数栈产品分享:Kafka—实时离不开的那个TA

一、前言
随着技术不断的成熟及市场需求的日益旺盛,实时开发已经成为当前大数据开发不可或缺的一部分。在整个实时开发的链路中,数据采集需要写入到Kafka,数据处理也需要使用到Kafka。今天我们就针对Kafka这个时下主流的消息中间件进行简单的介绍。
二、消息队列:数据流的归宿
在实时开发的场景中,来源于各类行为、事件的数据是随着发生时间源源不断如同河流一般进入实时任务并不断产出结果的。传统的异构数据源,数据以结构化的形式存储在对应的库表内。那么除了数据本身包含的业务时间属性,要如何找到一个稳定的时间维度来描述这些数据的先后呢?又要将流式的数据放在哪里去进行处理?
消息队列就是为了应对大量数据需要传递、分析场景所涉及的。
目前消息队列的方式分为以下两种:
- 点对点(point to point,queue):消息被任一消费者消费后即消失在点对点系统中,消息被保留在队列中,一个或多个消费者可以消耗队列中的消息,但是特定消息只能由最多一个消费者消费,一旦消费者读取队列中的消息,它就从该队列中消失。
- 发布-订阅(publish/subscribe,topic):消息可被所有订阅者(组)消费在发布-订阅系统中,消息生产者称为发布者,消息消费者称为订阅者。发布者发布的消息被保留在 Topic 中,与点对点系统不同,消费组可以订阅一个或多个主题并使用该主题中的所有消息,同样,所有发布到Topic的消息均可被所有订阅组消费。一个订阅组内可能包含多个订阅者。
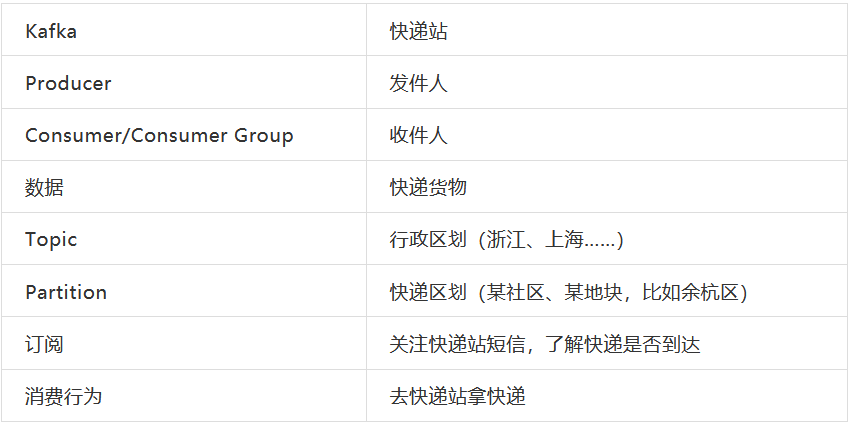
为了更好的理解消息队列的运作方式,我们先设想如下一个场景:数据是一份快递,数据在不同开发环节之间的流转就是快递的配送过程。
1、电视购物:上门配送,客户签收
在10年前电视购物还比较盛行的时代,多数货物是通过邮政等快递公司进行上门配送,往往快递员上门后,会让客户在运单上签字验收。这时候的快递员,只有每一份快递被客户签字验收后,才会再开始下一件货品的运输(此为极端情况下的举例)。
当一个客户存在多个快递,并且多个快递是陆续到达的时候,就会出现快递员配送-等待签收-客户签收-快递员回到收发点发现新的快递-快递员配送这样一个反复链路,如果存在客户反应慢,签字速度慢的情况,则会花费更多时间。
同样,在传统的数据开发场景中,数据传输也遵循这样的规律。上下游的两个服务之间对数据进行传输等同于快递配送的过程,如果一次数据传输需要等到下游服务给到的回执来保证数据正常写入,再开始下一次的进行,那么下游服务处理速度及响应速度会严重影响这一环节的数据从而导致数据延迟;如果整条数据传输的链路包含了多个这样的进程,整体数据的时效性就无法得到保证。
2、快递物流:统一快递站
随着网络购物的不断发展,为了提高效率,现在的货物配送方式发生了极大的改变。现在快递员从收发点拣货出发,将快递配送至相应地区的快递站,由快递站替实际用户进行一次代理签收,此时视作快递配送的过程已经完成。快递员就可以快速回到拣货点,后续快递站会以各类形式通知到具体的用户,有相应的快递需要签收,在“某某时间点”前来到快递点拿取。对于用户而言,它只需要持续关注快递站的状态(订阅),当有快递时,及时去取就可以。
当我们熟悉了快递从仓库中存储到配送到收件人手中的流转过程时,我们就能够理解消息中间件是如何在实时开发的过程中运作的。那么在多种消息中间件中,目前应用最广泛的就属Apache Kafka。
三、Kafka:消息中间件
Apache Kafka是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,用于实时处理大量数据,常用于大数据,数据挖掘等场景。
Kafka中经常会涉及到如下基本概念:
- Zookeeper:用于将独立的Broker配置成Kafka集群;
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为Broker;
- Topic:Kafka中的消息主题,类似于Table的概念,用于区分不同消息;
- Partition:Topic分区,每个topic可以有多个分区,分区的作用是方便拓展,提高并发。
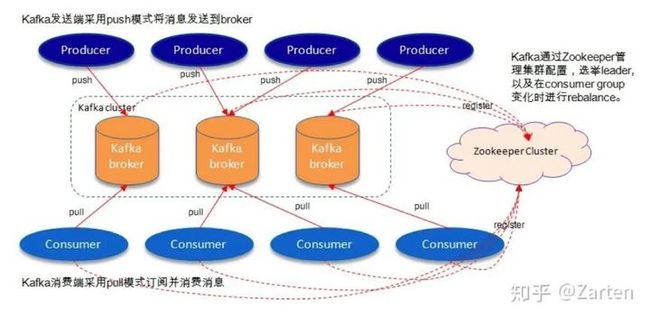
为了便于理解,我们可以简单的将Kafka与快递过程进行类比如下:
1、数据写入
1)确定Topic及Partition
一个Topic下可能存在多个Partition,在向Kafka写入数据时需要先确定Topic及对应的Partition。
2)找到Partition通信地址
由于Kafka实现了高可用,确定写入Partition后,Producer会从ZK中获取到对应Partition的Leader并与其通信。
3)数据传输
- Leader接收到Producer的信息并写入本地Log
- 其他Follower从Leader Pull信息,并写入本地log,完成后向Leader发送ACK
- Leader接收到所有Follower信息,并设置一个HW(High Watermark),然后向Producer发送ACK

