Vision Transformer 必读系列之图像分类综述(三): MLP、ConvMixer 和架构分析
文 @ 000007
号外号外:awesome-vit 上新啦,欢迎大家 Star Star Star ~
https://github.com/open-mmlab/awesome-vitgithub.com/open-mmlab/awesome-vit
0 前言
在 Vision Transformer 必读系列之图像分类综述(一):概述 一文中对 Vision Transformer 在图像分类中的发展进行了概述性总结。
在 Vision Transformer 必读系列之图像分类综述(二): Attention-based 一文中对 Vision Transformer 的 Attention-based 部分进行详细说明。
本文则对剩余部分进行说明。
ViT 进展汇总思维导图如下图所示:
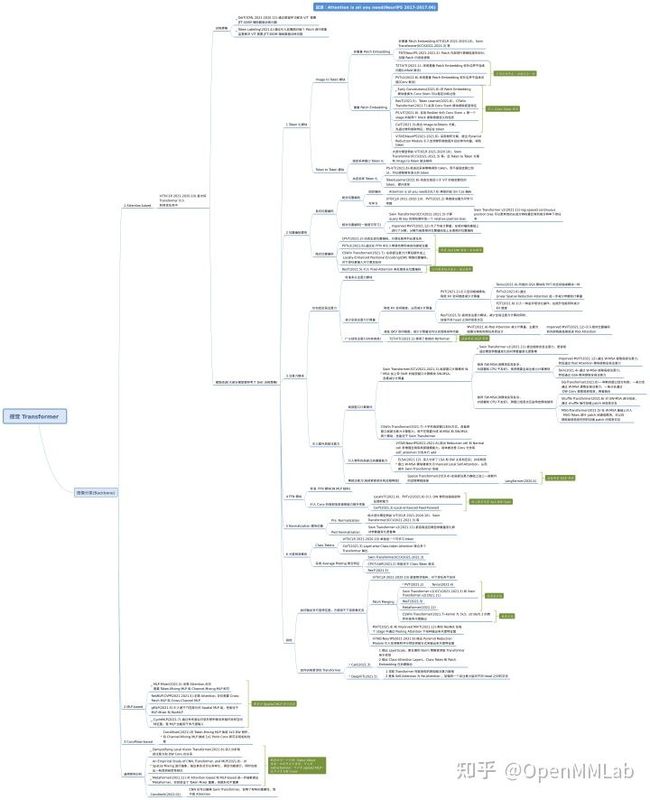
注意:文中涉及到的思维导图,可以通过 https://github.com/open-mmlab/awesome-vit 下载。
1 MLP-based
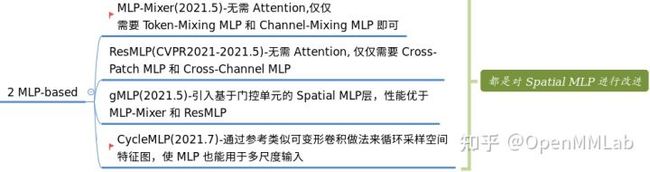
在 Vision Transformer 大行其道碾压万物的同时,也有人在尝试非注意力的 Transformer 架构(如果没有注意力模块,那还能称为 Transformer 吗)。这是一个好的现象,总有人要去开拓新方向。相比 Attention-based 结构,MLP-based 顾名思义就是不需要注意力了,将 Transformer 内部的注意力计算模块简单替换为 MLP 全连接结构,也可以达到同样性能。典型代表是 MLP-Mixer 和后续的 ResMLP。
1.1 MLP-Mixer
虽然 CNN 的卷积操作和 Vision Transformer 注意力在各个架构中都足以获得良好的性能,但它们都不是必需的,如果替换为本文设计的 MLP 结构依然可以取得一致性性能。

