推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN...
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第1张图片](http://img.e-com-net.com/image/info8/cb80000590dd44e4a3336efef54b904b.jpg)
今天给大家介绍的是我们团队今年发表在WWW2022上的论文CrossDQN,提出了一种基于强化学习的信息流广告分配方法。这也是我个人在入职美团之后工作的主要方向。接下来我将对论文内容进行详细的介绍。
1、信息流广告分配背景
电商场景下的信息流通常包含两部分的内容,一类被称为自然结果,另一类是广告结果。二者以混合列表的形式展现给用户。如下图是工业界常见的混排系统的架构,广告和自然结果首先在各自的系统内进行排序,最后通过Blending Server决定广告的插入位置并展现给用户(在本文研究的混排方法中,Blending Server不会改变广告和自然结果内部的相对顺序,只决策广告插入的位置):
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第2张图片](http://img.e-com-net.com/image/info8/2a4e75fbedcd483e91b298d0c08aeba5.jpg)
基于展现给用户的混排列表,平台可以通过两个途径获取收入,一方面,当用户下单(无论自然结果还是广告结果)时,可以从中获取佣金;另一方面,当用户点击广告时,平台可以收取广告主的费用(一般为CPC计费)。由于广告的质量往往差于自然结果,过多的广告展示可能对用户体验有损,但过少的展示广告,则有可能对平台的收入有损,因此通常将广告的曝光占比控制在一定的范围之内。而本文研究的问题就是,在一定的曝光约束情况下,如何合理的进行广告位分配,能够使平台收入最大化,同时能够尽可能减少用户体验的损失。
当前的广告位分配方法主要可以分为两大类,固定位插入方法和动态位置插入方法。固定位的插入方法显然是一种次优的结果,不仅没有考虑用户个性化的信息,同时也容易被用户所跳过(用户容易感知广告的插入位置,每次浏览的时候进行跳过)。因此,近年来研究的重点,主要集中在动态位置插入的方法,如领英提出的基于RankScore的排序方法,以及字节提出的基于强化学习的方法Dear。
当前的动态位置插入方法,主要存在以下几方面的缺陷:
1)忽略了排序过程中相邻展示商家的相互影响,如领英的方法基于单位置决策,没有考虑已决策商家对于下文的影响。
2)在个性化和广告曝光占比之间缺少有效的平衡,如字节的Dear时四个位置插入一个广告或不插入,尽管可以控制广告曝光在1/4之下,但决策空间相对较小。
为了解决上述的问题,我们提出了一种基于强化学习的广告位置分配方法,称为Cross Deep Q Network (Cross DQN) 。接下来,对其框架进行详细介绍。
2、问题定义
首先来看一下美团外卖场景下广告分配的问题定义。在我们场景下,用户的一次访问定义为一个回合,我们顺序决策每屏K个位置的广告插入结果,由于存在广告曝光占比的约束,因此可以通过如下的CMDP过程进行定义:
状态空间S:状态包含了当前屏候选的广告结果和自然结果信息,用户信息和上下文信息
动作空间A:动作表示为在当前屏哪个位置插入广告,假设每屏决策5个位置,那么动作01001代表在本屏的第二个和第五个位置进行广告插入
即时奖励r:即时奖励包含了三部分,广告收入、佣金收入和用户体验评分,定义如下:
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第3张图片](http://img.e-com-net.com/image/info8/01d5b59051ab497fa82b76888ba313d5.jpg)
状态转移概率P:用户的行为影响状态转移,当在st采取了动作at之后,若用户下拉,则st转移到st+1,否则回合结束
折扣因子:折扣因子用于平衡短期收益和长期收益
约束条件C:约束条件主要为曝光占比约束,即一定时间范围内(一小时,一天等)的广告曝光占比PAE(percentage of ads exposed,简称PAE),需要保持在一定范围之内,来平衡收入和用户体验。PAE和约束条件的定义如下:
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第4张图片](http://img.e-com-net.com/image/info8/2a400368ea6c4c88897bb9f67e7137be.jpg)
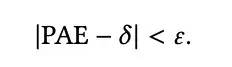
基于如上的问题定义,接下来,就来介绍CrossDQN的内容。
3、CrossDQN介绍
3.1 整体介绍
传统的DQN结构,如Dueling-DQN,以状态s作为输入,如下图左边的部分。这样的结构无法建模state和action的交叉信息,在我们场景下即无法建模相邻展示item的相互影响。那么,为了建模这种item的相互影响关系,我们提出了state和action的交叉(cross)思想,其主要思路是将候选的广告和自然队列基于候选的action进行拼接,得到action对应的商家的排列结果。举例来说,以每屏决策5个位置为例,假设候选广告队列为A1,A2,A3,A4,A5(只需要5个即可,因为最多插入五个广告,自然结果同理),候选自然结果队列为N1,N2,N3,N4,N5,若action为01001,则交叉后的商家排列顺序为N1,A1,N2,N3,A2,若action为00100,则交叉后的商家排列顺序为N1,N2,A1,N3,N4。
上述的交叉模块呢,我们称为State and Action Crossing Unit (SACU),除SACU外,我们还设计了Multi-Channel Attention Unit (MCAU),用于对展示商家的相互影响以及用户的不同特征偏好进行建模。模型的抽象结构如下图的右侧所示。
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第5张图片](http://img.e-com-net.com/image/info8/2fe47517066140ec91aaa1979766f0a5.jpg)
下图为CrossDQN的完整结构:
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第6张图片](http://img.e-com-net.com/image/info8/b71d6db117584cd7926604dd81c8bd36.jpg)
可以看到,整体的模型可以分为两大部分,分别是Item Representation Module (IRM)和Sequential Decision Module (SDM),IRM采用参数共享的方式,得到每个商家的压缩后的向量表示,SDM通过SACU、MCAU以及我们设计的batch粒度的曝光约束损失,完成个性化的广告位置决策。接下来,我们对每个模块进行详细介绍。
3.2 Item Representation Module
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第7张图片](http://img.e-com-net.com/image/info8/6fbc538a2de04fe59750f2355974e887.jpg)
IRM通过参数共享的方式,得到state中每个候选商家的embedding表示,对每个商家来说,输入包括用户特征,上下文特征,用户历史行为序列和候选商家特征,建模方式同DIN(公式可能符号定义比较复杂,从模型图看建模过程还是比较清晰的):
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第8张图片](http://img.e-com-net.com/image/info8/07d9cf7b9ebc4a858710ae5add75048c.jpg)
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第9张图片](http://img.e-com-net.com/image/info8/d6d76b836fde407d8f24cc5663c2d1ee.jpg)
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第10张图片](http://img.e-com-net.com/image/info8/66ba56cb41bd4661be7d11dc643f0ab6.jpg)
3.3 Sequential Decision Module
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第11张图片](http://img.e-com-net.com/image/info8/de138298929046c489a4ab324523f94f.jpg)
SDM为决策模块,基于计算的所有候选action的Q值,决策以何种广告位置展示给用户。主要包含SACU和MCAU两个模块,这也是本文的主要创新点所在。
3.3.1 SACU
SACU的基本思想在上文中已经介绍过了,具体的计算过程可以从如下的图中比较清晰的得到:
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第12张图片](http://img.e-com-net.com/image/info8/618a1b48833048bb98059aaa88a1f402.jpg)
这里简单介绍一下:
1)根据action得到广告和自然结果的偏置矩阵:若action为01001,代表广告的插入位置为2和5,那么1-action则代表自然结果的插入位置,即1-action=10110,那么基于这两个action,可以得到偏置矩阵,如图上的Mad和Moi
2)生成候选广告和自然结果的embedding矩阵,其实就是将IRM得到的结果进行reshape
3)交叉相乘并相加得到最终的结果,计作Mcross:

3.3.2 MCAU
MCAU用于建模相邻展示商家的相互影响,而基于SACU得到的结果使相互影响建模更加简便。
在实际点击或下单时,用户可能关注商家的某一方面或某几方面,如配送费、折扣、配送时间等等。若每个商家经过IRM得到的embedding表示长度为Ne,那么每一维度可以看做是信息的一种聚合方式,用户可能对不同的维度或维度组合有着不同的偏好。因此,我们通过多个通道,每个通道建模单一维度或维度组合的信息,这正是Multi-Channel的含义所在。
具体的,使用多组Mask,对SACU得到的交叉矩阵进行mask,再使用self-attention进行相互影响建模:
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第13张图片](http://img.e-com-net.com/image/info8/72abebdb5178455999fd938b9004b1c0.jpg)
MCAU模块的输出为各通道输出的拼接:
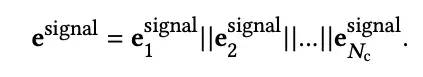
3.3.3 Q-Value
经过了SACU和MCAU,接下来就是Q-value的计算,我们采用Dueling-DQN的结构,因此Q-value包括状态价值V和优势函数A:
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第14张图片](http://img.e-com-net.com/image/info8/7bbc63607e29403a8aaaecdf669afb98.jpg)
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第15张图片](http://img.e-com-net.com/image/info8/9af5f8f3d4184f3b8d4a5d2c179c5f97.jpg)
3.4 Auxiliary Loss for Batch-level Constraint
接下来,我们要关注的问题是,如何保证广告曝光占比在一定的范围之内?由于强化学习训练的不稳定性,得到的不同模型在部署到线上时,对应的广告曝光占比可能差别非常大,总不能一个一个尝试。因此我们尝试将曝光占比损失融入到模型训练中。
一种简单的思路就是我们约束每个回合的曝光占比,那么所有回合的曝光占比也可以在我们要求的范围之内,但这种思路对于个性化的损失是非常大的。因此,这里我们提出了一种Batch粒度的损失函数,使用一个Batch的样本对应的广告曝光近似一段时间内所有请求的广告曝光占比。损失可以写作:
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第16张图片](http://img.e-com-net.com/image/info8/d996991cb81c4177af5af9f062212439.jpg)
上面的式子有两个问题值得讨论:
1)PAE是如何计算的,一种简单的方式是不考虑位置因素,那么01001和11000的曝光占比均为0.4,这种方式处理比较简单,但并不合理,理论上越靠前的位置具有更高的曝光概率,那么另一种方式就是给每一个位置赋予一定的权重,这样不同屏不同的广告位置分配,得到的曝光占比均是不同的。
2)上式中argmax是不可导的,如何将其变为可导的形式融入进模型训练?我们使用soft-argmax对argmax进行替换:
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第17张图片](http://img.e-com-net.com/image/info8/a58a7e13099b4edd8683cbe6714e6e83.jpg)
可以看到,本质是softmax,通过beta系数控制softmax的结果,如果beta越大,那么softmax的结果越接近于argmax,同时是一种可导的方式。
那么我们最终的损失包含两部分,一是基于贝尔曼方程的DQN损失,二是曝光约束损失:
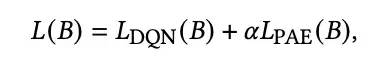
3.5 模型拆解和部署
到这里,模型部分的介绍就到这里了,那么你可能会有疑问,为什么我们的整体模型需要拆解为IRM和SDM两部分,IRM又为什么通过参数共享的方式进行计算。
这里主要是线上性能的考虑,广告位决策模块在精排之后,耗时有严格的限制,同时需要完成多次的顺序决策,因此我们把整个模型拆解为IRM和SDM两部分,并分开部署。IRM可以与精排并行计算,而SDM使用尽可能小的模型结构,完成多次决策,整个的线上部署架构如下图所示:
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第18张图片](http://img.e-com-net.com/image/info8/e49208c1a38447f784631054984197a6.jpg)
4、实验结果
最后简单看一下模型试验结果吧:
![推荐系统遇上深度学习(一三六)-[美团]基于强化学习的信息流广告分配方法CrossDQN..._第19张图片](http://img.e-com-net.com/image/info8/61fb5137a02a466999b0e324ecf03525.jpg)
效果还是比较不错的,同时整个的CrossDQN已经全量部署在美团外卖平台,取得了明显的收益提升。
好了,论文就介绍到这里,由于是自己团队的工作,也是介绍的尽可能详细,感兴趣的同学可以加我微信sxw2251,一起探讨交流~~