面试题笔记【一】
1、逻辑回归优缺点
优点:
(1)实现简单,广泛的应用于工业问题上;
(2)分类时计算量非常小,速度很快,存储资源低;
(3)便利的观测样本概率分数;
(4)对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决该问题;
(5)计算代价不高,易于理解和实现。
缺点:
(1)当特征空间很大时,逻辑回归的性能不是很好;
(2)容易欠拟合,一般准确度不太高;
(3)不能很好地处理大量多类特征或变量;
(4)只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
2、ROC、AUC
(FPR,TPR)
FPR=FP/(FP+TN) 表示所有反例中被预测为正例的比率
TPR=TP/(TP+FP) 表示所有正例中被预测为正例的比率
ROC(Receiver Operating Characteristic)曲线和AUC(Area Under Curve)常被用来评价一个二值分类器(binary classifier)的优劣。相比准确率、召回率、F-score这样的评价指标,ROC曲线有这样一个很好的特性:当测试集中正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
AUC被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。ROC曲线上的任意相邻两点与横轴都能形成梯形,把所有这样的梯形面积做加和即可得到AUC。物理意义:预测为正的概率值比预测为负的概率值大的可能性。AUC越大,代表模型越好。
机器学习性能评价指标总结:https://blog.csdn.net/LoseInVain/article/details/78109029
3、模型压缩
深度学习模型压缩和加速算法的三个方向:
(1)加速网络结构设计:分组卷积、分解卷积 (mobilenet,shufflenet等)、bottleneck结构(resnet)
(2)模型裁剪与稀疏化:
(3)量化加速:
知识蒸馏,将深度和宽度的网络压缩成较浅的网络,其中压缩模型模拟复杂模型所学习的功能,主要思想是通过学习通过 softmax 获得的类分布输出,将知识从一个大的模型转移到一个小的模型。核心思想是通过迁移知识,从而通过训练好的大模型得到更加适合推理的小模型。
4、常见损失函数
(1)0-1损失
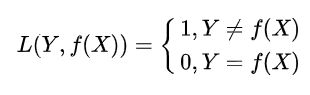
(2)L1范数损失,用于回归

(3)L2范数损失,用于回归

(4)交叉熵损失,用于分类(例如,逻辑回归二分类)

(5)指数损失,常用于adaboost

(6)Hinge损失,用于SVM

(7)focal loss
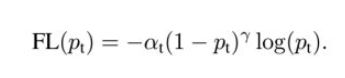
a. 当一个样本被分错的时候,pt是很小的,那么调制因子(1-Pt)接近1,损失不被影响;当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。
b. 当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。 专注参数γ平滑地调节了易分样本调低权值的比例。γ增大能增强调制因子的影响,实验发现γ取2最好。 直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍,当pt=0.968时,要小1000+倍,但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多。这样就增加了那些误分类的重要性。
focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
一句话总结:Focal loss 是交叉熵的改进版。alpha用于调整正负样本的权重(也就是在正负样本不均衡的情况下,增大少数样本的代价);(1-p)^gama 则控制难易分类样本的权重(当分类正确,1-p小,提供的损失小,当分类错误,1-p大,提供的损失大)。
特别地,当gama等于0时,focal loss 即为一般的交叉熵。
参考:https://zhuanlan.zhihu.com/p/58883095
5、SVM核函数的选择
(1)Linear核:主要用于线性可分的情形。参数少,速度快,对于一般数据,分类效果已经很理想了。
(2)RBF核:主要用于线性不可分的情形。参数多,分类结果非常依赖于参数。
如果数据量特别大或者特征很多,考虑采用线性核,因为采用高斯核的话计算量比较大。
6、SVM为什么转成对偶问题求解
(1)对偶问题将原始问题中的约束转为了对偶问题中的等式约束;
(2)方便核函数的引入;
(3)改变了问题的复杂度。由求特征向量w转化为求比例系数a,在原始问题下,求解的复杂度与样本的维度有关,即w的维度。在对偶问题下,只与样本数量有关。
7、异常值outiler的处理
异常值也称为“离群点”
处理方式:直接删除、用缺失值替代
针对多元变量的异常值诊断常用方法有:基于聚类的方法、基于邻近性的方法、基于分类的方法。
(1)基于聚类的离群点:一个对象是基于聚类的离群点,如果该对象不强属于任何簇。离群点对初始聚类的影响:如果通过聚类检测离群点,则由于离群点影响聚类,存在一个问题:结构是否有效。为了处理该问题,可以使用如下方法:对象聚类,删除离群点,对象再次聚类(这个不能保证产生最优结果)。
优缺点:1.基于线性和接近线性复杂度(k均值)的聚类技术来发现离群点可能是高度有效的;2.簇的定义通常是离群点的补,因此可能同时发现簇和离群点;3.产生的离群点集和它们的得分可能非常依赖所用的簇的个数和数据中离群点的存在性;4.聚类算法产生的簇的质量对该算法产生的离群点的质量影响非常大。
(2)基于距离:通常可以在对象之间定义邻近性度量,异常对象是那些远离其他对象的对象。
优缺点:1.简单;2.缺点:基于邻近度的方法需要O(m2)时间,大数据集不适用;3.该方法对参数的选择也是敏感的;4.不能处理具有不同密度区域的数据集,因为它使用全局阈值,不能考虑这种密度的变化。
详细可参考:https://www.cnblogs.com/charlotte77/p/5606926.html
8、Resnet,Resnext

左图为resnet,右图为renext。
Resnet的创造性贡献在于shortcut连接:100+层的网络,运算量却和16层的VGG差不多,精度提高一个档次,而且模块性、可移植性很强。
ResNeXt 是这个系列的新文章,是ResNet的升级版,升级内容为引入Inception的多支路的思想。ResNeXt就是把ResNet的单个卷积改成了多支路的卷积。
参考:https://imlogm.github.io/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/resnet/
9、python基础
(1)copy()与deepcopy()区别:两者之间的区分主要涉及到python对于数据的存储方式。
深复制:即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。
浅复制:并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。
参考:https://blog.csdn.net/qq_32907349/article/details/52190796
(2)lambda:匿名函数lambda是指一类无需定义标识符(函数名)的函数或子程序。所谓匿名函数,通俗地说就是没有名字的函数,lambda函数没有名字,是一种简单的、在同一行中定义函数的方法。
(3)列表和元组区别:列表list用“[]”表示,元组tuple用“()”表示。区别是列表可改,元组不可修改,元组无法复制。
Python将低开销的较大的块分配给元组,因为它们是不可变的。 对于列表则分配小内存块。 与列表相比,元组的内存更小。 当你拥有大量元素时,元组比列表快。列表的长度是可变的。
(4)生成器、迭代器、装饰器:
10、卷积的三种模式:full、same、valid
full模式的意思是,从filter和image刚相交开始做卷积。
same模式的意思是,当filter的中心(K)与image的边角重合时,开始做卷积运算,卷积之后输出的feature map尺寸保持不变。
valid模式的意思是,当filter全部在image里面的时候,进行卷积运算。
参考:https://blog.csdn.net/qq_26552071/article/details/86498227