2、消费方式及分配策略
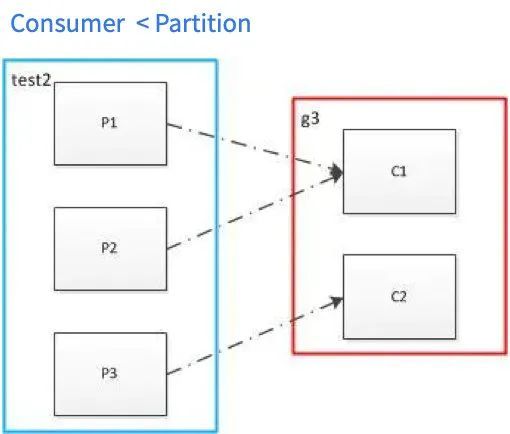
实际消费数据时Kafka中的消费者——Consumer会以Consumer Group的形式与Topic交互并分配对应的Partition。在消费过程中一个Group内的数据不重复,但多个Group之间的数据可重复消费,这也是发布-订阅制的特点。
开发人员可以利用这一特点实现在不影响主业务流程的情况下,对业务数据进行实时监控等。

一个Group中包含至少有一个Consumer,一个Topic下也至少包含一个Partiton。一个Consumer Group中的多个Consumer可以并行消费不同的Partition,以此来提高对Kafka数据消费的并行度,从而提高数据处理的速度。但是在消费的过程中,针对于Partition和Consumer数量的不同,会出现各种情况,Kafka针对于不同的情况有相应的分配策略,可参考如下:

四、实时开发如何使用Kafka
在实际生产中,实时开发也是以一个消费者组或生产者组的方式去Kafka中消费相应的数据。
在实时采集任务过程中,采集数据源的数据到Kafka,通过设置不同的写入并发数,可以设置多个Producer向同一个Topic下进行数据写入,提高并发度和数据读取效率;同样,当采集Kafka数据源时,通过设置不同的读取并发数,可以在一个Group内设置多个Consumer同时对Topic内的数据进行消费。
在实时开发任务中,也可以设置Kafka数据源的并行度,从而根据实际业务需求调整并行度来满足消费需求。
五、结语
通过今天的介绍,我们了解到Kafka作为典型“发布-订阅”形式的消息队列如何通过帮助用户临时存储流式数据,并通过Consumer Group和Partition的机制实现多并发的读写以提高实时开发相关的效率。后续我们还会继续介绍跟实时开发相关的内容,敬请期待。
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx