【王道】计算机组成原理第一章计算机系统概述(一)
✍、【王道】计算机组成原理第一章
计组第一章
- ✍、【王道】计算机组成原理第一章
- 1、计算机组成原理
-
- 1.0、计算机硬件识别数据
- 1.1、计算机硬件的基本组成
-
- 1.1.1、早期冯诺依曼机
- 1.1.2、现代计算机的结构
- 1.1.3、小结
- 1.2、各个硬件的工作原理
-
- 1.2.1、主存储器的基本组成
- 1.2.2、运算器的基本组成
- 1.2.3、控制器的基本组成
- 1.2.4、计算机的工作过程
- 1.2.5、小结
- 1.3、计算机系统的多级层次结构
-
- 1.3.1、三种级别的语言
- 1.3.2、小结
- 1.4、计算机的性能指标
-
- 1.4.1、存储器的性能指标
- 1.4.2、CPU的性能指标
- 1.4.3、系统整体的性能指标
- 1.4.4、系统整体的性能指标(动态测试)
- 1.4.5、总结
1、计算机组成原理
计算机的最底层是由一些硬件组成,在硬件之上我们会架设操作系统,在操作系统之上我们再安装一些应用软件,这样我们就得到一个计算机了。通过计算机网络又实现了计算机之间的互联互通。计组这门课研究的就是计算机硬件在底层是怎么相互协调工作的。

1.0、计算机硬件识别数据
计算机硬件唯一能识别的数据就是二进制0/1,那计算机硬件是怎么来区分二进制数呢?
答案:用低电平表示二进制0,用高电平表示二进制1。所以在计算机硬件传递数据就是通过电信号来传递的,我们可以将电信号划分为高低电平两种信号,从而硬件就可以识别数据了。传递二进制数据本质上就是在传递二进制数位,每个二进制数位称为1bit(比特)。
1.1、计算机硬件的基本组成
计算机系统 = 硬件+软件
- 硬件:主机、鼠标、键盘
- 软件:微信、QQ

