基于FPGA的嵌入式图像处理笔记——流水线处理(以原理图的形式来分析RGB到Ycbcr的灰度转换)
文章目录
- 什么是流水线结构
- 流水线结构的实质
- 使用流水线结构的优缺点
- 流水线结构的图解
- 流水线的时序调整
- 流水线进行颜色空间转换的计算
-
- RGB888 转 YCbCr
- 总体verilog代码
- RTL图
什么是流水线结构
流水线结构是把一个大的逻辑拆分成多个小逻辑,或者说将原本只需要一个时钟周期完成的逻辑操作分成用多个时钟周期来实现,以减少每个时钟周期的传播延迟。由于每个小逻辑的计算花费的时间较小,从而能使得设计的时钟速率加快。
同时分成几个时钟周期完成就成为几级流水线。
比如说 d = a*b+c,即可分成两级流水线来进行。在加法和乘法之间加入寄存器,第一个时钟周期计算乘法,第二个时钟周期来计算加法。
如下图所示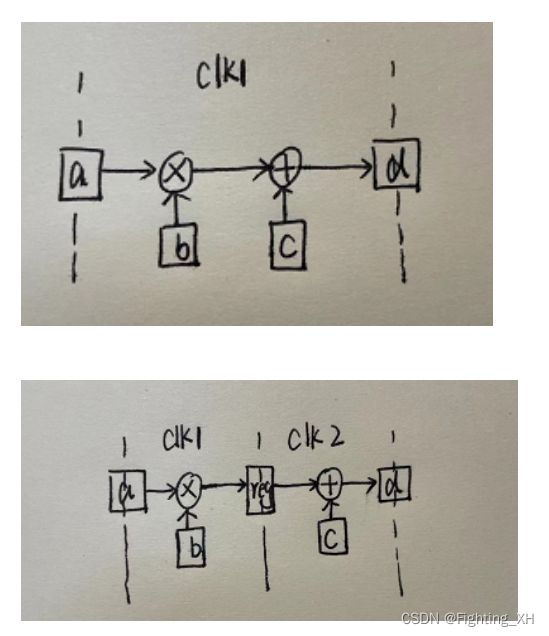
流水线结构的实质
首先流水线结构是将一个大操作分成更多的小操作。
那如何分成小的操作呢?就需要我们在各个计算之间插入寄存器,通过寄存器来暂存中间数据,尽管寄存器也会引入额外的小延迟,但相当于传播延迟来说可忽略。
使用流水线结构的优缺点
- 流水线结构缩短了一个时钟周期内的数据路径,能让吞吐量随着时钟速率的增高而增加。——比如说未采用流水线的逻辑计算总延迟为2Tpd,同时该逻辑计算需要在一个clk内完成,那么该时钟就受限于2Tpd,如果采用了两级流水线,总计算时间=Tpd+Tco+Tpd,多了额外很小的寄存器延迟(Tco),但是其需要在两个时钟周期内完成,那么一个时钟周期 = (Tpd+Treg+Tpd) /2 ,很明显时钟频率提高,从而使得计算加快。
如下是吞吐率的计算:
操作数*最大工作时钟频率。
若采用50MHZ的时钟周期来完成一个大操作,那么吞吐率=150 = 50MHZ
如果将一个大操作分成5个小操作,其时钟周期也是50MHZ,那么吞吐率=550=250MHZ
通俗的例子:传统操作中,假如一个流程需要三步完成,比如说生产一瓶药,一个人负责需要装药,一个人负责封装,一个人负责检查。每一步都需要花费一分钟,那么每个生产出一瓶药就需要3分钟,同时如果当一瓶药检查合格后,才能进入下一瓶的生产,那么当一个员工工作的时候,另外两个员工就需要等待,这就出现了劳动力浪费。因此采用流水线的方式,每个时间段,每个工人都在完成自己的任务,上一个工人的输出,就是下一个工人的输入,由此,第一次生产出来一瓶药同样还需要三分钟,而从第二轮开始,每一分钟即可生产出一瓶药,从而使得效率提高了三倍。
- 由于在各级之间插入了寄存器,因此就会消耗更多的资源和面积,最终也是以面积来换取速度。
流水线结构的图解
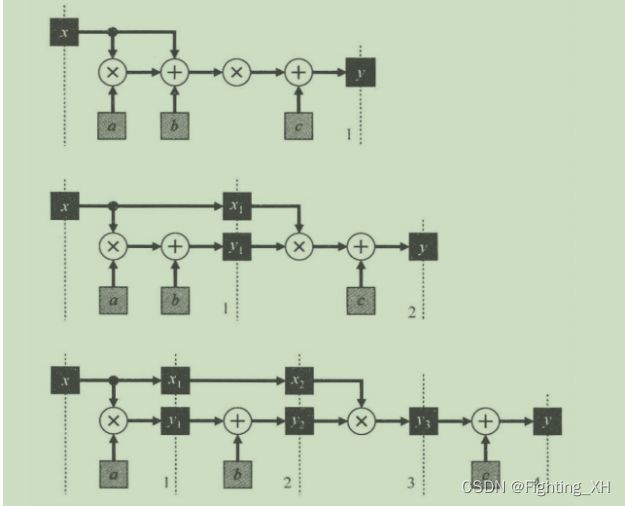
如下为简单流水线的例子:
第一个:一个简单的逻辑操作,且在一个时钟周期内完成运算
第二个:两级流水线操作,在两级中插入寄存器,从而将一个逻辑操作分成两个时钟周期来计算。
第三个:四级流水线,同理各部分分级之间分别插入寄存器,从而将一个逻辑操作分成四个时钟周期来完成。
流水线的时序调整
由于采用流水线结构后,原本花费一个clk完成的操作,现在需要3个clk来完成,因此为保证对应输出接收到正确的数据,那么输出也应该往后推迟3个时钟周期。所以采用流水线技术时,必须要进行时序调整。
流水线进行颜色空间转换的计算
