彻底弄懂Python标准库源码(三)—— pprint模块
目录
模块整体注释
依赖模块导入、对外暴露接口
saferepr函数——返回对象的字符串表示,并为无限递归数据结构提供保护
isreadable函数——返回对象的是否“可读”
isrecursive函数——返回对象的是否是无限递归结构
PrettyPrinter——优雅格式化Python对象的类
pprint——更方便更美观地打印
pformat——格式化字符串构造器
pp——同pprint
print 模块能够美观地对数据结构进行格式化。不仅可以由解释器正确地解析,而且便于人类阅读。输出尽可能地保持在一行,需要分拆到多行时会有缩进表示。
想象一下,你有下面这么一串 json (这个是我随机生成的)需要打印出来,或者调试程序的时候需要看一下 json 中某个字段的值。

用 print() 打印出来回事这么一坨,根本没有可读性:
{'_id': '5f8808d57ac946ae591e8929', 'index': 0, 'guid': 'b41b3b14-1ae2-4cc4-b443-105bda03f4f0', 'isActive': True, 'balance': '$1,985.20', 'picture': 'http://placehold.it/32x32', 'age': 37, 'eyeColor': 'brown', 'name': 'Alexandra Atkins', 'gender': 'female', 'company': 'COSMETEX', 'email': '[email protected]', 'phone': '+1 (999) 588-3661', 'address': '779 Beayer Place, Belvoir, Washington, 5395', 'about': 'Laborum Lorem labore sint excepteur ad do esse veniam sunt cillum. Magna ipsum id aliqua consequat. Commodo enim occaecat pariatur ullamco irure incididunt et incididunt. Dolor aliqua eiusmod id laboris non laborum aliqua sunt occaecat eu commodo elit consequat. In mollit aute ullamco officia exercitation eiusmod ea labore id magna adipisicing.\r\n', 'registered': '2018-12-29T09:52:41 -08:00', 'latitude': 66.079339, 'longitude': 68.156168, 'tags': ['mollit', 'velit', 'do', 'velit', 'Lorem', 'qui', 'irure'], 'friends': [{'id': 0, 'name': 'Latonya Pena'}, {'id': 1, 'name': 'Marion Ayers'}, {'id': 2, 'name': 'Bishop Day'}], 'greeting': 'Hello, Alexandra Atkins! You have 3 unread messages.', 'favoriteFruit': 'banana'}
在IDE中调试时,可能打印出来变成了一眼看不到头的一行,然后你就需要拖着进度条一个字段一个字段去找。
![]()
而用 pprint() 打印出来会自动变成这样美观可读的格式,这就是 pprint 库的作用:
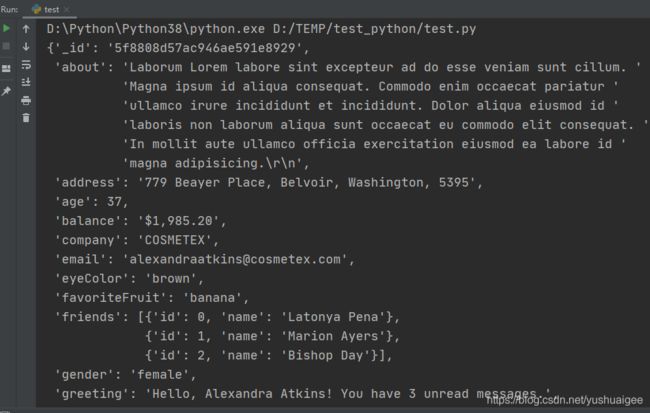
pprint 模块主要包含 "pprint","pformat","isreadable","isrecursive","saferepr", "pp" 方法和一个类“PrettyPrinter",其中核心是 PrettyPrinter 类,其他方法都是调用的这个类。以下文章中的行数是与我所用的3.8.4版本 pprint.py 文件真实的行数对应的。
模块整体注释
# Author: Fred L. Drake, Jr.
# [email protected]
#
# This is a simple little module I wrote to make life easier. I didn't
# see anything quite like it in the library, though I may have overlooked
# something. I wrote this when I was trying to read some heavily nested
# tuples with fairly non-descriptive content. This is modeled very much
# after Lisp/Scheme - style pretty-printing of lists. If you find it
# useful, thank small children who sleep at night.
"""Support to pretty-print lists, tuples, & dictionaries recursively.
Very simple, but useful, especially in debugging data structures.
Classes
-------
PrettyPrinter()
Handle pretty-printing operations onto a stream using a configured
set of formatting parameters.
Functions
---------
pformat()
Format a Python object into a pretty-printed representation.
pprint()
Pretty-print a Python object to a stream [default is sys.stdout].
saferepr()
Generate a 'standard' repr()-like value, but protect against recursive
data structures.
"""模块作者Fred L. Drake, Jr.是 PythonLabs 团队的成员,自1995年以来一直在为 Python 做出贡献,许多原始 Python 文档都是他贡献的。下面是他说的话:这是我为了让生活更容易写的一个简单的小模块。我之前没有在 Python 库中看到有类似功能的模块,可能有我没注意到吧。我写这篇文章时,我正在试图读一些嵌套很繁琐的元组,可读性非常差。这个模块仿效Lisp/Scheme(一种编程语言)风格将列表打印的更美观。如果你觉得有用,感谢那些晚上睡觉的孩子们吧(我估计作者的意思是他家孩子晚上睡觉很乖,没打扰他用晚上的业余时间写这个模块,hh)。
支持递归地的将列表、元组、字典优雅地打印出来,非常简单好用,尤其是调试数据的时候。
- 类 PrettyPrinter,作用是根据传入的参数将输入流优雅地打印出来。
- 方法 format ,作用是将 Python 对象格式化成优雅的表现形式。
- 方法 pprint,作用是将 Python 对象优雅地打印出来。(这个最常用,其实我写这篇博客之前只用过这个库这一个方法。。。)
- 方法saferepr,作用是返回 object 的字符串表示,并为递归数据结构提供保护。这个怎么理解具体见后面safe_repr()分析。
依赖模块导入、对外暴露接口
import collections as _collections
import re
import sys as _sys
import types as _types
from io import StringIO as _StringIO
__all__ = ["pprint","pformat","isreadable","isrecursive","saferepr",
"PrettyPrinter", "pp"]collections 是Python内建的一个集合模块,提供了许多有用的集合类,像 Deque、Counter等。re 是Python自带的标准库提供对正则表达式的支持。sys 是一个C实现的内置模块,主要是实现Python解释器、操作系统相关的操作。types 定义了一些工具函数,用于协助动态创建新的类型。io提供了 Python 用于处理各种 I/O 类型的主要工具。三种主要的 I/O类型分别为: 文本 I/O, 二进制 I/O 和 原始 I/O,此处引入的 StringIO 即是文本 I/O。pprint 库对外暴露的只有pprint、pformat、isreadable、isrecursive、saferepr、PrettyPrinter、pp 这几个属性。
saferepr函数——返回对象的字符串表示,并为无限递归数据结构提供保护
def saferepr(object):
"""Version of repr() which can handle recursive data structures."""
return _safe_repr(object, {}, None, 0, True)[0]第 65 ~ 67 行, saferepr 函数,通过递归调用 _safe_repr 方法,返回传入对象的的字符串表示,类似 repr() 和 str() 方法(str()、repr()的区别),不同的地方是这个函数对于无限递归的数据结构提供了保护。 如果传入的object包含一个无限递归的数据结构,该递归数据结构会被表示为
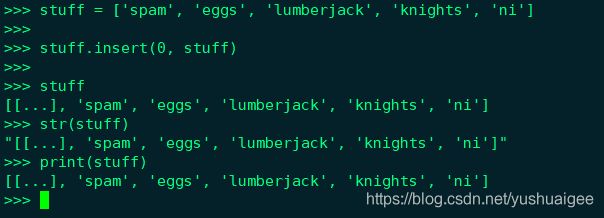
什么是无限递归数据结构?类似下面这种,一个数组包含了它自己,你要是想将它完整打印出来肯定会有问题,下图中结果说明内置的 repr() 和 str() 方法对无限递归数据结构也做了保护,会转换成 [...],而 saferepr 函数将其转化为了字符串
isreadable函数——返回对象的是否“可读”
def isreadable(object):
"""Determine if saferepr(object) is readable by eval()."""
return _safe_repr(object, {}, None, 0, True)[1]第69~71行,这里的“可读”的意思是说,该对象是否可被用来通过 eval() 重新构建对象的值。一般是判断是否一个字符串是否可以用 eval() 转换成python对象,此函数对于递归对象总是返回 False。
isrecursive函数——返回对象的是否是无限递归结构
def isrecursive(object):
"""Determine if object requires a recursive representation."""
return _safe_repr(object, {}, None, 0, True)[2]第 73~75行, 判断传入的对象是否是无限递归结构。
PrettyPrinter——优雅格式化Python对象的类
class PrettyPrinter:
def __init__(self, indent=1, width=80, depth=None, stream=None, *,
compact=False, sort_dicts=True):
"""Handle pretty printing operations onto a stream using a set of
configured parameters.
indent
Number of spaces to indent for each level of nesting.
width
Attempted maximum number of columns in the output.
depth
The maximum depth to print out nested structures.
stream
The desired output stream. If omitted (or false), the standard
output stream available at construction will be used.
compact
If true, several items will be combined in one line.
sort_dicts
If true, dict keys are sorted.
"""
indent = int(indent)
width = int(width)
if indent < 0:
raise ValueError('indent must be >= 0')
if depth is not None and depth <= 0:
raise ValueError('depth must be > 0')
if not width:
raise ValueError('width must be != 0')
self._depth = depth
self._indent_per_level = indent
self._width = width
if stream is not None:
self._stream = stream
else:
self._stream = _sys.stdout
self._compact = bool(compact)
self._sort_dicts = sort_dicts第104~145行,初始化函数,入参的处理和解析。
- indent:每个嵌套级别要缩进的空格数,即第 1 层缩进 indent 个字符,第 2 层缩进 2 * indent 个字符,默认值 1。
- width: 输出的字符的最大宽度,默认值 80。
- depth: 打印嵌套结构的最大深度,超过这个深度不再换行,默认None表示不限制。
- stream: 所需的输出流。如果省略(或False),将使用标准输出流,即 sys.stdout ,这个和 print()一样。
- * : keyword-only参数标志,不占参数位置,详见我的另一篇博客 彻底弄懂 Python3中入参里的*号的作用 第5节。
- compact: 如果为True,则多个元素将合并为一行,不会打印换行符,width 参数依然生效,默认为 False。
- sort_dicts: 字典打印前是否排序,如果为 True,则打印前根据 key 进行排序。
def pprint(self, object):
self._format(object, self._stream, 0, 0, {}, 0)
self._stream.write("\n")第147~149行,pprint(self, object) 函数,我们平时用的最多的 from pprint import pprint 最终也是调用的这个方法。这个方法先调用 self._format() 方法,再调用对象的输出流输出一个换行。这里面的函数层层调用有点多,需要一步一步看。
def _format(self, object, stream, indent, allowance, context, level):
objid = id(object)
if objid in context:
stream.write(_recursion(object))
self._recursive = True
self._readable = False
return
rep = self._repr(object, context, level)
max_width = self._width - indent - allowance
if len(rep) > max_width:
p = self._dispatch.get(type(object).__repr__, None)
if p is not None:
context[objid] = 1
p(self, object, stream, indent, allowance, context, level + 1)
del context[objid]
return
elif isinstance(object, dict):
context[objid] = 1
self._pprint_dict(object, stream, indent, allowance,
context, level + 1)
del context[objid]
return
stream.write(rep)第163~185行的 self._format() 方法,这是 PrettyPrinter 这个类一个比较核心的递归调用方法。
入参解析:
- object: 需要被格式化的对象。就是要打印的对象。
- stream:所需的输出流。。
- indent:每个嵌套级别要缩进的空格数。
- allowance:额外补偿的缩进空格数。会根据前面的 width 和这里的 allowance,indent 决定什么时候换行。
- context:以对象的id为键的字典,这些对象是当前表示上下文的一部分。
- level:打印嵌套结构的最大深度,超过这个深度不再换行。
第164~169行,获取对象的 id,如果object的 id 在 context 中,就打印 _recursion(object) ,_recursion() 在文件第575~577行,是个类外的函数,作用是返回对象的类型名字和 id:
def _recursion(object):
return (""
% (type(object).__name__, id(object))) 第170行,self._repr() 函数在 PrettyPrinter 类内的第403~410行,这里又调用了 self.format()
def _repr(self, object, context, level):
repr, readable, recursive = self.format(object, context.copy(),
self._depth, level)
if not readable:
self._readable = False
if recursive:
self._recursive = True
return reprself.format() 在类内的第412~417行,这里又调用了 _safe_repr()。注释是说本方法将对象格式化为一个具体的文本,返回一个字符串、是否“可读”、是否无限递归结构。和前面的saferepr函数是一样的,只是saferepr函数只取了第一个返回值。
def format(self, object, context, maxlevels, level):
"""Format object for a specific context, returning a string
and flags indicating whether the representation is 'readable'
and whether the object represents a recursive construct.