1.1.1、早期冯诺依曼机
存储程序的概念是指将指令以二进制代码的形式事先输入计算机的主存储器(内存),然后按其在存储器中的首地址执行程序的第一条指令,以后就按该程序的规定顺序执行其他指令,直至程序执行结束。
如下图,我们使用实线表示数据线,也就是说数据可以跟着实线箭头的流动方向来相互的传输。
虚线表示控制线和反馈线。
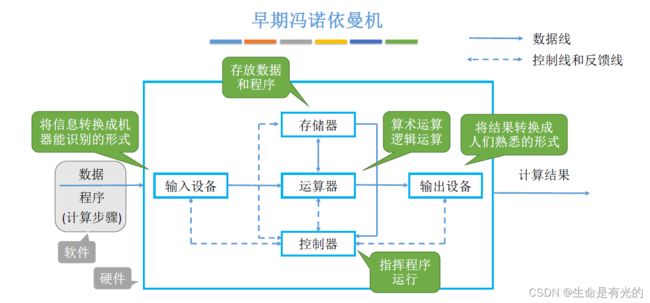
我们的计算机就是用来处理数据的,
- 所以要处理数据首先要有一个输入设备,把数据输入到计算机当中,这里的数据包含我们要进行数学运算的数据,也包含程序,也就是指令集合。
- 这些数据输入之后是先流向了运算器,运算器实现算术运算(加减乘除)和逻辑运算(与或非),然后才会把这些程序数据放到存储器(内存)当中,所以存储器就是用来存储数据和程序指令的。
- 经过运算器运算之后,数据会流向输出设备,输出设备将结果转换成人们熟悉的形式展示。
- 控制器会协调其他硬件相互配合的工作,另外控制器也会负责解析存储器中存储的程序指令。例如控制器从存储器中读取的是加法指令,控制器解析之后会指挥运算器执行相应的加法操作。所以程序指令的解析是由控制器来完成的,因此控制器的作用就是用来指挥程序有条不紊的运行的。
我们输入计算机的数据和程序其实就是软件模块,输入设备、运算器、存储器、控制器和输出设备就是计算机的硬件模块,在计算机系统中,软件和硬件在逻辑上是等效的,也就是说同一个功能,我们既可以用软件来实现,也可以用硬件来实现。
-
输入设备作用:将信息转换成机器能识别的形式
-
存储器:存放数据和程序
-
运算器:算术运算和逻辑运算
-
控制器:指挥程序运行
-
输出设备:将结果转换成人们熟悉的形式
在计算机系统中,软件和硬件在逻辑上是等效的。
也就是说,对于任一一种运算,我们可以在软件上实现,也可以在硬件上实现。例如:对于乘法运算,可以设计一个专门的硬件电路实现乘法运算也可以用软件的方式,执行多次加法运算来实现。
冯诺依曼计算机的特点:
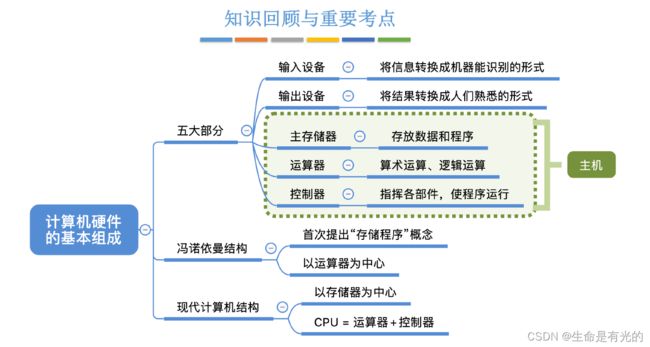
- 计算机由五大部件组成。其中输入设备和输出设备,我们可以统称为I/O设备。
- 指令和数据以同等地位(都是以二进制)存于存储器,可按地址寻访
- 指令和数据用二进制表示
- 指令由操作码和地址码组成。操作码就是指明了这条指令执行的是什么操作,地址码指明了我们要操作的数据存放在内存中的什么地址当中。
- 存储程序:也就是会提前把指令和数据存储到存储器当中。
- 冯·诺依曼计算机是以以运算器为中心(不论是输入设备输入数据还是输出是设备输出数据,都需要运算器作为中转站,虽然我们的本意是想将数据放入存储器中,但是冯·诺依曼计算机就是需要经过运算器才行,所以我们说冯·诺依曼计算机是以以运算器为中心)
这就产生了一个问题,我们的运算器本来是用来对数据进行运算的,但是现在所有的数据中转还需要通过运算器,这样会导致数据计算的效率降低。
1.1.2、现代计算机的结构
冯·诺依曼计算机是以以运算器为中心,现代计算机以存储器为中心。也就是说输入设备输入的是数据是直接放到存储器里面的,当运算器处理完这些数据之后,输出设备也会直接从存储器当中取走数据进行输出。这样就可以解放运算器,让运算器进行更多的运算。

在如今的计算机硬件上,都会将运算器和控制器放在一块,也就是我们说的CPU => CPU = 运算器+控制器,结构框图简化如下:

CPU里面包含了控制器和运算器,控制器通过控制线来告诉运算器执行什么运算,控制器也会控制主存储器的读写和输入输出设备的启动和停止,主存储器和CPU之间会进行数据的交换(上方实线),数据在运算器运算后进行交换,指令在控制器解析后进行交换,主存储器也会和输入输出设备直接和进行数据的交换。
- 主存储器和CPU统称为主机
- 我们生活中所说的主机还包括风扇、硬盘等等,但是在计组中主机 = 主存储器+CPU
主存就是主存储器,相当于手机的运行内存,辅存就是辅助存储器,相当于手机的存储空间。
- 主机只包含主存,不包含辅存,辅存归为I/O设备。例如我们平常手机里的app,不启动的时候都放在辅存里面,只有启动运行的时候,才会将程序放入主存里面。所以辅存我们将其看为输入输出设备。
1.1.3、小结
1.2、各个硬件的工作原理

