C++模拟实现位图和布隆过滤器
文章目录
- 位图
-
- 引论
- 概念
- 解决引论
- 位图的模拟实现
-
- 铺垫
- 结构
- 构造函数
- 存储
- set,reset,test
- flip,size,count
- any,none,all
- 重载流运算符
- 测试
- 位图简单应用
- 位图代码汇总
- 布隆过滤器
-
- 引论
- 要点
- 代码实现
- 效率
位图
引论
四十亿个无符号整数,现在给你一个无符号整数,判断这个数是否在这四十亿个数中。
路人甲:简单,快排+二分。
可是存储这四十亿个整数需要多少空间?
简单算一下,1G=1024M=1024 * 1024KB=1024 * 1024 * 1024Byte,也就是说1G大概也就是十亿个字节。
四十亿个整数多大?40亿 * 4==160亿个字节,换算一下也就是16G。
我电脑内存也就十六个G,还不加上别的应用,显然内存超限了。
所以快排+二分是不可取的,那有没有别的法子呢?
所以也就有了下面要讲的位图。
概念
位图是什么?
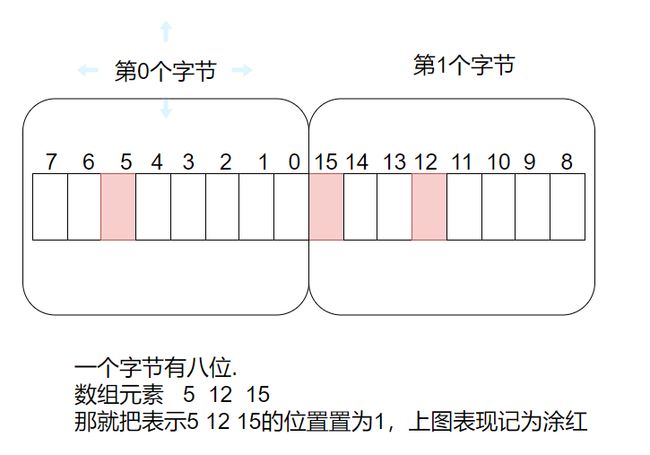
根据上面的模型我们可以发现,之前要用四个字节存储一个数字,现在只需一个比特位,当然我们不是存储具体数值,而是存储数字的状态。
因为一个比特位只有两种状态,所以我们存储的是该数字是否存在(数字存在对应位为1,否则为0)
解决引论
上面发现本来需要4个字节存储,现在只需要1位去存储,一下子就缩小了32倍,所以原本需要16G内存存储的数据只需要0.5G。显然这个内存我们是开的起的。
那该怎么判断这个数字是否存在呢?将这个数字/8得到它在第几个字节,将这个数字%8即可得到他在这个数字在第几位。
比如10,就在第一个字节的第二位。(都是从0开始计数)
总结一下应该怎么解决引论提出的问题?开一个能存储42亿位的位图,查找时算出待查找数的位置,如果这个位置为1则表示存在,否则就不存在。
位图也是一种哈希思想的运用
位图的模拟实现
铺垫
从上面可以看出,位图的实现主要在于把某一位置为0和把某一位置为1。
- 如何把某一位置为1?
把那个位置 |1
|是按位或运算符
- 如何把某一位置为0?
