python 粒子滤波目标追踪_【MOT】详解DeepSORT多目标追踪模型

1. 前言
DeepSORT是目前非常常见的多目标追踪算法(虽说性能一般,但是速度还挺可观,也比较简单),网络上有很多基于不同检测器(YOLO V3/YOLO V4/CenterNet)的DeepSORT实战。
链接分别如下:
(1)YOLO V3+DeepSORT
mikel-brostrom/Yolov3_DeepSort_Pytorchgithub.com
(2)YOLO V4+DeepSORT
https://github.com/theAIGuysCode/yolov4-deepsortgithub.com(3)CenterNet +DeepSORT
https://github.com/kimyoon-young/centerNet-deep-sortgithub.com那么如此通用的一个追踪器(DeepSORT),可以被接在任何一个检测器上(不仅仅是上面提到的)。
我之前做过一个基于YOLOV4+DeepSORT的交通流参数提取,部分效果图如下

上一篇文章中,我们对SORT,特别是SORT中的卡尔曼滤波算法进行了详细解析。链接如下
周威:【MOT】详解SORT与卡尔曼滤波算法zhuanlan.zhihu.com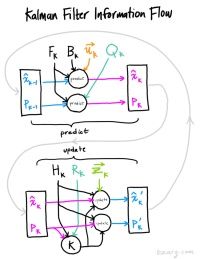
2 DeepSORT中的Deep
光看名字就知道了DeepSORT是SORT算法中的升级版本。那这个Deep的意思,很显然就是该算法中使用到了Deep Learning网络。
那么相比于SORT算法,DeepSORT到底做了哪部分的改进呢?这里我们简单了解下SORT算法的缺陷。
SORT算法利用卡尔曼滤波算法预测检测框在下一帧的状态,将该状态与下一帧的检测结果进行匹配,实现车辆的追踪。
那么这样的话,一旦物体受到遮挡或者其他原因没有被检测到,卡尔曼滤波预测的状态信息将无法和检测结果进行匹配,该追踪片段将会提前结束。
遮挡结束后,车辆检测可能又将被继续执行,那么SORT只能分配给该物体一个新的ID编号,代表一个新的追踪片段的开始。所以SORT的缺点是
受遮挡等情况影响较大,会有大量的ID切换
那么如何解决SORT算法出现过多的ID切换呢?毕竟是online tracking,不能利用全局的视频帧的检测框数据,想要缓解拥堵造成的ID切换需要利用到前面已经检测到的物体的外观特征(假设之前被检测的物体的外观特征都被保存下来了),那么当物体收到遮挡后到遮挡结束,我们能够利用之前保存的外观特征分配该物体受遮挡前的ID编号,降低ID切换。
当然DeepSORT就是这么做的,论文中提到
We overcome this issue by replacing the association metric with a more informed metric that combines motion and appearance information.In particular,we apply a convolutional neural network (CNN) that has been trained to discriminate pedestrians on a large-scale person re-identification dataset.
很显然,DeepSORT中采用了一个简单(运算量不大)的CNN来提取被检测物体(检测框物体中)的外观特征(低维向量表示),在每次(每帧)检测+追踪后,进行一次物体外观特征的提取并保存。
后面每执行一步时,都要执行一次当前帧被检测物体外观特征与之前存储的外观特征的相似度计算,这个相似度将作为一个重要的判别依据(不是唯一的,因为作者说是将运动特征与外观特征结合作为判别依据,这个运动特征就是SORT中卡尔曼滤波做的事)。
那么这个小型的CNN网络长什么样子呢?论文中给出了结构表,如下

那么这个网络最后输出的是一个128维的向量。有关残差网络和上图表中残差模块的结构就不多说,很简单。
值得关注的是,由于DeepSORT主要被用来做行人追踪的,那么输入的大小为128(高)x 64(宽)的矩形框。如果你需要做其他物体追踪,可能要把网络模型的输入进行修改。
实现该网络结构的代码如下:
class 可以看出,网络的输出为分类数,并不是128。那么后面想要提取图像的特征,只需要在使用过程中,将最后一层classifier忽略即可(128维向量为输入到classifier前的特征图)。
3 DeepSORT中的卡尔曼滤波
我们在SORT深度解析时提到过,SORT中的卡尔曼滤波算法使用的状态是一个7维的向量。即

在DeepSORT中,使用的状态是一个8维的向量
相较于SORT中的状态,多了一个长宽比(aspect ratio)的变化率。这是合情合理的,毕竟像SORT中假设物体检测框的长宽比是固定的,实际过程中,随着镜头移动或者物体与相机的相对运动,物体的长宽比也是会发生变化的。
同时,DeepSORT对追踪的初始化、新生与消失进行了设定。
- 初始化:如果一个检测没有和之前记录的track相关联,那么从该检测开始,初始化一个新的目标(并不是新生)
- 新生:如果一个目标被初始化后,且在前三帧中均被正常的捕捉和关联成功,那么该物体产生一个新的track,否则将被删除。
- 消失:如果超过了设定的最大保存时间(原文中叫做predefined maximum age)没有被关联到的话,那么说明这个物体离开了视频画面,该物体的信息(记录的外观特征和行为特征)将会被删除。
具体有关卡尔曼滤波算法,建议您看看之前我在SORT分析时给出的链接和我的分析。
周威:【MOT】详解SORT与卡尔曼滤波算法zhuanlan.zhihu.com
4. DeepSORT中的分配问题
惯例中(类似SORT),解决分配问题使用的是匈牙利算法(仅使用运动特征计算代价矩阵),该算法解决了由滤波算法预测的位置与检测出来的位置间的匹配。DeepSORT中,作者结合了外观特征(由小型CNN提取的128维向量)和运动特征(卡尔曼滤波预测的结果)来计算代价矩阵,从而根据该代价矩阵使用匈牙利算法进行目标的匹配。
- 运动(motion)特征
作者使用了马氏距离,用来衡量预测到的卡尔曼滤波状态和新获得的测量值(检测框)之间的距离。

上述公式中
马氏距离通过测量卡尔曼滤波器的追踪位置均值(mean track location)之间的标准差与检测框来计算状态估计间的不确定性,即
值得注意的是,这里的两个符号含义分别为
- i:追踪的序号
- j:检测框的序号
i,j的含义将在后面的解析中仍然出现。
使用对马氏距离设定一定的阈值,可以排除那些没有关联的目标。文章中给出的阈值是
the Mahalanobis distance at a 95% confidence interval computed from the inverse χ2 distribution.
就是倒卡方分布计算出来的95%置信区间作为阈值。
有关马氏距离的实现,定义在Tracker类中可以获得,代码如下:
def 显然当目标运动过程中的不确定度比较低(马氏距离小)的时候(也就是满足卡尔曼滤波算法的假设,即所有物体的运动具有一定规律,且没有什么遮挡),那么基于motion特征的方法,即上面提到的方法(可是视为改进的SORT)自然有效。
但是实际情况哪有那么理想,所有仅靠motion特征是不行的了,需要用到appearance特征来弥补不足。
2. 外观(appearance)特征
前面我们提到了外观特征提取网络——小型的残差网络。该网络接受reshape的检测框(大小为128x64,针对行人的)内物体作为输入,返回128维度的向量表示。
对于每个检测框(编号为j)内物体
接着作者对每个目标k创建了一个gallery,该gallery用来存储该目标在不同帧中的外观特征(128维向量),论文中用
注意,这里的k的含义是追踪的目标k,也就是object-in-track的序号。为了区分i和k,我画了个示意图,如下。

作者原论文是这么提到的

这里的
接着在某一时刻,作者获得出检测框(编号为j)的外观特征,记作

接着作者对最小余弦距离设定了阈值,来区分关联是否合理,如下

3. 运动(motion)特征与外观(appearance)特征的融合
motion特征和appearance特征是相辅相成的。在DeepSORT中,motion特征(由马氏距离计算获得)提供了物体定位的可能信息,这在短期预测中非常有效。
appearance特征(由余弦距离计算获得)可以在目标被长期遮挡后,恢复目标的ID编号,减少ID切换次数。
为了结合两个特征,作者做了一个简单的加权运算。也就是
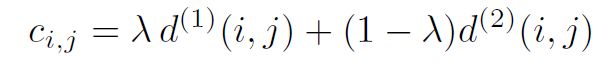
这里的
最后,作者设定了如何判断关联是否匹配的判别总阈值,作者提到
where we call an association admissible if it is within the gating region of both metrics
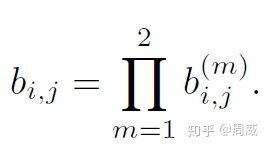
作者将上面提到的两个阈值(分别为马氏距离和余弦距离的阈值)综合到了一起,联合判断该某一关联(association)是否合理可行的(admissible)。
4 更多匹配的细节
论文中作者提到了Matching Cascade,该算法流程的伪代码如下:

输入:该算法接受三个输入,分别为
- 追踪的索引集合
,
,i在前面已经讲过了。
- 当前帧检测框索引的集合
,
,j在前面已经讲过了。
- 最大保留时长(Maximum age)
步骤1:根据上面图名为公式3的公式,计算联合代价矩阵;
步骤2:根据上面图名为公式4的公式,计算gate矩阵;
步骤3:初始化匹配列表
步骤4:初始化非匹配列表
步骤5:循环
- 按照给定的age选择track
- (使用匈牙利算法)计算最小代价匹配时的i,j
- 将满足合适条件的i,j赋值给匹配列表
,保存
- 重新更新非匹配列表
步骤6:循环结束,匹配完成
返回:匹配列表
代码实现如下:
def 和上面的伪代码一一对应,很清晰。
至此,有关DeepSORT就讲解结束了。如果有疑问的话,建议多阅读一下原文和代码。
5. 总结
本文中如果存在错误解读,欢迎大家留言告诉我,我们共同进步!未来本专栏将开始对目标追踪的其他文章进行解读,欢迎大家关注!