1.2.1、主存储器的基本组成

主存储器用于存放数据的东西叫做存储体,存储体可以存放二进制0/1,此外主存储器还包括MAR存储地址寄存器和MDR存储数据寄存器,分别是存储地址的二进制和存储数据的二进制。
菜鸟驿站的货架是用来存放货物的,主存储器里面的存储体是用来存放数据的。
-
"我"将取件号告诉店员,同时取件号也反映出了我的货物在货架上的存放位置。之后我的货物会被放到柜台上,最终"我"是从柜台上取走包裹的。
-
对于主存储器来说,CPU会将想要取的数据的位置写到MAR寄存器当中,主存储器就可以根据MAR的地址去存储体里面拿出数据,并把数据写到MDR寄存器当中,最后CPU就可以取走数据。

数据在存储体内按地址存储,每个地址对应一个存储单元,每个存储单元会存放一串二进制代码,每一个存储单元中存储的二进制代码的组合称为存储字,每个存储字包含多少个二进制位我们称为存储字长。每个存储单元会对应一个地址信息,地址是从0开始的。这个地址信息就是MAR寄存器里面指明的地址信息。如果我要读取2号地址的存储单元,那么CPU会向MAR寄存器写入2号地址信息。
-
用于存储二进制数的电子原件叫做存储元,每个存储元可存1bit。
-
通常每个存储单元存储的二进制数都是 8bit 的整数倍。
MAR是指明了我当前要访问哪一个存储单元的地址,所以MAR寄存器的位数反映存储单元的个数。
我们从存储体中取出的数据是要放到MDR中的,所以MDR它的二进制位数应该和存储单元是一致的,也就是 MDR位数 = 存储字长。
例如:
- 一个主存储器的MAR寄存器只有4bit位,那么也就意味着它的存储体里面总共只有24个存储单元。(因为4个二进制位,最多也就只能表示24个存储单元)
- 一个主存储器的MDR寄存器共有16bit位,那么就说明这个主存储器一个字的大小就是16bit,也就是每一个存储单元可以存放16个二进制位,16个bit的信息。
容易混淆:
1个字节(byte)=8bit,1B=1个字节,1b=1个bit。
我们在描述一个字节的时候,经常会用1B来表示。当我们在描述一个二进制位的时候,一般是用1b来表示。
字节是固定单位,8个比特。字是代表一个存储单元的大小,根据存储器的不同而不同。
例如我们办100Mbps的宽带(这里是小写的b),当我们下载东西时,会显示10MB/s左右,这是为什么呢?
答:其实并不是运营商骗了你,而是下载东西时会以字节B显示,1B=8bit,所以 100Mbps/8bit ≈ 10MB/s 是我们理论的最大下载速度。
1.2.2、运算器的基本组成
运算器:用于实现算术运算(如:加减乘除)、逻辑运算(如:与或非)

| 运算器组成 | 说明 |
|---|---|
| ACC(Accumulator) | 累加器,用于存放操作数,或运算结果 |
| MQ(Multiple-Quotient Register) | 乘商寄存器,在乘、除运算时,用于存放操作数或运算结果 |
| X | 通用的操作数寄存器,用于存放操作数 |
| ALU | 算术逻辑单元,通过内部复杂的电路实现算数运算、逻辑运算 |
1.2.3、控制器的基本组成
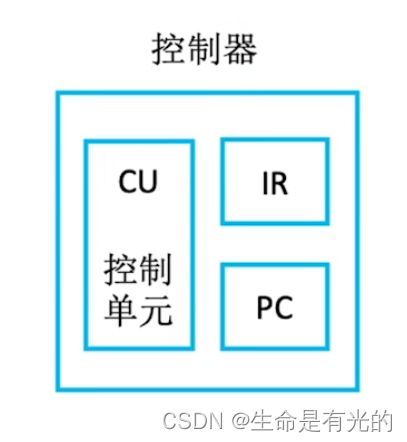
| 控制器 | 组成说明 |
|---|---|
| CU | Control Unit,控制单元,分析指令,给出控制信号 |
| IR | Instruction Register,指令寄存器,存放当前执行的指令 |
| PC | Program Counter,程序计数器,存放下一条指令地址,有自动加1的功能 |

