李宏毅老师2020机器学习(深度学习)——知识点总结篇(21-30)
李宏毅老师2020机器学习——知识点总结篇(21-30)
李宏毅老师2020机器学习课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML20.html
视频链接地址:
https://www.bilibili.com/video/BV11E41137sE?p=1
目录
-
- 李宏毅老师2020机器学习——知识点总结篇(21-30)
- 21 Unsupervised Learning:Word Embedding
- 22 HW4 RNN
- 23 Explainable Machine Learning-1
- 24 Local Explanation: Explain the Decision(Explainable Machine Learning-2)
- 25 Explainable Machine Learning-3
- 26 Global Explanation (Explainable Machine Learning-4)
- 27 Global Explanation(Explainable Machine Learning-5)
- 28 Using a Model to Explain Another(Explainable Machine Learning-6)
-
- Local Interpretable Model-Agnostic Explanations (LIME)
- 29 LIME(Explainable Machine Learning-7)
- 30 Decision Tree(Explainable Machine Learning-8)
注:本知识点仅供大家参考和快速了解这门课,每一节均为笔者听后仅总结细节和重点(而无基础知识),李宏毅老师的课程非常好,详细学习的读者还是请自行一一观看学习。作业代码也在持续整理。
以下顺序均参照视频顺序,无缺无改
21 Unsupervised Learning:Word Embedding
You shall know a word by the company it keeps
-
Count based: V ( w i ) . V ( w j ) < − > N i , j V(w_i) . V(w_j) <-> N_{i,j} V(wi).V(wj)<−>Ni,j
如Glove Vector -
Predition based:
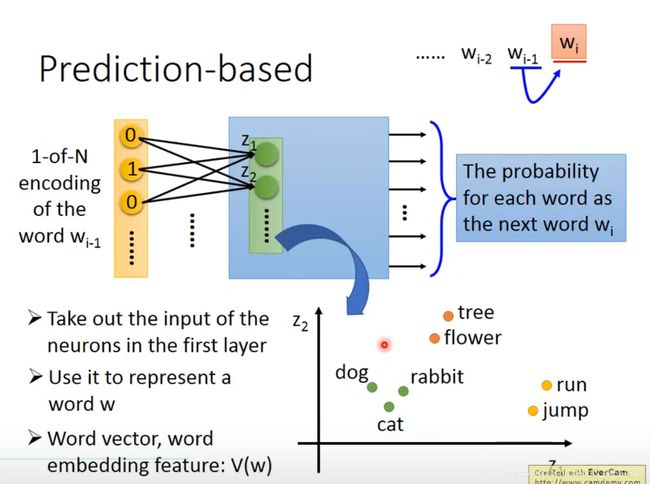
因为要根据输入的词汇预测下一个挨着的词汇,故如果两个词汇的下文相同,它们对应的隐藏层的参数也就相似。
CBOW: use w i − 1 , w i + 1 w_{i-1} , w_{i+1} wi−1,wi+1 to predict w i w_{i} wi
Skip-gram: w i w_{i} wi to predict w i − 1 , w i + 1 w_{i-1} , w_{i+1} wi−1,wi+1
在论文刚出现时训练隐藏层的神经网络其实并不深,仅有一层,为什么呢?在当时,发明者表示早期就有了这种word embedding的方法,但它们的神经网络都是较深的,导致训练速度慢、不能训练大量的数据。
讲个励志故事,word embedding发明人最初投稿的时候,投给了并不出名的期刊,但是被拒了并附有类似这是什么东西的,能有什么用的评论。现在这篇word embedding已经”家喻户晓“了。
22 HW4 RNN
LSTM实现文本分类,已整理完
23 Explainable Machine Learning-1
有这样两种 Explainable ML:
- Local Explanation
Why do you think “this image” is a cat? - Global Explanation
Why do you think a “cat” looks like?
decision tree其实是现有既比lr强大,可解释性又不错的模型。
24 Local Explanation: Explain the Decision(Explainable Machine Learning-2)
Why do you think “this image” is a cat?
基本思想:把某一个component修改或拿掉,如果对机器预测的结果有很大的影响就说明这个componet很重要

有这样一个实验,通过改变灰度方框遮挡位置来进行图像分类的可解释机器学习。上图红色的部分表示模型确信正确标签的程度,如上图第一个识别博美狗,当灰色方框遮挡住狗头时,模型便无法确定这张图是否是博美狗了,也就是说狗头部分将是模型判断为博美狗的重要因素。
但值得注意的是,灰度图的大小也是一个重要的参数,不同大小的灰度图最终得到的可解释结论也不同。

还有这样一种方法,根据目标值的变化对扰动的梯度作为亮度画图,Saliency Map来判断哪部分是重要的。
类似梯度的方法还有很多。但是这种方法会遇到下图这样的问题

解决方法:见上图论文
25 Explainable Machine Learning-3
图像分类宝可梦和数码宝贝,经过Saliency Map画图后,可以发现机器真正在意的不是宝可梦或数码宝贝的本体,而是主要考虑了本体周围的边缘。后来发现原来所有的宝可梦都是PNG的,而数码宝贝都是JPEG的。(PNG透明背景)
26 Global Explanation (Explainable Machine Learning-4)
Why do you think a “cat” looks like?

