AIstudio——李宏毅机器学习课程记录(一、机器学习介绍)
什么是机器学习?
人工智慧(目标):简单的定义,就是让机器拥有学习的能力。而其中的机器学习,就是实现人工智慧的手段;深度学习,则是机器学习的其中一种方法。
对于一款智能产品(比如聊天机器人),假设采用传统的特征定义的方法去创建,其设计结构可能是这样:
if (Human say "Please urn on the Music"):
turnOntheMusic();
这样设计的弊端是显而易见的:语言表达的复杂性,使得设计师很难枚举所有情况,且需要消耗大量人力和计算资源去枚举和实现所有情况。理想的设想,是让机器拥有自主学习、总结知识的能力。
返回到机器学习,正经一点的说法,我们希望机器能够找到一个函数(function),使得我们丢进去一个输入,能够得到期望的输出。例如,在影像识别中,我们给机器一张猫的图片,它的返回就是“猫”。如何实现?通过提供给机器的资料(data),让其自己学习其中的知识
怎么实现机器学习?
1.模型准备:function set,参数未确定的模型可以理解为待选模型的集合
2.模型评估:使用某些比较函数(也就是损失函数)来对比模型输出数值与真实值的偏差
3.模型求解:让模型“尽快”向理想模型的方向优化
以上提到的training data,其构成为(data, label);通过这种提供(数据,标签)的方式让机器去学习,称为supervised learning(监督学习)。就像(1+1, 2)、(2+3, 5);机器通过自主学习,当我们输入数据(15+5)的时候它就会给出相应结果了。结果对不对就看怎么训练了
机器学习的细分
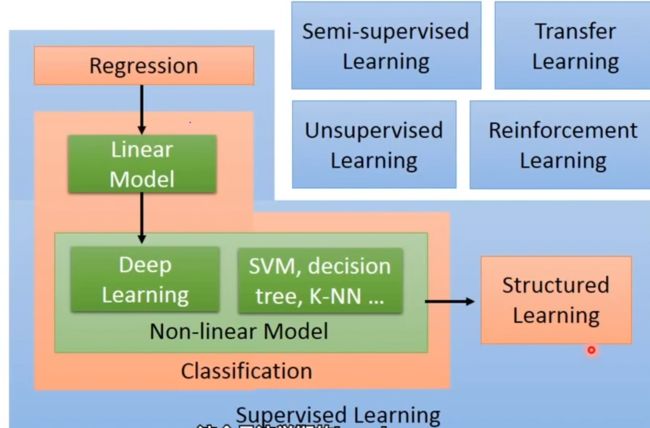
- regression:回归任务;输入多组已知数据,预测数据的未来变化。例:波士顿房价预测,根据已有资料预测未来房价
- classification:分类任务。根据要求的不同,又有二分类(垃圾邮件的判定)、多分类任务(动物识别)等等
- linear model:线性模型。
在实际环境中,我们可能会面临一个问题:对于监督学习,可能没有足够的数据让我们去训练得到比较理想的模型。一种解决思路,就是使用semi-supervised learning(半监督学习)的技术;另一个角度,就是使用transfer learning(迁移学习)。关于这两种技术的详细特点在之后进行阐述。
reinforcement learning(强化学习):如果说监督学习是learning from teacher,那么强化学习就是learning from critics,从评价中学习;机器并不知道具体哪个步骤表现的怎么样,只知道自己整体表现是“好”还是“不好”,并且还得自己去优化表现。
回归任务
下面用一个例子来简述完成回归任务的步骤
任务:预测宝可梦的CP值。通过预测宝可梦进化后的CP值,来判断这只宝可梦是否具有进化价值,节省资源。
