HTTP协议
文章目录
-
-
-
- HTTP 往往是基于传输层的 TCP 协议实现的
- 应用层协议
- HTTP协议的工作过程
- HTTP协议的格式
- HTTP请求(Request)
- 方法
-
- 1.GET方法
-
- GET请求特点
- 2.POST方法
-
- POST方法特点
- GET和POST的区别
- 登录过程
- 状态码
-
- 404
- 500
-
-
HTTP 往往是基于传输层的 TCP 协议实现的
打开一个网站, 就是通过 HTTP 协议来传输数据的:
在浏览器中输入一个 搜狗搜索的 “网址” (URL) 时, 浏览器就给搜狗的服务器发送了一个 HTTP 请 求, 搜狗的服务器返回了一个 HTTP 响应.
这个响应结果被浏览器解析之后, 就展示成我们看到的页面内容. (这个过程中浏览器可能会给服务器发送
多个 HTTP 请求, 服务器会对应返回多个响应, 这些响应里就包含了页面 HTML, CSS, JavaScript, 图片, 字体等信息)
应用层协议
通过TCP/IP,数据能从客户端进程经过路径选择跨网络传送到服务器端进程[ IP+Port ]。
把数据从A端传送到B端, TCP/IP 解决的是通信的功能,而两端还要对数据进行加工处理或者使用,我们还需要一层协议,不关心通信细节,关心应用细节。这层协议叫做应用层协议。而应用是有不同的场景的,所以应用层协议是有不同种类的,其中经典协议之一的HTTP就是其中的佼佼者.
HTTP协议的工作过程
当我们在浏览器中输入一个 “网址”, 此时浏览器就会给对应的服务器发送一个 HTTP 请求. 对方服务器收到这个请求之后, 经过计算处理, 就会返回一个 HTTP 响应.

HTTP协议的格式
HTTP协议以资源为基本单位:
一次请求:浏览器向Web服务器进程请求一个Web资源。请求中需要告诉客户端到服务器什么内容:请求哪个WEB资源、对资源做哪种操作、请求本身的源信息、携带的内容。
一次响应:Web服务器进程给回浏览器一个Web资源的内容
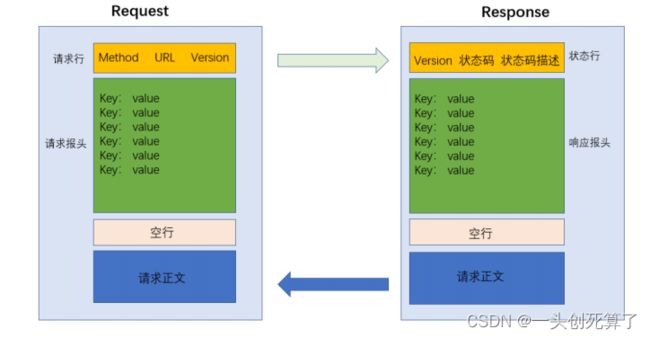
为什么 HTTP 报文中要存在 “空行”?
因为 HTTP 协议并没有规定报头部分的键值对有多少个. 空行就相当于是 “报头的结束标记”, 或者是 “报头和正文之间的分隔符”.
HTTP 在传输层依赖 TCP 协议, TCP 是面向字节流的. 如果没有这个空行, 就会出现 "粘包问题
HTTP请求(Request)
为了表述我们请求哪个资源,需要一种统一的规范给资源命名:统一资源标识符(网址)
URL基本格式:

1、资源在哪一台主机上——域名或者IP来体现
2、和主机上的哪个进程去获取资源——端口
3.具体定位到 是该进程管理的哪个资源——资源路径

EG

可以省略的部分

方法
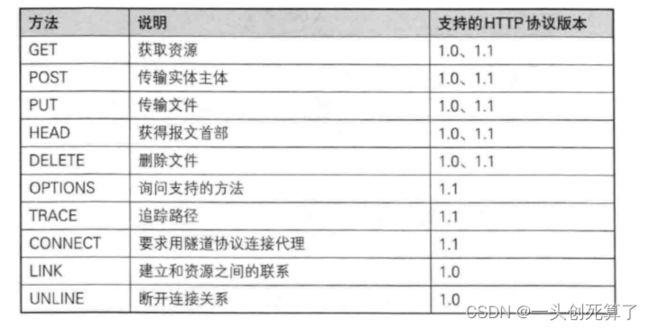
1.GET方法
GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源.
在浏览器中直接输入 URL, 此时浏览器就会发送出一个 GET 请求.
另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求
GET请求特点
1、首行的第一部分为 GET
2、URL 的 query string 可以为空, 也可以不为空.
3、header 部分有若干个键值对结构.
4、body 部分为空.
2.POST方法
用于提交用户输入的数据给服务器(例如登陆页面).
POST方法特点
1、首行的第一部分为 POST
2、URL 的 query string 一般为空 (也可以不为空)
3、header 部分有若干个键值对结构.
4、body 部分一般不为空. body 内的数据格式通过 header 中的 Content-Type 指定. body 的长度由
5、header 中的 Content-Length 指定.
GET和POST的区别
1、语义不同: GET 一般用于获取数据, POST 一般用于提交数据.
2、GET 的 body 一般为空, 需要传递的数据通过 query string 传递, POST 的 query string 一般为空, 需要传递的数据通过 body 传递
3、GET 请求一般是幂等的, POST 请求一般是不幂等的. (如果多次请求得到的结果一样, 就视为请求是幂等的).
4、GET 可以被缓存, POST 不能被缓存. (这一点也是承接幂等性).
登录过程

状态码
404
没有找到资源.
浏览器输入一个 URL, 目的就是为了访问对方服务器上的一个资源. 如果这个 URL 标识的资源不存在, 那么就会出现 404
例如, 在浏览器中输入 www.sogou.com/index.html , 此时就在尝试访问 sogou 上的/index.html 这个资源.
如果输入正确, 则可以正确访问到. 但是如果输入错误, 比如 www.sogou.com/index2.html , 就会看到 404 这样的响应
500
服务器出现内部错误. 一般是服务器的代码执行过程中遇到了一些特殊情况(服务器异常崩溃)会产生这个状态码.