- 将图片切分成不重叠的 patch 块 ,将patch 输入到 Pre-patch FC 层中,对每个 patch 进行线性映射,这两个步骤实际上就是 patch embeding 过程,假设输出是 (Patch, C),不同的颜色块代表不同的 patch。
- 将上述 (Patch, C) 输入到 N 个 Mixer Layer 中进行特征提取。
- 最后输出序列经过 global average pooling 聚合特征,然后接上 FC 层进行分类即可。
Mixer Layer 中整体结构和 Transformer 编码器类似,只不过内部不存在自注意力模块,而是使用两个不同类型的 MLP 代替,其分别是 channel-mixing MLPs 和 token-mixing MLPs。channel-mixing MLPs 用于在通道 C 方向特征混合,从上图中的 Channels (每个通道颜色一样) 可以明显看出其做法,而 token-mixing MLPs 用于在不同 patch 块间进行特征混合,其作用于 patch 方向。
在极端情况下,上述两个 Mixer Layer 可以看出使用 1×1 卷积进行通道混合,并使用全感受野的和参数共享的单通道深度卷积进行 patch 混合。反之则不然,因为典型的 CNN 不是 Mixer 的特例。 此外卷积比 MLP 中的普通矩阵乘法更复杂,因为它需要对矩阵乘法和/或专门的实现进行额外的成本降低。代码如下所示,非常简洁。
# 代码是先进行 token mixing 再进行 channel mixing
class MixerBlock(nn.Module):
"""Mixer block layer."""
tokens_mlp_dim: int
channels_mlp_dim: int
@nn.compact
def __call__(self, x):
# (b, patch, c)
y = nn.LayerNorm()(x)
# 交互为 (b, c, patch)
y = jnp.swapaxes(y, 1, 2)
# MlpBlock 作用于 patch 维度,实现 token mixing
y = MlpBlock(self.tokens_mlp_dim, name='token_mixing')(y)
# 交换回来
y = jnp.swapaxes(y, 1, 2)
x = x + y
y = nn.LayerNorm()(x)
# MlpBlock 作用于 C 维度,实现 channel mixing
return x + MlpBlock(self.channels_mlp_dim, name='channel_mixing')(y)
class MlpBlock(nn.Module):
mlp_dim: int
@nn.compact
def __call__(self, x):
y = nn.Dense(self.mlp_dim)(x)
y = nn.gelu(y)
return nn.Dense(x.shape[-1])(y)
结果如下所示,可以看出性能和 ViT 非常接近。

1.2 ResMLP
几乎在同时,ResMLP 也沿着这条思路也进行了一些尝试。示意图如下所示:

从上图来看,几乎和 MLP-Mixer 一样,最核心的两个 MLP 层也是分成跨 patch 交互 MLP 层和跨通道 MLP 层。最后输出也是采用 avg pool 进行聚合后分类。
同时作者观察到如下现象:
- 当使用与 DeiT 和 CaiT 相同的训练方案时,ResMLP 的训练比 ViTs 更稳定,不再需要 BatchNorm、GroupNorm 或者 Layer Norm 等归一化层。作者推测这种稳定性来自于用线性层代替自注意力。
- 使用线性层的另一个优点是仍然可以可视化 patch embeding 之间的相互作用,揭示了类似于和 CNN 一样的学习特性即前面层抽取底层特征,后续层抽取高维语义特征。
MLP-Based 类算法相比 ViT 算法,有如下好处:
- 不再需要自注意力模块
- 不再需要位置编码
- 不再需要额外的 class token
- 不再需要 Batch 等 Norm 统计算子,只需要引入可学习的 affine 层即可
通过 MLP-Mixer 和 ResMLP 大家逐渐意识到 ViT 成功的关键可能并不是注意力机制,这也间接说明了目前大家对视觉 Transformer 架构理解度还是不够,还有很多研究空间。
1.3 CycleMLP
众所周知,MLP 一个非常大的弊端是无法自适应图片尺寸,这对下游密集预测任务不友好,MLP-Mixer 和 ResMLP 都存在无法方便用于下游任务的问题,基于这个缺点,CycleMLP 对 MLP 引入周期采样功能,使其具备了自适应图片尺寸的功能,大大提升了 MLP-based 类算法的实用性。其核心做法如下所示:

将 FC 作用于 Channel 通道即 Channel FC 层可以实现自适应图片尺寸功能,因为其信息聚合维度是 C,而这个维度本身是不会随着图片尺寸而改变,将 FC 作用于 Spatial 维度即 Spatial FC 层无法实现自适应图片尺寸功能,HW 维度会随着图片大小而改变。MLP-Mixer 和 ResMLP 为了聚合信息在自注意力层都会包含 Spatial FC 层和 Channel FC 层。
Spatial FC 层的主要作用是进行 patch 或者序列之间的信息交互,比较关键,无法简单的移除。可以从下面对比实验看下:

为了能够在移除 Spatial FC 层但依然保持 patch 或者序列之间的信息交互能力,论文提出一种循环采样 FC 层 Cycle FC,其属于局部窗口计算机制,周期性地在空间维度进行有序采样,和可变形卷积做法非常类似,实际上代码确实是直接采用可变形卷积实现的,由于比较清晰就不再分析计算过程了。作者绘制了非常详细的可视化图:
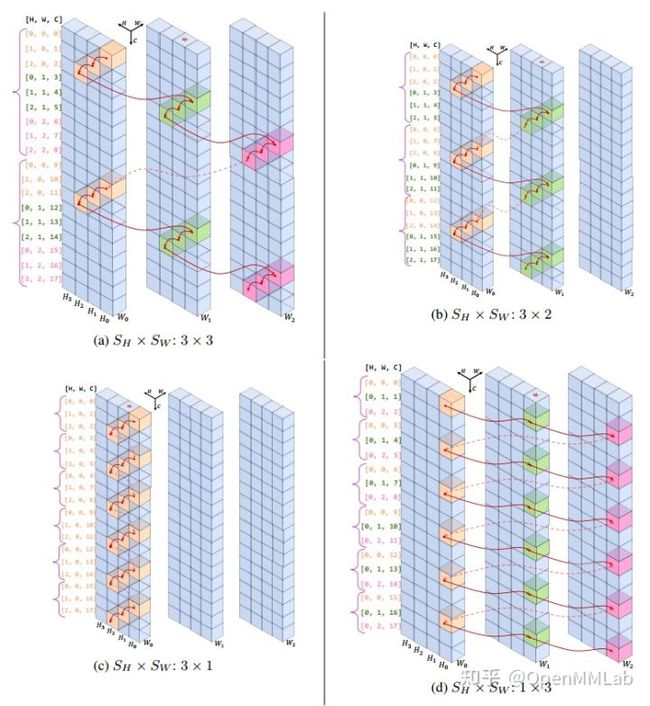
不再将自注意力层输入看出序列 (N,C) 格式,而是视为图片特征 (H, W, C) 格式,此时 Cycle FC 采样的空间维度可以选择 H 或者 W,如果设置 S_H=3 S_W=1,则如图 c 所示,采样方向是 H 方向,W 方向不进行聚合。而 Cycle MLP 模块(下图的 Spatial Proj 模块)实际上由 1x7 的 Cycle FC 层、 7x1 的 Cycle FC 层和 Channel FC 并联,然后相加构成
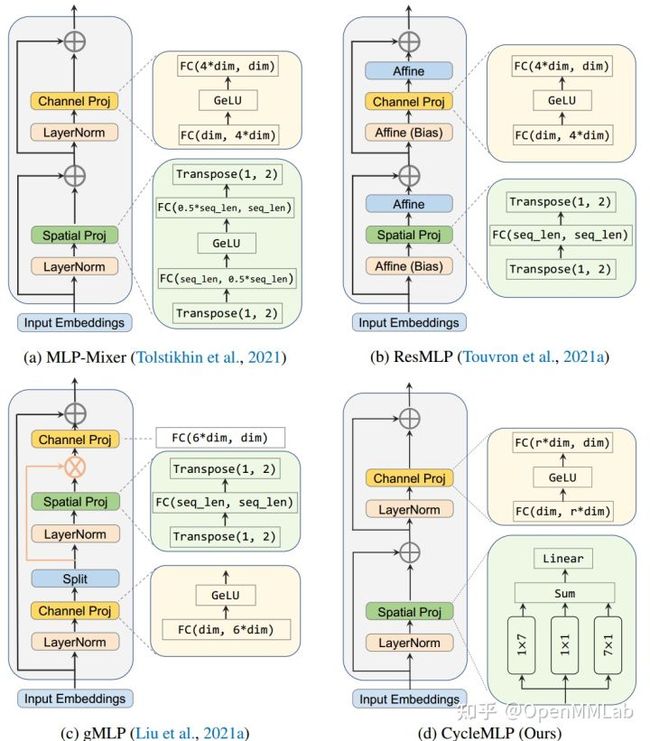
代码如下所示:
class CycleMLP(nn.Module):
def __init__(self, dim, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.mlp_c = nn.Linear(dim, dim, bias=qkv_bias)
# W 方向采样
self.sfc_h = CycleFC(dim, dim, (1, 3), 1, 0)
# H 方向采样
self.sfc_w = CycleFC(dim, dim, (3, 1), 1, 0)
# 通道方向
self.reweight = Mlp(dim, dim // 4, dim * 3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
h = self.sfc_h(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
w = self.sfc_w(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
c = self.mlp_c(x)
a = (h + w + c).permute(0, 3, 1, 2).flatten(2).mean(2)
a = self.reweight(a).reshape(B, C, 3).permute(2, 0, 1).softmax(dim=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x)
return x
作者也对采样过程进行深入分析,对比了另外 2 种采样策略。
- 随机采样,并设置了 3 次不同的种子分别进行实现
- 空洞 stepsize 采样
空洞 stepsize 采样即每隔 stepsize 个位置再进行采样。

实验表明空洞采样效果比随机采样好,但是不如循环采样。
因为 FC 也可以用 Conv 层代替,作者又和 Conv 1x3 和 3x1 核进行比较,Conv 模式相比 CycleMLP 属于密集采样模式,效果居然比稀疏的 CycleMLP 差,作者分析原因是:密集采样模式会引入额外的参数量,为了快速比较将 epoch 相应的缩短到 100 epoch,在这种设置下,可能密集采样会引入额外的冗余参数,不利于优化。
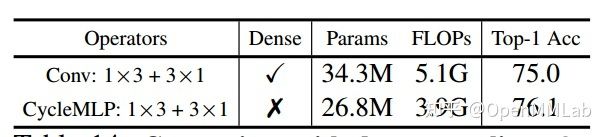
在构建好 CycleMLP 后,将带 CycleMLP FC 层自注意力模块应用于 PVT 和 Swin 中即可无缝的应用于各种密集下游任务,其详细的结构图如下所示,所构建的网络性能优于目前主流的 Swin Transformer。

2 ConvMixer-based
ConvMixer 的含义是:
- 不包括自注意力层
- 不包括 Spatial Mixer MLP 层
- 包括 Channel Mixer 层,这个层可以是 1x1 的点卷积,或者 MLP 层

因为 Channel Mixer MLP 层和 1x1 卷积完全等价,所以这里所说的 ConvMixer-based 是强调 Spatial Mixer 层模块可以替换为 DW 卷积(关于全局自注意力和 DW 卷积的区别和联系,在 3.4.3 中会详细说明)。ConvMixer-based 的典型代表是 ConvMixer,其结构图如下所示:
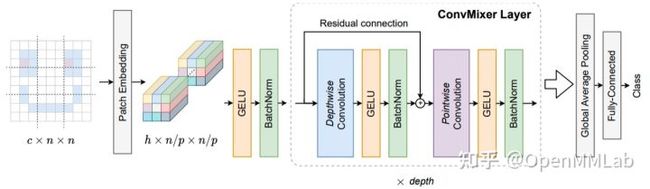

在 MLP Mixer 模型中说过, ViT 的编码器层核心结构可以分成全局空间自注意力层(用于 token 和 token 间信息交互),通道混合 MLP 层(用于每个 token 内的 channle 间信息交互)。ConvMixer 也是沿用了同样的分解策略,只不过替换模块不再是 Spatial Mixer MLP 和 Channel Mixer MLP,而是全部替换为了卷积,分别是 DW Conv 和 1x1 Point Conv。使用 Depthwise Convolution(逐通道卷积) 来提取 token 间的相关信息,类似 MLP Mixer 中的 token-mixing MLP,使用 Pointwise Convolution(1x1 卷积) 来提取 channel 间的相关信息,类似 MLP Mixer 中的 channel-mixing MLP,然后将两种卷积交替执行,混合两个维度的信息。性能如下所示:

本论文核心结论不是强调 DW 卷积的重要性,而是说明 ViT 这种架构的成功不在于是使用了自注意力模块还是 Spatial Mixer MLP,只要有相应的代替结构,性能其实都差不多,我们可能要关注整个 Transformer 架构而不是注意力等模块。这个问题在 3.4.1 中也有详细说明。
3 通用架构分析
前面所提出的 MLP-Mixer 和 ResMLP 已经证明了 ViT 成功的关键可能并不是注意力机制,而是来自其他地方或者说整体架构。基于这个出发点,有大量学者对整个架构进行深入研究,试图从更高维度来理解 Transformer,典型算法如下所示:

3.1 MetaFormer
基于 ResMLP 的自注意力不是必备的而是可以通过 MLP 代替的结论, MetaFormer 作者提出了更进一步的架构抽象,如下所示:
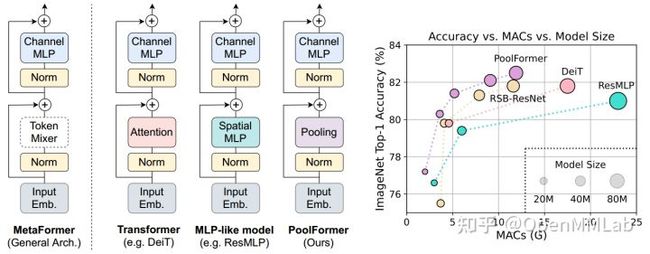
其核心观点和 ResMLP 一致,即 Transformer 模型中自注意力模块不是最核心的(并不是说可以直接去掉),Transformer 的成功来源其整体架构,同时可以将 Transformer 的 Attention 模块和 ResMLP 的 Spatial MLP 层统称为 Token Mixer,进而提出了 MetaFormer 通用结构,Meta 的含义代表 Token Mixer 是一种统称,只要能够实现 Token Mixer 功能的模型都属于 MetaFormer 范畴,例如你也可以将 Token Mixer 换成 3x3 DW 卷积。为了验证这个架构的可行性,作者将 Token Mixer 替换为最简单的无参数的 Pooling 算子,其性能如右边图所示,令人意外的是 PoolFormer 性能居然比 DeiT 和 ResMLP 更好,详细结构如下所示。

由于架构非常简单,不再进行详细描述。以下是基于 PoolFormer 的一些 Ablation。
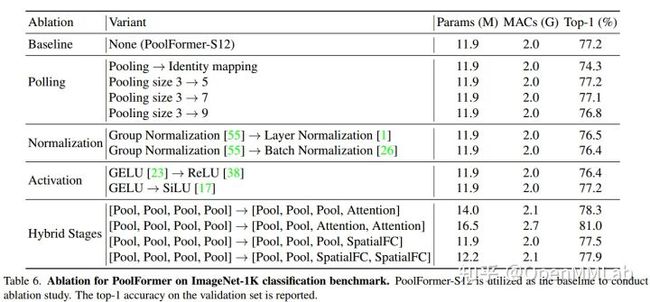
Pooling 模块代码如下:

注意有个减号,原因是 Pooling 模块后面还有一个残差连接线,Pooling 模块中先减掉 x 才能构成可能的恒等变换 x+ (Pool(x)-x) = x,而通常的 Conv 操作是可以通过调整初始化核参数来实现 x+ Conv(x)=x 的。
3.2 Empirical Study
An Empirical Study of CNN, Transformer, and MLP 对现在火热的 CNN、Transformer 和 MLP 之争进行了一些经验性研究,可以带给我们一些启发。
为了能够公平比较,作者首先设计了一个通用的 SPACH 架构,在该框架下引入了 mixing block 概念,其结构如下所示,上面是单阶段 SPACH 表示 ViT 这种直筒结构,多阶段 SPACH 表示 ResNet 这种下采样结构,SPACH-MS 结构可以用于高分辨率图片输入场合,该结构和大部分网络例如 PVT 一样。

内部的 Spatial Mixing 可以即插即用的替换为任意 CNN、Transformer 和 MLP ,如下所示
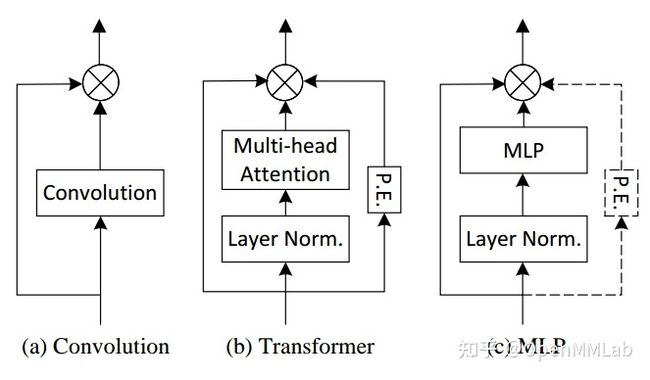
作者对上述三种 Spatial Mixing 模块和单阶段、多阶段 SPACH 模块进行实验,得出了如下经验性结论:
- 无论选择三种网络结构中的哪一种 Spatial Mixing 模块,多阶段框架始终显著优于单阶段框架。这个结论在其他文章中也有相同的描述。
- CNN 这种局部建模是非常有效且至关重要的。在 MLP 和 Transformer 添加一个局部建模旁路,可以在仅增加极少的参数量和计算量的情况下,获得显著的性能提升。这个也同样被大部分论文(例如 CeiT )所证实。
- MLP 在小模型尺寸下可以获得很强的性能,但是在模型尺寸增加时会出现严重的过拟合。作者认为过拟合是 MLP 获得 SOTA 性能的主要障碍。
- 卷积和 Transformer 是互补的,卷积结构的泛化能力最好,而 Transformer 结构的模型容量最大。这表明卷积依然是设计轻量级模型的最佳选择,而在设计大模型时,可以充分考虑 Transformer。
可以说上述 4 条结论已经在各个算法中得到了充分验证,是非常可信的,这也能够启发后续相关网络设计。
3.3 Demystifying Local Vision Transformer
Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight 深入分析了注意力和 Conv 的关系,并进行了大量的实验验证,是一篇值得学习的论文。
Conv 是众所周知的局部提取算子,而 Swin Transformer 中虽然没有借助 Conv ,但是提出了类似功能的局部注意力模块 W-MSA,本文试图深入分析局部注意力机制和 Conv (尤其是 depth-wise convolution )的区别和联系,其关系如下所示:

- (a) 为标准的 3x3 卷积,其同时作用于空间和通道维度
- (b) 为 Transformer 中的全局空间注意力和 Spatial Mixing MLP,作用于空间维度
- (c) 是 Transformer 局部窗口注意力和 3x3 DW 卷积,相比于 (b) 关注空间的局部维度
- (d) 是常规的 MLP 层 和 1x1 点卷积,作用于通道维度
- (e) 是全连接层,作用于整个空间和通道维度
这里需要明确 ViT 中我们所说的全局自注意力实际上是全局空间自注意力,是逐通道算的,通道间没有信息混合,通道信息混合是通过后续的 FFN 模块实现。
通过上图可以清晰的发现局部注意力计算可以采用 3x3 DW 卷积等效替换,并且可以总结出局部注意力的三条特性:
- Sparse connectivity:每个 Token 的输出只依赖于其所在局部窗口内的 Tokens,而且各个 channel 之间是无联系的 (这里忽略了 attention 中 query,key 和 value 的线性投影,attention 可以看成在计算好的权重下对 Tokens 的特征进行加权求和,而且是 channel-wise 的)。
- Weight sharing:权重对于各个 channel 是共享的( (1, HW) X (HW, C) = (1, C),通道维度权重共享)。
- Dynamic weight:权重不是固定的,而是基于各个 Tokens 动态生成的。
DW Conv 具备前两条特性,但是其不是动态权重的,其权重是一旦训练好就固定了,不会随着图片内容不同而改变。下面是总结汇总表格:

作者还进一步描述了 MLP、Conv 等层的联系,如下所示:

从 2d 全连接层 MLP 出发
- 将其功能分成 Token Mixer MLP 和 Channel Mixer MLP,将其统称为 Sep. MLP
- Sep. MLP 如果具备了自适应的动态权重功能,即为 ViT 带注意力的模型
- 而 ViT 如果引入局部窗口计算能力,则称为 Local ViT,如果有空间尺度缩放的多尺度结构则和 PVT 类似
从 2d 全连接层 MLP 出发
- 如果引入稀疏连接功能,则退化为 Conv
- 如果空间存在缩放,则可以构成金字塔结构的 Pyramid MS Conv
- 如果通道维度有瓶颈结构,则构成了 Bottleneck
如果同时具备稀疏连接,仅仅在空间维度信息聚合则为逐深度方向可分离 DW-S Conv。
基于上述等价分析,作者基于 Swin Transformer 提出了 DWNet。
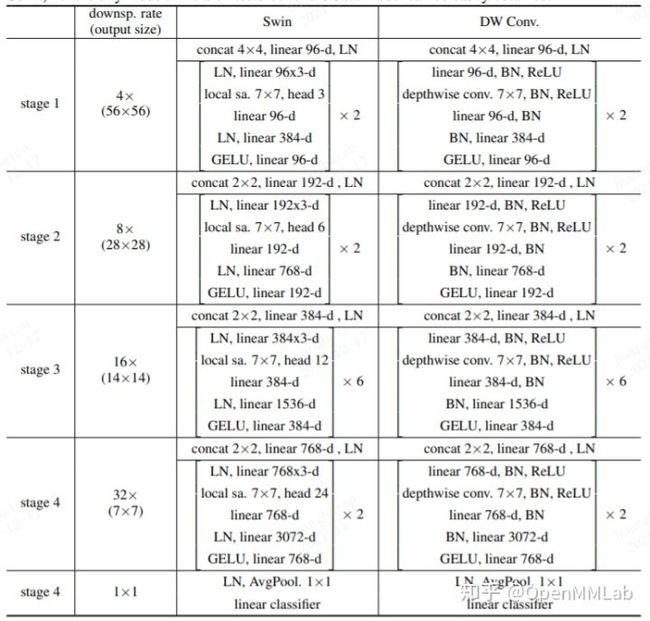
对 Swin Transformer 的改动包括:
- 将 W-MSA 和 SW-MSA 替换为 7x7 的 DW 卷积+BN+Relu 模块
- 将 stage 中的 LN 全部换成 BN
- 为了进一步提高性能,还提出动态权重版本,即将 DW 卷积替换为带有 SE 模块的动态加权 DW (D-DW)
其性能如下所示:

可以看出,如此简单的模型性能和 Swin Transformer 差不多,这也和 ConvMixer 相互印证了。
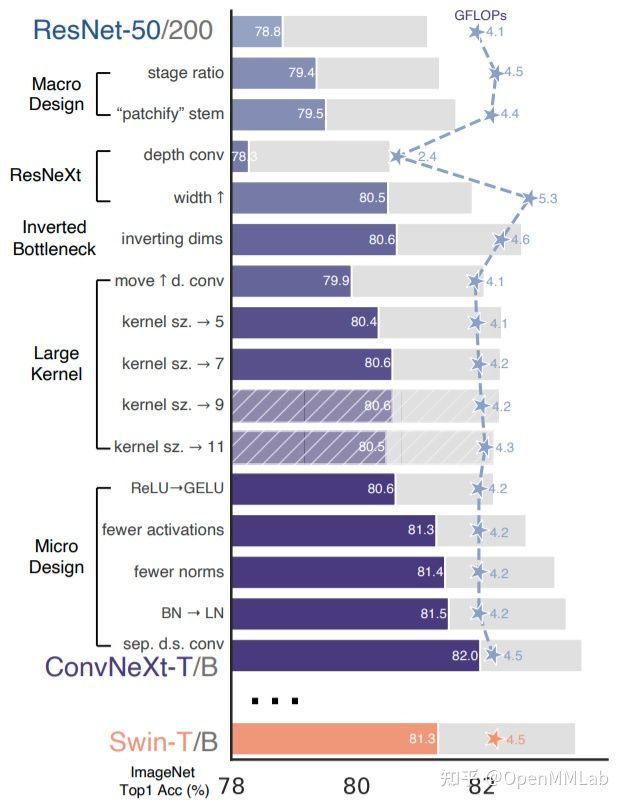
如果说 MetaFormer 还有 Transformer 的影子,那么 ConvNeXt 就是一个更彻底的去 Transformer 的例子了。其核心出发点是纯粹的 Conv 堆叠性能能不能超过 Transformer? ConvNeXt 对 Swin Transformer 进行了逐模块分解,并且将其应用于 ResNet 上,通过不断对比两者差异,作者将 ResNet 改造为 ConvNeXt,性能最终超越 Swin Transformer,证明了纯粹的 Conv 堆叠性能能够超过 Transformer,这也间接说明 Transformer 架构和优化策略的优异性,而不是所谓的 Attention。
4 总结
本文对 Vision Transformer 发展进行了详细的综述,由于内容比较多,下面进行简要总结。
在 Attention is all you need 论文中第一次提出 Transformer 架构,ViT 将其第一次成功推广到了视觉任务领域,DeiT 针对 ViT 需要超大数据预训练问题提出了蒸馏学习训练方式,在解决大数据预训练问题的同时也进一步提高了性能,推动了 ViT 在视觉中的进一步应用的可能。
ViT 的核心在于 Attention,但是整个架构也包括多个组件,每个组件都比较关键,有诸多学者对多个组件进行了改进。我们可以简单将 ViT 结构分成 6 个部分:
- Token 模块,其中可以分成 Image to Token 模块 和 Token to Token 模块, Image to Token 将图片转化为 Token,通常可以分成非重叠 Patch Embeding 和重叠 Patch Embeding,而 Token to Token 用于各个 Transformer 模块间传递 Token,大部分方案都和 Image to Token 做法一样即 Patch Embeding,后续也有论文提出动态窗口划分方式,本质上是利用了图片级别的语义自动生成最有代表性的采样窗口。
- 位置编码模块,其中可以分成显式位置编码和隐式位置编码,显式位置编码表示需要手动设置位置编码,包括绝对位置编码和相对位置编码,而隐式位置编码一般是指的利用网络生成自适应内容的位置编码向量,其提出的主要目的是为了解决显式位置编码中所遇到的当图片尺寸变化时候位置编码插值带来的性能下降问题
- 注意力模块,早期的自注意力模块都是全局注意力,计算量巨大,因此在图片领域会针对性设计减少全局注意力,典型做法是降低 KV 空间维度,但是这种做法没有解决根本问题,因此 Swin Transformer 中提出了局部窗口自注意力层,自注意力计算仅仅在每个窗口内单独计算,不再存在上述问题。
- FFN 模块,其改进方向大部分是引入 DW 卷积增强局部特征提取能力,实验也证明了其高效性。
- Normalization 模块位置,一般是 pre norm。
- 分类预测模块,通常有两种做法,额外引入 Class Token 和采用常规分类做法引入全局池化模块进行信息聚合。
在此之后,我们还分析了如何输出多尺度特征图,方便用于下游密集任务以及如何训练更深的 Transformer。
随着研究的深入,大家发现 attention 可能不是最重要的,进而提出了 MLP-based 和 ConvMixer-based 类算法,这些算法都是为了说明自注意力模块可以采用 MLP 或者 Conv 层代替,这说明 Transformer 的成功可能来自整个架构设计。
进一步,MetaFormer、An Empirical Study of CNN, Transformer, and MLP 和 Demystifying Local Vision Transformer 等论文都详细说明和验证了上面的说法,并都提出了自己各自的看法,这或许也指明了 ViT 的下一步研究方向。
从目前 Vision Transformer 进展来看,目前 CNN 和 attention 的边界已经越来越模糊了,相互可以等价替换,也可以相互增强,谁强谁弱尚未可知,或许 Conv、MLP 和 attention 混合才是最终能够实际落地的出路吧!
至此图像分类综述就完成了,主要包括三篇文章:
- Vision Transformer 必读系列之图像分类综述(一):概述
- Vision Transformer 必读系列之图像分类综述(二): Attention-based
- Vision Transformer 必读系列之图像分类综述(三): MLP、ConvMixer 和架构分析
对 Vision Transformer 系列内容感兴趣的朋友,不要忘记 star 啦~
https://github.com/open-mmlab/awesome-vigithub.com/open-mmlab/awesome-vit
后续我们会对训练 trick 等进行整理,会同步到上述 repository 中,敬请期待!