把那个位置 &0
&是按位与运算符
所以我们在实现时只需要算出那个位置再进行位操作即可。
结构

构造函数
BitSet()
{
_bits.resize(N / 8 + 1);//开这么多个字节,+1是怕有余数
}
比如开10个位就要开两个字节。
因为采用的是vector,所以所有的char都会被默认置为0。char类型的默认值就是0,空字符。
比如底层实现时resize第二个参数默认值给成T(),T为模板,当用char去实例化时,那默认值就是char()了,也就是ASCII码为0的字符。
存储
vector_bits;
用vector存的。
set,reset,test
test作用:检查这一位是0还是1,是1返回true,否则返回false
bool test(size_t x)
{
size_t integer = x / 8;//第几个字节
size_t rem = x % 8;//字节的第几个位置
return ((_bits[integer] >> rem) & 1) ? true : false;
}
set作用:把某一个位置置为1
void set(size_t x)//第x位置为1
{
if (!test(x))//如果这一位是0,置为1的话++
{
_cnt++;
}
size_t integer = x / 8;//第几个字节
size_t rem = x % 8;//字节的第几个位置
_bits[integer] |= (1 << rem);
}
reset作用:把某一个位置置为0
void reset(size_t x)//第x位置为0
{
if (test(x))//如果这一位是1,置为0的话--
{
_cnt--;
}
size_t integer = x / 8;//第几个字节
size_t rem = x % 8;//字节的第几个位置
_bits[integer] &= (~(1 << rem));
}
flip,size,count
flip:翻转,0变为1,1变为0
void flip(size_t x)//翻转
{
if (test(x))//1
{
reset(x);
}
else//0
{
set(x);
}
}
size:位图有多少位
size_t size() const
{
return N;//模板参数
}
count:位图里有多少个1
size_t count()
{
return _cnt;
}
any,none,all
any:位图里有没有1,有1返回true,否则返回false
bool any()
{
if (_cnt)
{
return true;
}
return false;
}
none:与any相反
bool none()
{
return !any();
}
all:全为1返回true,否则返回false
bool all()
{
if (_cnt == N)
{
return true;
}
else
{
return false;
}
}
重载流运算符
重载流运算符必须在BitSet里面加上一个函数声明
template
friend ostream& operator<<(ostream& out, const BitSet& bs);
这里会出现的一个问题是,因为类已经有了一个模板参数,所以很容易写成
friend ostream& operator<<(ostream& out, const BitSet& bs);
导致运行时报链接错误。
大佬的解释:函数模板和友元重载运算符报"无法解析的外部符"的解决方法_UKey_的博客-CSDN博客_函数模板 无法解析的外部符号
简单解释一下,因为这是一个声明,所以编译到这里时只当这是个友元函数的声明,并不会把函数里的模板N参数实例化,只有调用流运算符时才会去实例化,这就出现了二次编译(第一次编译只实例化了BitSet类,即类BitSet模板参数N被确定下来)
但因为友元函数只是声明并没有实例化,即第二种写法的N并没有被确定下来,到调用这个函数的时候要对N进行编译,但是不知道这个N具体是什么,因为N是一个模板参数被第一次实例化确定下来后就没了,编译器往上找也找不到,导致有函数声明但是找不到具体函数,从而发生了链接错误。解决就是写成第一种,第二次编译时看到了上面有一个模板声明就知道T是个模板参数,调用时第一次被确定的N传给现在的T,所以就能正确运行。
ostream& operator<<(ostream& out, const BitSet& bs)
{
//从后往前是低位到高位,库里面是这样的
int len = bs.size() / 8 ;
char tmp;
tmp = bs._bits[len];
for (int i = bs.size() % 8 - 1; i >= 0; i--)
{
if ((tmp >> i) & 1)
{
cout << '1';
}
else
{
cout << '0';
}
}
for (int i = len-1; i >=0; i--)
{
tmp = bs._bits[i];
for (int j = 7; j >=0; j--)
{
if ((tmp >> j) & 1)
{
cout << '1';
}
else
{
cout << '0';
}
}
}
//从前往后是低位到高位(人看起来合适)
//for (int i=0;i> i) & 1)
// {
// cout << '1';
// }
// else
// {
// cout << '0';
// }
// }
//}
//tmp = bs._bits[len];
//for (int i = 0; i < bs.size() % 8; i++)
//{
// if ((tmp >> i) & 1)
// {
// cout << '1';
// }
// else
// {
// cout << '0';
// }
//}
return out;
}
比如有十个位,把第一位置为1,那打印出来就是0000000010
是从右往左数的,库里的打印是这样的,注释掉的那部分代码会打印0100000000
实际我们操作内存实现的存储是00000010 00000000
测试
void test_bitset()
{
BitSet<10> bits;
bits.set(1);
bits.set(9);
cout << bits.count() << endl;
bits.reset(1);
cout << bits.count() << endl;
cout << bits << endl;
/*cout << bits.none() << endl;
bits.set(4);
cout << bits.none() << endl;
cout << bits.any() << endl;
cout << bits.all() << endl;*/
/*bits.set(4);
cout << bits.test(4) << endl;
bits.flip(4);
cout << bits.test(4) << endl;
bits.flip(4);
cout << bits.test(4) << endl;*/
/*bits<0xffffffff>bits;
cout << endl;*/
}
位图简单应用
- 100亿个整数,找到只出现一次的数。
100亿个整数不代表要开一百亿位大小的空间,有些可能重复了几次,所以开int大小的即可。
整两个位图代表两位, 00 01 10 11, 第一个位图代表第一位,第二个位图表示第二位 ,初始状态都是00,插入一个数后将其置为01, 再来就置为10 ,再去遍历整个位图得到只出现一次的数的集合。
template
class FindOnceVal
{
public:
void set(size_t x)
{
bool flag1 = _bs1.test(x);//得到第一位
bool flag2 = _bs2.test(x);//得到第二位
if (flag1 == false && flag2 == false)//00->01
{
_bs2.set(x);
}
else if (flag1 == false && flag2 == true)//01->10
{
_bs1.set(x);
_bs2.reset(x);
}
//10->11...不用再处理了
}
bool check(size_t x)
{
if (!_bs1.test(x) && _bs2.test(x))//01
{
return true;
}
return false;
}
void print()
{
for (size_t i = 0; i < N; i++)
{
if (check(i))
{
printf("%d\n",i);
}
}
}
private:
BitSet_bs1;
BitSet_bs2;
};
void TestFindOnceVal()
{
int a[] = { 1, 20, 30, 43, 5, 4, 1, 43, 43, 7, 9, 7, 7, 0 };
FindOnceVal<100> fov;
for (auto e : a)
{
fov.set(e);
}
fov.print();
}
- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
两个位图,分别去映射两个文件,再去遍历比对即可。比如两个位图的同一个位置都为1说明整个数就在交集里面
- 给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址? 我们只有1G内存,
如何找到top K的IP?
哈希切割,运用哈希算法将IP分类(切割),比如把IP转成字符串,再映射成整形,这就是一种哈希算法,100G给分成100个文件,即100个小类,每一个文件去计数,比如就用map
第二个文件出来的最大次数再与第一个得到的最大次数进行比较记录下出现最大次数的ip和次数,如此循环遍历完 100个文件即可。
如果要topK 建一个小堆即可
如果出现切分后一个文件还是过大,那换一种哈希算法再进行切割
位图的优势就在于可以大大节省空间!
位图代码汇总
#pragma once
#include
#include
#include
using namespace std;
namespace ck
{
template//N个数
class BitSet
{
public:
BitSet()
{
_bits.resize(N / 8 + 1);//开这么多个字节
}
void set(size_t x)//第x位置为1
{
if (!test(x))//如果这一位是0,置为1的话++
{
_cnt++;
}
size_t integer = x / 8;//第几个字节
size_t rem = x % 8;//字节的第几个位置
_bits[integer] |= (1 << rem);
}
void reset(size_t x)//第x位置为0
{
if (test(x))//如果这一位是1,置为0的话--
{
_cnt--;
}
size_t integer = x / 8;//第几个字节
size_t rem = x % 8;//字节的第几个位置
_bits[integer] &= (~(1 << rem));
}
bool test(size_t x)
{
size_t integer = x / 8;//第几个字节
size_t rem = x % 8;//字节的第几个位置
return ((_bits[integer] >> rem) & 1) ? true : false;
}
void flip(size_t x)//翻转
{
if (test(x))//1
{
reset(x);
}
else//0
{
set(x);
}
}
size_t size() const
{
return N;//模板参数
}
size_t count()
{
return _cnt;
}
bool any()
{
if (_cnt)
{
return true;
}
return false;
}
bool none()
{
return !any();
}
bool all()
{
if (_cnt == N)
{
return true;
}
else
{
return false;
}
}
template
friend ostream& operator<<(ostream& out, const BitSet& bs);
private:
vector_bits;
size_t _cnt = 0;//被设置为1的个数
};
template//模板参数不能取名为N
ostream& operator<<(ostream& out, const BitSet& bs)
{
//从后往前是低位到高位,库里面是这样的
int len = bs.size() / 8 ;
char tmp;
tmp = bs._bits[len];
for (int i = bs.size() % 8 - 1; i >= 0; i--)
{
if ((tmp >> i) & 1)
{
cout << '1';
}
else
{
cout << '0';
}
}
for (int i = len-1; i >=0; i--)
{
tmp = bs._bits[i];
for (int j = 7; j >=0; j--)
{
if ((tmp >> j) & 1)
{
cout << '1';
}
else
{
cout << '0';
}
}
}
//从前往后是低位到高位(人看起来合适)
//for (int i=0;i> i) & 1)
// {
// cout << '1';
// }
// else
// {
// cout << '0';
// }
// }
//}
//tmp = bs._bits[len];
//for (int i = 0; i < bs.size() % 8; i++)
//{
// if ((tmp >> i) & 1)
// {
// cout << '1';
// }
// else
// {
// cout << '0';
// }
//}
return out;
}
void test_bitset()
{
BitSet<10> bits;
bits.set(1);
bits.set(9);
cout << bits.count() << endl;
bits.reset(1);
cout << bits.count() << endl;
cout << bits << endl;
/*cout << bits.none() << endl;
bits.set(4);
cout << bits.none() << endl;
cout << bits.any() << endl;
cout << bits.all() << endl;*/
/*bits.set(4);
cout << bits.test(4) << endl;
bits.flip(4);
cout << bits.test(4) << endl;
bits.flip(4);
cout << bits.test(4) << endl;*/
/*bits<0xffffffff>bits;
cout << endl;*/
}
/*1. 给定100亿个整数,设计算法找到只出现一次的整数?
100亿个整数不代表要开一百亿位大小的空间,有些可能重复了几次,所以开int大小的即可。
整两个位图 00 01 10 11 第一个位图代表第一位 第二个位图表示第二位 初始状态都是00 来了一个数后将其置为01 再来就置为10 再去遍历
*/
template
class FindOnceVal
{
public:
void set(size_t x)
{
bool flag1 = _bs1.test(x);
bool flag2 = _bs2.test(x);
if (flag1 == false && flag2 == false)//00->01
{
_bs2.set(x);
}
else if (flag1 == false && flag2 == true)//01->10
{
_bs1.set(x);
_bs2.reset(x);
}
//10->11...不用再处理了
}
bool check(size_t x)
{
if (!_bs1.test(x) && _bs2.test(x))//01
{
return true;
}
return false;
}
void print()
{
for (size_t i = 0; i < N; i++)
{
if (check(i))
{
printf("%d\n",i);
}
}
}
private:
BitSet_bs1;
BitSet_bs2;
};
void TestFindOnceVal()
{
int a[] = { 1, 20, 30, 43, 5, 4, 1, 43, 43, 7, 9, 7, 7, 0 };
FindOnceVal<100> fov;
for (auto e : a)
{
fov.set(e);
}
fov.print();
}
/*位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数 在第一题的基础上稍作改动即可*/
/*给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
两个位图,分别去映射两个文件,再去遍历即可
*/
/*给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址? 与上题条件相同,
如何找到top K的IP?*/
/*哈希切割 运用哈希算法将IP分类(切割),比如把IP转成字符串,再映射成整形,这就是一种哈希算法 100G给分成100个文件,即100个小类,
每一个文件去计数,比如就用map 然后记录下最大的,再将map清空
第二个文件出来的最大次数再与第一个得到的最大次数进行比较
如果要topK 建一个小堆即可 如果出现一个文件还是过大,那换一种哈希算法在进行切割
*/
}
布隆过滤器
前提是已经实现了位图
引论
存在一亿个ip,给一个ip,快速判断这个ip在不在这一亿个ip中
之前哈希切割能不能做?之前是切成小文件,但是其实归根到底都只记录了出现次数最多的,并没有记录所有人的状态。
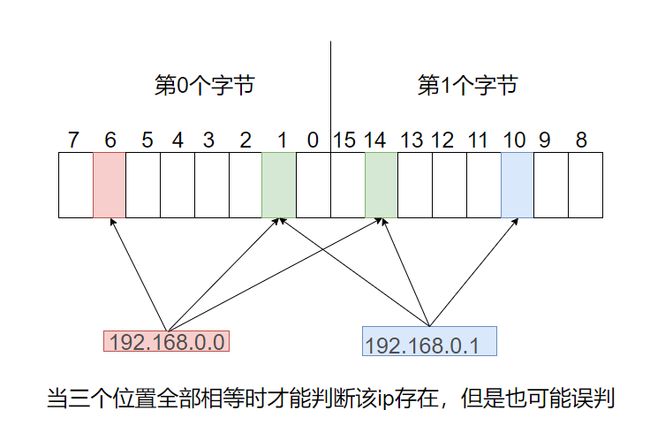
那我们可不可以通过位图来做,把IP映射到位图的一个位置,再去判断这个IP是否在位图中。听起来可行,但是显然会出现映射上的冲突,即两个不同的IP映射到了同一个位置,这就导致了误判。那有没有更好的法子?
一个叫布隆的人发现消除冲突是不可能的,但是可以减缓冲突,他是怎么减缓冲突的呢?
之前一个ip映射一个位置,现在我去映射多个位置,比如映射三个,只有三个位置全部对上,那才说明这个ip存在,当然这也可能存在误判,但误判概率已经减小很多了。这就是布隆过滤器
要点
-
布隆过滤器没有消除冲突,但是减缓了冲突。
-
布隆过滤器判断数据是否存在时是可能误判的,但是在判断数据不存在时一定准确
-
在一些允许误判的情境下大大提高了判断的效率。
一个经典的场景就是取名,我们在一个软件内注册一个用户,用户输入一个名称检查是否重复,误判的情景:用户输入一个名字,这个名字事实上不存在,但是被误判为存在,那这个代价很小啊,大不了让用户换一个名字输入不就行了。如果为了得到一个准确的结果,可以在判断存在后去对服务器发送一个请求去检查这个名字是否存在(一般能不涉及服务器就不去涉及了)。
-
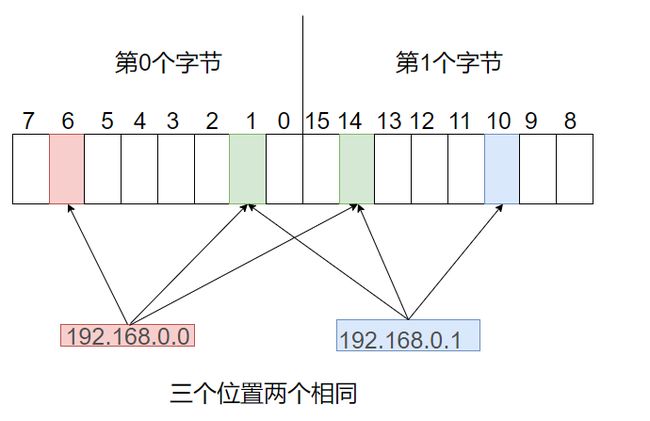
布隆过滤器可以删除吗?