代码其实就是一条一条的指令,每完成一条指令需要分为三个阶段:
- 根据PC程序计数器里面存放的指令地址从内存中取出那一条指令
- 取出的指令会被放在IR指令寄存器当中
- 之后CU控制单元进行执行指令
很多地方也会把取指令分析指令称为取指,将第三个执行指令称为执行
1.2.4、计算机的工作过程
我们来看我们的高级语言是怎么来被计算机解析的:
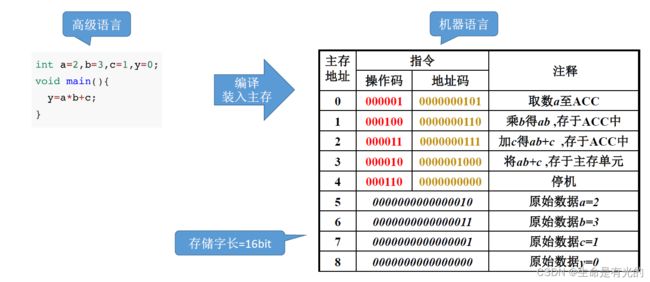

让我们静下心来仔细分析上述图进行理解计算机的工作过程:
首先指令和变量数据都是存放在存储体当中的,程序执行的首先是主存地址为0的指令
-
所以在程序运行前,(PC)=0,PC会指向第一条指令的存储地址
-
我们需要将第一条指令取出来,PC存放的地址内容需要告诉MAR寄存器,所以 (PC) -> MAR,因为(PC)=0,所以导致(MAR)=0
-
主存储器根据地址信息会让MAR去存储体取出这条指令并放入MDR中,M(MAR) -> MDR,导致(MDR) = 0000001 0000000101
-
MDR会通过数据线将其传入IR指令寄存器中,(MDR) -> IR,导致 (IR)=0000001 0000000101
-
IR指令寄存器会将指令的操作码传入CU控制单元去分析指令,将地址码传入MAR寄存器中让其从存储体取数据
- OP(IR) -> CU,指令的操作码送到CU,CU分析后得知,这是"取数"指令。
- Ad(IR) -> MAR,指令的地址码送到MAR,导致(MAR)=5,5号存储地址刚好对应就是a=2,主存储器根据MAR指明的地址去存储体当中取出5号地址的数据,也就是a=2,之后将a=2放入MDR当中
-
(MDR)->ACC,MDR的数据会被存入ACC累加寄存器当中,导致(ACC)=0000000000000010=2
(MAR)带括号表示MAR里面的内容。(给寄存器打括号,表示这个寄存器里面的内容)
M(MDR)表示主存储器M里面MDR里面的内容
上一条指令取指后PC自动+1,所以(PC)=1,执行下一个取指令操作。取指令的步骤都一样,之后分析指令,然后不同的指令传到不同的寄存器,CPU区分指令和数据的依据:指令周期的不同阶段。
上图中取指令是1-4步,分析指令是第5步,执行取数指令是6-9步。
1.2.5、小结

- 存储体里面的概念都是选择题高频考点
- MAR和MDR逻辑上是属于主存的,但是现在的计算机通常把MAR、MDR也集成在CPU内,所以把MAR、MDR画在CPU内也正确。
1.3、计算机系统的多级层次结构

