【深度学习】李宏毅深度学习2022
文章目录
- 机器学习基本概念介绍
-
- 分类与回归
- 训练攻略
- 网络训练一些细节
-
- critical point
- batch
- 优化器和learning rate
- 引出DL角度1
- 引出DL角度2
- 卷积神经网络CNN
-
- CNN引入角度1(本质的角度)
- CNN引入角度2(应用的角度)
- Spatial Transformer Layer
- self-attention
-
- 问题引入
- 原理
- 变体
-
- 角度1:减少attention score的计算开销
- 其余角度
- 应用
- RNN
-
- simple 版本
- long short-term memory(LSTM)
- RNN的训练
- RNN的应用
- Deep learning和structured learning
- graph neural network(GNN)
-
- 概述
- convolution and spatial-based GNN
- spatial-based GNN的真实模型
- graph signal processing and spectral-based GNN
- spectral-based GNN 真实模型
- transformer
-
- 概述
- encoder
- decoder
- encoder与decoder的连接
- 训练
- 训练sequence2sequence的tip
- NAT
- GAN
-
- 概述
- Unconditional generation
- GAN的理论
- GAN的评估
- Conditional Generation
- GAN与无监督学习
- 自监督学习
-
- 概述
- BERT
- GPT
- 番外篇
-
- 训练的tip
- word embedding
- Pointer Network
- domain adaptation
学习视频: https://www.bilibili.com/video/BV1Wv411h7kN 52开始选修不上了,倦了。
机器学习基本概念介绍
机器学习的任务:回归、分类、结构化学习
本质:就是找到一个函数关系,去完成我们的任务
过程:设计一个带未知有参数的函数(运用领域知识)、设计损失函数、参数优化
分类与回归
回归:模型预测一个数值,希望这个数值和label尽可能地接近。
回归问题的损失函数:MSE,也就是均方差损失函数, e = e= e= 1 n {1}\over{n} n1 Σ ( y ^ − y ) 2 \Sigma(\hat{y}-y)^2 Σ(y^−y)2
分类:思路1:可以用回归的思路来做,也就是同样输出一个数值,看他接近哪个数字,接近1就是类别1,接近2就是类别2以此类推。但是会有一些问题:这样的话,就是假设类别之间有一些关系,如一年级和二年级比较接近,一年级和三年级距离比较远,但是很多时候的分类,如猫和狗,其实是没有什么直接关系的。
思路2:输出一个one hot向量,避免类与类之间的关系。模型得到的是一组任意的向量 [ y 1 , y 2 , y 3 ] [y_1,y_2,y_3] [y1,y2,y3],接着我们将他进行softmax,得到一组0-1之间的向量,希望它和onehot的label尽可能地接近。
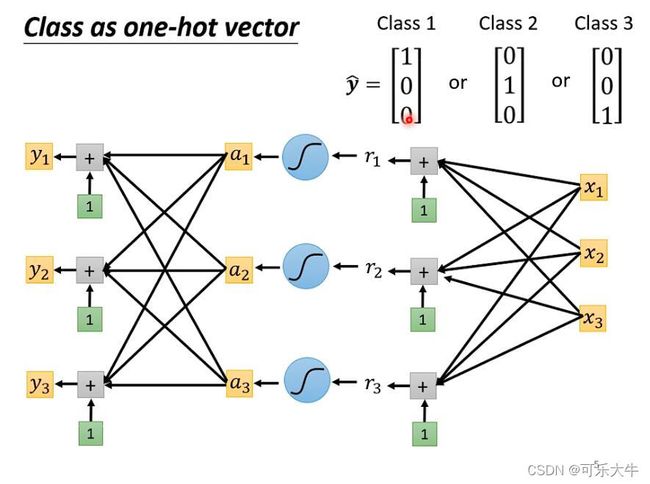
softmax的过程如下:(两个作用:1、归一化,2、会对最大值进行强化,因为取了指数)
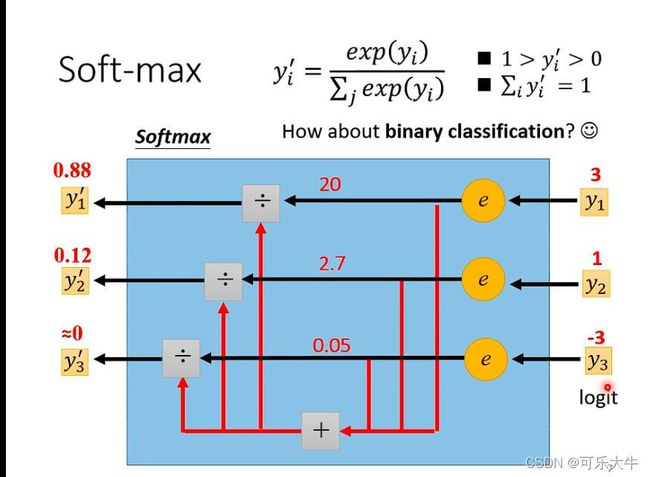
注:多分类就直接用softmax,但是二分类的话,softmax和sigmod效果是一样的了。并且,二分类问题的解决称为Logistic 回归,多分类问题的解决称为softmax回归,后者可以看成是前者的推广,并且处理分类问题的nn也主要就是他们两个。另外,当分类的时候类别互相排斥,直接用softmax回归来做(因为logistic回归就是特殊的softmax回归),若是分类的时候类别相互之间不排斥,应该两两之间使用logistic回归来做。
分类问题的损失函数:交叉熵损失函数 e = − Σ y i ^ l n y i e=-\Sigma\hat{y_i}lny_i e=−Σyi^lnyi,其中 y i ^ \hat{y_i} yi^是label这个onehot向量的分量, l n y i lny_i lnyi是模型最后输出的0-1之间的向量的分量
注:pytorch中使用交叉熵损失函数,就会自动在模型的最后加上一层soft-max,所以我们是不需要手动加的
训练攻略
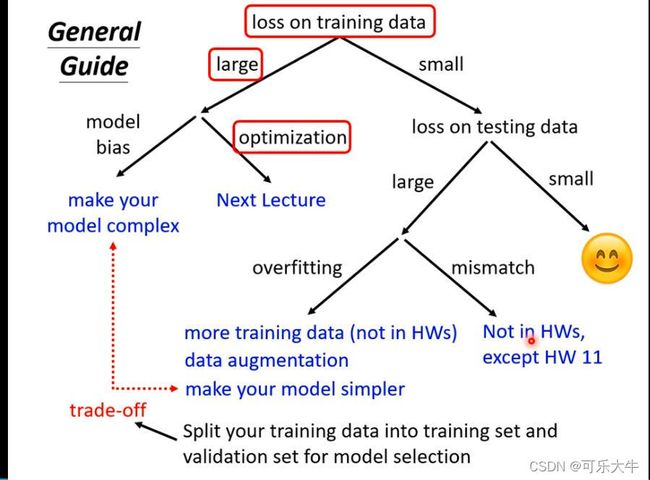
model bias:模型不够复杂,参数量不够大导致无法找到真正符合样本数据的function,因为function set太小了
model bias解决:增加更多的特征,或者使用DL的方法,增加层数
optimization:优化器选择的不好
optimization解决:换优化器
区分model bias和optimization:先在浅一点的网络上训练,再到深一点的网络上训练,如果loss下去了,那就是model bias,如果loss上去了,那就是optimization。
原因:因为深度上去之后,模型的弹性肯定大了,极端一点的情况就是后续的层中什么都不做,直接把前面的结果输出,得到的loss应该是一样的,但是loss还是上去了,说明没有优化好
overfitting:没有学习到真实数据的分布,而是对于测试数据的情况进行强行拟合。所以在训练数据上表现比较好,但是测试数据上表现糟糕
overfitting解决:1、增大训练数据集或者数据增广,想办法使得数据训练数据变多;2、给model一些限制,如减少参数量或者公用一些参数(CNN);更少的特征;早停;正则化;Dropout;注:但是限制不能太多,否则会就导致model bias
mismatch:训练数据和测试数据的分布不相同
网络训练一些细节
loss不再下降:原因1:到了critical point也就是微分为0的点,包括local minima和saddle point,但是其实大部分都是容易处理的saddle point,local minima的情况很少很少。原因2:学习率设置不当,导致震荡,loss不再下降,但是梯度肯定是有的。
critical point
local minima的好坏:虽然都是local minima但是也有好坏,附近平滑的local minima是好的,陡峭的local minima是坏的。原因在于,训练数据的分布和测试数据的部分都是从全部数据中采样的,他们分布大致相同,但是总会有点偏差,也就是预测结果与标签之间会有偏差,这个偏差在陡峭的情况下影响很大,平缓的时候影响相对较小。
泪目了:以前求多元函数极值的方法,首先一阶导是0,然后看二阶导的情况,其实就是看Hessian矩阵,若他是正定的,那么就是一个局部极小值,如果是负定矩阵,则临界点处是一个局部极大值,如果是不定矩阵,则临界点就是saddle point
卡在saddle point的解决:我们可以沿着Hessian矩阵的特征向量方向走,就可以继续更新参数了。注:但是我们一般不会这么做,还有其他更好的办法
batch
batch:深度学习中,一般是将数据分成若干个batch,每个batch进行一次损失计算,得到梯度,根据梯度更新参数,新的参数作为下一个batch的初始参数。每次更新参数称为update,也就是有几个batch。对于所有batch的数据都进行一次更新的过程叫做一个epoch。而每个epoch中batch中的数据都是不一样的,因为会有shuffle的存在
batch-size:一个batch内部的数据个数。batch-size过大(极限情况就是数据数N),也就是只有一个batch。batch-szie过小(极限情况就是1),也就是总共用N个batch。
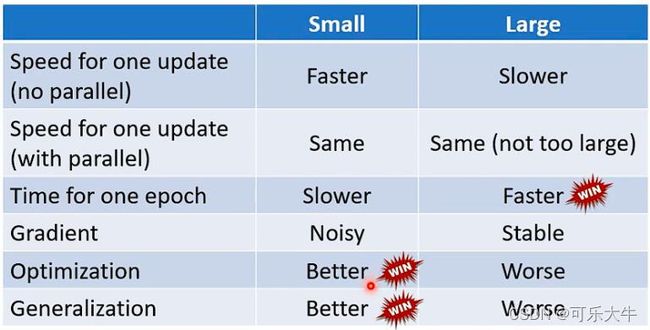
两者的比较:一方面,从每个batch的时间上看,随着batch-szie的增大,每个batch计算损失,然后更新参数的时间会变大,而且是线性关系的,但是其实在batch-size没有非常非常大的时候,效果差不多,主要原因在于GPU资源。;另一方面,从每个epoch的时间上看,随着batch-szie的增大,batch的数量减小,那么update的次数也就变小了,update的时间也就变小了;再者,随着batch-size增大,噪声会减小,但是训练集的准确率会下降,测试集的准确率也会下降的趋势。也就说其实是小的batch-szie有利于训练和测试。这是由于发生了optimization的问题。对于训练有用的解释是,batch-size过大,那么batch就很小,也就是update的次数少了,容易陷入critical point,但是batch-size小了,那么batch就很多,也就是update的次数就多了,容易逃离critical point,到达全局最优。
总结:
Momentum+Gradient descent:可以处理critical point的问题,核心思路就是以前是往梯度反方向走,现在是梯度反方向合成前一步移动的方向
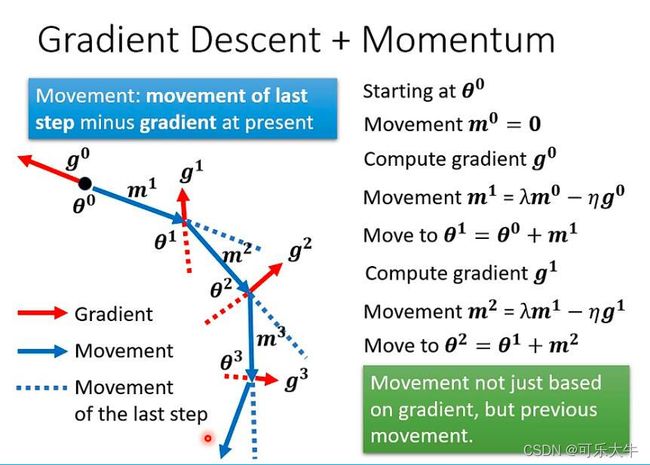
优化器和learning rate
优化器:原来优化器就是梯度下降中学习率的调整策略
常见的优化器:SGD,SGDM,Adagrad,RMSProp,Adam
学习率设置不当,导致震荡,loss不再下降,但是梯度肯定是有的,所以我们要自动调整学习率。
自动调整学习率原则:梯度大,很陡峭,则学习率要小一点,梯度小,很平缓,则学习率大一点
Off-line Optimization:离线优化,假设我们知道了所有的x和y。因为事实上我们每次只知道一个x和对应的y
On-line Optimization:在线优化,每次对一组x,y进行优化
SGD:随机梯度下降,就是每次只是根据一个数据计算梯度,然后沿着梯度反方向走
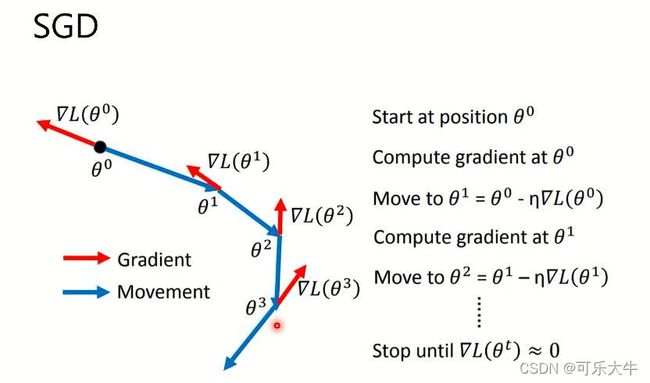
SGDM:再SGD的基础上加了Movement,会累加之前的梯度。所以SGDM陷入局部最小的概率会比SGD小,也就是优化效果会比SGD好

学习率调整-添加分母:
方法1:Adagrad优化器,引入学习率的分母, σ i t \sigma_i^t σit表示前面所有历史梯度的平均。很好,但是感觉还是不够智能。

方法2:RMSProp优化器。思路和Adagrad一致,但是添加了超参数 α \alpha α,使得学习率调整更加动态。

方法3:Adam就是SGDM+RMSProp,更加科学
用的最多的就是Adam和SGDM
Adam与SGDM的区别:Adam训练的会快一点,可能不收敛,不稳定,到测试的时候性能落差会比较大;SGDM训练的会慢一点,收敛性能好,稳定,到测试的时候性能落差会比较小;
Adam与SGDM的选择:CV包括图片分类、分割、目标检测;用的都是SGDM,NLP包括QA自动问答、机器翻译,摘要,用Adam比较多;语音合成、GAN、RL一般也都是用Adam
帮助优化过程:引入随意因子:Shufling,Dropout,Gradient noise;让模型更稳定:Warm-up,Curriculum learning,Fine-tuning;其他,Normalization,Regularization
学习率调整-变化:方法1:学习率衰减:顾名思义,就是学习率不断衰减;方法2:warm up,学习率先变大后变小,一个解释是说先让模型探索一下。
引出DL角度1
描述直线:可以用 y = w x + b y=wx+b y=wx+b
描述折线:可以用 y = ∑ i H a r d S i g m o i d ( w i x i + b i ) + b y=\sum_{i}Hard Sigmoid(w_ix_i+b_i)+b y=∑iHardSigmoid(wixi+bi)+b 也就是说可以用若干个Hard Sigmoid函数进行叠加再加上一个偏移得到折线。由下面知识可知,Hard Sigmoid可以由Sigmoid函数逼近,故用 y = ∑ i c i S i g m o i d ( w i x i + b i ) + b y=\sum_{i}c_iSigmoid(w_ix_i+b_i)+b y=∑iciSigmoid(wixi+bi)+b,将其改成向量表示: y = b + C T σ ( b ⃗ + W ⃗ x ) y=b+C^T\sigma(\vec b +\vec Wx) y=b+CTσ(b+Wx)
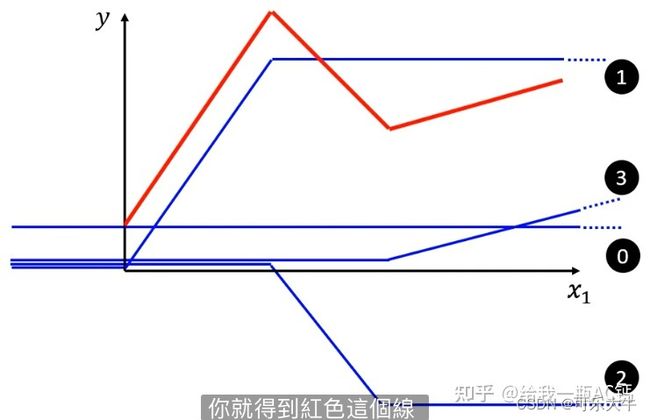
描述曲线:我们可以在曲线上任意取点,然后将曲线转换为折线。也就是说,取点足够多的话,我们就可以用若干个Hard Sigmoid函数的组合去逼近一条曲线
什么是Hard Sigmoid函数呢?
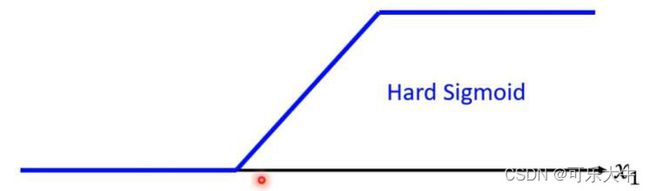
因为这个函数直接用数学语言描述会比较复杂,那怎么方便的描述这个Hard Sigmoid函数呢?
使用Sigmoid函数去逼近它!调整不同的w和b就可以得到不同的Sigmoid函数,也就可以逼近不同的Hard Sigmoid函数了。(当然使用ReLU可是可以的)
而什么是Sigmoid函数呢?就是 y = y= y= 1 1 + e ( − b + w x ) {1}\over{1+e_(-b+wx)} 1+e(−b+wx)1;什么是ReLU函数呢?就是 y = m a x ( 0 , b + w x ) y=max(0,b+wx) y=max(0,b+wx)关系 Sigmoid函数可以使用两个ReLU函数叠加得到

上面说的是若干了Sigmoid函数的叠加可以逼近任意复杂度的函数,但是另一个角度若是把Sigmoid函数的输出作为新的x进行套娃,就可以再套一层,这也可以逼近任意复杂度的函数。
而事实也证明参数量相同的情况下,更深的网络错误率会比更胖的网络低,之后的研究也都是用这种方法了,深度上去了之后,再叫神经网络就不好听了,那就叫深度学习了。
原因在于,表示同一个复杂的函数,深的模型会比胖的模型参数量更少,那么也就更不容易overfitting,需要更少的训练数据。而且对于那些复杂而又有规律的function,非常非常适合使用deep network去处理,比如图片、语音。
参数量:模型参数越多,那么就能包含更多的function,就能得到更好的适用于alldata的function,但是想要得到这个function,需要的训练数据也就越大。
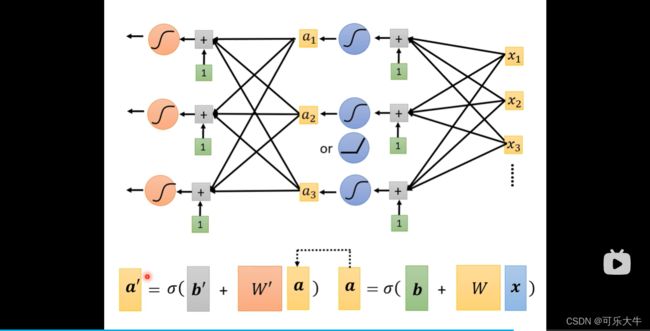
引出DL角度2
误差逆传播算法其实就是梯度下降算法的封装,也就是为了能够在DL模型大量的参数下更加有效使用梯度下降的方法:讲解14P,瞬间理解更加清晰了
正则化:在损失函数中加入一项表示参数规模的式子,如: τ Σ ( w i ) 2 \tau\Sigma(w_i)^2 τΣ(wi)2 也就是代表着参数越多,会使得损失值越大,从而抑制模型过于复杂,使得模型比较平滑,也就是对于输入的变化没有那么敏感。式子中只写了W没有写b,因为模型曲线平滑与否与b这个偏置项是没有关系的,另外曲线最平滑肯定就是直线了,所以参数 τ \tau τ也是我们需要慢慢调整的
最大似然估计的理解:一般样本都会服从一个分布,而自然界最广泛的分布就是高斯分布,那么在不知道样本分布的情况下,我们默认他服从高斯分布。那么想要描述当前样本的分布,就需要找到两个参数 μ \mu μ还有 σ \sigma σ。参数的选择很多,但是其中的选择生成分布能够符合当前样本数据的概率也有大小,我们就用最大似然估计去找一组最有可能的参数选择。
朴素贝叶斯算法去进行分类,假如是已知x问他是类别 C 1 C_1 C1还是 C 2 C_2 C2,就是计算 P ( C 1 ∣ X ) P(C1 | X) P(C1∣X) 如果它大于0.5就是属于类别 C 1 C_1 C1,否则就似乎类别 C 2 C_2 C2,按照贝叶斯公式,其余部分都是先验概率很好算的,关键就是计算 P ( X ∣ C 1 ) P( X | C1) P(X∣C1),而这个计算的话就是假设他服从一个分布,然后解出确定这个分布的参数,但是一般选择的是正态分布。
朴素贝叶斯算法的机器学习描述方法就是,设计一个带未知有参数的函数->贝叶斯公式,未知参数就是 μ \mu μ还有 σ \sigma σ,然后找到最优的一组参数
怎么找最优参数?1、对贝叶斯公式不断化简得到 P ( C 1 ∣ X ) = σ ( w x + b ) P(C1 | X)=\sigma(wx+b) P(C1∣X)=σ(wx+b),然后就是梯度下降求解了;2、假设特征相互独立,那么就可以使用最大似然估计去求解未知参数 μ \mu μ还有 σ \sigma σ。两个方法求出来的参数不会相同的,因为后者明显加了额外的条件。
注:前者是贝叶斯网络,后者是朴素贝叶斯
逻辑回归和线性回归
主要区别就在逻辑回归套了一层归一化,所以结果限制在了0-1之间,并且他的损失函数使用的是交叉熵损失,这个原因在于,套了一层归一化之后,再用均方差损失会很难训练,梯度很小既可能是因为距离很远也可能是因为距离很近。
还有一个区别是,逻辑回归出来的值可以理解为概率,用于分类问题,线性回归不方便做分类,因为将1,2,3,4的接近值定义为类别1,2,3,4的话,就会额外多出类别之间的大小等等关系
逻辑回归的局限:只能得到线性的模型
解决:特征变换,可以手动做,也可以让模型做
怎么让模型做?将数据输入两个逻辑回归模型,得到两个输出,这两个输出如果线性可分,再放入一个逻辑回归模型就可以分出来了,否则继续堆叠。然后堆叠的深了,又成为了DL
机器学习算法描述表格:logistic回归套的函数是sigmoid函数

判别式模型和生成式模型
一般认为前者性能好一点,后者相对较差一点,因为后者做了一些假设
而后者也有一些优势如:
第一,生成式模型可以用较少的数据完成分类任务。这当然是因为对数据分布的假设实际上也为我们提供了一些信息,这部分信息多少可以弥补一些数据量不足带来的损失。
第二,生成式模型对噪声更加稳健。这其实依然要归功于我们对数据分布的假设,当数据中有一些noise的时候,数据分布的假设可以帮助我们无视掉这些噪声点。
第三,可以把问题分解成先验概率和关于类别的条件概率两部分进行估计。这样做的好处李宏毅老师是用语音识别的例子来说明的,当我们判别一段语音的下一个单词是什么的时候,我们采用的先验未必也要从语音中估计获得,直接去网上搜集一些文本来进行估计就可以了,而条件概率的部分我们则可以用语音数据进行估计。
卷积神经网络CNN
首先,如果我们要用神经网络处理图片,假设是100*100*3的图片,第一个反映就是将他直接拉直成一个超长的100*100*3向量,输入模型,然后得到最后softmax之后的分类结果与label通过cross entropy计算损失,然后更新网络。但是,由于这个向量太大了,参数就会很多,会导致过拟合。
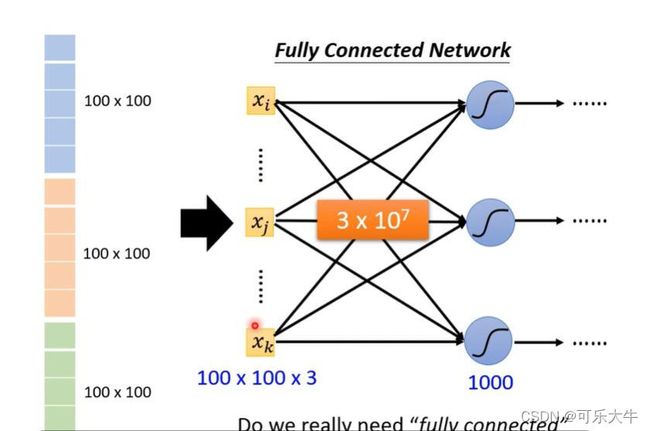
CNN引入角度1(本质的角度)
对图片数据进行观察,得到一些简化的技巧。
观察一:想要判断图片里的是什么东西,神经元只需要判断某些部分是否出现就可以了,把这些部分综合起来就知道图片里面有什么了,这是和人的认知保持一致的。而判断某些部分是否出现不需要看到整张图片,只需要看很小的一部分就可以得到了。
简化1:Receptive field 感受野。每个神经元不接受全部的输入,只和输入数据的一部分相关联,而这一部分会与若干个神经元相连,也就是每个Receptive field由若干个神经元负责侦测。最经典的Receptive field设计:首先是看全部的channels通道,并且kernel size也就是卷积核大小,也就是神经元侦测的范围是3*3,stride也就是步长是1或者2,也就是说虽然移动,但是会有重叠。原因在于:如果没有重叠的话,相交部分就没有神经元去侦测了。而为了避免移动的过程中超越边界,我们在边界外额外添加了一些层,作为padding填充。综上,图片中每个像素都是被Receptive field 覆盖的,都是有神经元负责侦测的。
观察2:很多神经元负责检测的Receptive field所判断的部分其实是一样的。
简化2:共享参数。也就是两层神经元之间的连接权重是一样的。由于每个神经元侦测的Receptive field是不一样的,所以他们的输出也是各不相同的。公用的这组参数称为filter,或者是卷积。

总结:CNN对全连接神经网络做出限制得到的,所以模型的弹性变小了,但是bias变大了,没那么容易过拟合了。这些限制是专门针对图像提出来的,所以他处理图像问题效果会很好,其余问题就得看它是否有这些图像的特性了。
观察3:将图片中奇数个像素点拿掉,形成的图片其实没有什么变化。
简化3:池化。将数据分为若干组,每组取一个代表,去掉其他元素。关键是为了减少计算量。但是他会损失图像的信息,所以很多现在的架构中,都直接不使用pooling了,而是使用一定形式的卷积,产生下采样的效果。
经典的CNN的架构:
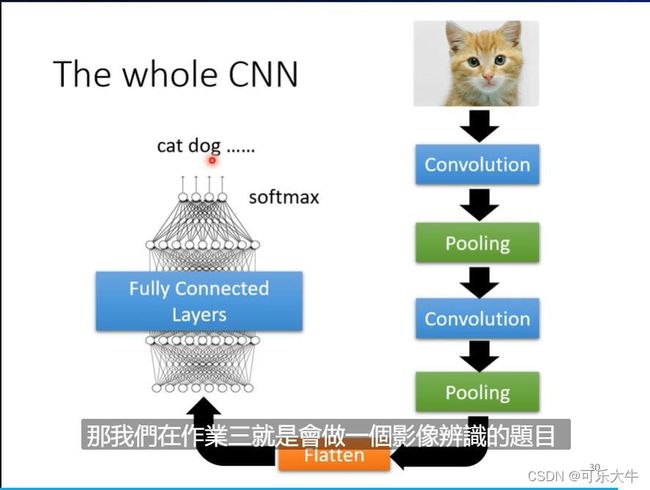
flattern:就是将矩阵拉平,得到一个长长的向量
CNN引入角度2(应用的角度)
卷积层就是有一组的filter,每个filter是kernel size * kernel size * channel的tensor(常见的是3 * 3 * 3),这些filter负责从图片中获取pattern(主体的部分),而filter里面的数值就是神经元之间的连接参数。
使用filter对着图片从左往右,从上往下移动并进行矩阵运算,得到一组新的n * n * 1的数据,移动的距离称之为stride。然后有m个filter就有多少组数据,将他们堆起来就得到了n * n * m的数据,我们称之为feature-map。n的计算是有公式的。
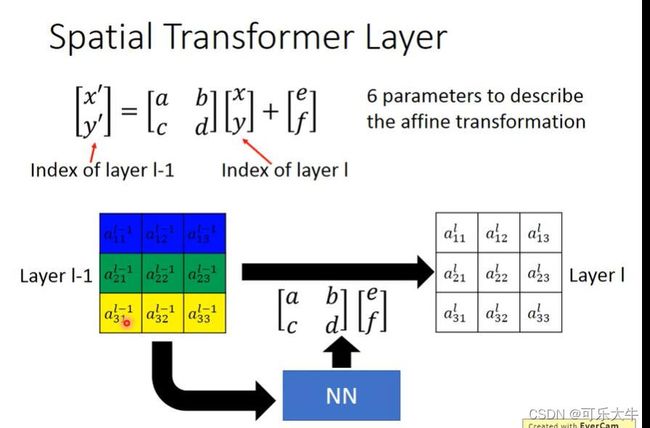
Spatial Transformer Layer
CNN对于旋转和缩放很不敏感,就是同一张图片,旋转缩放之后,CNN就认不出来了。所以,CNN如果可以认出来,一般就是因为数据增广的缘故,使得训练数据集中包含了这些图片。
故提出了Spatial Transformer Layer的概念,就是在CNN图片输入之后,多加一层,这一层的作用是对图片进行旋转缩放,将图片原来的旋转缩放进行矫正,使得模型处理的图片都是比较标准的图片。
例子:
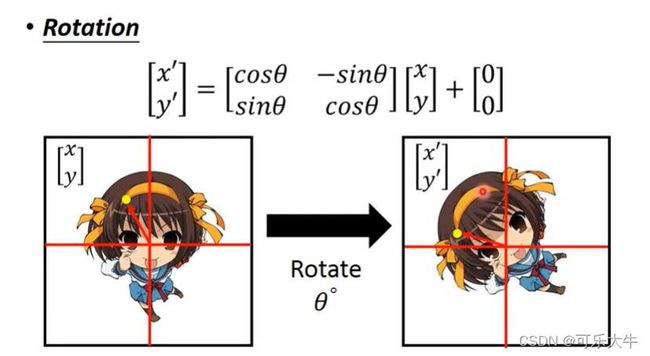

