【UG474】可配置逻辑块(configurable logic block,CLB)资源学习
目录
- 1 CLB概述
-
- 1.1 CLB结构
- 1.2 设计流程建议
- 2 CLB架构细节
-
- 2.1 CLB 排列
-
- 2.1.1 ASMBL架构
- 2.1.2 CLB slice
- 2.1.3 CLB/SLICE 配置
- 2.2 slice 描述
- 2.3 查找表(LUT)
- 2.4 存储单元
-
- 2.4.1 控制信号
- 2.5 分布式RAM(仅SLICEM)
-
- 2.5.1 实现多位宽的形式
- 2.5.2 实现多端口的形式
- 2.5.1 分布式RAM数据流
-
- 同步写操作
- 异步读操作
- 2.5.2 分布式RAM总结
- 2.5.3 只读存储器(ROM)
- 2.6 移位寄存器(仅SLICEM)
-
- 2.6.1 移位寄存器数据流
- 2.6.2 移位寄存器总结
- 2.7 数据选择器
- 2.8 进位逻辑
1 CLB概述
1.1 CLB结构
可配置逻辑块(configurable logic block,CLB)提供高级、高性能的FPGA逻辑:
- 6输入查找表(6-input look-up table ,LUT)
- 双5输入查找表(LUT5)选项
- 分布式内存和移位寄存逻辑能力
- 用于算术功能的专用高速进位逻辑
- 多路复用器
CLB是实现时序电路和组合电路的主要逻辑资源。每个CLB单元都连接到一个switch matrix,为了访问通用的路由矩阵。每个CLB单元包含一对Slice:

LUT可以配置为单个输出的6输入LUT,或者两个5输入LUT(同地址或逻辑输入,不同的输出)。每个5输入LUT的输出可以选择被触发器寄存。
CLB结构:
- 四个6输入LUT和对应的8个触发器、数据选择器(multiplexer)、算术单元(arithmetic)以及 进位逻辑(carry logic) 组成一个slice。
- 两个slice形成一个CLB。
- 每个slice的4个触发器(每个LUT对应一个触发器)可以选择配置为锁存器。在这种情况下,该slice中的其余4个触发器不可用。
上述slice被称为SLICEL。大约三分之二的slice是SLICEL,其余的是SLICEM。
SLICEM可以将其LUT用作分布式64位RAM或32位移位寄存器(SRL32)或两个SRL16。
SLICEL(L:Logic):

SLICEM(M:Memory):

1.2 设计流程建议
CLB资源是为通用设计逻辑推断的,不需要实例化。好的HDL设计需要注意的几点:
-
CLB触发器有set和reset。设计者不能同时使用set和reset。
-
触发器很充足。所以考虑用流水线提升性能。
-
控制输入是跨slice或CLB共享的。设计所需的独特控制输入的数量应尽量减少。控制输入包括时钟、时钟使能、设置/重置和写使能。
-
一个6输入的LUT可以作为一个32位移位寄存器,为了高效的implementation。
-
一个6输入的LUT可以作为一个64x1存储,用于小型存储需求。
-
专用进位逻辑高效地实现了算术功能。
这些步骤表明了推荐的设计流程:
- 使用首选的方法(HDL, IP等)实现设计。
- 评估资源利用率报告以确定所使用的资源。如果有用的话,检查确保使用了算术逻辑、分布式RAM和SRL。
- 考虑触发器用法:
- 流水线提高性能
- 在专用资源(块RAM, DSP)的输出上使用专用触发器
- 允许移位寄存器使用SRL(避免 set/resets)
- 尽量减少使用set/resets。
2 CLB架构细节
2.1 CLB 排列
7系列FPGA 的 CLB按列排列,7系列是基于Xilinx高级硅模块(Advanced Silicon Modular Block,ASMBL)体系结构的第四代。
2.1.1 ASMBL架构
Xilinx创建了高级硅模块(ASMBL)体系结构,以支持具有针对不同应用领域优化的不同特性混合的FPGA平台。

以7k325t-ffg676为例,其X0Y0时钟域下资源排布为:

211203补充:
关于各资源的排列,以高速收发器为例,Left Side对应的是手册以及Implementation Device视图的左边一列,每隔Clock Region有四个收发器,所以我们可以根据Clock Region来推测GT的坐标编号,比如Clock Region X0Y4对应的GT CHANNEL编号为GTHE2_CHANNEL_X0Y16~19,对应的GT COMMON 编号为GTHE2_COMMON_X0Y4。同理,这个时钟域的MMCM和PLL的编号分别为:MMCME2_ADV_X0Y4 和 PLLE2_ADV_X0Y4。
各种功能基元按列排列。
- 消除几何布局约束,如I/O计数和数组大小之间的依赖关系。
- 通过允许电源和地被放置在芯片上的任何地方,增强片上电源和地分布
- 允许完全不同的集成IP块独立于彼此和周围的资源进行比例调节。
SSI技术:
堆叠硅片互联(stacked silicon interconnect,SSI)技术。允许多个超逻辑区域( super logic region,SLR)在一个passive interposer 层上组合,以创建一个具有超过10,000个SLR间连接的单片FPGA。
2.1.2 CLB slice
一个CLB包含两个SLICE(两个SLICEL(CLB_LL),或一个SLICEL一个SLICEM(CLB_LM)),每个SLICE包含四个LUT6,八个存储单元。
- SLICE(0): CLB左下角
- SLICE(1):CLB右上角
一个CLB的两个SLICE没有直接的连接。每个SLICE都是以列为组织的,在列结构上有一个独立的进位链。
Xilinx工具使用以下定义来命名SLICE:
- 一个“X”后面跟着一个数字,表示每个SLICE在 SLICE对 中的位置 以及 SLICE的列位置。“X”数从序列0,1(第一个CLB列)的底部开始计数;2、3(第二个CLB列);等。
- “Y”后面跟着一个数字,表示一行SLICE。在同一CLB中,这个数字相同,但是从一个CLB行到下一个CLB行依次计数,从底部开始。
其实就是SLICE的坐标计数:

为什么与Device示意图中的计数不一致?Device示意图同一个CLB的两个SLICE位于同一行。
2.1.3 CLB/SLICE 配置
一个CLB的资源:
| slice | LUT | Flip-Flop | 算术及进位链 | 分布式RAM(仅SLICEM) | 移位寄存器(仅SLICEM) |
|---|---|---|---|---|---|
| 2 | 8 | 16 | 2 | 256bit(2^6*4) | 128bit |
2.2 slice 描述
每个Slice包含:
- 四个逻辑函数(logic-function)产生器(或查找表)
- 八个存储单元
- 多功能数据选择器
- 进位逻辑
所有slice都使用这些单元来提供逻辑、算术和ROM功能。此外,SLICEM还支持两个额外的功能:使用分布式RAM存储数据 和 使用32位寄存器进行数据移位。
SLICEM结构:

SLICEL结构:

2.3 查找表(LUT)
功能产生器使用六输入查找表实现,每个LUT有六个独立的输入(A1-A6),两个独立的输出(O5-O6)。一个SLice中的四个LUT分别以A B C D编号。
功能产生器可以实现:
- 任意的六输入布尔函数
- 两个任意的五输入的布尔函数,只要这两个函数共享共同的输入
- 两个任意的3和2个或更少输入的布尔函数
一个六输入函数使用:
- A1-A6
- O6
两个任意的少于五输入的布尔函数使用:
- A1-A5
- A6接高电平
- O5,O6
通过LUT的传播延迟与所实现的功能无关。
来自函数生成器的信号可以:
- 直接出Slice(通过A,B,C,D 输出O6,或通过AMUX, BMUX, CMUX, DMUX输出O5)
- 从O6输出进入专用异或XOR门
- 从O5输出进入进位逻辑链(carry-logic chain)
- 从O6输出进入进位逻辑多路选择器的选择行
- 提供存储单元的D输入
- 从O6输出到F7AMUX/F7BMUX宽多路选择器
除了基本的lut外,slice还包含三个多路选择器(F7AMUX、F7BMUX和F8MUX)。这些多路选择器用于组合4个函数生成器,以提供任何slice中7或8个输入的任何函数。
- F7AMUX: 用于从LUT A和B生成7个输入函数
- F7BMUX: 用于从LUT C和D生成7个输入函数
- F8MUX: 用于组合所有lut生成8个输入函数。
就是说,如果需要实现7输入的函数,就需要将最下面两个LUT(A,B)组合起来,并使用一个数据选择器F7AMUX来选择输出数据,如果是8输入,则在两个两个7输入的基础上,再增加一个数据选择器F8MUX。
具有八个以上输入的函数可以使用多个slice来实现。在CLB中,slice之间没有直接连接以形成大于8个输入的函数生成器。
我们可以看到,再Vivado的Device视图中,LUT6的结构:
SLICEL的LUT6:

SLICEM的LUT6:

LUT6内部是怎么连接的?为什么示意图没有A6、O6的连接?
无论是UG474(7 Series FPGAs CLB User Guide)、UG574(UltraScale Architecture CLB User Guide)都没有提到。而UG384(Spartan-6 FPGA CLB User Guide)中有关于其LUT6的结构图:

根据这个结构图就可以更好的理解,为什么LUT6只能从O6输出,而LUT5既可以从O5输出也可以从O6输出。
A1-A5为LUT6内部两个LUT5的公用地址,而A6是作为两个LUT5的输出选择信号的。
SLICEM的LUT6的读地址A同样为6位,为什么写地址(WA)有8位?
高两位为了实现深度大于64的分布式RAM时作为数据选择信号。
2.4 存储单元
每个slice有8个存储单元。四个可以配置为边沿触发D型触发器或电平敏感的锁存器。D输入可以直接由LUT输出通过AFFMUX, BFFMUX, CFFMUX,或DFFMUX驱动,或由BYPASS slice通过AX, BX, CX,或DX输入,绕过函数生成器。当配置为latch时,CLK为Low时latch是直通的。
另外四个存储单元只能配置为边沿触发D型触发器。D输入可以由LUT的O5输出驱动,或BYPASS slice通过AX, BX, CX,或DX输入。当其他四个存储元素被配置为latch时,这四个额外的存储元素不能被使用。

2.4.1 控制信号
时钟(CLK)、时钟使能(CE)、set/reset(SR):一个slice内的所有存储单元公用。
当slice的一个触发器启用SR或CE,因为共用信号的原因,这个slice的其他触发器也会启用。
我们可以看到只有CLK的输入有一个极性选择器,只有CLK的有效极性可编程,CE和SR都是高电平有效。
存储单元的初始化选项:
- SRLOW:当CLB SR断言时,同步或异步reset
- SRHIGH:当CLB SR断言时,同步或异步set
- INIT0:通电时异步reset或全局Set/Reset
- INIT1: 通电时异步set或全局Set/Reset
SR信号强制存储元素进入SRHIGH或SRLOW属性指定的状态。当断言SR时,SRHIGH强制存储元素输出逻辑为High,而SRLOW强制存储元素输出逻辑为Low。
| SR | SRVAL | 功能 |
|---|---|---|
| 0 | SRLOW (默认) | 无逻辑转换 |
| 1 | SRLOW (默认) | 0 |
| 0 | SRHIGH | 无逻辑转换 |
| 1 | SRHIGH | 1 |
SRHIGH和SRLOW可以为slice中的每个存储元素单独设置。
不能为slice中的每个存储元素单独设置同步(SYNC)或异步(ASYNC)设置/重置(SRTYPE)。
配置后的初始状态或全局初始状态由单独的INIT0和INIT1属性定义。默认情况下,设置SRLOW属性会设置INIT0,设置SRHIGH属性设置INIT1。7系列设备可以独立设置SRHIGH和SRLOW的INIT0和INIT1。
一个寄存器或四个能够起锁存功能的存储元件的set和reset功能的配置选项是:
- 无set或reset
- 同步set
- 同步reset
- 异步set (preset)
- 异步reset (clear)
2.5 分布式RAM(仅SLICEM)
SLICEM中的函数产生器(或LUT)可以配置为被称为分布式RAM单元的 同步RAM资源。
SLICEM中的多个LUT可以通过多种方式组合。
RAM单元通过SLICEM来实现以下配置:
| RAM | 描述 | 原语 | LUT数量 |
|---|---|---|---|
| 32 x 1-bit | Single-Port | RAM32x1S | 1 |
| 32 x 1-bit | Dual-Port | RAM32x1D | 2 |
| 32 x 2-bit | Quad-Port | RAM32M | 4 |
| 32 x 6-bit | Simple Dual-Port | RAM32M | 4 |
| 64 x 1-bit | Single-Port | RAM64x1S | 1 |
| 64 x 1-bit | Dual-Port | RAM64x1D | 2 |
| 64 x 1-bit | Quad-Port | RAM64M | 4 |
| 64 x 3-bit | Simple Dual-Port | RAM64M | 4 |
| 128 x 1-bit | Single-Port | RAM128x1S | 2 |
| 128 x 1-bit | Dual-Port | RAM128x1D | 4 |
| 256 x 1-bit | Single-Port | RAM256x1S | 4 |
我们知道一个LUT6的存储大小为64bit。
2.5.1 实现多位宽的形式
以32x2为例,总存储容量为64bit,所以只需要一个LUT6。当LUT6配置为SPRAM32(single port RAM 32 depth),内部的两个LUT5深度为32,分别存储一个bit。此时A6和WA6都要拉高以同时再O5和O6分别输出两个LUT5的值。当然,并没有单端口32x2bit的工作模式,这里只是为了说明多位宽的工作方式。

如果需要6bit位宽,就需要三个LUT6来拓展。
2.5.2 实现多端口的形式
如果需要实现多个端口,比如64x1bit 双端口,实际实现方式是写数据的时候同时往两个LUT6写数据,其中一个LUT6分别可以用于读写,而另一个则实现一个只读端口。

分布式RAM模块是同步(写)资源。同步读可以通过触发器来实现。
通过这些触发器,降低了clock-to-out 的延迟,所以提升了分布式RAM的性能。然而,增加了一些额外的时钟延时。
这些分布式元件共享相同的时钟输入。对于写操作,由SLICEM的CE或WE引脚驱动的write Enable (WE)输入必须设置为high。
分布式RAM的配置包括:
-
单端口
- 用于同步写和异步读的通用地址端口
- 读写地址共享同一地址总线
- 用于同步写和异步读的通用地址端口
-
双端口
- 一个用于同步写和异步读的端口
- 一个函数生成器连接到共享的读和写端口地址
- 一个端口用于异步读取
- 第二个函数生成器将A输入连接到第二个只读端口地址,而WA输入与第一个读/写端口地址共享
- 一个用于同步写和异步读的端口
-
简单双端口
- 一个用于同步写的端口(从写端口没有数据输出/读端口)
- 一个端口用于异步读取
-
四端口
- 一个用于同步写和异步读的端口
- 三个端口用于异步读取
2.5.1 分布式RAM数据流
同步写操作
同步写操作是单时钟沿操作,当WE为高,数据D加载进地址A。
异步读操作
地址A决定SPO输出。双端口时,地址DPRA决定DPO输出。
每次地址变化,延迟访问LUT的时间后输出该地址的内存数据值。
2.5.2 分布式RAM总结
- 具有Single-port 和dual-port 模式
- 写操作需要一个时钟沿
- 读操作是异步的(Q输出)
- 数据输入具有 setup-to-clock 的时序规范
2.5.3 只读存储器(ROM)
SLICEL和SLICEM都可以实现64x1bit ROM。
可以配置成三种:ROM64X1, ROM128X1, 和 ROM256X1
在给FPGA program时配置加载ROM。
2.6 移位寄存器(仅SLICEM)
SLICEM可以在不使用触发器的条件下配置为32位移位寄存器。这样,每个LUT可以将串行数据延迟1到32个时钟周期。
移位输入D(LUT DI1脚)和移位输出Q31(LUT MC31脚)可以进行级联,以形成更大的移位寄存器。一个SLICEM的4个LUT6级联可以实现128个时钟周期的延时。
多个SLICEM也可以进行组合。但SLICEM之间没有直接连接以形成更长的移位寄存器,在LUT B/C/D处的MC31输出也没有。由此产生的可编程延迟可用于平衡数据pipeline的时间。
移位寄存器的应用:
- 延迟或延迟补偿
- 同步FIFO和内容寻址存储器(CAM)
32位移位寄存器的结构:

占用一个函数生成器的移位寄存器配置的示例:

关于 SRLC32E 和 SRL16E,看UG953。
这个移位寄存器的实现,输入的数据往LUT中压入,而读数据地址一致保存要移位的数,比如读地址为8,那么就输出延迟9拍的数据。
2.6.1 移位寄存器数据流
- 输入(D)被加载到移位寄存器的第一个位
- 前一个位被移到下一个位置并出现在Q输出上,最高位移到MC31输出。
- 移位寄存器长度为(N + 1),其中N为输入地址(0-31)
2.6.2 移位寄存器总结
- 一个移位操作需要一个时钟沿
- 对LUT的Q输出的动态移位长度读操作是异步的
- 对LUT的Q输出的静态移位长度读取操作是同步的
- 数据输入具有 setup-to-clock的时序规范
- 在可级联配置中,Q31输出总是包含最后一位值
- Q31输出在每次移位操作后同步变化
2.7 数据选择器
可以实现的功能:
- 使用1个LUT实现4:1数据选择器
- 每个slice 4个4:1MUX

就是将4路DATA都保存在LUT中,根据选择信号SEL来输出对于情况的数据就行。
对应的LUT数据为:

- 使用2个LUT实现8:1数据选择器
- 每个slice 2个8:1MUX

- 使用4个LUT实现16:1数据选择器
- 每个slice 1个16:1MUX

2.8 进位逻辑
除了函数生成器,还提供了专用的快速超前进位逻辑(fast lookahead carry logic),用于在slice中执行快速算术加减运算。
7系列FPGA的CLB有两个分离的进位链(每个slice各一个),进位链可级联形成更宽的加减逻辑。
进位链向上运行,每各slice高度为4位。对于每一位,都有一个进位数据选择器(MUXCY)和一个专用的异或门,用于用选定的进位位加/减操作数。专用进位路径和进位数据选择器(MUXCY)也可用于级联函数生成器,以实现广泛的逻辑函数。
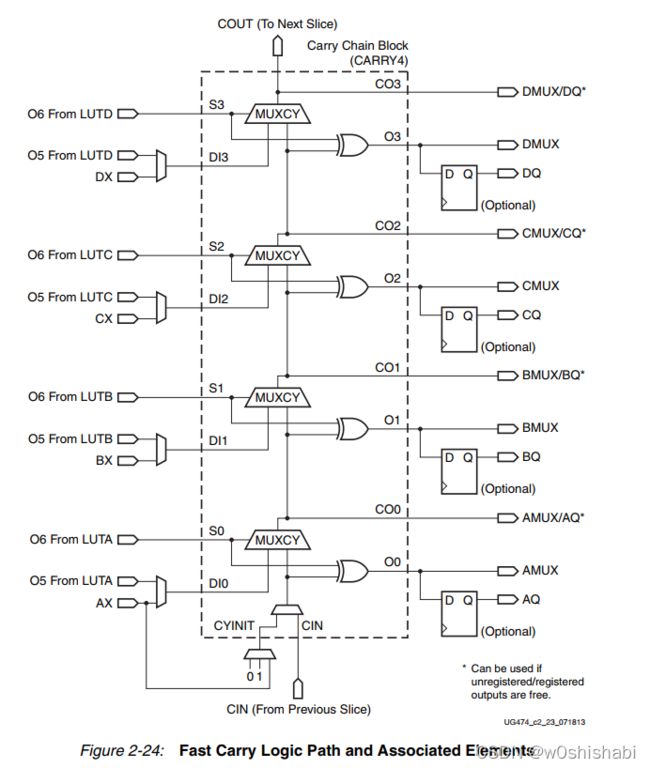
进位链使用超前进位逻辑,配合函数生成器使用。有10个独立输入,8个独立输出:
- 输入:
- S输入:S0-S3
- 超前进位逻辑的“propagate”信号。
- 来源于函数生成器的O6输出
- DI输入:DI1-DI4
- 超前进位逻辑的“generate”信号。
- 来自函数生成器的O5输出
- 创建一个multiplier
- 或者是slice的BYPASS输入(AX,BX,CX,DX)
- 创建adder/accumulator
- CYINIT
- 进位链中第一个比特的CIN
- 0表示加
- 1表示减
- 为动态第一进位位的AX输入
- 进位链中第一个比特的CIN
- CIN
- 级联slice形成更长的进位链
- S输入:S0-S3
- 输出:
- O输出:O0-O3
- 包含加或减的结果
- CO输出:CO0-CO3
- 计算每个位的进位
- CO3与slice的COUT输出相连,多个slice级联形成较长的进位链
- O输出:O0-O3
当更多的进位链级联时,加法器的传播延迟随操作数中的比特数线性增加。进位链可以用同一片中的存储元件或触发器来实现。
进位逻辑级联仅受slice列高度的限制。在使用堆叠硅互连(SSI)技术的设备中,进位逻辑不能跨超逻辑区域(SLR)级联。