理论上是可以的,但是不建议,比如两个元素,每个元素映射三个位置,三个位置里有两个位置相同,那删除一个ip,即删除三个位置肯定会影响到另一个,所以就不好删除。
但也不是不能删除,硬要删除也是可以的,现在一个ip映射三个位置,每个位置都是1个比特位,只能表示两种状态,可以把每种状态设置为8个位,也就是一个字节,就可以表示256种状态,可以用来计数实现删除。但是问题在开位图的原因就是为了节省空间,现在一个状态一个字节与初衷相违背了,可谓是杀敌一千自损八百。因此不建议删除
代码实现
这个比较简单,复用位图即可,比如一个ip映射三个位置,也就是用来三个哈希函数而已。
哈希函数都是贴网上的代码,处理string的哈希效率比较好的有BKDR哈希等等。实现的布隆过滤器默认的哈希函数是处理string的
#include "BitSet_.h"//复用位图
namespace ck
{
struct HashFunc1
{
//BKDR Hash
size_t operator()(const string& str)
{
size_t seed = 131; // 31 131 1313 13131 131313 etc..
size_t hash = 0;
for (size_t i = 0; i < str.length(); i++)
{
hash = (hash * seed) + str[i];
}
return hash;
}
};
struct HashFunc2
{
//FNV Hash
size_t operator()(const string& str)
{
size_t fnv_prime = 0x811C9DC5;
size_t hash = 0;
for (std::size_t i = 0; i < str.length(); i++)
{
hash *= fnv_prime;
hash ^= str[i];
}
return hash;
}
};
struct HashFunc3
{
//APH Hash
size_t operator()(const string& str)
{
unsigned int BitsInUnsignedInt = (unsigned int)(sizeof(unsigned int) * 8);
unsigned int ThreeQuarters = (unsigned int)((BitsInUnsignedInt * 3) / 4);
unsigned int OneEighth = (unsigned int)(BitsInUnsignedInt / 8);
unsigned int HighBits = (unsigned int)(0xFFFFFFFF) << (BitsInUnsignedInt - OneEighth);
unsigned int hash = 0;
unsigned int test = 0;
for (std::size_t i = 0; i < str.length(); i++)
{
hash = (hash << OneEighth) + str[i];
if ((test = hash & HighBits) != 0)
{
hash = ((hash ^ (test >> ThreeQuarters)) & (~HighBits));
}
}
return hash;
}
};
template
class BloomFilter
{
public:
void set(const K& key)
{
size_t x1 = Hash1()(key)%len;
size_t x2 = Hash2()(key) % len;
size_t x3 = Hash3()(key) % len;
_bs.set(x1);
_bs.set(x2);
_bs.set(x3);
}
bool test(const K& key)
{
//不用一次性算出所有的值
size_t x1 = Hash1()(key) % len;
if (!_bs.test(x1))
{
return false;
}
size_t x2 = Hash2()(key) % len;
if (!_bs.test(x2))
{
return false;
}
size_t x3 = Hash2()(key) % len;
if (!_bs.test(x3))
{
return false;
}
return true;//三个位置全都存在才能说明存在
}
private:
BitSet<6*N>_bs;
size_t len = 6 * N;//位图的大小可以决定过滤器的效率(越大哈希冲突概率越小,误判概率越低)
};
效率
效率指的就是误判的概率。
多搞几个哈希函数,或者把位图开大一点都能提高降低误判的可能性。
网上有很多大佬探究了位图大小开多少合适,比如位图要存储N个数,那开多大可以让性能还可以的同时也不用开过多的空间,结果是4。有N个数就开4N左右,当然和存储的具体数据有关。比如我上面就开了6N。