就是说,只要有6个参数就能够实现对于图片的旋转缩放,也就是模型在输入图片之后,这一层输出6个参数就可以了。
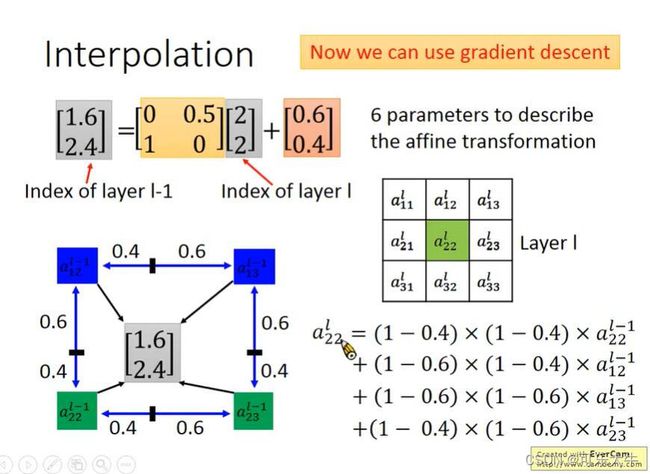
但是,如果得到的x,y坐标是小数呢?直觉上,直接将他归到最近的一个整数就可以的,但是这样就无法微分了,无法用梯度下降来求解了。所以有一个更好的方法,将他写成周围4个点的坐标关系式没这样就可以微分了。
例子: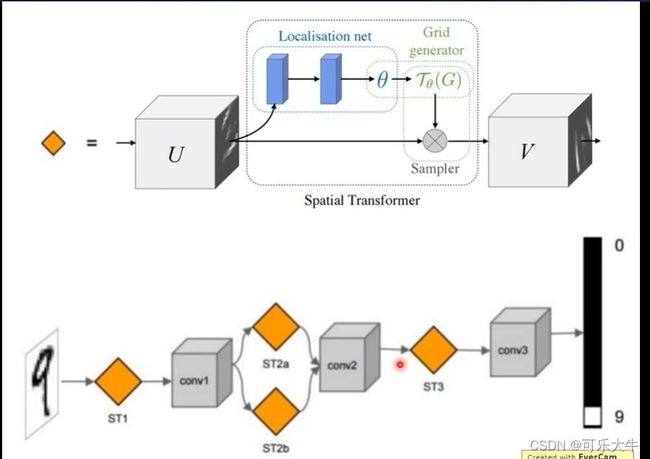

self-attention
问题引入
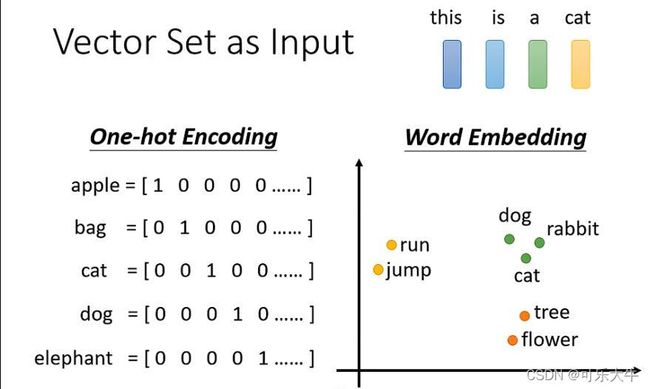
问题引入:之前的网络输入都是一个固定长度的向量,但是如果是一组向量呢?向量长度可变呢?
输入例1:对于输入一个句子,我们怎么把他变成一个向量组呢?对于句子中的每个单词可以1、one-hot编码,2、聚类,使用类别作为这个单词的编码,3、word embedding,one-hot编码每个单词显然不科学,一般用的就是word embedding。
输入例子2:声音序号,把一段声音取一个范围称为window,一般就是25ms,把window中的信息描述成一个向量,这个向量叫做frame。然后开始移动window,一般移动10ms。所以1s的声音就有100个frame。
输入例子3:图的每个结点也可以看成是一个向量。最经典的例子就是,社交网络图,中间的每个结点都是人的特性向量;分子可以看成一个图,而原子就是一个向量,这时候确实可以用one hot编码来表示了。
输出例子1:输入几个向量就输出几个label,无论是分类还是回归。这一类任务称为Sequuence Labeling.比如POS tagging也就是词性标注,输入一个句子,为每个单词标注词性。再比如语音辨识,就是输入一段语音,得到每个frame中的说的单词是什么。还有就是,输入社交网络图,输出每个结点的特性,如是否会购买某个商品。
输出例子2:输入几个向量就输出1个label。情感分析,输入一个句子,输出positive还是negtative。输入一段语音,输出speaker。输入一个分子,输出这个分子是什么。
输出例子2:输入几个向量模型自己判断输出几个向量。这一类任务称为seq2seq。比如,翻译,语音辨识。
Sequuence Labeling:输入几个向量就输出几个label。直觉上直接使用全连接神经网络就能做。但是貌似不对,考虑POS tagging也就是词性标注任务,直接将句子I saw a saw,中的每个单词分配给神经元,那么对于神经元而言两个saw是一样的,但是显然他们的类别不一样。那么,也就是我们需要引入上下文相关信息,也就是每个神经元除了接受对应单词之外还需要接受对应单词前后的单词。但是,如果需要的上下文信息很多,极限情况下就是需要整个句子的上下文信息呢?直觉上看,我们可以将神经元和所有的输入向量连起来,但是一方面是参数量大了,容易过拟合,另一方面输入向量到底有多少谁也不知道,网络不好设计。最终,我们可以采用self-attention的方法。
原理
self-attention:就是输入几个向量就输出几个向量的结构,并且对于每个输入向量他会考虑全部的输入向量也就是整个sequence的信息。
self-attention的运作:
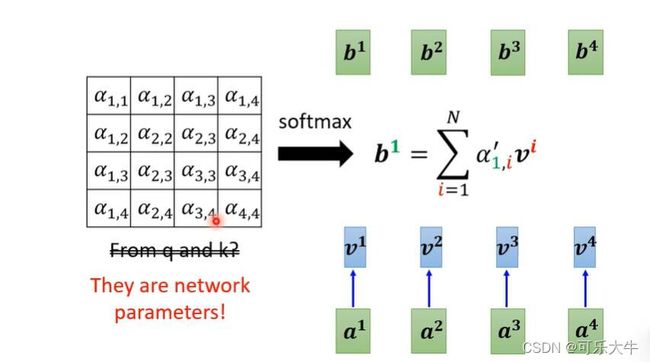
- 向量与向量之间的关联程度使用 α \alpha α表示,以向量a1为例,计算他和其余向量的关联程度 α \alpha α。
- 根据 α \alpha α抽取出sequence中的重要信息,得到输出b1。
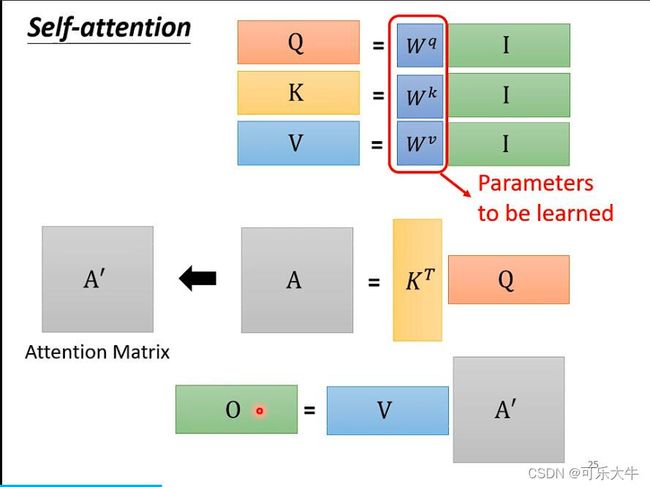
计算两个向量之间的关联程度 α \alpha α:最常用的做法是Dot-product。
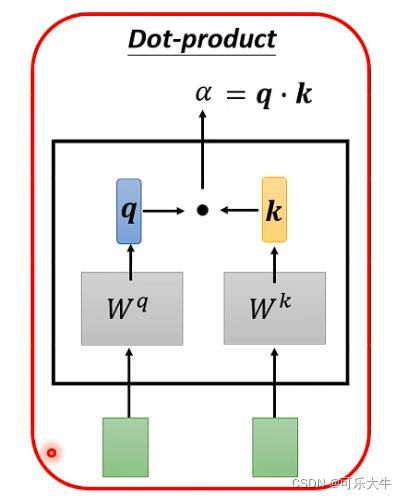
第一步:先计算全部的attention-score,然后做一个soft-max,但是不是一定用这个,只是实验表示这个会好一点。
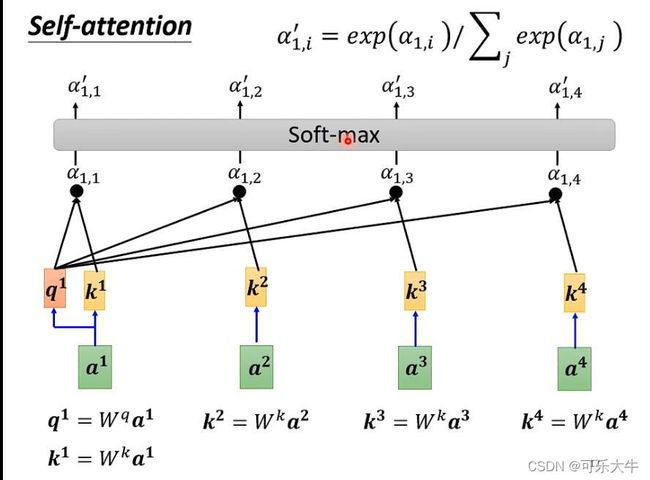
第二步:前一步得到的 α \alpha α越大,最后得到的b就与它越接近,也就是达到了一个抽取相关信息的作用。
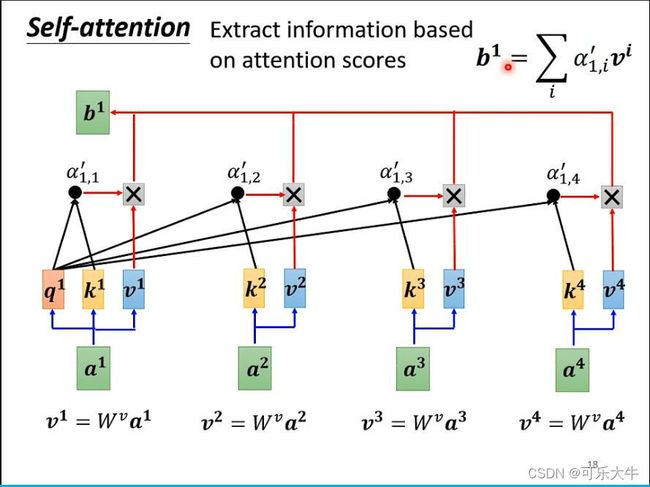
从矩阵角度看到self-attention:
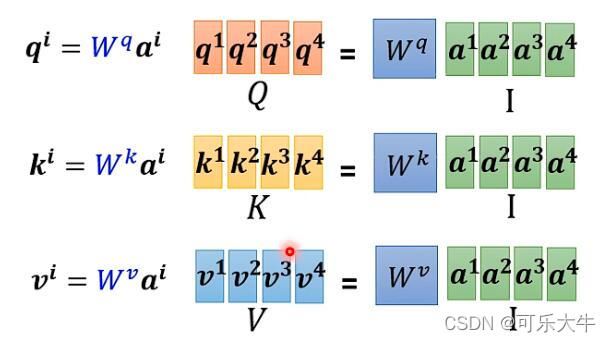

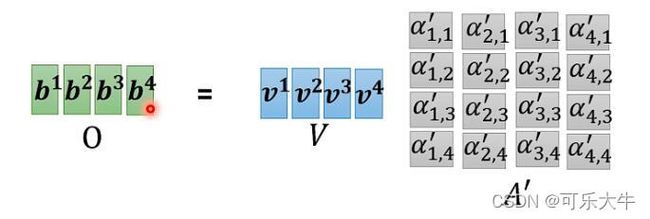
简略版本就是:
变体
self-attention中的痛点:运算量太大了。需要注意的是,self-attention现在都不是一个整体,也就是说,他是一个大的network中的一部分。当input sequence的长度太大的时候,self-attention对于整个网络性能的影响会比较大。
运算量的来源:需要得到attention-score matrix这个 N ∗ N N*N N∗N的矩阵,也就是每个q乘上N个K得到N个a,再乘上各自对应的v,相加之后,才能得到1个输出,要得到N个输出就得计算 N ∗ N N*N N∗N次,下面的图中,行表示query,列表示key
角度1:减少attention score的计算开销
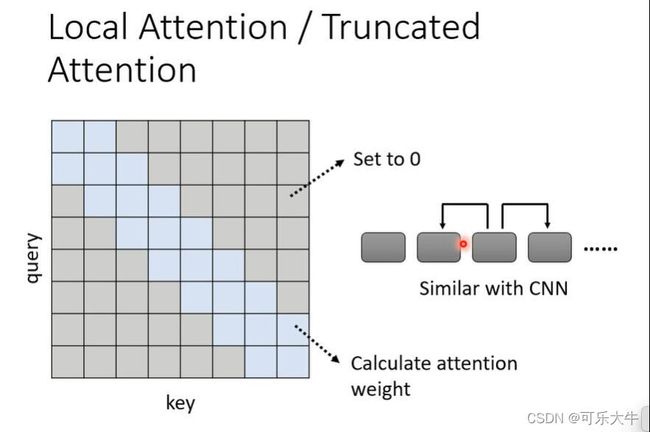
Local attention或者truncated attention:每次计算attention score的时候,只和周围的算,将其余的全部置为0。
如图,第一个q只和第一个、第二个key相乘,第二个q只和第一个、第二个、第三个key相乘,其余全为0,然后再去计算输出B。这就和CNN一样了,用它还不如直接用CNN
stride attention:不看临近的,看与某个位置距离为K的位置的咨询,相当于上一种方法的泛化。
如图,第一个q只和第一个、第四个、第七个K相乘。

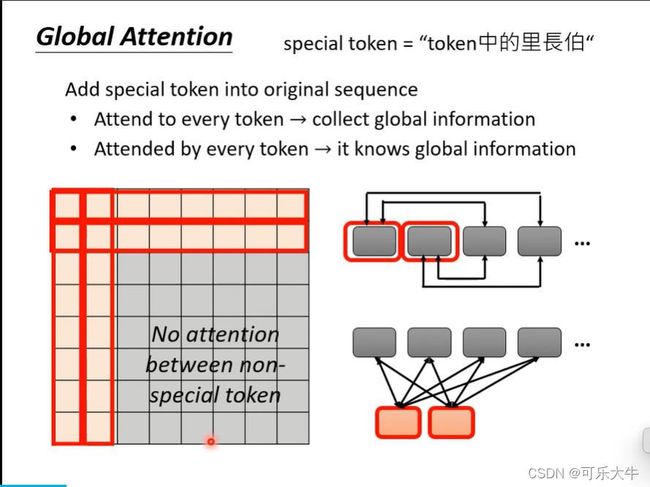
global attention:设置一些special token,他们会看到整个sequence的信息。方法1:设置一些sequence中的token作为这个special。方法2:额外加入一些token作为special token。
如图,假设第一、第二个token是special token,那么第一、第二个q会和所有的k相乘,之后所有的q只会和第一、第二个k相称。
random attention:随机选择一些k与q相乘
Multi-head Self-attention
策略引入原因:self-attention可以看成使用q矩阵去寻找相关的k矩阵的过程,但是相关可以有多种不同的表示形式,因此我们可以有多个不同的q负责不同种类的相关性。
具体过程就是,对于得到的矩阵Q、K、V,分别乘上两个矩阵,得到Q1、K1、V1和Q2、K2、V2,然后分别在做之后的操作得到O1和O2,然后将他们拼起来,乘上一个矩阵,得到最后的O矩阵。这里多出来的三个矩阵,就是这个方法额外增加的参数了。
本质:就是上面的多种attention的叠加
只计算矩阵中large value而不是small value:因为small value对于输出的影响很小,可以不计算直接置为0
方法:先将q和k进行聚类,然后只有q和k属于同一个簇,我么才计算attention score
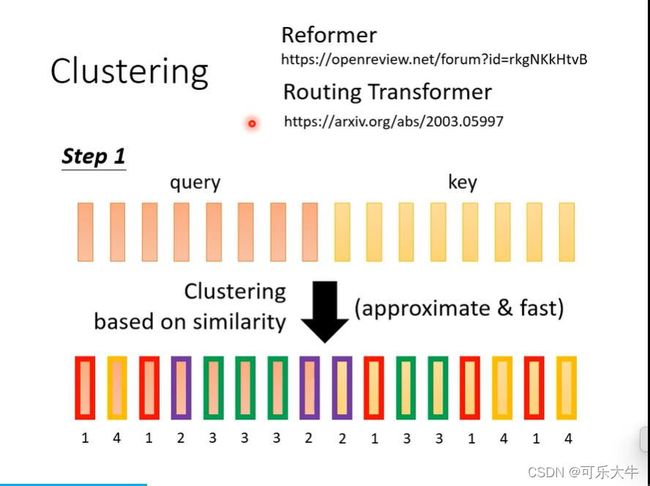
Sinkhorn Sorting Network:上面要不要计算attention score由人来决定,这个方法是直接由于机器来学习。就是学到一个 N ∗ N N*N N∗N的矩阵,元素内容都是0或者1,这个矩阵表明attention score matrix中那些需要计算,哪些直接置为0。
做法:输入input sequence,得到输出,然后将输出排起来,并且归一化,就得到了所要求的0-1矩阵了。
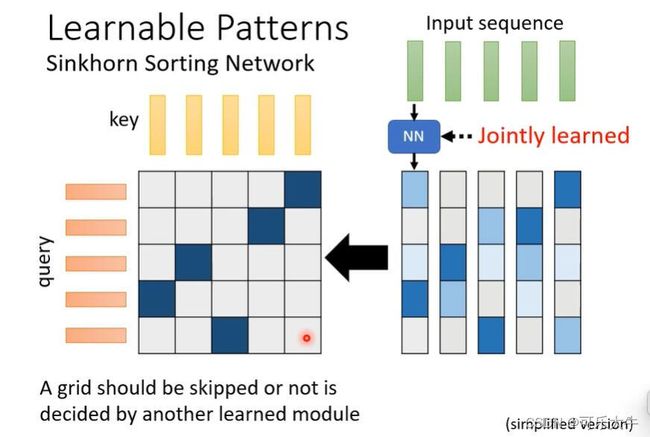
Linformer:观察发现,其实attention score matrix中,很多都是重复的,或者说这是一个低秩矩阵,我么只需要将其中核心保留就好了,其余就不重复计算了。
做法:挑选K个key和k个value来计算输出,大大减小计算量。但是q的数目变不变,需要由任务决定。因为q的数目和输出的数目是一致的,那些Sequuence Labeling的任务,显然不能变,其余的就可以了。

得到这K个key和value:方法1:使用CNN扫过,就可以了。方法2:乘上一个矩阵,做线性变化得到。
其余角度
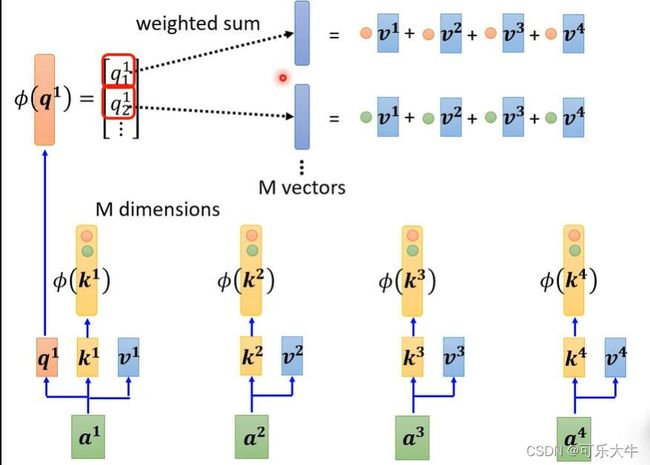
加速矩阵运算:不考虑softmax的话,self-attention相当于是 v ∗ k T ∗ Q v*k^T*Q v∗kT∗Q的过程
我们之前都是先算后面,再算前面的。但是,由线代的知识,其实先算前面的这个运算量是大大减少的,因为d很小但是N很大。另外,加上softmax,结论也是一样的。
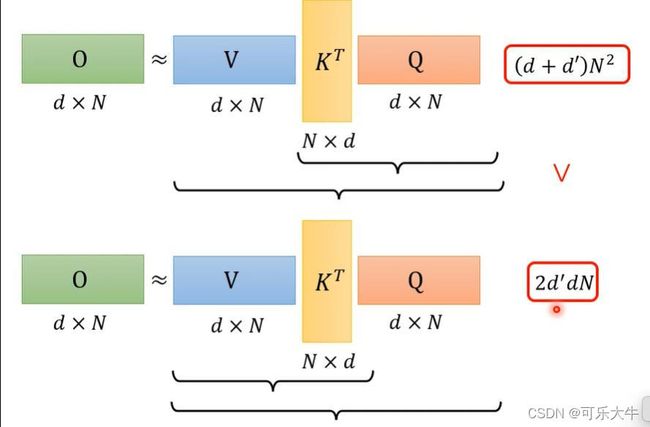
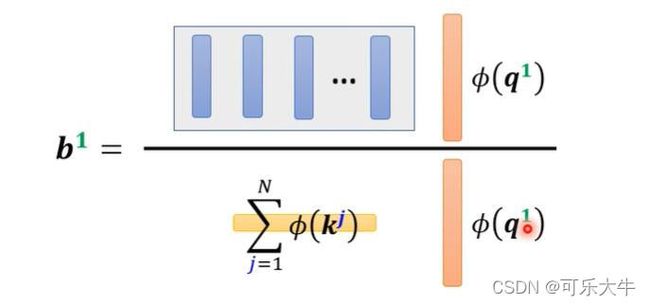
怎么操作对所有的K做一个transfor,然后拿K的每一个dimention(假设有M个diemntion)与v相乘得到M个vector,并与q做完transfo之后的每个dimention相乘,得到分子,然后与分母一起得到输出b。注:这里的m个vector是公用的,只需要计算一次就可以了的。
Synthesizer:输出是由矩阵得到输出的,但是这个矩阵不再是attention score,而是由于输入得到的。更近一步,可以直接就是输入输出之间的参数作为矩阵的值。
attention free:处理sequence,不使用attentio
Positional Encoding
策略引入原因:我们之前的self-attention没有考虑任何的位置关系,也就是说,对于每个输入向量的处理其实都是一样的。
这个技术的核心是:给每一个输入向量增加位置信息,也就是输入向量 a i a^i ai+位置向量 e i e^i ei,然后再去做self-attention。
应用
selef-attention最早用于NLP,但是在其他领域,如语音处理,计算机视觉也有广泛的应用。
做语音的时候,一句话生成的frame向量的数量非常的大,那么在做self-attention的时候,只需要关注一部分就可以了,不需要对整句话都做。
做图片的时候,因为self-attention需要的输入是vector set也就是一组的向量,我们可以将一个5*5*3的图片当成是5*5的向量组,也就是每个像素作为一个3维的向量
self-attention与CNN:CNN可以理解为是简化版的self-attention,self-attention设定合适的参数就可以做到与CNN一样的事情。导致:self-attention需要更多的数据训练,而CNN需要更少的数据。毕竟更加flexable的模型需要更多的数据。
因为self-attention关注某个像素与其他全部像素的关系,最关心的是与当前像素相关的一些像素,那么他们到底是什么样子的呢?是学习出来的。而CNN是像素与kernel-size范围内的像素之间的关系,他们长什么样子呢?就是kernel-size * kernel-size的一个矩形。
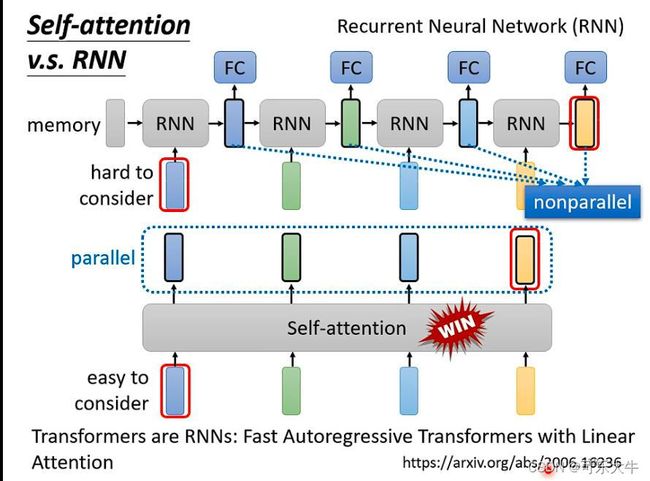
self-attention与RNN:很像并且self-attention+一些变化就能得到RNN,首先,RNN的输出想要考虑很前面的一个输入的时候,要将它存下来,然后才能在产生输入的时候考虑这个输入;而self-attention的输入肯定是考虑每一个输入,并且很方便。其次,self-attention可以平行处理所有的输入,然后得到所有的输出,而RNN不行。
self-attention与graph:graph的每个结点都是一个向量,但是graph中本来就有结点和结点直接的关系了,因此我们处理的时候可以只计算相连结点的attention-score。并且,把self-attention用在graph上面就得到了一种类型的GNN了。
RNN
simple 版本
问题引入:slot filling技术,输入一句话,得到对应的关键词。详细点就是,一个智能订票系统,有一些slot,如终点、时间。输入我想要明天去上海。终点slot就能填入上海,时间slot就能填入明天。那么网络的任务就应该输入这句话,然后输出句子中每个单词数某个slot的概率。
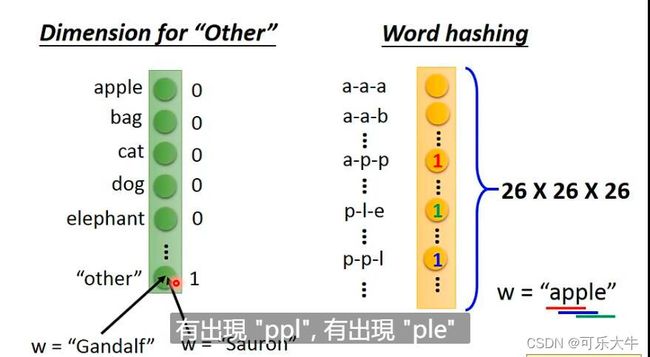
将句子中的单词变为向量:1、one-hot编码,将单词库里的所有单词变为一个one-hot的向量,另外再增加一个other向量,将训练集中没有的单词归为这个other向量。2、word hashing,将word分为若干个部分,然后对应部分为1,其余为0。
朴素思想:我们可以使用全连接神经网络处理这个问题,输入各个单词向量,输出这些单词向量属于每个slot的概率。对于已下情况,全连接神经网络就会出现问题,我们对于同样的输入,需要得到不同的结果。为什么是同样的,因为arrive和leave都是other向量,那么也就是输入是一模一样的。不同结果指的是,前面一个句子taibei是终点,后一个句子taibei是起点。

由此引出了Recurrent neural network,RNN,也就是模型具有记忆力,能够解决input相同但是output不同的问题。
Elman network
核心思想:hidden layer中的neuron的输出会被存起来,那么下一次这个neuron要计算输出的时候,不是单纯考虑输入了,还会考虑所有的memory的值。为了统一化,最初memory中的值就是0。
特点:同一个输入的值,得到的输出是不一定相同的。并且,输出的值和输入的顺序也有关系。