RGB888 转 YCbCr
学习颜色格式的转换
如下是RGB565到RGB888的转化原理:

这里以咸鱼FPGA的 RGB888转 YCbCr例子。如下是颜色转换公式,由于FPGA不擅长处理浮点数,因此先进行了256倍的扩大,最终在缩小256倍数即可。
上述公式可看出,我们可以对Y,Cb,Cr操作进行拆分,采用三级流水线,一级流水线进行乘法操作,二级流水线进行加减法操作,三级流水线进行移位操作。同时由于Y,Cb,Cr的计算都是一样的加法和乘法,因此我们使用流水线的同时,还需利用FPGA的并行计算能力来处理。不过此处以流水线结构为重点,这里仅对Y进行分析,下面是对上述公式的流水线图解:
对于Y不采用流水线:
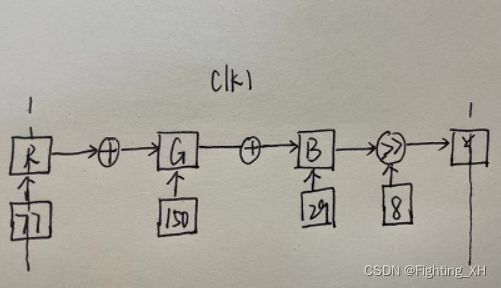
对于Y采用流水线:
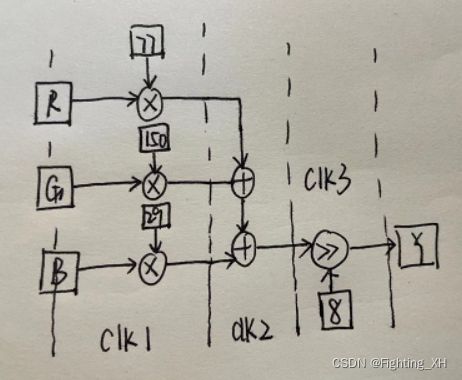
由于Cr和Cb中,还有常数的加法,因此下面对Cr进行图解:
由此可以自己根据Cb进行画图分析。
至此,我们即可采用流水线以及并行的方式,进行如下的verilog编写,来实现RGB到 YCbCr的转换。
第一级流水线+并行处理:clk 1来完成所有的乘法计算。
always @(posedge clk or negedge rst_n) begin
if(!rst_n)begin
{R1,G1,B1} <= {16'd0, 16'd0, 16'd0};
{R2,G2,B2} <= {16'd0, 16'd0, 16'd0};
{R3,G3,B3} <= {16'd0, 16'd0, 16'd0};
end
else begin
{R1,G1,B1} <= { {R0 * 16'd77}, {G0 * 16'd150}, {B0 * 16'd29 } };
{R2,G2,B2} <= { {R0 * 16'd43}, {G0 * 16'd85}, {B0 * 16'd128} };
{R3,G3,B3} <= { {R0 * 16'd128}, {G0 * 16'd107}, {B0 * 16'd21 } };
end
end
第二级流水线+并行处理:clk 2来完成所有的加减法
always @(posedge clk or negedge rst_n) begin
if(!rst_n)begin
Y1 <= 16'd0;
Cb1 <= 16'd0;
Cr1 <= 16'd0;
end
else begin
Y1 <= R1 + G1 + B1;
Cb1 <= B2 - R2 - G2 + 16'd32768; //128扩大256倍
Cr1 <= R3 - G3 - B3 + 16'd32768; //128扩大256倍
end
end
第三级流水线+并行计算:clk3来完成所有的移位操作。除以256,相当于右移8位,因此取高八位即可。
always @(posedge clk or negedge rst_n) begin
if(!rst_n)begin
Y2 <= 8'd0;
Cb2 <= 8'd0;
Cr2 <= 8'd0;
end
else begin
Y2 <= Y1[15:8];
Cb2 <= Cb1[15:8];
Cr2 <= Cr1[15:8];
end
end