对 于 这 个 任 务 , 输 入 就 是 : 宝 可 梦 的 各 种 信 息 ; x = ( x s , x c p , . . . ) 而 输 出 就 是 进 化 后 的 C P 值 , 属 于 标 量 s c a l a r 对于这个任务,输入就是:宝可梦的各种信息;x = (x_s,x_{cp},...) \\ 而输出就是进化后的CP值,属于标量scalar 对于这个任务,输入就是:宝可梦的各种信息;x=(xs,xcp,...)而输出就是进化后的CP值,属于标量scalar
第一步:模型准备。对于这个例子,假定输入输出之间关系为某种线性关系,则假设模型为:
y = w ⋅ x c p + b y=w·x_{cp}+b y=w⋅xcp+b
这样子的model称为linear model(线性模型)。其中w和b可以是任何数值。要注意的是,w和b的选取在理论上是任意的,但是实际问题中选取要符合客观变化规律(预测出来的PC值比进化前更低显然不合理)。
线性模型通用的写法为:
y = b + ∑ w i x i x i : 输 入 的 f e a r u r e ( 特 征 ) , 比 如 宝 可 梦 的 名 字 , 身 高 , 体 重 , 进 化 前 C P 值 . . . w i , b : w e i g h t ( 权 重 ) 、 b i a s ( 偏 置 ) y=b+\sum w_ix_i \\ x_i:输入的fearure(特征),比如宝可梦的名字,身高,体重,进化前CP值... \\ w_i,b:weight(权重)、bias(偏置) y=b+∑wixixi:输入的fearure(特征),比如宝可梦的名字,身高,体重,进化前CP值...wi,b:weight(权重)、bias(偏置)
第二步:模型评估。有了模型集合,还需要用训练数据来调整模型中的参数。
假设手中有10个宝可梦,他们的数据类型(简化后)为:
( x 1 , y ^ 1 ) 、 ( x 2 , y ^ 2 ) 、 . . . ( x 1 0 , y ^ 1 0 ) x : 宝 可 梦 进 化 前 的 C P 值 ; y ^ : 进 化 后 的 C P 值 (x^1, \hat y^1)、(x^2, \hat y^2)、...(x^10, \hat y^10) \\ x:宝可梦进化前的CP值;\hat y:进化后的CP值 (x1,y^1)、(x2,y^2)、...(x10,y^10)x:宝可梦进化前的CP值;y^:进化后的CP值
在坐标系中表示出来:

有了训练数据,还需要告诉模型输出的好坏
定义模型性能的函数称为L --> loss function(损失函数)。其输入:模型;输出:一个数值,用数值的大小来形容模型的性能。
也可以这么理解:
L ( f ) = L ( w , b ) = ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p n ) ) 2 L(f)=L(w,b)=\sum _{n=1}^{10}(\hat y^n-(b+w·x_{cp}^n))^2 L(f)=L(w,b)=n=1∑10(y^n−(b+w⋅xcpn))2
显然,预测值与真实值的差距越大,损失函数的输出就会越大,也就证明模型的性能越不好。
第三步:找到性能最好的模型
对于“寻找”最佳模型这一过程,要考虑的不仅仅是性能能有多接近理想模型,还要考虑如何尽快地逼近理想模型。理由很简单,即使上述模型只有两个参数w和b,如果采用遍历解法的话可能得等到猴年马月才能找到目标参数。
此时,梯度下降法(gradient descent)的使用会大幅提高求解效率,能够更快找到目标参数。当然,要求模型函数是可微分的
梯度下降法
1. 随 机 选 取 初 始 参 数 ( w 0 ) 2. 计 算 w = w 0 时 参 数 w 对 损 失 函 数 的 微 分 ( 也 就 是 这 一 点 在 函 数 上 的 切 线 斜 率 ) 3. 根 据 斜 率 更 改 w 的 值 : w n = w n − 1 − α d L d W ( 斜 率 体 现 了 函 数 值 的 变 化 , 目 标 是 让 函 数 值 达 到 最 小 ) 式 中 , α 为 参 数 更 新 幅 度 ( 学 习 率 , l e a r n i n g r a t e ) 。 多 个 参 数 的 线 性 模 型 推 导 同 理 1.随机选取初始参数(w_0) \\ 2.计算w=w_0时参数w对损失函数的微分(也就是这一点在函数上的切线斜率) \\ 3.根据斜率更改w的值:w_n=w_{n-1}-α\frac{dL}{dW}(斜率体现了函数值的变化,目标是让函数值达到最小) \\ 式中,α为参数更新幅度(学习率,learning rate)。多个参数的线性模型推导同理 1.随机选取初始参数(w0)2.计算w=w0时参数w对损失函数的微分(也就是这一点在函数上的切线斜率)3.根据斜率更改w的值:wn=wn−1−αdWdL(斜率体现了函数值的变化,目标是让函数值达到最小)式中,α为参数更新幅度(学习率,learningrate)。多个参数的线性模型推导同理
经过多次迭代后,w会不再更新,这就意味着微分=0,达到了loss函数的极小值点。这里选取的均方差损失函数为凸函数,这就意味着它不存在局部最优解,所以无需担心会出现极小值≠最小值的情况。
现在假定已经拥有了最优解:w=2.7,b=-188.4,将其绘制成图形:
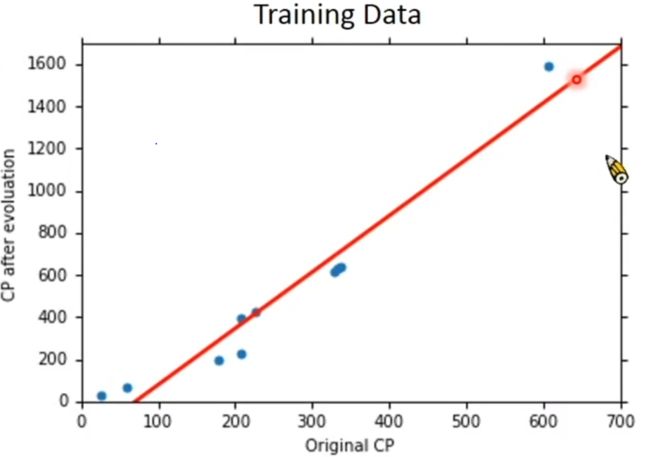
看得出来,模型不一定能正确预测所有的CP值,但我们关心的是模型在面对新数据时的正确率。用新数据(测试数据,testing data)对模型进行检测得到:
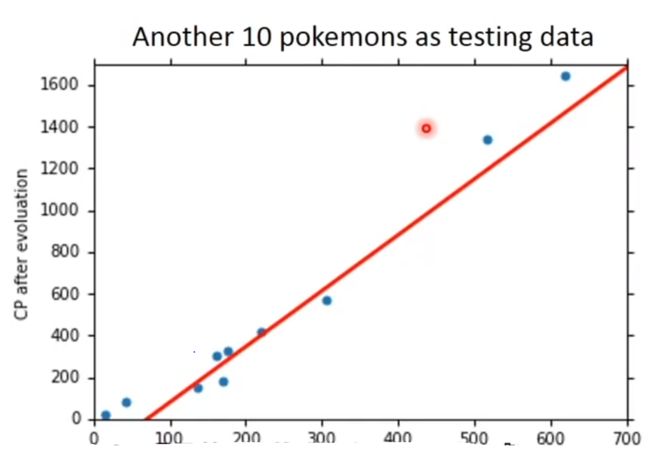
如果想要得到误差更小的模型,就需要对模型进行结构优化了。重新设计一个模型,让它长这样
y = w 1 ⋅ x c p + w 2 ⋅ ( x c p ) 2 + b y=w_1·x_{cp}+w_2·(x_{cp})^2+b y=w1⋅xcp+w2⋅(xcp)2+b
然后用刚才提到的方式去更新模型参数,再绘制图形:
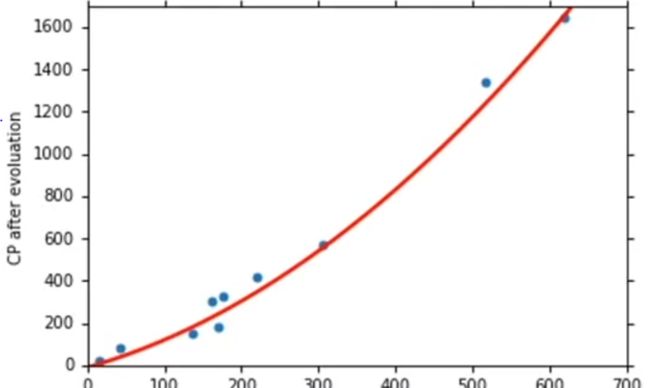
对比之下,模型对测试数据的拟合程度提高了,也可以说模型的错误率下降了。如果还想要进一步提升正确率,就要考虑更加设计的模型结构了。但是值得注意的是,越复杂的模型效果不一定越好,有时也会出现模型在训练数据上表现优异,而在测试数据上表现差劲的情况;这种情况就是过拟合(overfitting)。打个比方,就像一个学生只会死读书,对知识死记硬背而不理解背后的知识点,在面对不同问法的题目时是难以做到正确应答的。