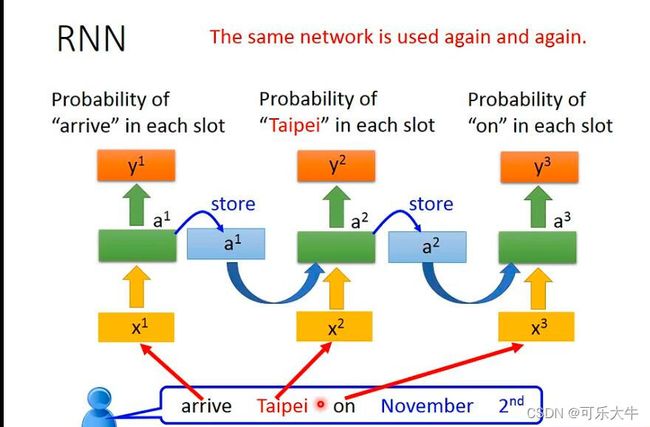
并且RNN对于输入的向量,并不是同时得到输出的,而是串行的,下面是一个模型的不同时间。先输入x1然后得到y1,再输入x2,得到y2但是计算过程中会使用memory的数据,之后同理。
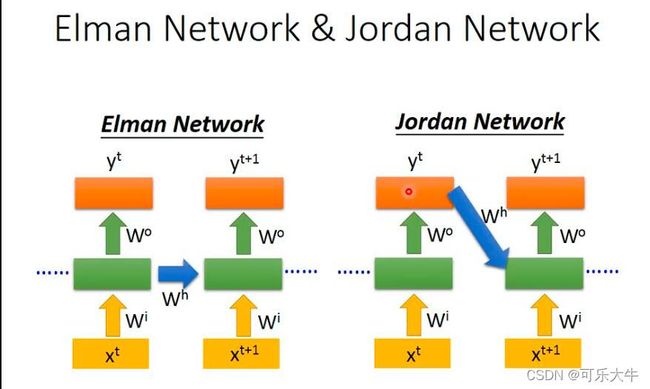
Jordan network:每次memory的不是hidden neuron的输出而是输出Y,并且下次hidden neuron计算输出的时候,使用的都是这个Y。好处:江湖传言,性能会好一点,并且memory里面的是输出Y,这个我们是可以知道的,而上面一种的话,其实memory里面是什么我们很难把握。
Bidirectional RNN:双向RNN,就是同时训练两个方向的RNN,然后每个输入向量的输出是这两个RNN对应的结果接入一个输出层得到的。好处:使得每个输出都是看过完整的sequence之后才得到的,所以性能会好一点。
long short-term memory(LSTM)
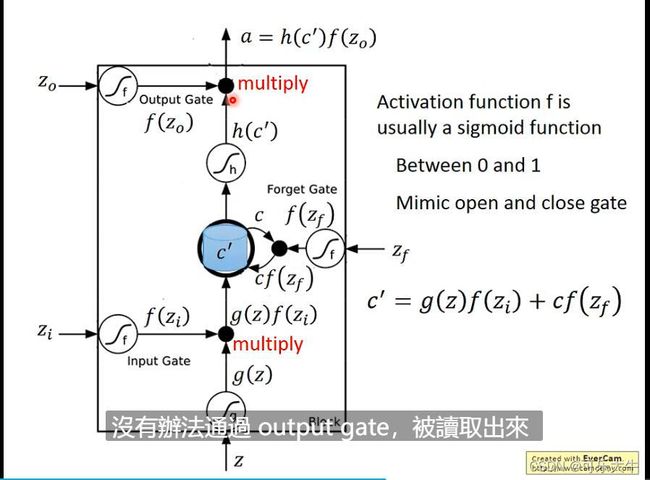
LSTM的cell中有三道门:input gate、output gate 和forget gate
详细一点:neuron的output想要被写到memory cell的话必须通过input gate,而input gate只有在打开的时候才能被写入,而它打开还是关闭是需要网络学习的。而memory cell中的值要被其他neuron使用,也必须通过一个output gate,而它打开还是关闭也是需要网络学习的。而memory cell中的值,是保留还是被forget,由forget gate决定,同样是forget还是保留以就需要网络学习。
抽象:LSTM可以看成是4个输入一个输出,四个输入指的是一个来自其他neuron的想要被写入memory的数据,3个控制信号,控制input gate,output gate和forget gate,输出就是output gate的值。
具体:这里的activation function f一般选择sigmoid函数,表示这些门打开的程度,对于memory中存储的 C C C,每次使用 C ^ = g ( z ) f ( z i ) + C f ( z f ) \hat{C}=g(z)f(z_i)+Cf(z_f) C^=g(z)f(zi)+Cf(zf)来替换, f ( z i ) f(z_i) f(zi)越小就表示输入的影响越小, f ( z f ) f(z_f) f(zf)越小就表示遗忘程度越大, f ( z o ) f(z_o) f(zo)越小就表示输出值越小。
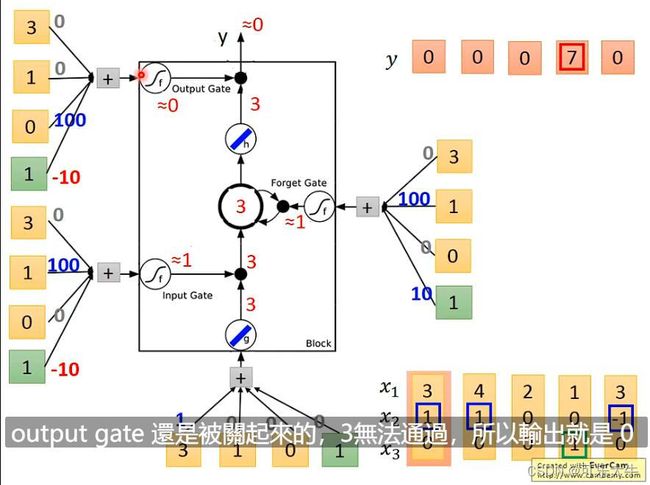
例子:原来memory是0输入[3,1,0]之后memory变为3,但是输出是0
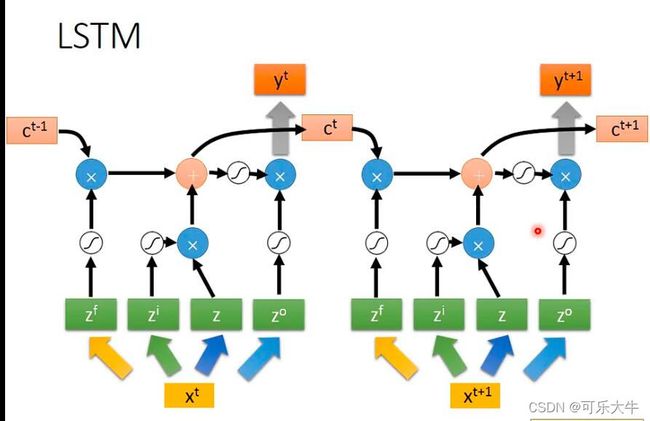
LSTM与RNN:相当于就是将RNN中所有的neuron都变为LSTM中的cell。原来的neuron接受上一级的所有neuron或者所有输入数据,有一组weight和一个bais,但是cell会将上一级cell或者输入数据进行变化,得到四个vector操控四个门,因此有4组weight和bais,参数量是原先RNN netwok的4倍。
RNN结构:
simple版本的LSTM:
hard版本的LSTM:用于生成4个vetor的变换矩阵还受到上一个时间结点输出和memory中的内容的影响,
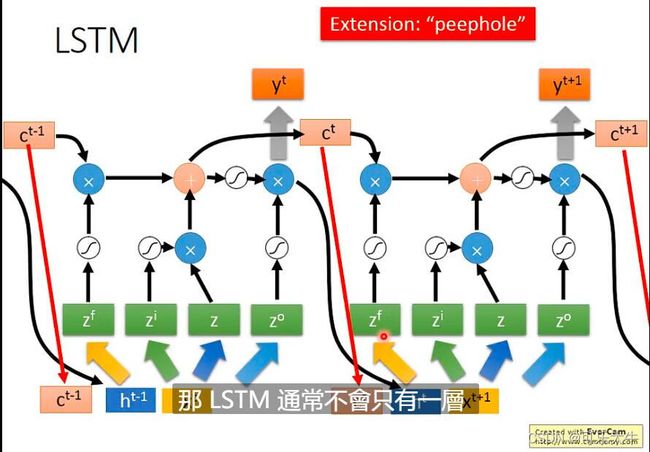
现在用RNN一般都不是simple RNN,基本都是LSTM
RNN的训练
原则:就是希望输出的vector与ground-truth尽可能地接近
方法:backpropagation through time(BPTT),是BP地进阶版,就是在BP的基础上考虑时序关系。
注:RNN的训练和之前的CNN不一样,CNN是随着epoch增加,loss慢慢下降的,但是RNN中loss的抖动很诡异…处理方式就是clipping,也就是当梯度大于阈值的时候,直接将梯度设置为阈值。为什么会有这个问题:RNN有time sequence同样的weight在不同的时间点会被反复使用。那么它可能梯度很小,也可能梯度很大。怎么解决:LSTM。为什么能解决:RNN中每个时间点,memory中的值都会被覆盖掉,但是LSTM中memory与input是相加的,所以除非被forget掉,否则memory每次的改变都是被保留的。冷知识:最初的LSTM就是为了解决这个问题的,并且forget gate多数时候需要开着的,也就是一般不会forget掉memroy的值。另外,有一个版本的LSTM叫做GRU,减少了一个门,参数量也少了,训练起来会更舒服。
RNN的应用
我们之前讲的是输入和输出的尺寸都是一样的,如输入单词输出他应该属于哪个slot,但是RNN还能做到更复杂的。
- 输入一个sequence,输出一个vector。情感分析(这是一个分类问题)和关键字提取等.
- 输入一个sequence,输出一个短一点的sequence。语音辨识,输入一个sequence,输出一个sequence。
为什么语言辨识不是输入和输出尺寸一样的呢?因为输入一个语音“好棒”,按照相应规则得到的输入vector应该是“好”“好”“棒”“棒”“棒”这种形式的,那么输出就应该是“好”“好”“棒”“棒”“棒”对应的文字表示,然而这是不符合我们要求的,我们要的输出就是“好棒”的文字表示。处理方法:’trimming‘,就是暴力去重,得到“好棒”,但是万一我们的输入是“好棒棒”呢?这个方法局限性很大。CTC:这个方法就是输出的时候不只是输出文字表示,还可以输出"NULL",那么输入“好”“好”“棒”“棒”“棒”,输出“好”“NULL”“棒”“NULL”“NULL”,然后去掉NULL就可以得到正确结果了。CTC训练:训练数据“好”“好”“棒”“棒”“棒”,对应的ground-truth就是“好”“NULL”“棒”“NULL”“NULL”的所有排列,也就是穷举所有可能性作为正确答案。 - sequence to sequence(sequence2sequence),这个与上面一个应用不同之处在于,两个sequence不知道谁长谁短。
典型应用:机器翻译。方法1:输入某种语言的文字,输出另外一种语言的文字。做法是在memory中存了所有sequence的信息,然后输出另一个语言的字符,然后再把这个字符作为下一个时间点的memory,让模型输出下一个翻译字符,不断循环,直到输出了一个终止字符,表示本次翻译结束。方法2:输入某一个语言的语音信号,输出另一个语言的文字表示。beyound sequence。RNN还能用于Syntactic parsing 句法分析上。Auto-encoder - Text:将文档转化为向量。Auto-encoder - Speech:将语音转化为向量,可以用于语音的抽取。 - attention-based-model以及它的升级版
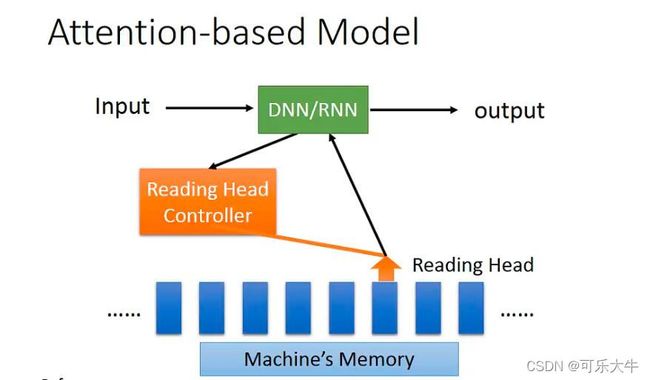
- Reading Comprehension
- Visual Question Answering:输入图片和问题,得出回答
- speech question answering
Deep learning和structured learning
各有优势,deep learning最大的优势就是可以deep,而structed learning不可以。
并且将两者进行结合才是主流和趋势。
比如:
- speech recognition:CNN/LSTM/DNN+HMM
- Semantic Tagging: Bi-directional LSTM +CRF/Structured SVM
graph neural network(GNN)
概述
GNN的作用:做分类,做生成。要用GNN的原因:输入之间会有复杂的关系。举例:做一个分类器判断哪个角色会是凶手。而角色和角色之间会有复杂的关系,这些关系能够帮助我们进行更好的分类,这种情况下GNN的表现会比较良好。
怎么使用这些结构和关系去帮助我们设计模型呢?使用convolution的方法,怎么使用呢?方法1:对convolution这个方法进行graph中的泛化,spatial-based GNN;
方法2:回归到信号处理中从convolution 的定义,spectral-based GNN。
如果graph很大,上面很多结点没有标注,又怎么办呢?
convolution and spatial-based GNN
spatial-based GNN的核心操作:
- aggregate:类似与convolution的操作,使用当前结点的所有neighbor node的feature去update当前结点。
- readout:将最后一层所有结点的feature集合起来代表整个graph
spatial-based GNN的真实模型
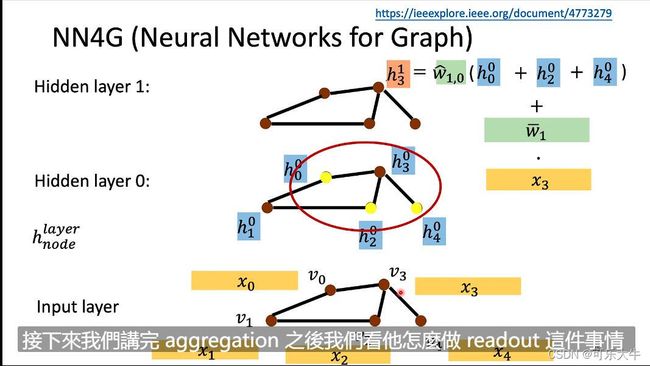
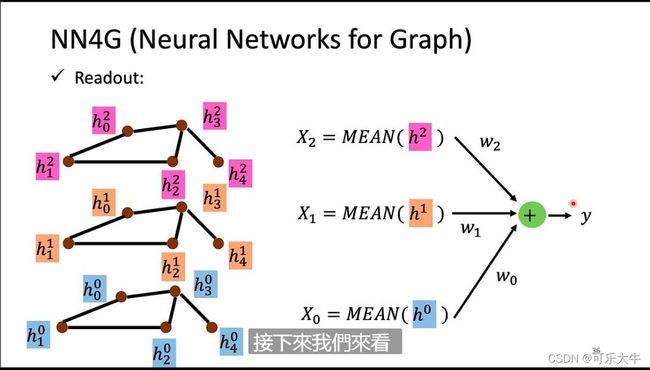
NN4G(neural network for graph)
输入就是各个结点的feature vetor,然后乘上一个weight数组就得到了第一层的结果,之后就要进行aggregate操作得到下一层的值了。这里的aggregate操作是将相邻结点的值乘上weight数组在、再加上当前结点的值,作为下一层的结果。之后不断aggregate直到到达最后一层。最后一层做的是readout操作得到输出。这里的readout操作指的是将之前每一层的feature全部加起来然后取平均,作为那一层的代表,然后将所有层的代表作为输出,得到输出y。
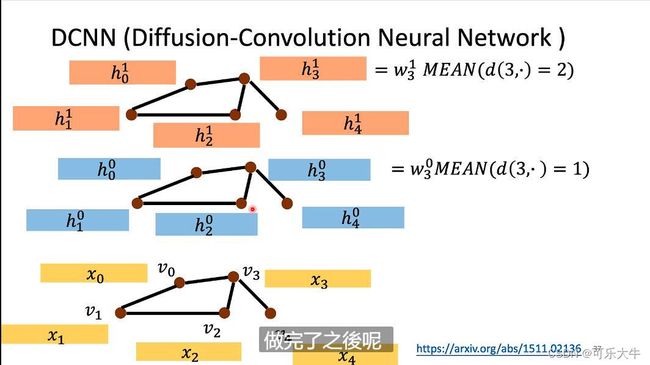
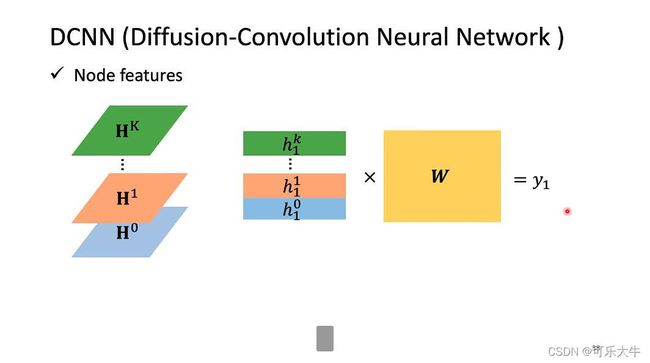
DCNN(diffusion convolution neural network)
输入就是各个结点的feature vetor,将与当前结点距离为1的结点相加再取平均,之后乘上weight数组得到第一层的对应结点的值.所以aggregate操作就是在第k-1层中,将与当前结点距离为k的结点相加再取平均,之后乘上weight数组得到第k层的对应结点的值。readout操作就是将每一层的feature stack起来,然后乘上weight矩阵得到输出。
MoNET(mixture model networks)
模型的关键就是aggregate部分,前面的aggregate操作都是直接相交,这个有点不科学,这个模型提前设定了一个边与边之间的距离,然后aggregate操作不再是将之前的neighbor 直接相加而是按权相加。
GTA(Graph attention network)最常用
模型的关键就是aggregate部分,上面一个模型是提前设定了一个边与边之间的距离,然后aggregate操作不再是将之前的neighbor 直接相加而是按权相加。这个模型里面,权重不是预先设定的,而是以一种attention的计算规则得到的,更加科学。
GraphSAGE:就是做aggregate的时候,使用LSTM取更新
GIN:是提出了一种可解释性,就是哪些aggregate操作是合理的,哪些是不合理的。关键是应该用相加而不是取mean
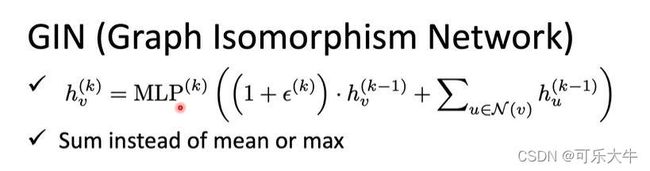
graph signal processing and spectral-based GNN
spectral-based GNN 真实模型
这个方法涉及了大量的信息与系统的知识,以后有需要在看吧链接
最常用的就是GCN
transformer
概述
是什么:就是一个sequence2sequence的model,输入输出两个sequence不知道谁长谁短。
典型应用:语音辨识就是将语音转化为文字,机器翻译某一种语言转换为另一种语言,语音翻译就是将一种语言的语音转换为另一种语言的文字。注:语音翻译能否使用前两者的结合来替代呢?理论上是可以的,但是很多语言的语音是没有对应的文字的,所以行不通。语音合成就是输出文字,输出声音讯号。聊天机器人输入一句话,输出对应的回答。
注1:很多NLP的问题都可以理解成QA(提问然后让机器回答),而QA就可以用sequence2sequence的model来解决。解决方法就是输入问题和大量的资料,输出问题的回答。但是对于各种问题,最好的解决方案还是特制一些模型,才能获得更好的效果。
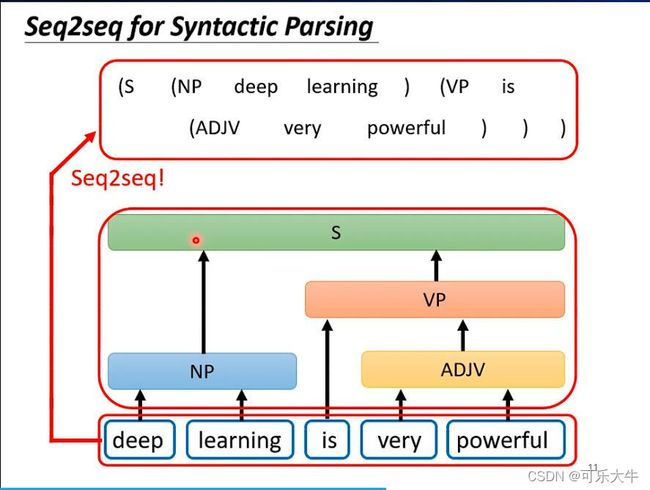
注2:一些看起来不像是sequence2sequence的问题也可以用sequence2sequence来硬解。如句法分析,输入句子,输出句子的句法结构。怎么做:就是将句法结构转换成一个sequence,那么就能用sequence2sequence的model来解了。
如多标签分类:比如输入文本,输出该文本对应的类别。这个不能用分类的方式做,因为分类最后得到的是各个类别对应的概率,我们无法划分界限,到底取几个。
如目标检测,也可以!
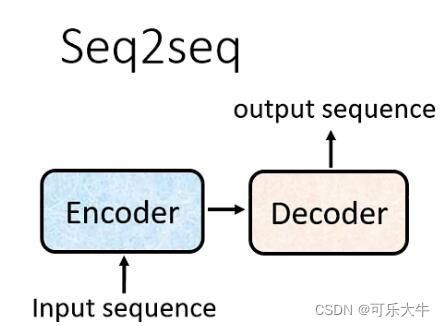
sequence2sequence的结构:input sequence 交给encoder处理,处理完之后交给decoder决定输出什么样的sequence。
encoder
核心:输入一排vector,输出一排对应的vector。有很多技术可以实现,如self-attention,RNN,CNN,而transformer用的就是self-attention。
encoder的结构:
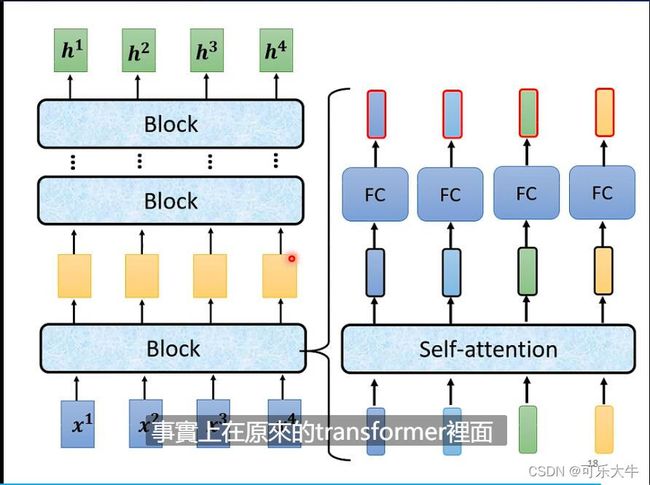
transformer中encoder的结构:
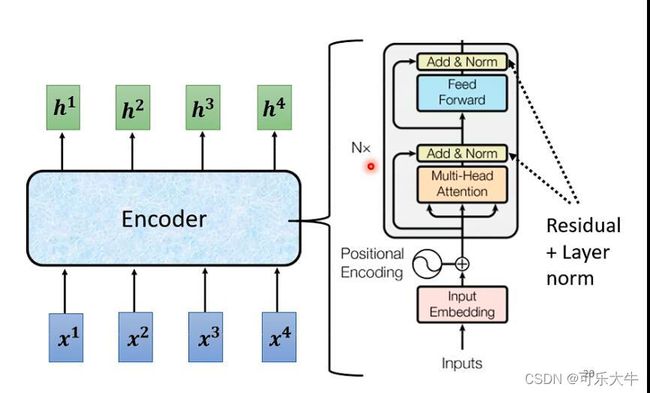
而transformer中encoder的结构,详细版本:
首先将输入送入selft-attention,然后得到的输出加上原来的输入,做一个residual的结构,之后再做layer normalizatio,然后送入feed forward network中,得到的结果同样加上原来的输入,做一个residual的结构,然后再进行layer normalizatio得到最后的block的输出。
layer normalization:输入一个向量,输出一个向量,不用考虑batch。对向量中各个dimention计算 μ 和 σ \mu和\sigma μ和σ,然后做归一化。

decoder
AT(Autoregressive model):
以中文语音辨识为例:首先将语音转换为vector,投入encoder中,输出一排的vector。接着decoder读入这些vector。然后给decoder一个开始符号(BOS begin of sentence),也就是现在decoder的输入是encoder输出的vector和BOS,他会输出一个vector,这个vector的长度与vocabulary(就是所有的中文字,本例中是这样)的长度相同,并且vector的内容就是各个中文字以及对应的概率(因为最后做了softmax),之后概率最高的就是输出,假设是’机’。之后,在将’机’最为新的输入,也就是现在的输入是encoder输出的vector、BOS和’机’,然后得到输出。接着迭代上述过程,

注:decoder会存在一些问题,比如,某一个时刻输出错了,但是之后会将这个错误的输出作为新的输入去进行decoder。
transformer中decoder的结构:
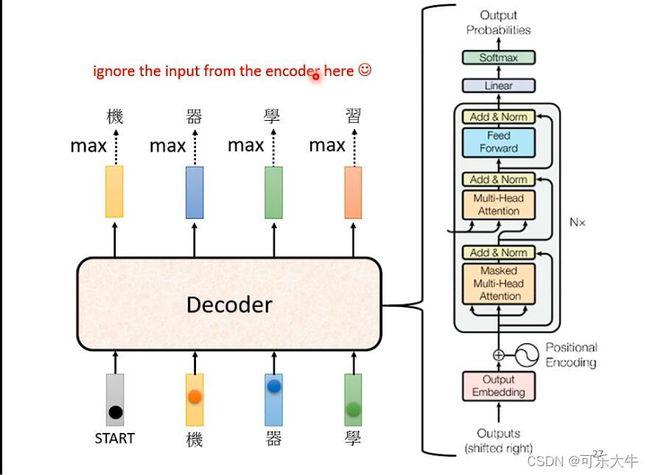
对比encoder与decoder发现其实长得很像:如果说不看中间的两个块,中间部分结构是一样的,除了一个Masked块。
Masked块就是Masked self-attention:self-attention是产生的每一个输出都会考虑所有的输入,而Masked self-attention则是考虑的范围逐渐变大,也就是产生b1的时候只考虑a1,产生b2的时候只考虑a1,a2,以此类推。只考虑,就是只与他们计算attention。具体看self-attention部分。
为什么需要masked:主要是由于decoder的性质决定的,计算b2的时候确实没有a3,a4的数据。
怎么停止:在vocabulary中添加一个额外的符号表示结束,如“end”,那么希望在语音辨识的最后输出这个符号,表明语音辨识结束。
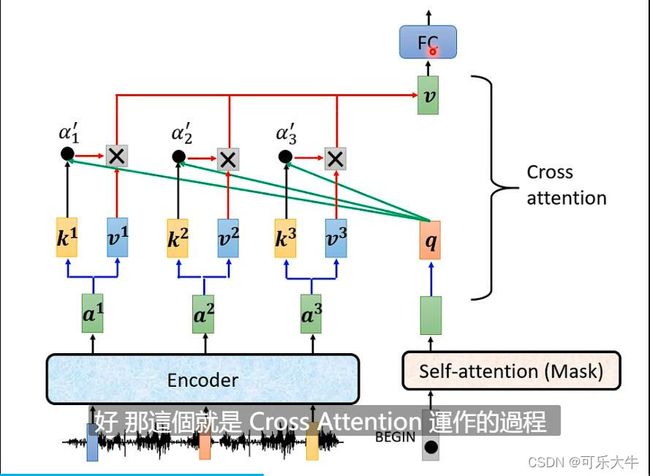
encoder与decoder的连接
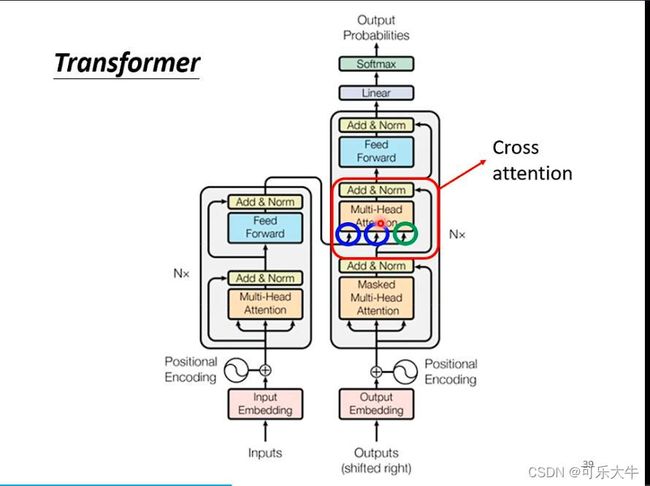
cross-attention:刚开始begin经过输出q然后做cross attention,得到的结果经过全连接得到输出,这个输出又作为下一次的输入之一。
训练
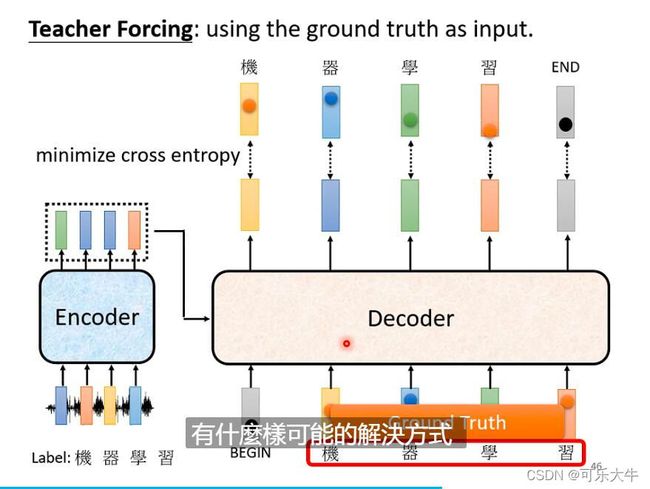
以上讲的全是检测,现在来讲讲训练。
训练:decoder的时候输入begin,输出一个softmax之后的概率分布,我们希望这个分布与机的one-hot编码尽可能地接近,使用交叉熵损失。后面同理,最后就是希望输入begin,机,器,学,习时希望输出end。希望全部的损失越小越好。
teacher forcing:注意到,encoder地输入此时其实就是真实标签,所以叫这个名字。但是测试的时候,decoder的输入很多时候是不对的,这个就叫exposure bias。怎么解决呢?scheduled samping训练的时候给decoder的输入加一点噪声。没错,加一点噪声反而会使得泛化的时候效果更好。
训练sequence2sequence的tip
decoder可以复制一些输入:输出并不一定要是产生的,也可能是从输入复制过来的。比如聊天机器人的任务,输入:我是aaB,输出:你好aaB,很高兴认识你。这个aaB对机器来说,很难创造这个词,但是可以学这去复制。再比如摘要任务。关键词:Pointer Network,Copying mechanism.
guided attention:强迫机器把输入的全部看过,避免出现机器看漏了输入的情况。如语音辨识,语音合成的任务。关键词:Monotonic Attention,Location-aware attention
Beam search:我们上面的decoder都是每次选softmax之后概率最高的,是贪心的过程。而这个方法就不是这样。
注:语音合成TTs模型测试的时候需要加入一点噪声,效果才会好。
NAT
NAT(Non Autoregressive model):decoder的时候输入N个begin,然后产生N个输出。
问题:不知道输入几个begin。解决方法:1、将encoder的输出放入分类器,然后输出一个数值N。之后给decoder用。2、规定一个上限N,那么我们decoder的时候,直接输入N个begin,然后在规定,输出end之后的字符全部不考虑。
NAT相比于AT的好处:快,能够平行输出结果;输出长度可控;性能没有AT好

GAN
概述
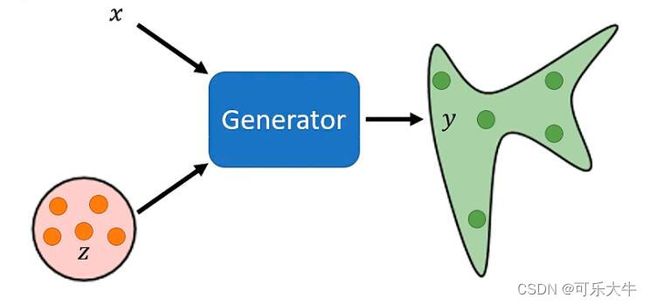
什么是生成:生成就是输入x和z得到y,但是z是一个分布中的随机采样(这个分布我们是知道的)。也就是说,一个固定的x,会得到一个分布
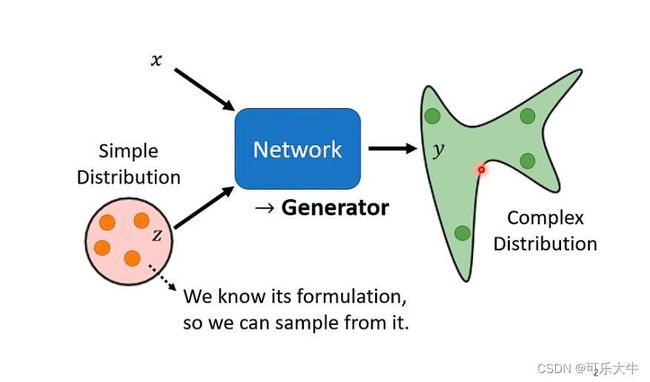
为什么要得到一个分布呢?以视频预测为例,输入一系列的图片序列,输出下一个时间点的图片。我们可以从视频中获得大量的训练数据,来训练模型。假设是游戏视频,我们通过学习大量的资料,用来预测真实游戏场景的结果。这里就会有一个问题,自由性会很大,也就是,一个场景下,我们往左走也行,往右走也行,训练资料中也都有,那么模型会认为两者都是正确答案,那么预测的一个可能结果就是同时向左向右走。因此,我们可以引入一个分布z,当z采样到1的时候向左走,采样到0的时候向右走。
也即是,对于同样的输入,其实存在多种不同的可能性的时候,适合使用生成。
例子,机器画图,聊天机器人…
Unconditional generation
Unconditional generation:就是没有x,单纯依靠z去生成。
例:动漫人脸生成,输入的z是正态分布(简单分布),输出动漫人脸(复杂分布),也就是输入一个简单分布的采样,一个低维vector,输入一个复杂分布的采样,就是 n ∗ n ∗ 3 n*n*3 n∗n∗3的高维vector
discriminator:判别器,识别出是生成的就打低分,识别出是训练数据,就打高分
例:输入一张生成的动漫人脸,输出一个数值,输出的数值越大表明这个动漫人脸被认为是来自训练数据集而不是生成

generator和discriminator的关系概述:左右互博,亦师亦友。generator不断进化,生成与训练数据接近的数据,discriminator判别其是生成的还是原始数据。
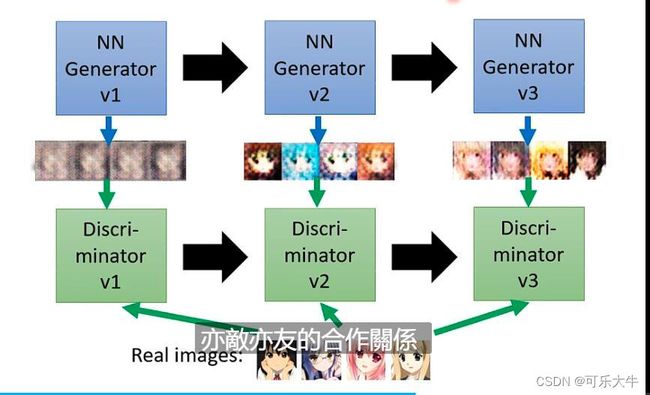
generator和discriminator的算法:首先随机初始化generator和discriminartor,然后每次训练都做已下的操作:
- 固定G,训练D。给G一些简单分布的采样,也就是一些低维的vector,生成出一些复杂分布的采样,也就是一些高维的vector,比如例子中的动漫脸。接着训练D,使用分类的方式,给训练数据标注为1,生成数据标注为0,将D作为一个分类器,希望给定一张图片能够输出类别;或者使用回归的方式,输入一张图片,回归出它对应的数值。不管怎么做,结果就是D对于输入数据的反馈是,越接近训练数据,打分越高。
- 固定D,训练G。就是调整G的参数,使得最后D输出的分数越高越好。
注:训练方法还是梯度下降或者说是反向传播,没有区别。另外,不要将G和D割裂开来,他们可以看成是一个整体,也就是说加入G是5层的,输出是一个 n ∗ n ∗ 3 n*n*3 n∗n∗3的向量,D是6层的输出是一个数值,我们可以直接将他们看成是11层的nn,输出是一个数值,只是说中间的隐藏层的 n ∗ n ∗ 3 n*n*3 n∗n∗3的向量可以转换一下,成为一张图片而已。
GAN的理论
generator
理论一点:输入一组从简单分布中采样到的低维vector,希望generator能够产生一组高维vector,这组高维vector满足一个分布 P G P_G PG,我们希望这个分布与所给的训练数据的分布 P d a t a P_{data} Pdata尽可能地接近,他们之间的差距称为divergence
实际一点:输入一组从简单分布中采样到的低维vector,希望generator能够产生一组图片,这组图片与所给的训练图片中随机采样得到的图片尽可能地接近。
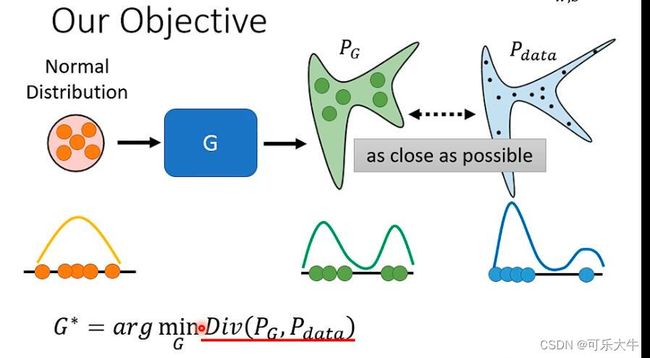
怎么计算两个分布的divergence:很难,但是GAN可以。只需要得到 P G 和 P d a t a P_G和P_{data} PG和Pdata的采样,就可以计算这个divergence。怎么得到采样呢? P G P_G PG的采样就是generator的输出, P d a t a P_{data} Pdata的采样就是从训练数据集中随机挑选几张。
具体怎么做呢:可以用discriminator的object function来辅助。什么是object function?:我们前面说discriminator要做的就是对于来自训练数据集的数据打高分,对于生成的数据打低分,这就是描述这个过程的函数。为什么?:首先train discriminator的时候就是希望objec function越大越好。那么divergence很大,那么discriminator就容易判别,objec function的值就能很大;divergence很小,那么discriminator就很难判别,objec function的值就不会很大。

WGAN:使用Wasserstein distance作为divergence进行训练的GAN
js divergence的问题:因为 P G 和 P d a t a P_G和P_{data} PG和Pdata的重叠范围很小。而从二维平面看,如果不相交,计算js divergence肯定是 l o g 2 log 2 log2,而完全重合就是0,根据它完全看不出训练的好坏。
Wasserstein distance指的是:将 P G 转 换 为 P d a t a P_G转换为P_{data} PG转换为Pdata所需的距离作为divergence
Wasserstein distance的问题:如果分布变复杂了,这个转换的方案就会有很多,Wasserstein distance选用这些方案中距离最小的一个作为divergence,计算量就有点大了,但是能够从Wasserstein distance的变化,看出模型的情况。
train GAN很难,最难的就是生成文字
将decoder作为generator,但是很难用梯度下降训练,可以适用RL训练,但是RL也很难训练,难上加难了。最后,有了一个方法就是scratchGAN
不能用监督学习做生成呢?可以!
GAN的评估
怎么评估生成的结果呢?:
最开始:肉眼观察
具体任务:比如这个动漫人脸的生成,可以train一个动漫人脸的检测,在生成出来的图片中,检测到越多,就代表检测效果越好
通用评估:得到所有图片整体的分布,这个是对所有图片分别进行分类,得到每个图片对应的类别(不是类别分布,而是单一类别),然后得到类别的分布,分布集中代表生成的效果好,分布分散代表生成的效果差
一些问题:
Mode collapse:生成的结果很像。因为某些图片discriminator会判别失误,那个generator就会大量产生这类图片,导致生成结果不好。
解决:发生Mode collapse之后,不train了,就使用没有Mode collapse模型
mode dropping:就是生成的分布是真实分布的一部分,也就是生成的分布对了,但是片面了,多样性不足,没有完整的刻画真实分布。导致,本次的生成结果是真实分布的一部分,下次是另一部分,两次之间可能存在蛮大的不同。
解决:增加生成结果的多样性。使用一个图片分类模型对生成的结果进行分类,得到每个图片对应的类别概率分布,然后将所有图片的分布做一个平局,最后看这个平均的分布是集中的还是分散的,集中代表多样性差,分散代表多样性好。
注:上面提到了两个分布,一个是所有图片整体的分布,这个是对所有图片分别进行分类,得到每个图片对应的类别(不是类别分布,而是单一类别),然后得到类别的分布,分布集中代表生成的效果好,分布分散代表生成的效果差;下一个是图片分类,得到每个图片对应的类别概率分布,然后将所有图片的分布做一个平局,最后看这个平均的分布是集中的还是分散的,集中代表多样性差,分散代表多样性好。
IS(inception score):就是上面两个分布结果的纵横衡量指标
FID(frechet inception distence):就是将生成的图片经过inception network,将softmax的输入向量作为这个图片的向量代表,假设这些向量服从高斯分布,假设真实图片也是服从高斯分布的,计算这两个分布的frechet distence,就是FID
Conditional Generation
Conditional Generation:给定条件x,根据x与z来生成
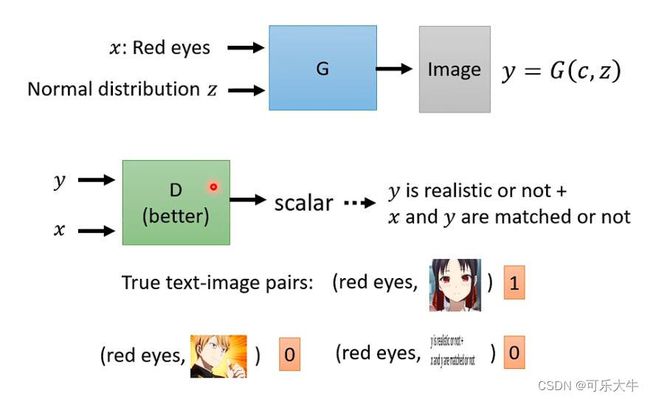
应用:文字对图片的生成,这个就需要监督了。输入“红眼睛 白头发”生成一张红眼睛白头发的图片,每次都不一样,因为每次的采样都不一样。图片对图片的生成,看一张设计图,输出设计的结果;输入白天,输出晚上;输入起雾的,输出没有雾的;输入素描,输出油画;
结构:generator输入x与z输出图片对应高维vector y,discriminator输入x与y输出一个数值,判别是来自数据集的还是生成的。注:1、discriminator的输入增加了x;2、判别的时候要求同时满足x与y了,并且不仅是给正确答案与错误答案,还得给正确答案的胡乱搭配。
注:GAN+监督学习==效果更好
GAN与无监督学习
以风格迁移为例:假设输入真人图片,输出对应的二次元人物的图片。我们可以使用上面的做法,也就是使用unconditional generator。原来是输入一个简单分布的采样(比如高斯分布),这里就输入一个真人人脸分布的采样,然后generator输出一个二次元人物的图片,discriminator给真人人脸打低分,给二次元人物打高分。也就是说,我们可以使用以前的方法做,但是会存在什么问题呢?问题:generator出来的,可能和输入没有任何关系,也就是说,直接将输入作为噪声,来generator,也是可以的,但是和我们的任务脱节了;其次,这个任务背景下,显然是没有成对的训练资料的(无监督学习嘛,可能有x与y但是x与y之间不是对应的),怎么用这种方式训练呢?
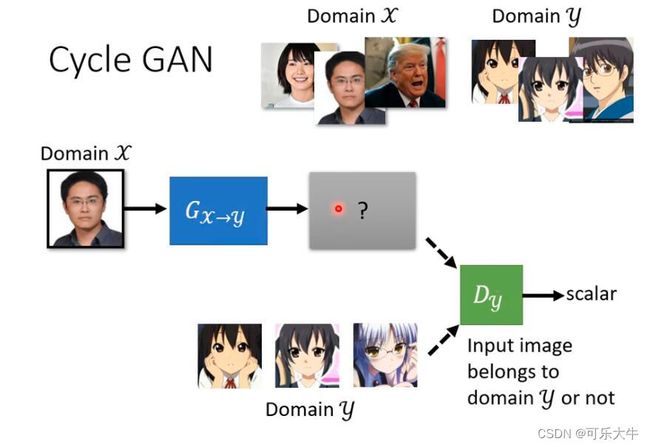
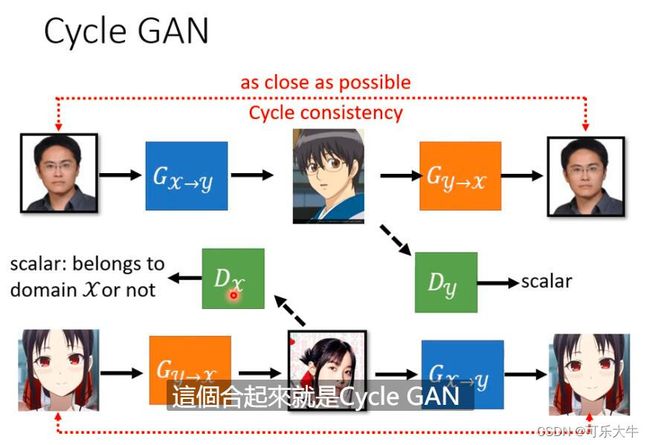
Cycle GAN:两个generator,也就是第一个generator负责将x转换为y,第二个generator负责将y转换为x,那么这种情况下,就会导致genrator生成的结果不会特别糟糕,并且与输入具有一定的相似性。discriminator的工作还是一样的。另外,训练的时候,可以同时训练双向的。
自监督学习
概述
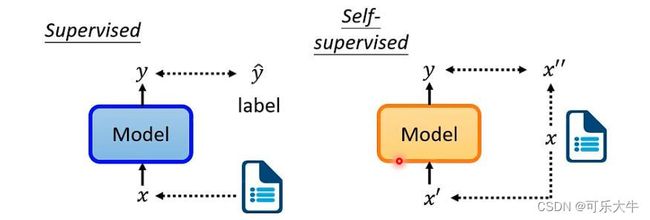
监督学习:有成对的 x 和 y ^ x和\hat{y} x和y^,训练的时候,模型输入x,输出y,我们希望 y 与 y ^ y与\hat{y} y与y^越近越好
自监督学习:没有 y ^ \hat{y} y^,直接将x分为 x ′ 与 x ′ ′ x^{'}与x^{''} x′与x′′,模型输入 x ′ x^{'} x′,输出y,我们希望y与 x ′ ′ x^{''} x′′越接近越好
注:自监督学习其实就是无监督学习,但是因为无监督学习里面的方法太多了,所以将这种形式的学习称为自监督学习
BERT
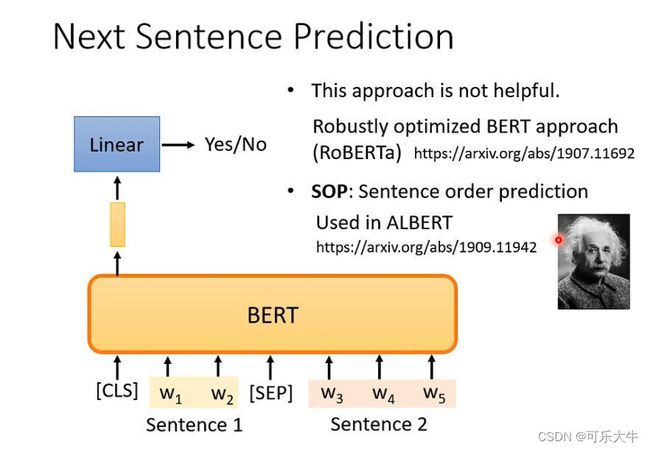
训练的时候:输入一个sequence,随机盖住几个token,然后通过BERT这个Transformer encoder得到一个输出的sequence,接着对于盖住的部分经过一个linear层,并且再通过一个softmax得到字符集上各个字符的概率,希望他与ground-truth尽可能地接近,没错,我们是使用这些被盖住地token进行训练的。当然,训练的时候不只有这个技巧,还有一个。就是预测两个句子是不是连在一起的。输入,cls(标志两个句子开始),句子一,sep(标志两个句子间隔),句子二。输出一个sequence,对于第一个token对应的vector经过linear之后,做一个二分类,也就是判断这两个句子是不是连在一起的。但是这个方法据说好像没什么用…有了一种改进的方法,就是给两个连续的句子,可能颠倒他们的顺序,模型要判断是否被颠倒顺序。
怎么盖住:使用特殊token替换或者随机变为其他不同的token