另外还涉及到流水线时序调整的问题,由于RGB到Ycbcr的转换是进行图像数据的处理,并最终显示在显示屏上,因此显示要与数据的输出同步,由于计算转换后得到的输出数据花费了三个clk。那么对于显示驱动来说,其中的数据使能信号,行同步信号和帧同步信号应该延迟三个clk,才能保证输出数据的正确接收,因此延迟如下:
//信号同步,保证输出显示可正确接收到数据
//RGB_de,RGB_hsync,RGB_vsync为原本的数据使能信号,行同步信号和帧同步信号
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
RGB_de_r <= 3'b0;
RGB_hsync_r <= 3'b0;
RGB_vsync_r <= 3'b0;
end
else begin //三个clk的延迟操作
RGB_de_r <= {RGB_de_r[1:0], RGB_de};
RGB_hsync_r <= {RGB_hsync_r[1:0], RGB_hsync};
RGB_vsync_r <= {RGB_vsync_r[1:0], RGB_vsync};
end
end
//延迟三个clk的的数据使能信号,行同步信号和帧同步信号
assign gray_de = RGB_de_r[2];
assign gray_hsync = RGB_hsync_r[2];
assign gray_vsync = RGB_vsync_r[2];
总体verilog代码
//RGB888——Ycbcr的转换
//我们在进行图像处理的时候,图像均是RGB565,并设该信号为16位的VGA_RGB,因此首先需要进行RGB565到RGB888的转化,然后根据RGB888进行Ycbcr转化
//转化后只取Y通道,然后进行888到565的转化
module Ycbcr(
input clk,
input rst_n,
input [15:0]VGA_RGB,
input wire VGA_blank,
input wire VGA_hsync,
input wire VGA_vsync,
output wire Y_blank,
output wire Y_hsync,
output wire Y_vsync,
output[7:0] Y
);
reg [15:0] R1,G1,B1;
reg [15:0] R2,G2,B2;
reg [15:0] R3,G3,B3;
reg [15:0] Y1 ;
reg [15:0] Cb1;
reg [15:0] Cr1;
reg [7:0] Y2 ;
reg [7:0] Cb2;
reg [7:0] Cr2;
reg [2:0] RGB_blank;
reg [2:0] RGB_hsync;
reg [2:0] RGB_vsync;
wire [7:0] R;
wire [7:0] G;
wire [7:0] B;
//低位补 0 或继续补充原通道的低位
assign R = {VGA_RGB[15:11],3'b0};
assign G = {VGA_RGB[10:5],VGA_RGB[6:5]};
assign B = {VGA_RGB[4:0],VGA_RGB[2:0]};
//第一级流水线,进行所有的乘法计算
always @(posedge clk or negedge rst_n)begin
if (!rst_n)begin
{R1,G1,B1} <= {16'd0,16'd0,16'd0};
{R2,G2,B2} <= {16'd0,16'd0,16'd0};
