送数据,因此我们肯定需要按照状态对其进行划分,区分状态机的跳转。
三、从设备(reg_array)
3.1 状态机跳变
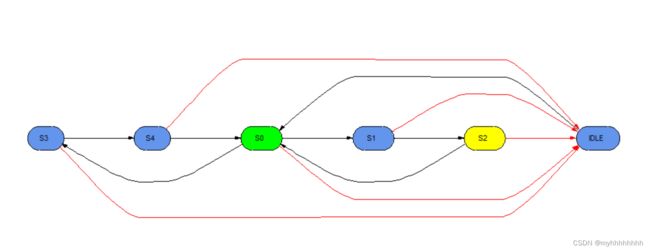
IDLE:是待机状态,当其接收到css的拉低信号时,跳转到S0
S0:S0状态代表该从设备已经被选中了
S1和S2:是读取操作的状态机
S3和S4:是写入操作的状态机
本状态机跳转图由Questasim自动生成,相关操作更新于
如何自动生成设计文件的状态机跳转图(仿真工具使用技巧)
3.2 设计文件
module reg_array(
input clk,
input rst_n,
input nss,
input enable, // to ensure that it can sample data_in
input [7:0] data_in,
output reg [7:0] data_out,
output done//读取操作的完成信号);
localparam IDLE = 3'b000;
localparam S0 = 3'b001;
localparam S1 = 3'b010;
localparam S2 = 3'b011;
localparam S3 = 3'b100;
localparam S4 = 3'b101;
reg [2:0] state;
reg [2:0] nstate;
reg [7:0] array [0 : 15];
reg [3:0] address;
//状态机第一段
always@(posedge clk or negedge rst_n)
if(!rst_n)
state <= IDLE ;
else
state <= nstate;
//状态机第二段
always@(*)
begin
case(state)
IDLE : nstate = !nss ? S0 :IDLE;
S0 : nstate = (enable & data_in[3:0] == 4'b0000) ? S1 : (enable & data_in[3:0] == 4'b1111) ? S3 : S0;
S1 : nstate = (enable) ? S2 : S1;
S2 : nstate = !nss ? S0 : IDLE;
S3 : nstate = (enable) ? S4 : S3;
S4 : nstate = !nss ? S0 : IDLE;
default: nstate = IDLE;
endcase
end
//数据读取操作
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin
array[0] <= 16'h0000;
array[1] <= 16'h0000;
array[2] <= 16'h0000;
array[3] <= 16'h0000;
array[4] <= 16'h0000;
array[5] <= 16'h0000;
array[6] <= 16'h0000;
array[7] <= 16'h0000;
array[8] <= 16'h0000;
array[9] <= 16'h0000;
array[10] <= 16'h0000;
array[11] <= 16'h0000;
array[12] <= 16'h0000;
array[13] <= 16'h0000;
array[14] <= 16'h0000;
array[15] <= 16'h0000;
end
else if (nstate == S2)
data_out <= array[address];
else if (nstate == S4)
array[address] <= data_in;
else
data_out <= data_out;
//地址操作
always@(posedge clk or negedge rst_n)
if(!rst_n)
address <= 4'h0;
else if(state == S0 && enable)
address <= data_in[7:4];
else
address <= address;
assign done = (state==S2 && nstate == S0) ? 1 : 0 ;
endmodule
3.3 仿真文件
`timescale 1ns / 1ps
module reg_array_tb ();
reg clk;
reg rst_n;
reg nss;
reg enable;
reg [7:0] data_in;
wire [7:0] data_out;
wire done;
reg_array u1 (clk,rst_n,nss,enable,data_in,data_out,done);
task reset;
begin
clk = 0;
rst_n = 1;
nss = 1;
enable = 0;
@(negedge clk);
rst_n = 0;
@(negedge clk);
rst_n = 1;
@(negedge clk);
@(negedge clk);
end
endtask
task write;
input [3:0] w_address;
input [7:0] w_data;
begin
@(negedge clk);
nss = 0;
enable = 0;
@(negedge clk);
enable = 1;
data_in = {w_address,4'b1111};
@(negedge clk);
data_in = w_data;
@(negedge clk);
end
endtask
task read;
input [3:0] r_address;
begin
@(negedge clk);
nss = 0;
enable = 0;
@(negedge clk);
enable = 1;
data_in = {r_address,4'b0000};
@(negedge clk);
enable = 0;
// data_in = r_data;
repeat(8) @(negedge clk);
enable = 1;
end
endtask
always #5 clk = !clk;
initial
begin
reset;
write(4'h3,8'h1a);
write(4'ha,8'ha4);
read(4'ha);
read(4'h3);
#2000 $stop;
end
endmodule
3.4 仿真结果

四、从设备控制器设计(SPI_slave_controller)
4.1 设计文件(SPI_slave_controller)
需要关注的是,SPI_slave_controller设计虽然有诸多接口,但是实际上与主设备相连的只有四个,即,sck,nss,mosi,miso,其它的的接口都是体现在从设备整体内部的互联,体现了SPI通信的四根线的原则。
module SPI_slave_controller
#(parameter CPOL = 1'b0,
parameter CPHA = 1'b0)
(input mosi,
input nss,
input sck,
input rst_n,
input done,// done信号来控制什么时候该发送读出的数据
input [7:0] data_in, //来自reg_array的data_in(读出的数据)
output reg enable,
output[7:0]data_out, //送往reg_array的data_out(写入寄存器组的数据)
output reg miso);
reg [0:7] receive_reg;
reg [0:7] send_reg;
reg [3:0] r_cnt;
reg [3:0] s_cnt;
// 数据采样
always@(posedge sck or negedge rst_n )
if(!rst_n)
receive_reg <= 8'h00;
else if(nss)
receive_reg <= receive_reg;
else
receive_reg[r_cnt]<= mosi;
//采样计数器,接收满一个字节重置
always@(posedge sck or negedge rst_n)
if(!rst_n)
r_cnt <= 4'h0;
else if(nss || r_cnt == 4'h7)
r_cnt <= 4'h0;
else
r_cnt <= r_cnt + 1'b1;
//reg_array的控制信号生成
always@(posedge sck or negedge rst_n)
if(!rst_n)
enable <= 1'b0;
else if(!nss && r_cnt == 4'h7)
enable <= 1'b1;
else
enable <= 1'b0;
assign data_out = enable ? receive_reg : 8'h00;
// 数据的发送
always@(negedge sck or negedge rst_n)
if(!rst_n)
send_reg <= 8'h00;
else if(done)
send_reg <= data_in;
else if(!nss && s_cnt < 4'h8)
miso <= send_reg[s_cnt];
else
miso <= 1'bx;
//数据发送计数器
always@(negedge sck or negedge rst_n)
if(!rst_n)
s_cnt <= 4'h0;
else if(nss || s_cnt == 4'h7)
s_cnt <= 4'h0;
else
s_cnt <= s_cnt + 1'b1;
endmodule
4.2 仿真文件(SPI_slave)
这里按照主设备的发送时序,写了名为r_data的task,以此用来仿真,另外的的一个task是时钟复位task,此处的仿真文件,直接将控制器和寄存器组作为整体来进行仿真,没有单独区分控制器的仿真
`timescale 1ns / 1ps
module SPI_slave_tb ();
reg mosi;
reg nss;
reg sck;
reg rst_n;
wire done;
wire [7:0] data_in;
wire enable;
wire [7:0]data_out;
wire miso;
reg_array u1 (.clk(sck),.rst_n(rst_n),.nss(nss),.enable(enable),.data_in(data_out),.data_out(data_in),.done(done));
SPI_slave_controller #(0,0)u2 (.mosi(mosi),.nss(nss),.sck(sck),.rst_n(rst_n),.done(done),
.data_in(data_in),.enable(enable),.data_out(data_out),.miso(miso));
task reset;
begin
sck = 0;
rst_n = 1;
nss = 1;
@(negedge sck);
rst_n = 0;
@(negedge sck);
rst_n = 1;
@(negedge sck);
@(negedge sck);
end
endtask
task r_data;
input [7:0] r_data;
begin
@(negedge sck);
nss = 0;
#0.5
mosi = r_data[7];
@(negedge sck);
mosi = r_data[6];
@(negedge sck);
mosi = r_data[5];
@(negedge sck);
mosi = r_data[4];
@(negedge sck);
mosi = r_data[3];
@(negedge sck);
mosi = r_data[2];
@(negedge sck);
mosi = r_data[1];
@(negedge sck);
mosi = r_data[0];
end
endtask
always #5 sck = !sck;
initial
begin
reset;
r_data(8'haf);
r_data(8'h13);
r_data(8'ha0);
r_data(8'h00);
#1000
$stop;
end
endmodule
4.3 仿真结果
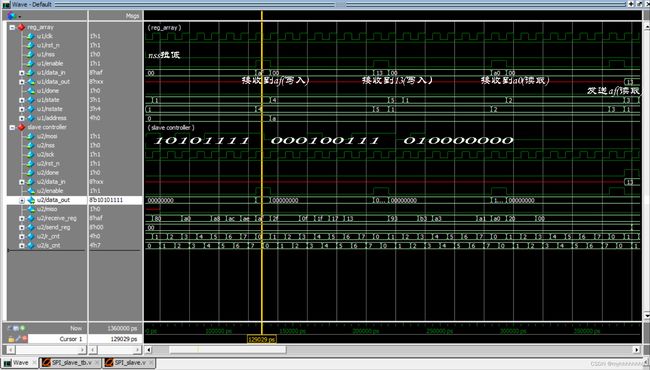
拉低nss后,我们按照slave的读写时序,先写后读,先向地址a中写入13,再从a地址中读出写入的数据,发现二者相符,需要注意的是,此slave的读取操作的第二拍,主设备依旧会发送数据,体现了【数字IC】深入浅出理解SPI协议所说SPI协议的本质是两个移位寄存器不断地互相交换数据,不过读操作第二拍发送的数据不会对寄存器的存储值产生影响
四、波特率分频器(BaudratePrescaler)
4.1 设计文件
module BaudratePrescaler #(parameter Prescaler = 2'b01)
( input clk,
input rst_n,
output reg clk_scaler
);
reg scaler_2;
reg scaler_4;
reg scaler_8;
reg scaler_16;
always@(posedge clk or negedge rst_n)
if(!rst_n)
scaler_2 <= 1'b0;
else
scaler_2 <= !scaler_2;
always@(posedge scaler_2 or negedge rst_n)
if(!rst_n)
scaler_4 <= 1'b0;
else
scaler_4 <= !scaler_4;
always@(posedge scaler_4 or negedge rst_n)
if(!rst_n)
scaler_8 <= 1'b0;
else
scaler_8 <= !scaler_8;
always@(posedge scaler_8 or negedge rst_n)
if(!rst_n)
scaler_16 <= 1'b0;
else
scaler_16 <= !scaler_16;
always@(*)
case(Prescaler)
2'b00: clk_scaler = scaler_2;
2'b01: clk_scaler = scaler_4;
2'b10: clk_scaler = scaler_8;
2'b11: clk_scaler = scaler_16;
default: clk_scaler = 1'b0;
endcase
endmodule
4.2 仿真文件
`timescale 1ns / 1ps
module BaudratePrescaler_tb ();
reg clk;
reg rst_n;
wire clk_scaler;
BaudratePrescaler #(0) u0 (clk,rst_n,clk_scaler);
BaudratePrescaler #(1) u1 (clk,rst_n,clk_scaler);
BaudratePrescaler #(2) u2 (clk,rst_n,clk_scaler);
BaudratePrescaler #(3) u3 (clk,rst_n,clk_scaler);
BaudratePrescaler #(4) u4 (clk,rst_n,clk_scaler);
task reset;
begin
@(negedge clk);
rst_n = 0;
@(negedge clk);
@(negedge clk);
rst_n = 1;
end
endtask
initial
begin
clk = 0;
rst_n = 1;
reset;
#1000
$stop;
end
always #5 clk = !clk;
endmodule
4.3 仿真结果

我们按照Prescaler的值分别例化了五个module,分别是二分频,四分频,八分频,十六分频和错误分频,观察输出的值,符合预期,设计成立。
五、SPI主设备控制器(SPI_master_controller)
5.1 状态机跳变(SPI_master_controller)
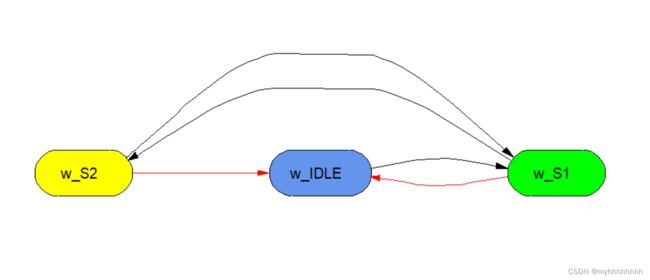
w_IDLE是复位以后的状态,当接收到enable信号后跳转到w_S1状态
w_S1是发送前7bit的状态
w_S2是发送最后1bit的状态
为什么需要用两个状态来表示同样的一个发送行为呢?跳转到5.2.1即可寻找到答案。
5.2 设计文件(SPI_master_controller)
module SPI_master
#(parameter Prescaler = 2'b00,
parameter CPOL = 0,
parameter CPHA = 1)
(input clk,
input rst_n,
input enable,
input [7:0] data_in,
input miso,
output sck_o,
output reg mosi,
output nss);
localparam w_IDLE = 2'b00;
localparam w_S1 = 2'b01;
localparam w_S2 = 2'b10;
reg [1:0] w_state;
reg [1:0] w_nstate;
reg [7:0] send_reg_1;
reg send_reg_2;
reg [0:7] receive_reg;
reg [2:0] w_cnt;
reg [2:0] r_cnt;
wire [7:0] data_out;
reg nss_r;
always@(negedge clk or negedge rst_n)
if(!rst_n)
w_state <= w_IDLE;
else
w_state <= w_nstate;
always@(*)
case(w_state)
w_IDLE : w_nstate = enable ? w_S1 : w_IDLE;
w_S1 : w_nstate = (w_cnt == 3'h6) ? w_S2 : w_S1;
w_S2 : w_nstate = enable ? w_S1 : w_IDLE;
default: w_nstate = w_IDLE;
endcase
always@(negedge clk or negedge rst_n)
if(!rst_n)
send_reg_1 <= 8'h00;
else if(w_state == w_IDLE && enable || w_state == w_S1 || w_state == w_S2)
send_reg_1 <= data_in;
else
send_reg_1 <= 8'h00;
always@(negedge clk or negedge rst_n)
if(!rst_n)
send_reg_2 <= 1'h0;
else if(w_state == w_S1 && w_cnt == 3'h1)
send_reg_2 <= send_reg_1[1];
else
send_reg_2 <= 1'h0;
always@(negedge clk or negedge rst_n)
if(!rst_n)
w_cnt <= 3'h0;
else if(w_state == w_S1 || w_state == w_S2 )
w_cnt <= w_cnt + 1'b1;
else if (w_cnt == 3'h7)
w_cnt <= 3'h0;
else
w_cnt <= w_cnt;
always@(*)
if(w_state == w_S1)
mosi = send_reg_1[w_cnt];
else if(w_state == w_S2)
mosi = send_reg_2;
else
mosi = 1'bx;
always@(negedge clk or negedge rst_n)
if(!rst_n )
nss_r <= 1'b1;
else if(w_state == w_IDLE && enable || w_state == w_S1 || w_state == w_S2)
nss_r <= 1'b0;
else if(w_state == w_IDLE || !enable)
nss_r <= 1'b1;
else
nss_r <= nss_r;
assign nss = nss_r;
// read_statement
always@(posedge clk or negedge rst_n)
if(!rst_n)
r_cnt <= 3'h0;
else if(r_cnt < 3'h7 && enable)
r_cnt <= r_cnt + 1'b1;
else if(r_cnt == 3'h7)
r_cnt <= 3'h0;
else
r_cnt <= r_cnt;
always@(posedge clk or negedge rst_n)
if(!rst_n)
receive_reg <= 8'h00;
else if(!nss_r)
receive_reg[r_cnt] <= miso;
else
receive_reg <= receive_reg;
assign data_out = r_cnt == 3'h7 ? receive_reg : 8'hx;
assign sck_o = (!rst_n) ? CPOL : clk ;
endmodule
5.2.1如何让SPI pipeline起来
当8bit的数据传输进来后,依次按从高到低的顺序进行发送,存储这8bit的寄存器是send_reg_1,但是这种形式没有办法pipeline起来,因为8bit寄存器内部数值的更新会暂停整个数据的发送(相当于需要暂停一个时钟周期),因此使用了一个send_reg_2,来保留最后1bit的数据,通过增大面积的方式减少了暂停产生的SPI带宽损失。
5.2 仿真文件
这里的仿真也同样是将波特率分频器和主设备控制器共同进行仿真,第一段代码为二者连接的.v文件,第二段代码为二者的仿真文件。
module top_module
(input clk,
input rst_n,
input enable,
input [7:0] data_in_top,
input miso,
output nss,
output sck_o,
output mosi
);
wire clk_sacler;
wire [7:0] data_in;
BaudratePrescaler u1 (.clk(clk),.rst_n(rst_n),.clk_scaler(clk_scaler));
SPI_master u2 (.clk(clk_scaler),.rst_n(rst_n),.enable(enable),
.data_in(data_in_top),.miso(miso),.sck_o(sck_o),.mosi(mosi),.nss(nss));
endmodule
`timescale 1ns / 1ps
module top_module_tb();
reg clk;
reg rst_n;
reg enable;
reg [7:0] data_in;
reg miso;
wire sck_o;
wire mosi;
wire nss;
top_module u1 (.clk(clk),.rst_n(rst_n),.enable(enable),.data_in_top(data_in),.miso(miso));
task reset;
begin
clk = 0;
rst_n=1;
enable = 0;
data_in = 8'h00;
miso = 1;
@(negedge clk);
rst_n = 0;
@(negedge clk);
rst_n = 1;
enable =1;
#0.5
data_in = 8'h1f;
end
endtask
always #5 clk = !clk;
initial
begin
reset;
#100;
enable = 0;
#1000;
enable = 1;
#2000;
$stop;
end
endmodule
5.3 仿真结果
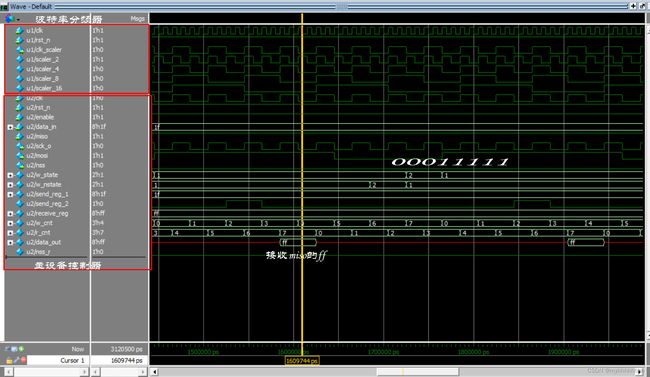
六、本设计与工业级SPI的差距
- 输入输出处使用FIFO做缓冲
感兴趣的读者可以参考 【数字IC手撕代码】Verilog同步FIFO,增加相对应的模块和控制信号,使整个SPI的设计更为完善
- CPOL与CPHA的更多状态
这里的案例只引入了CPOL和CPHA的一种状态,如果想要添加更多的状态可以使用条件编译的ifdef的方式来进行
- 从设备的复杂程度
我们案例的从设备只支持读写,其实以EEPROM——常用于SPI控制的内存芯片为例,读写的命令可以非常复杂,如顺序读写,随机读写,错误检测,错误矫正等诸多内容可以进行添加
- 等等等等
实际上,本设计仅为学习参考使用,配合【数字IC】深入浅出理解SPI协议使读者对于协议和电路实现有基本的认识才是本篇博文的目的所在。