目标检测—R-CNN、Fast R-CNN和Faster R-CNN
目标检测
- 1. 基本介绍
- 2. 目标检测网络
-
- 2.1 R-CNN
- 2.2 Fast R-CNN
- 2.3 Faster R-CNN
- 3. 结尾
- 参考文献
1. 基本介绍
本讲进入到深度学习的应用方面,前面提到的卷积神经网络被用作图像分类识别,即输入一张图像,输出它的类别。在实际应用中,我们更有可能遇到的是如下几种将检测、分割与识别综合处理的情形。

第一种情形,单目标检测中的目标定位与识别,即图像中有一个目标,我们需要检测出它的位置,同时识别出它的类别。
第二种情形,多目标检测中的目标定位与识别,即图像中有多个目标,我们需要分别检测出它的位置,同时对每个目标都要进行识别。
第三种情形,语义分割,我们不仅要检测和识别出图像中的各种目标,还要确定每个目标所对应的像素。
这三种情形的难度是逐渐升级的,在本讲及以后的讲解中,我们将会讲到如何处理这三种情形的深度学习算法。
首先,我们针对第一种情形单目标定位与识别,这是目标检测与识别的最简单的情形,相比前面利用卷积神经网络做图像识别的例子,除了要识别目标的类别,我们还要找出目标的位置。
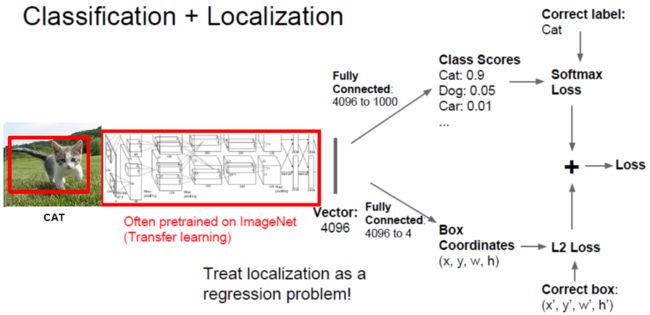
如上图2所示,我们可以采用最简单的方法,在网络的最后一层,增加4个维度的输出,分别代表目标所属方框的左上角坐标点 ( x , y ) (x, y) (x,y),方框的长和宽 ( h , w ) (h,w) (h,w)。当然,图像需要进行归一化,使得这四个坐标在不同的图像中具有等价的关系,然后,我们可以利用卷积神经网络直接获得识别结果。
接下来,我们来看第二种情形多目标检测中的目标定位与识别,即图像中有多个目标,我们需要分别检测出它的位置,同时对每个目标都要进行识别。这种情形相对复杂一些,关键的问题是我们不知道图像中有多少个目标,以及目标在哪里。如果我们在图像中找出一些区域,使得这些区域有且只有一个目标,那么问题便转化为第一种情形了。
2. 目标检测网络
2.1 R-CNN
在2014年,有研究者提出了R-CNN(Regions with CNN feature)的概念,用来处理上述情形。其核心思路是用大大小小的方框遍历所有的图像是不现实的,我们需要一个计算量不那么大的算法,提出ROI(Region of Proposal,or Proposal)。
R-CNN的主要思想是用 Selective Search 去产生候选的方框(Proposal),将这些候选方框输入到CNN中,最后用SVM来判断这些候选方框中有没有目标。
下面主要介绍提取图像候选区域的Region Proposals(Selective Search, SS)的算法。