评估:怎么评估这样的BERT模型呢,使用任务集,也就是用于一系列的任务,然后取这些任务的平均得分,最常见的任务集就是GLUE
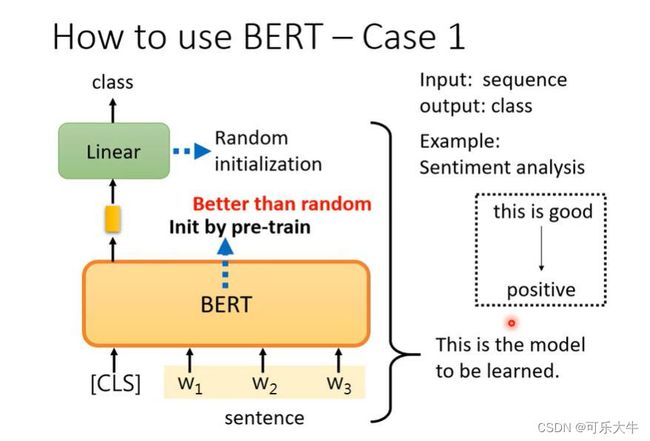
怎么用:将BERT添加一些层之后,直接用于下游任务中,额外添加的参数是需要训练的,BERT中原本的参数微调一下就好,训练用的就是下游任务的训练数据了。
为什么有用:因为在使用上述方法训练的时候,BERT学到了输入的上下文关系等核心信息,输出的向量就能代表输入的文字!
例子:

GPT
鸽
番外篇
训练的tip
batch normalization(BN):
思想:上面的优化器是在error surface不是很好train的情况下,想各种办法取train它。而BN则是直接变化error surface使得它会比较好train。
引入:error surface不好train的一种情况是某一个维度的数值变化对于最后的LOSS影响很大,而另一个维度的数值变化对最后的LOSS影响很小,这种变化会直接反映在梯度上。那么又是什么导致了这种情况呢?可能是输入,当输入很大的时候,会放大weight的变化,而输入很小的时候会缩小weight的变化。因此,我们可以想办法将输入的数值范围尽可能地一致,这种方法称为feature normalization。

具体的做法:将所有的N个数据放在一起,每个数据就是一个vector,然后对这些vector的每个dimention做标准化。标准化的过程:取N个数据的同一个dimention,得到N个数值,求这N个数值的均值和标准差,然后每个数值通过减去均值,除以标准差来进行更新。符号化表示就是,所有数据当前dimention的数值是 x 1 , x 2 , . . . , x N x_1,x_2,...,x_N x1,x2,...,xN, m e a n = mean= mean= 1 N {1}\over{N} N1 ∑ n x i \sum_{n}x_i ∑nxi, σ 2 = \sigma^2= σ2= 1 N {1}\over{N} N1 ∑ n ( x i − m e a n ) 2 \sum_{n}(x_i-mean)^2 ∑n(xi−mean)2, x i = x i − m e a n σ x_i= \frac{x_i-mean}{\sigma} xi=σxi−mean
用处:使得loss收敛更快一点。梯度下降更顺利一点
继续:上面是对输入数据做了normalization,但其实经过layer之后,又是一个个的vector了,还是可以继续做normalization方便接下来对于weight的更新。那么,新的问题:是在activation function之前做还是之后做呢? 实践表明,其实是一样的。但是如果activation function是sigmoid之类的话,还是在之前会好一点,因为normalization之后会更容易落到他们的饱和区,获得更大的梯度。
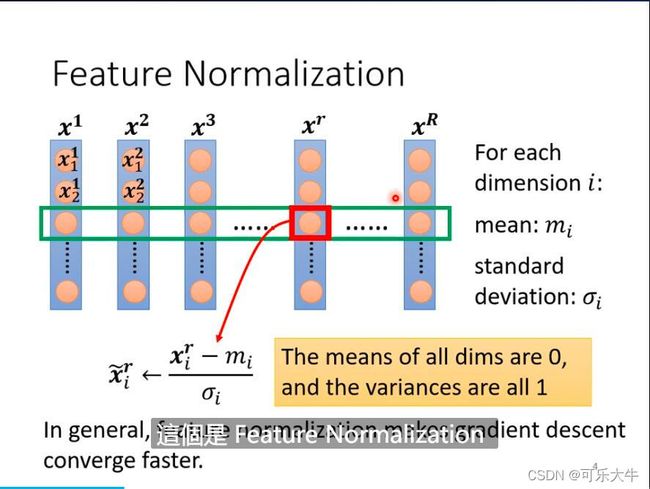
但是我们无法对整个数据集所有的数据都做feature normalization,只能对每一个batch做,所以叫做batch normalization
接下来是Testing或者inference的部分(上面是training的部分):正式使用这个模型的时候,肯定是来了一个数据我们直接计算模型输出了,这个时候没有一个batch数据了,怎么得到 μ 、 σ \mu、\sigma μ、σ呢?一个做法就是,我们根据训练时候的 μ 、 σ \mu、\sigma μ、σ进行处理得到测试时候的 μ 、 σ \mu、\sigma μ、σ,什么处理呢?平均或者是前n-1个平均再和最后一个加权等等做法都可以。
BN生效的原因:BN会改变error surface,使其不崎岖,比较平滑。
word embedding
对于输入一个句子,我们怎么把他变成一个向量组呢?对于句子中的每个单词可以1、one-hot编码,2、聚类,使用类别作为这个单词的编码,3、word embedding,一般用的也是word embedding。
word embedding是一个unsupervised prolem,也就是我们要输入一个词汇,输出这个词汇对应的word embeddingde,而我们的训练数据只有大量的文字,没有对应的label。
思想:关键是靠context。比如说小明喜欢你,小强喜欢你,那么机器就会认为小明和小强之间是存在一定相似性的。基于这个思想的做法:count based和prediction based。
count based:如果 w i w_i wi和 w j w_j wj经常在文章中一起出现,他们对应的word embedding向量就应该比较接近,
prediction based:我们训练一个model,他的作用是给定一个单词的one hot vector,输出下一个单词是某个word的概率。而我们使用第一个hidden layer的input作为这个word的word embeddingde vector。为什么这样能行:还是这个例子小明喜欢你,小强喜欢你,模型的输入是小明或者小强,我们都希望model输出的是喜欢你的概率最大,那么也就是希望经过中间weight的转化,使得两个不同的输入能够尽可能对应相同的输出。因此,hidden的输入可以作为他们对应的word embeddingde vector。
prediction based-sharing-parameters:我们可以不只是看一个单词预测下一个单词,而是可以看前N个单词,预测下一个单词。但是这里有一个要求,就是neuron会连接所有单词对应的分量,但是我们要求他连接每个单词对应的分量weight都相同。就是说第一个单词第一个分量和第二个单词第一个分量连接第i个neuron的weight都一样。这么做的原因:一方面,因为前N个单词顺序不同,得到的output应该是相同的;另一方面,能够减少参数量。怎么做呢:首先给他们一样的初始值,然后梯度下降的时候,减去的不是单个梯度值,而是减去这N个梯度值。

训练:最基本的训练方法就是希望预测出来的下一个单词vector与真实的值越接近越好。
变体:
Continuous bag of word (CBOW) model:使用前一个和后一个单词预测中间的单词
skip-gram:就是用中间的单词预测前后的单词
Pointer Network
问题引入:在一些点中找到部分点,能够将所有点包起来。
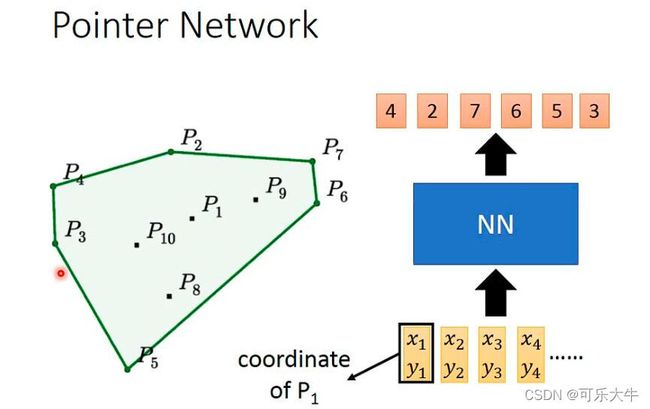
不适用sequence2sequence的方法解决:因为encoder无所谓,但是decoder的时候会有问题,输出的范围不会取决于输入。
可以使用attention的方法解决
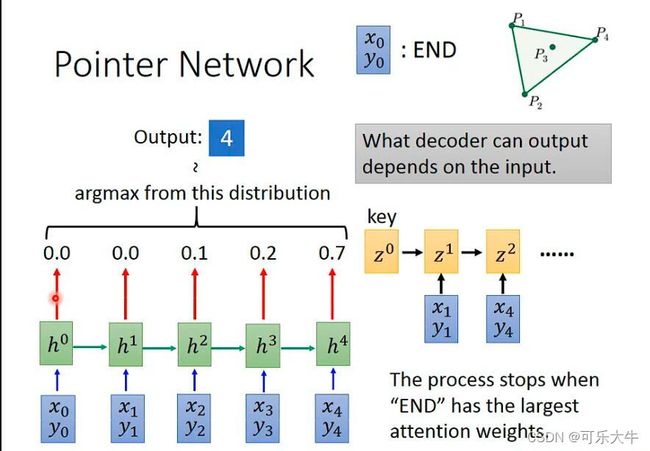
因此Pointer Network的好处就是,输入多少,那么输出的范围就定了。
应用:比如summarization、机器翻译、聊天机器人
domain adaptation
domain shift:输入的时候,训练数据和验证数据分布不同。输出的时候,训练和测试的输出结果的分布不同。
情景1:验证集是有大量数据和大量标注,这种情况,直接拿它来训练吧
情景2:验证集有大量数据和少量标注,可以使用这些少量的标注来微调模型,一般2/3个epoch就可以了,不然会过拟合的。
主要情景:验证集大量数据,没有标注。
朴素思想:找到一个特征提取器,能够在验证数据中得到与训练数据类似的特征,接着喂入模型,那么我们训练的模型就可以在验证集上得到好效果了。
详细一点:对于图片而言,我们可以理解为特征提取和标签预测两个阶段,我们希望对于训练集中图片特征提取之后的分布与验证集上图片特征提取之后的分布相同。
具体:标签预测的功能是预测图片对应的标签,领域分类器的功能是根据特征提取器的输出判断输入的图片是训练集那种有标签的资料,还是验证集那种,没有标签的资料。特征提取器的作用是,对输入进行特征提取,并且,让领域分类器分不出来,也就是输出的特征分布尽可能地一致。