我们可以通过找 x ⋆ x^{\star} x⋆使得某一类 y i y_i yi的值最大,代表机器在判断 y i y_i yi这类时主要关注了什么,即
x ⋆ = arg max x ( y i ) x^{\star} = \argmax_x(y_i) x⋆=xargmax(yi)
但是仅考虑这一点,对手写数字识别可以得到上图左侧的图片,这是完全没法看出来什么的。
因此又引入了 R ( x ) R(x) R(x),代表当前的x有多么像一个数字,即
R ( x ) = − ∑ i , j x ∣ x i j ∣ R(x) = -\sum_{i,j}^x|x_{ij}| R(x)=−i,j∑x∣xij∣
加上这个限制后得到了上图右侧的图像。
27 Global Explanation(Explainable Machine Learning-5)
可以训练Generator来生成图片

训练的目标从
x ⋆ = arg max x ( y i ) x^{\star} = \argmax_x(y_i) x⋆=xargmax(yi)
变成
z ⋆ = arg max z ( y i ) z^{\star} = \argmax_z(y_i) z⋆=zargmax(yi)
训练过程从直接找x使得某类y的预测值越大;改为找低纬度向量z,用图片生成器生成x,再通过x进行图片分类使得某类y的预测值越大。最后再把 z ⋆ z^{\star} z⋆用图片生成进行展示。
那为什么要这么做的,因为引入Image Generator相当于加了一种限制,它能够使机器最终展示给我们的一定是一张正常的图片,是可解释的。
28 Using a Model to Explain Another(Explainable Machine Learning-6)
基本思想:某些模型是可以被解释的,假设可解释的模型和不可解释的模型做的事请是一样的,用这些可解释的模型去分析不可解释的模型做了什么。用可解释的模型去模仿不可解释的模型,如下图所示

Local Interpretable Model-Agnostic Explanations (LIME)
- 决定想要分析的数据点
- 在想要分析的数据点附近采样,将采样的点带到需要解释的黑盒中,得到黑盒结果
- 训练LR预测黑盒结果
- 分析LR模型来解释黑盒

29 LIME(Explainable Machine Learning-7)
LIME一般只能用在Loacl Explaination上,因为如果用LR是很难模仿整个被解释模型的。
LIME使用步骤如下图



比如我们对图片进行二分类,判断这样图片是不是青蛙,使用LIME进行模型解释时,有上述四个步骤:
- 选定需要被解释的数据点,即选取一张青蛙图片
- 在被解释的数据点附近采样,可以考虑对这张图片加噪音,较常见的方法是将一张图片分块,每次仅用几块,也就是一张图片的一部分进行需要被解释的模型的预测,并记录预测结果
- 使用LR进行上述图片的一部分的线性拟合,使其尽可能预测为黑盒的预测结果。在这里需要注意的是如果直接用图片输入给LR会导致参数量过多,因此往往会通过一个feature extractor进行特征提取后再交给LR预测
- 通过LR内训练得到的权重参数w,来确定对于黑盒而言,哪一部分是重要的,即解释黑盒是通过观察到什么而确定一张图片是青蛙的。
LIME的实验结果如下

30 Decision Tree(Explainable Machine Learning-8)
上述的LIME是用LR进行黑盒的解释的,其实还可以用更为强大的Decision Tree来做。

但通过Decision Tree进行黑盒解释时,可能会创造出参数量过多的一棵决策树,因此还需要考虑决策树的参数量。
有这样一种想法,在神经网络中不仅考虑目标函数的损失函数,也考虑到通过决策树拟合黑盒时决策树的参数量越少越好

那怎么确定神经网络转成决策树时,决策树的参数量会是多少呢?论文作者做出了一个神奇的神经网络转成决策树的决策树的参数量预测神经网络:),神经网络太强大了
神经网络转成决策树的决策树的参数量预测神经网络就是
输入:神经网络参数量
输出:转成决策树时的参数量(其实是决策树的平均深度)