传统机器只能识别机器语言,机器语言就是用二进制表示的机器指令,CPU在执行这些机器指令的时候还需要将这些机器指令细分为更细的微指令来执行。之后出现了用汇编语言来编程的虚拟机器,对于使用汇编语言的程序员来说,他所看到的机器似乎是可以直接识别汇编语言程序的(所以叫虚拟机器),其实还是机器将汇编程序翻译成机器语言程序来执行。最后出现了高级语言机器,看起来好像我们编写的高级语言机器能直接识别一样(所以依旧称为虚拟机器),其实本质还是用编译程序翻译成汇编语言程序,再经过翻译得到机器语言。
我们所编写的程序会用到操作系统所提供的服务,所以一般用汇编语言编写的程序同样需要请求操作系统的服务,通过系统调用的方式来请求,系统调用又可以称为广义指令。
操作系统机器、汇编语言机器和高级语言机器都属于软件,而机器语言机器和微指令系统是属于硬件部分,这个部分就是计组所研究的。
对于这个层次结构来说,下层是上层的基础,上层是下层的扩展。
1.3.1、三种级别的语言
高级语言通常有下列三种方式进行翻译成机器语言程序:
-
高级语言(C、C++、Java)源程序 -> 编译程序(编译器) -> 汇编语言 -> 汇编程序(汇编器) -> 二进制代码(机器语言程序)
-
高级语言(C、C++、Java)源程序 -> 解释程序(解释器) -> 二进制代码(机器语言程序)
-
高级语言(C、C++、Java)源程序 -> 编译程序(编译器) -> 二进制代码(机器语言程序)
编译程序:将高级语言编写的源程序全部语句一次全部翻译成机器语言程序,而后再执行机器语言程序(只需翻译一次)
解释程序:将源程序的一条语句翻译成对应于机器语言的语句,并立即执行。紧接着再翻译下一句(每次执行都要翻译)
C、C++一般是由编译器进行编译,会一次性将所有源程序翻译成机器语言;Python、JavaScript这些脚本语言一般是由解释器进行解释程序,是一句一句进行翻译成机器语言,所以C、C++的效率速度更快,而Python、JavaScript效率速度较慢。
注:编译、汇编、解释程序,可统称为"翻译程序"
1.3.2、小结

1.4、计算机的性能指标
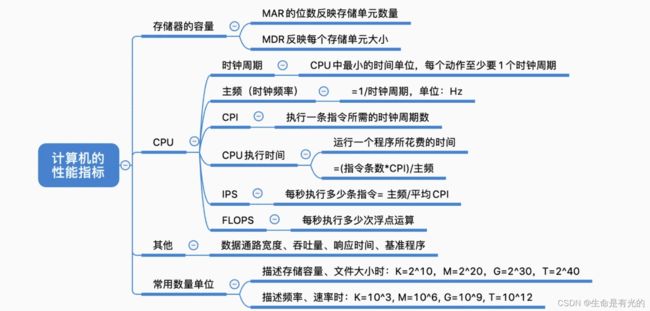
1.4.1、存储器的性能指标

MAR的位数可以反映出这个存储体里面总共有多少个存储单元,而MDR的位数可以反映出每一个存储单元可以存放多少个二进制比特位,所以只需要这两个信息就可以算出存储器的总容量(总共可以存多少个二进制比特位),如果把比特/8 就可以转换为字节Byte 。
所以存储体的总容量为:
总 容 量 = 存 储 单 元 个 数 × 存 储 字 长 b i t = 存 储 单 元 个 数 × 存 储 字 长 / 8 B y t e 总容量 = 存储单元个数×存储字长 bit \\ = 存储单元个数×存储字长/8 Byte 总容量=存储单元个数×存储字长bit=存储单元个数×存储字长/8Byte
例如 MAR有32位,那么它最多可以存储 232个二进制数,也就是这么多个地址,每个地址对应一个存储单元,所以总共有232个存储单元, MDR有8位,也就是每个存储单元的大小为8bit,所以总容量二者相乘即可。
为什么32位就可以表示232个地址呢?n个二进制位可以表示出多少种不同的状态?
- 32位 就是 32个二进制位
| n进制 | 状态 | 规律 |
|---|---|---|
| 1个二进制位 | 0,1 | 21 |
| 2个二进制位 | 00,01,10,11 | 22 |
| 3个二进制位 | 000,001,010,011,100,101,110,111 | 23 |
| n个二进制位 | 2n |
单位换算:
- 1kb = 210B = 1024B
- 1Mb = 220B
- 1GB = 230B
- 1TB = 240B
1.4.2、CPU的性能指标

例如我们在买电脑看CPU时,它往往会在选项中显示 3.6GHz、2.9GHz等,这其实就是CPU的主频,也就是CPU内数字脉冲信号振荡的频率。如图中的信号频率图,每一个波峰就代表一个数字脉冲信号。所以CPU的数字脉冲信号是有规律、有节奏的发生的。有点像跳广播体操时体委每喊一个口号,你每做一个动作。
- 我们把每个脉冲信号的时间称为CPU的时钟周期,单位为微妙、纳秒
- CPU的主频(也称为时钟频率),和CPU的时钟周期是互为倒数关系,主频的单位是赫兹、Hz
- 例如 主频 = 10Hz,代表每秒中有10个脉冲信号 10Hz = 10个脉冲信号/s
一般主频越高,CPU的执行速度会越快,但除此之外还有其他因素影响CPU的性能,例如:
- CPI(Clock cycle Per Instruction):每一条指令需要的时钟周期的数量。不同的指令CPI不同,甚至相同的指令CPI也可能不同。所以我们一般都考虑平均情况,例如我们知道CPI的平均数量,则执行一条指令耗时如下:
- 所以执行一条指令耗时 = CPI × CPU时钟周期
来看一个例题:某CPU主频为1000Hz,某程序包含100条指令,平均来看指令的CPI=3,该程序在CPU上执行需要多久?
- 这个程序有100条指令,每个指令平均需要3个时钟周期,一个时钟周期的长度是主频的倒数
$$
CPU执行时间(整个程序的耗时) = \frac{指令条数*CPI}{主频} \
T = 100×3× \frac{1}{1000} = 0.3s
$$
- IPS(Instructions Per Second) :每秒执行多少条指令
I P S = 主 频 平 均 C P I IPS = \frac{主频}{平均CPI} IPS=平均CPI主频
主频反映的是每秒中会出现多少个时钟周期,CPI反映的是执行一条指令所需要的时钟周期。
- FLOPS(Floating-point Operations Per Second):每秒执行多少次浮点运算
我们在使用 IPS 和 FLOPS 时都会在其前面加上单位,例如KIPS、MIPS、KFLOPS、MFLOPS、GFLOPS、TFLOPS
- 此处的K、M、G、T为数量单位
- K = Kilo = 千 = 103
- M = Millon = 百万 = 106
- G = Giga = 十亿 = 109
- T = Tera = 万亿 = 1012
- 2MIPS:这台计算机平均每秒可以执行两百万条指令
这里注意:
- 我们在描述文件大小时的K、M、G、T,表示的是容量大小 210 、220、230、240
- 我们在描述处理速率的K、M、G、T,表示的是 103、106、109、1012
- 例如CPU主频是3GHz:这里的G表示的是109
1.4.3、系统整体的性能指标
数据通路带宽:数据总线一次所能并行传送信息的位数(各硬件部件通过数据总线传输数据)。例如CPU和内存、内存和I/O设备,他们之间的信息传输都是通过数据总线传输数据的,
吞吐量:指的是系统在单位时间内处理请求的数量。例如服务器会处理一条条HTTP请求,这些请求在单位时间内的数量我们就可以说是吞吐量。吞吐量取决于信息能多快地输入内存,CPU能多快的取指令,数据能多快地从内存取出或存入,以及所得结果能多快地从内存送给一台外部设备。这些步骤中的每一步都关系到主存,因此,系统吞吐量主要取决于主存的存取周期。
响应时间:指的是从用户向计算机发送一个请求,到系统对该请求做出响应并获得它所需要的结果的等待时间。
1.4.4、系统整体的性能指标(动态测试)
上述静态测试很难反映一个系统整体的性能指标,我们通常会使用基准程序来测量计算机的处理速度。
其实就是跑分软件 -> 例如鲁大师

问1:CPUB一秒可以跑1G指令,而CPUA一秒只能跑0.2G指令
1.4.5、总结