"""
return _safe_repr(object, context, maxlevels, level, self._sort_dicts)所以经过 rep = self._repr(object, context, level) 的层层调用,这一步已经获取到了对象的字符串形式,下一步就是按照预定的格式将它美观地打印出来。self._dispatch 是一个函数映射字典,以对象类型为键,对应的处理方法为值。p = self._dispatch.get(type(object).__repr__, None) 就是根据对象类型不同获取不同的处理函数。
下面就是各种类型的对象的具体处理函数。可以看出它不是一次性输出的,而是用 write 方法一块一块的输出,例如字典,先输出 “{”,然后递归调用fomat方法解析每一个键值对,每一个键值对先解析key输出,再解析value,最后再输出“”。这个debug一下就能直观地看出来。
_dispatch = {}
def _pprint_dict(self, object, stream, indent, allowance, context, level):
write = stream.write
write('{')
if self._indent_per_level > 1:
write((self._indent_per_level - 1) * ' ')
length = len(object)
if length:
if self._sort_dicts:
items = sorted(object.items(), key=_safe_tuple)
else:
items = object.items()
self._format_dict_items(items, stream, indent, allowance + 1,
context, level)
write('}')
_dispatch[dict.__repr__] = _pprint_dict
def _pprint_ordered_dict(self, object, stream, indent, allowance, context, level):
if not len(object):
stream.write(repr(object))
return
cls = object.__class__
stream.write(cls.__name__ + '(')
self._format(list(object.items()), stream,
indent + len(cls.__name__) + 1, allowance + 1,
context, level)
stream.write(')')
_dispatch[_collections.OrderedDict.__repr__] = _pprint_ordered_dict
def _pprint_list(self, object, stream, indent, allowance, context, level):
stream.write('[')
self._format_items(object, stream, indent, allowance + 1,
context, level)
stream.write(']')
_dispatch[list.__repr__] = _pprint_list
def _pprint_tuple(self, object, stream, indent, allowance, context, level):
stream.write('(')
endchar = ',)' if len(object) == 1 else ')'
self._format_items(object, stream, indent, allowance + len(endchar),
context, level)
stream.write(endchar)
_dispatch[tuple.__repr__] = _pprint_tuple
def _pprint_set(self, object, stream, indent, allowance, context, level):
if not len(object):
stream.write(repr(object))
return
typ = object.__class__
if typ is set:
stream.write('{')
endchar = '}'
else:
stream.write(typ.__name__ + '({')
endchar = '})'
indent += len(typ.__name__) + 1
object = sorted(object, key=_safe_key)
self._format_items(object, stream, indent, allowance + len(endchar),
context, level)
stream.write(endchar)
_dispatch[set.__repr__] = _pprint_set
_dispatch[frozenset.__repr__] = _pprint_set
def _pprint_str(self, object, stream, indent, allowance, context, level):
write = stream.write
if not len(object):
write(repr(object))
return
chunks = []
lines = object.splitlines(True)
if level == 1:
indent += 1
allowance += 1
max_width1 = max_width = self._width - indent
for i, line in enumerate(lines):
rep = repr(line)
if i == len(lines) - 1:
max_width1 -= allowance
if len(rep) <= max_width1:
chunks.append(rep)
else:
# A list of alternating (non-space, space) strings
parts = re.findall(r'\S*\s*', line)
assert parts
assert not parts[-1]
parts.pop() # drop empty last part
max_width2 = max_width
current = ''
for j, part in enumerate(parts):
candidate = current + part
if j == len(parts) - 1 and i == len(lines) - 1:
max_width2 -= allowance
if len(repr(candidate)) > max_width2:
if current:
chunks.append(repr(current))
current = part
else:
current = candidate
if current:
chunks.append(repr(current))
if len(chunks) == 1:
write(rep)
return
if level == 1:
write('(')
for i, rep in enumerate(chunks):
if i > 0:
write('\n' + ' '*indent)
write(rep)
if level == 1:
write(')')
_dispatch[str.__repr__] = _pprint_str
def _pprint_bytes(self, object, stream, indent, allowance, context, level):
write = stream.write
if len(object) <= 4:
write(repr(object))
return
parens = level == 1
if parens:
indent += 1
allowance += 1
write('(')
delim = ''
for rep in _wrap_bytes_repr(object, self._width - indent, allowance):
write(delim)
write(rep)
if not delim:
delim = '\n' + ' '*indent
if parens:
write(')')
_dispatch[bytes.__repr__] = _pprint_bytes
def _pprint_bytearray(self, object, stream, indent, allowance, context, level):
write = stream.write
write('bytearray(')
self._pprint_bytes(bytes(object), stream, indent + 10,
allowance + 1, context, level + 1)
write(')')
_dispatch[bytearray.__repr__] = _pprint_bytearray
def _pprint_mappingproxy(self, object, stream, indent, allowance, context, level):
stream.write('mappingproxy(')
self._format(object.copy(), stream, indent + 13, allowance + 1,
context, level)
stream.write(')')
_dispatch[_types.MappingProxyType.__repr__] = _pprint_mappingproxy
#......