给定一张图片(如上图3所示),首先利用Efficient Graph-BasedImage Segmentation算法,将图片进行过分割(Over-Segmentation)。过分割后每个region非常小,以此为基础,对相邻的region进行相似度的判断并融合,形成不同尺度下的region,每个region对应一个Bounding Box。以下是R-CNN的三个步骤:
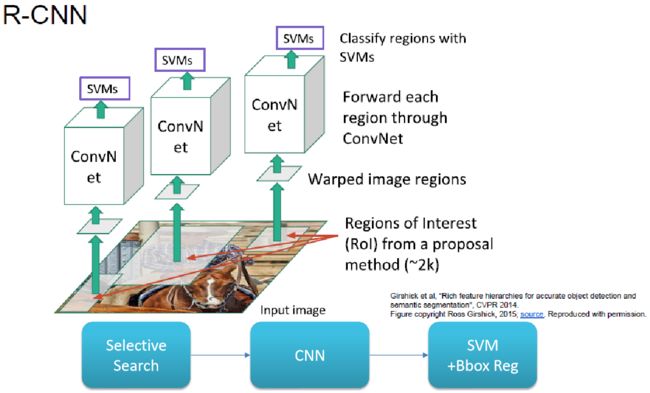
Step1: 利用Selective Search产生一些候选区域。
Step2: 对这些候选的区域进行长和宽的归一化后输入到CNN中,获得目标是别的结果。
Step3: 利用SVM对这些候选的区域来确定这些区域是存在目标还是不存在目标。
结合Step2和Step3就可以得到最终检测的结果。
R-CNN的算法虽然简单,但是有一个很大的缺点是计算消耗太大。例如对于每幅图像Selective Search耗时大约是5s左右,而Selective Search会产生2000个左右的候选区域,每个候选区域都要送到CNN中获得结果,同时每个结果都需要SVM去判断是否存在目标。因此,R-CNN处理一幅图像的时间在1min这个量级,它远远不能满足实时性的需要。
2.2 Fast R-CNN
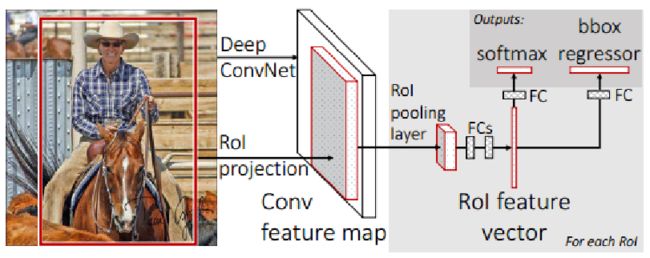
在2015年,Ross等人提出了Fast R-CNN,其主要的思想是利用ROI-Pooling来加速特征提取的过程。

例如在上面这幅图中,有很多候选区域,而这些候选区域存在非常多的重叠关系。如果把每一个候选区域归一化送入到CNN中,那么针对同一区域的卷积将会被重复的做很多次。因此,作者的基本想法是首先用CNN的卷积层对整幅图像进行卷积操作,在中间某一层的特征图上再用ROI-Pooling来归一化每个候选框区域的输出。这样只需要经过一轮卷积操作就能处理整幅图的所有候选区域,从而大大节约计算量。
下面将通过举例来介绍ROI-Pooling的过程。
如上图6所示,假如有2个候选区域,整幅图片经过CNN卷积后获得特征图。
假设在这个特征图上2个候选区域对应的感受野如图中的红色方框所示,大一点的候选区域感受野是8×8,小一点的候选区域感受野是4×4,下一步可以用ROI-Pooling来归一化。
- 例如对
8×8的候选区域,我们在4×4的范围内做MaxPooling,步长Stride=4,这样就获得2×2的特征图; - 对于
4×4的另外的候选区域,我们在2×2的范围内做MaxPooling,步长Stride=2,这样也可以获得2×2的特征图;
根据不同候选区域在某一层特征图上的感受野,成比例的利用MaxPooling,这样就可以将每个候选区域经过MaxPooling后获得的特征图在维度上变为一致。这些维度一致的特征图再通过后续的全连接层获得输出结果。