宝可梦属性对其PC值的影响,不仅有身高体重带来的影响,不同种类的宝可梦CP值变化规律也是不一样的。对模型进行改写:
y = b 1 ⋅ δ ( x s = x 1 ) + w 1 ⋅ δ ( x s = x 1 ) x c p + b 2 ⋅ δ ( x s = x 2 ) + w 1 ⋅ δ ( x s = x 2 ) x c p + b 3 ⋅ δ ( x s = x 3 ) + w 1 ⋅ δ ( x s = x 3 ) x c p + b 4 ⋅ δ ( x s = x 4 ) + w 1 ⋅ δ ( x s = x 4 ) x c p + . . . 其 中 δ = { = 1 , i f x s = x 1 = 0 o t h e r w i s e δ 的 作 用 是 降 低 其 它 种 类 的 宝 可 梦 在 训 练 中 的 权 重 , 使 得 模 型 更 加 专 注 于 单 一 种 类 宝 可 梦 的 规 律 学 习 y=b_1·δ(x_s=x_1)+w_1·δ(x_s=x_1)x_{cp} + \\ b_2·δ(x_s=x_2)+w_1·δ(x_s=x_2)x_{cp} + \\ b_3·δ(x_s=x_3)+w_1·δ(x_s=x_3)x_{cp} + \\ b_4·δ(x_s=x_4)+w_1·δ(x_s=x_4)x_{cp} + ... \\ 其中δ=\begin{cases} =1,if\quad x_s=x_1 \\ =0 otherwise \end{cases} \\ δ的作用是降低其它种类的宝可梦在训练中的权重,使得模型更加专注于单一种类宝可梦的规律学习 y=b1⋅δ(xs=x1)+w1⋅δ(xs=x1)xcp+b2⋅δ(xs=x2)+w1⋅δ(xs=x2)xcp+b3⋅δ(xs=x3)+w1⋅δ(xs=x3)xcp+b4⋅δ(xs=x4)+w1⋅δ(xs=x4)xcp+...其中δ={=1,ifxs=x1=0otherwiseδ的作用是降低其它种类的宝可梦在训练中的权重,使得模型更加专注于单一种类宝可梦的规律学习

结论就是,尽可能地多考虑更多的参数,可能会对模型优化有积极的效果。
另一方面,也可以选择对损失函数重构来评价模型的优劣,比如正则化。重构后表达式为:
L = ∑ n ( y ^ n − ( b + ∑ w y x i ) ) 2 + λ ∑ ( w i ) 2 L=\sum_n(\hat y^n-(b+\sum w_yx_i))^2+λ\sum(w_i)^2 L=n∑(y^n−(b+∑wyxi))2+λ∑(wi)2
L越小表示模型的性能越好,也就是wi越小越好,因为越小的参数代表着模型比较“平滑”,也就是大变化的输入不是很敏感。假设输入的数据有噪音干扰,此时“平滑”的模型会受到更小的影响。当然了,太过“平滑”的模型也是不可取的,因此这意味着参数w过小,模型比较接近线性,对于数据的拟合也会不尽人意的。可见,λ的取值也需要适可而止。