def _pprint_default_dict(self, object, stream, indent, allowance, context, level):
if not len(object):
stream.write(repr(object))
return
rdf = self._repr(object.default_factory, context, level)
cls = object.__class__
indent += len(cls.__name__) + 1
stream.write('%s(%s,\n%s' % (cls.__name__, rdf, ' ' * indent))
self._pprint_dict(object, stream, indent, allowance + 1, context, level)
stream.write(')')
_dispatch[_collections.defaultdict.__repr__] = _pprint_default_dict
def _pprint_counter(self, object, stream, indent, allowance, context, level):
if not len(object):
stream.write(repr(object))
return
cls = object.__class__
stream.write(cls.__name__ + '({')
if self._indent_per_level > 1:
stream.write((self._indent_per_level - 1) * ' ')
items = object.most_common()
self._format_dict_items(items, stream,
indent + len(cls.__name__) + 1, allowance + 2,
context, level)
stream.write('})')
_dispatch[_collections.Counter.__repr__] = _pprint_counter
def _pprint_chain_map(self, object, stream, indent, allowance, context, level):
if not len(object.maps):
stream.write(repr(object))
return
cls = object.__class__
stream.write(cls.__name__ + '(')
indent += len(cls.__name__) + 1
for i, m in enumerate(object.maps):
if i == len(object.maps) - 1:
self._format(m, stream, indent, allowance + 1, context, level)
stream.write(')')
else:
self._format(m, stream, indent, 1, context, level)
stream.write(',\n' + ' ' * indent)
_dispatch[_collections.ChainMap.__repr__] = _pprint_chain_map
def _pprint_deque(self, object, stream, indent, allowance, context, level):
if not len(object):
stream.write(repr(object))
return
cls = object.__class__
stream.write(cls.__name__ + '(')
indent += len(cls.__name__) + 1
stream.write('[')
if object.maxlen is None:
self._format_items(object, stream, indent, allowance + 2,
context, level)
stream.write('])')
else:
self._format_items(object, stream, indent, 2,
context, level)
rml = self._repr(object.maxlen, context, level)
stream.write('],\n%smaxlen=%s)' % (' ' * indent, rml))
_dispatch[_collections.deque.__repr__] = _pprint_deque
def _pprint_user_dict(self, object, stream, indent, allowance, context, level):
self._format(object.data, stream, indent, allowance, context, level - 1)
_dispatch[_collections.UserDict.__repr__] = _pprint_user_dict
def _pprint_user_list(self, object, stream, indent, allowance, context, level):
self._format(object.data, stream, indent, allowance, context, level - 1)
_dispatch[_collections.UserList.__repr__] = _pprint_user_list
def _pprint_user_string(self, object, stream, indent, allowance, context, level):
self._format(object.data, stream, indent, allowance, context, level - 1)
_dispatch[_collections.UserString.__repr__] = _pprint_user_stringpprint——更方便更美观地打印
def pprint(object, stream=None, indent=1, width=80, depth=None, *,
compact=False, sort_dicts=True):
"""Pretty-print a Python object to a stream [default is sys.stdout]."""
printer = PrettyPrinter(
stream=stream, indent=indent, width=width, depth=depth,
compact=compact, sort_dicts=sort_dicts)
printer.pprint(object)看明白了 PrettyPrinter 类和它的 pprint 方法,后面这些就很好理解了。这个pprint方法是实例化一个PrettyPrinter对象并调用对象的pprint方法。这样我们在使用时只需要 from pprint import pprint,然后pprint(xxx)就行了,不必每次初始化一个对象再调用pprint方法。
pformat——格式化字符串构造器
def pformat(object, indent=1, width=80, depth=None, *,
compact=False, sort_dicts=True):
"""Format a Python object into a pretty-printed representation."""
return PrettyPrinter(indent=indent, width=width, depth=depth,
compact=compact, sort_dicts=sort_dicts).pformat(object) def pformat(self, object):
sio = _StringIO()
self._format(object, sio, 0, 0, {}, 0)
return sio.getvalue()
这个也是为了方便调用,实例化一个PrettyPrinter对象并返回对象的 pformat 方法。pprint 是直接将格式化后的字符串打印出来,pformat是构造好字符串但是不打印出来。也就是说 pprint(test_data) 和 print(pformat(test_data)) 是等效的。
pp——同pprint
def pp(object, *args, sort_dicts=False, **kwargs):
"""Pretty-print a Python object"""
pprint(object, *args, sort_dicts=sort_dicts, **kwargs)原来和pprint是一样的,看来以后只需要 from pprint import pp 了。欧耶,没白看。