上图6说明了Fast R-CNN的原理,左边是对整张图做卷积操作,右边ROI-Pooling操作是针对所有候选区域的,最后系统输出仍然采用的是分类的SoftMax层加上四个坐标的回归。
2.3 Faster R-CNN
Fast R-CNN虽然解决了多个候选区域的输入CNN导致的计算耗时问题,但是它仍然需要耗费较多的时间产生候选区域。为了解决此问题,2015年提出的Faster R-CNN利用深度学习自动产生候选区域,更好地解决了多目标检测中的计算复杂度问题。
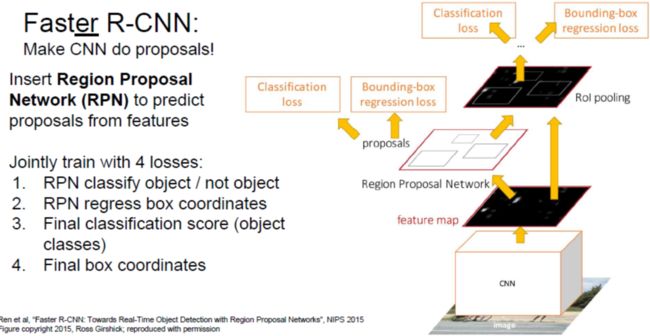
如下图7所示,Faster R-CNN在卷积后特征图上滑动窗口,用不同长宽比的矩形作为候选区域,用一个小网络来判断这些候选区域是不是存在目标,对于确定是目标的候选区域运用前面的ROI-Pooling来进行归一化,最终获得输出的结果。
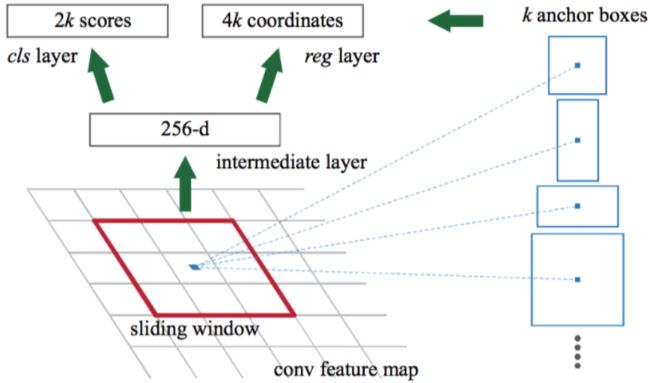
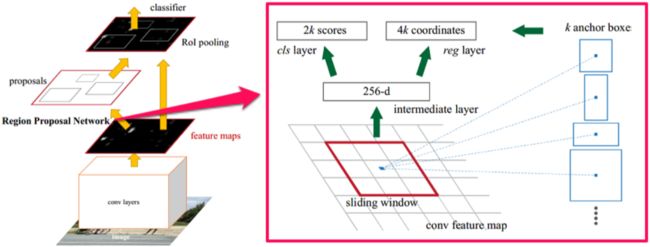
网络的局部结构如下图8所示。
下图9是R-CNN、Fast R-CNN和Faster R-CNN处理一幅图片的时间对比(单位:s)。
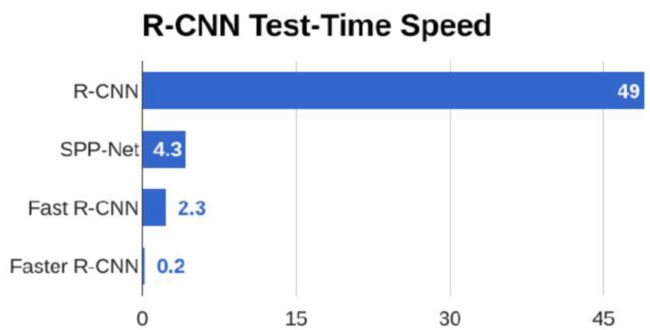
Faster R-CNN处理一幅图片仅需要0.2s的时间,它已经具备了实时处理图像的性能。
3. 结尾
在这一讲中,详细介绍了目标检测中常用的几个网络,它们分别是R-CNN、Fast R-CNN和Faster R-CNN,介绍了这三个网络的结构和设计思路。
通过这一讲的学习能够获得启发,这三个网络的发展充分说明某个研究领域的进步是不断递进的,后人的工作以前人的工作为基础不断突破,研究人员一起贡献聪明才智,共同推动科学研究向前发展。另一方面,科学研究并非高不可攀。例如最初的R-CNN的思路比较笨重,但是在2年的时间里却被改造得如此轻盈与实用,一些改造的方法,如Faster R-CNN中的ROI-Pooling的基本思想简单自然,这样的想法对于处在研究状态中的学者来说都是有可能想到的。
对本将内容感兴趣的读者,可以参考文后的相关论文,了解R-CNN、Fast R-CNN和Faster R-CNN的训练细节。例如如何进行数据的预处理、目标函数的设置、如何进行梯度反向传播等内容,加深理解。
参考文献
- 浙江大学《机器学习》课程—胡浩基老师主讲
- Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” CVPR. 2014.
- Girshick, Ross. “Fast r-cnn.” CVPR. 2015.
- Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” NIPS. 2015.