yolo v4基础知识先导篇
*免责声明:
1\此方法仅提供参考
2\搬了其他博主的操作方法,以贴上路径.
3*
场景一:Mish激活函数
场景二:Mosaic数据增强
场景三:DropBlock正则化方法
场景四:CIoU Loss损失函数
场景五: CSPNet
场景六: FPN
场景七: PANet
场景八: DIOU NMS
…
场景一:Mish激活函数
Mish论文地址
改进: Hard-Mish
一个新的激活函数,ReLU的继任者



#绘制Mish激活函数
import math
import numpy as np
from matplotlib import pyplot as plt
def mish(x):
return x * math.tanh(math.log(1+math.exp(x)))
x = np.linspace(-10,10,1000)
y=[]
for i in x:
y.append(mish(i))
plt.plot(x,y)
plt.grid()
plt.show()

场景二:Mosaic数据增强
原文链接
YoloV4当中的Mosaic数据增强方法(附代码讲解)



代码可跳过
from PIL import Image, ImageDraw
import numpy as np
from matplotlib.colors import rgb_to_hsv, hsv_to_rgb
"""
数据增强的方式:
数据增强其实就是让图片变得更加多样,数据增强是非常重要的提高目标检测算法鲁棒性的手段。
可以通过改变亮度,图像扭曲等方式使得图像变得更加多种多样,改变后的图片放入神经网络进行训练可以提高网络的鲁棒性,降低各方面额外因素对识别的影响.
目标检测中的图像增强:
在目标检测中如果要增强数据,并不是直接增强图片就好了,还要考虑到图片扭曲后框的位置。也就是框的位置要跟着图片的位置进行改变。
"""
def rand(a=0, b=1): # 生成一个取值范围为[a,b)的随机数
return np.random.rand() * (b - a) + a
# get_random_data数据增强
def get_random_data(annotation_line, input_shape, random=True, max_boxes=20, jitter=.5, hue=.1, sat=1.5, val=1.5, proc_img=True):
"""
实时数据增强的随机预处理
random preprocessing for real-time data augmentation
:param annotation_line: 数据集中的某一行对应的图片
:param input_shape: yolo网络输入图片的大小416*416
:param random:
:param max_boxes:
:param jitter:控制图片的宽高的扭曲比率,jitter=.5表示在0.5到1.5之间进行扭曲
:param hue: 代表hsv色域中三个通道中的色调进行扭曲,色调(H)=.1
:param sat: 代表hsv色域中三个通道中的饱和度进行扭曲,饱和度(S)=1.5
:param val: 代表hsv色域中三个通道中的明度进行扭曲,明度(V)=1.5
:param proc_img:
:return:
"""
line = annotation_line.split()
image = Image.open(line[0])
iw, ih = image.size # 原图片大小
h, w = input_shape # 模型输入图片的大小
box = np.array([np.array(list(map(int, box.split(',')))) for box in line[1:]]) # 对该行的图片中的目标框进行一个划分
# 对图像进行缩放并且进行长和宽的扭曲
# 扭曲后的图片大小可能会大于416*416的大小,但是在加灰条的时候会修正为416*416
new_ar = w/h * rand(1-jitter, 1+jitter)/rand(1-jitter, 1+jitter) # 表原图片的宽高的扭曲比率,jitter=0,则原图的宽高的比率不变,否则对图片的宽和高进行一定的扭曲
scale = rand(.25, 2) # scale控制对原图片的缩放比率,rand(.25, 2)表示在0.25到2之间缩放,图片可能会放大可能会缩小,rand(.25, 1)会把原始的图片进行缩小,图片的边缘加上灰条,可以训练网络对我们小目标的检测能力。rand(1,2)则是一定放大图像
if new_ar < 1:
nh = int(scale * h)
nw = int(nh * new_ar)
else:
nw = int(scale * w)
nh = int(nw / new_ar)
image = image.resize((nw, nh), Image.BICUBIC)
# print(nw,nh) # 扭曲后的图片的宽和高
# 将图像多余的部分加上灰条,一定保证图片的大小为w,h = 416,416
dx = int(rand(0, w - nw))
dy = int(rand(0, h - nh))
new_image = Image.new('RGB', (w, h), (128, 128, 128)) # (128, 128, 128)代表灰色
new_image.paste(image, (dx, dy))
image = new_image
# 是否翻转图像
flip = rand() < .5 # 有50%的几率发生翻转
if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT) # 左右翻转
# 色域扭曲
# 色域扭曲是发生在这个hsv这样的色域上,hsv色域是有色调H、饱和度S、明度V三者控制,调整这3个值调整色域扭曲的比率
hue = rand(-hue, hue)
sat = rand(1, sat) if rand()<.5 else 1/rand(1, sat)
val = rand(1, val) if rand()<.5 else 1/rand(1, val)
x = rgb_to_hsv(np.array(image) / 255.) # 将图片从RGB图像调整到hsv色域上之后,再对其色域进行扭曲
x[..., 0] += hue
x[..., 0][x[..., 0] > 1] -= 1
x[..., 0][x[..., 0] < 0] += 1
x[..., 1] *= sat
x[..., 2] *= val
x[x > 1] = 1
x[x < 0] = 0
image_data = hsv_to_rgb(x) # numpy array, 0 to 1
# 将box进行调整
# 对原图片进项扭曲后,也要对原图片中的框框也进行相应的调整
box_data = np.zeros((max_boxes, 5))
if len(box) > 0:
np.random.shuffle(box)
# 扭曲调整
box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx
box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy
# 旋转调整
if flip: box[:, [0, 2]] = w - box[:, [2, 0]]
# 因为调整后不再图像中的目标框的调整
box[:, 0:2][box[:, 0:2] < 0] = 0
box[:, 2][box[:, 2] > w] = w
box[:, 3][box[:, 3] > h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w > 1, box_h > 1)] # discard invalid box
if len(box) > max_boxes: box = box[:max_boxes]
box_data[:len(box)] = box
return image_data, box_data
# 原图片绘制展示
def normal_(annotation_line, input_shape):
"""
random preprocessing for real-time data augmentation
:param annotation_line: 选取的数据集第a行所对应的图片进行数据增强
:param input_shape: 输入的大小
:return:
"""
line = annotation_line.split() # 以空格进行分割
# 获取该行对应的图片
image = Image.open(line[0])
# 获取该图片上的每一个目标框
box = np.array([np.array(list(map(int, box.split(',')))) for box in line[1:]])
return image, box
if __name__ == "__main__":
with open("2007_train.txt") as f:
lines = f.readlines()
a = np.random.randint(0, len(lines))
line = lines[a] # 选取的数据集第a行所对应的图片进行数据增强
image_data, box_data = normal_(line, [416, 416])
img = image_data
# 原图片绘制展示
#数据集的第a行图片的展现
for j in range(len(box_data)):
thickness = 3
left, top, right, bottom = box_data[j][0:4]
draw = ImageDraw.Draw(img)
for i in range(thickness):
draw.rectangle([left + i, top + i, right - i, bottom - i], outline=(255, 255, 255))
img.show()
#对图片进行数据增强后的展示
image_data, box_data = get_random_data(line, [416, 416])
print(box_data)
img = Image.fromarray((image_data * 255).astype(np.uint8))
for j in range(len(box_data)):
thickness = 3
left, top, right, bottom = box_data[j][0:4]
#创建绘制对象
draw = ImageDraw.Draw(img)
for i in range(thickness):
draw.rectangle([left + i, top + i, right - i, bottom - i], outline=(255, 255, 255))
img.show()
# img = Image.open(r"F:\Collection\yolo_Collection\keras-yolo3-master\Mobile-yolo3-master/VOCdevkit/VOC2007/JPEGImages/00000.jpg")
# left, top, right, bottom = 527,377,555,404
# draw = ImageDraw.Draw(img)
# draw.rectangle([left, top, right, bottom])
# img.show()
场景三:DropBlock正则化方法
论文地址
论文翻译
正则化方法之DropBlock
新的正则化神器:DropBlock(Tensorflow实践)



场景四: CIoU Loss损失函数
参考博文博主
浅谈目标检测中常规的回归loss计算


1.1 SmoothL1 Loss
Fast R-CNN论文地址

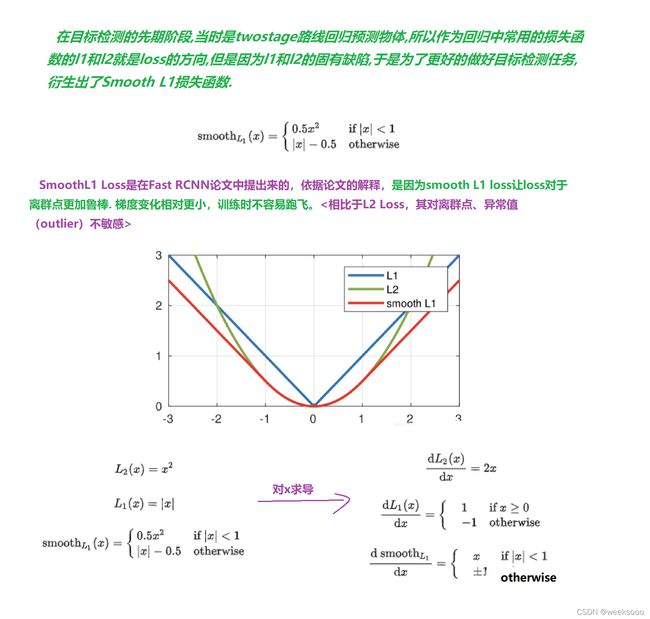


1.2 Iou Loss (2016)
论文地址

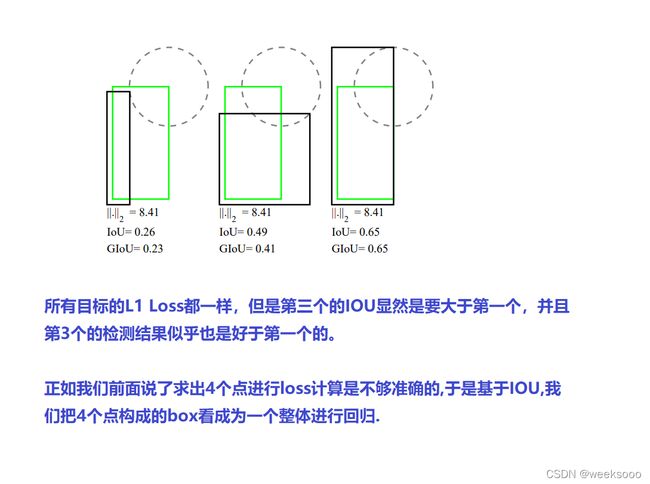


1.3 GIou Loss(2019)
论文地址
开源代码


1.4 DIou Loss 和 CIou Loss(2020)
论文地址
DIou开源代码
CIou开源代码




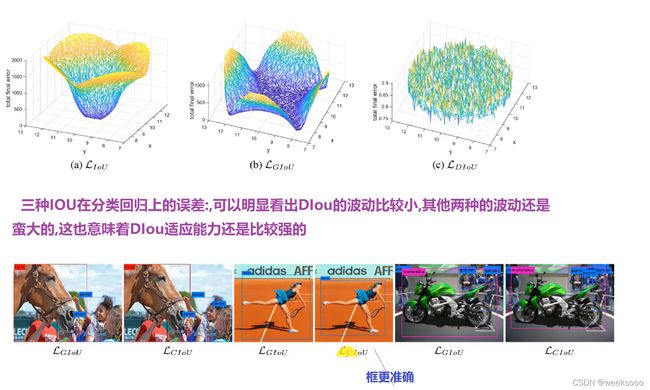

…
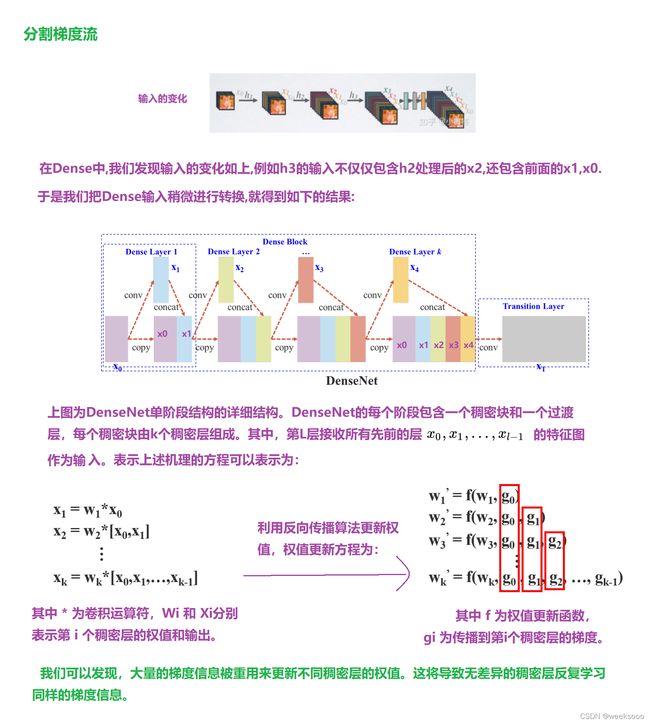
场景五: CSPNet (2019)
CSPNet 论文地址
先导知识DenseNet----场景十:新增模型DenseNet
深度学习_经典网络_CSPNet网络详解
【CSPNet 解读】一种增强CNN学习能力的新型骨干网络










场景六: FPN (多尺度特征融合手段)
论文地址 : Feature Pyramid Networks for Object Detectio
FPN网络
FPN全解-最全最详细




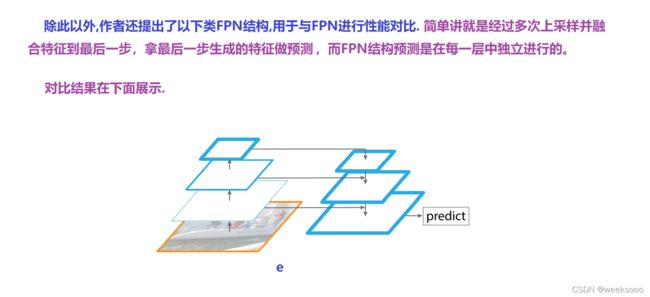
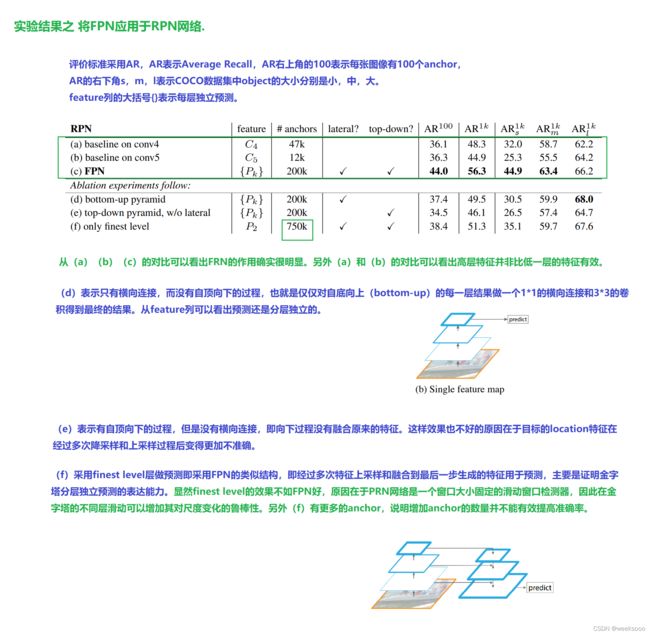

场景七:PANet (对FPN的增强)
论文地址: Path Aggregation Network for Instance Segmentation
【实例分割】PANet简单笔记

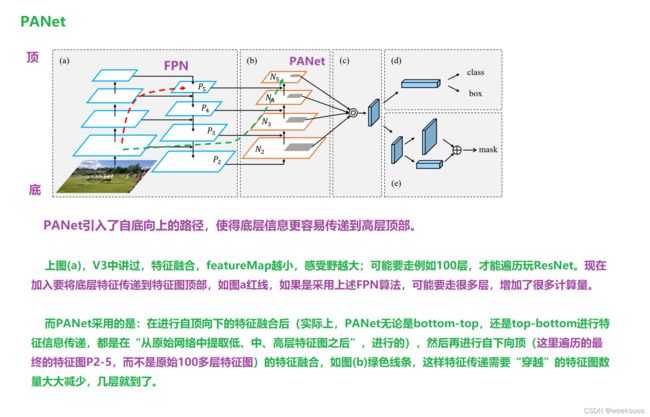

场景八: DIOU NMS (目标检测后处理手段)
Soft NMS 论文地址
DIOU NMS论文地址
YOLOv4的Tricks解读三— 目标检测后处理(Soft-NMS/DIoU-NMS)




代码实现参考地址
you did it