{R3,G3,B3} <= {16'd0,16'd0,16'd0};
end
else begin
{R1,G1,B1} <= {{R*16'd77},{G*16'd150},{B*16'd29}};
{R2,G2,B2} <= {{R*16'd43},{G*16'd85},{B*16'd128}};
{R3,G3,B3} <= {{R*16'd128},{G*16'd107},{B*16'd21}};
end
end
//第二级流水线,进行所有的加法计算
always @(posedge clk or negedge rst_n)begin
if (!rst_n) begin
Y1 <= 16'd0;
Cb1 <= 16'd0;
Cr1 <= 16'd0;
end
else begin
Y1 <= R1+G1+B1;
Cb1 <= B2-R2-G2+16'd32768;
Cr1 <= R3-G3-B3+16'd32768;
end
end
//第三级流水线,进行所有的移位操作
always @(posedge clk or negedge rst_n)begin
if (!rst_n)begin
Y2 <= 8'd0;
Cb2 <= 8'd0;
Cr2 <= 8'd0;
end
else begin
Y2 <= Y1 [15:8];
Cb2 <= Cb1[15:8];
Cr2 <= Cr1[15:8];
end
end
//此时得到了8位的Y2Crb2Cr2,然后取Y通道的8位数据,进行565的转化
assign Y = {Y2[7:3],Y2[7:2],Y2[7:3]};
//至此完成了该颜色空间的转化,对于流水线时序问题,我们需要进行VGA驱动模块的相应信号延迟。
//信号与输出数据同步
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
RGB_blank <= 3'b0;
RGB_hsync <= 3'b0;
RGB_vsync <= 3'b0;
end
else begin
RGB_blank <= {RGB_blank[1:0], VGA_blank};
RGB_hsync <= {RGB_hsync[1:0], VGA_hsync};
RGB_vsync <= {RGB_vsync[1:0], VGA_vsync};
end
end
assign Y_blank = RGB_blank[2];
assign Y_hsync = RGB_hsync[2];
assign Y_vsync = RGB_vsync[2];
endmodule
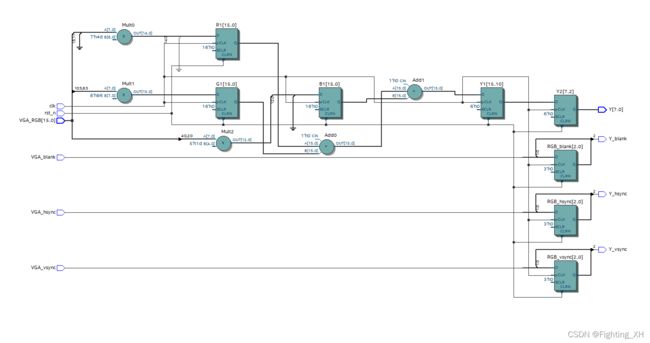
RTL图
由于最后只取Y分量进行拼成RGB565,因此下面的RTL图也仅仅显示Y分量的部分。
首先不分析与输出数据同步的信号,则Ycbcr的Y部分的信号包括 :
R1,G1,B1 ——乘法运算得到的
Y1 —— 加法运算得到的
Y2——移位操作得到的
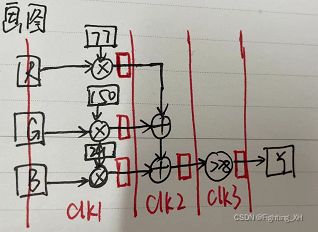
因为采用了流水线的方式,因此各级之间均插入了寄存器来暂存中间数据。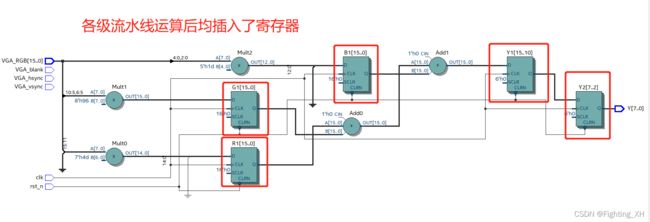
和我们之前的原理图分析是一样的。如下图红色框就表示我们上面的寄存器
如下是加入了流水线时序调整的RTL图,为让图像可正确显示,因此需要讲输出数据与VGA的驱动信号同步: