java-mahout根据用户或物品数据过滤推荐(开源)
业务场景:
在学研究ava过程中想做一个智能的推荐系统,千人千面智能推荐。在翻阅资料过程中看到了mahout这个机器学习算法库,感觉很实用,无奈与文档是英文(真是扑街gai了)。那就看看咱们大csdn的文章吧,不过大家给的示例都是用的简单推荐器,也就是无法基于用户的属性(如用户性别等)、物品属性(物品的分类)进行过滤推荐,都是基于用户为物品打分的这么一个数据模型进行推荐,这是灾难的又不精准。因此写下这篇文章讲述实现结合用户数据及物品数据过滤推荐。
mahout介绍
Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
主要优势在于它的协同过滤算法,它在市场上非常可靠也是成功的。
测试模型示例:MovieLens | GroupLens
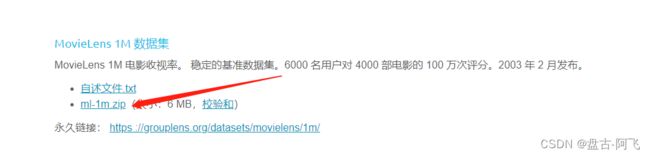
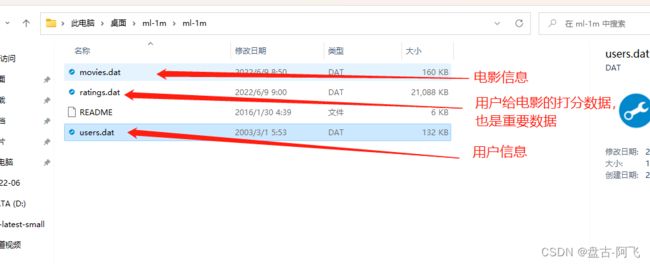
将这三个数据该为csv格式,因为本文使用的是FileDataModel类加载。
代码具体实现:
引入包:
org.apache.mahout
apache-mahout-distribution
0.11.2
zip
1、基于用户属性数据实现
分析数据,users.csv这个文件是用户的信息数据,它包含了用户id,用户性别,用户年龄等。
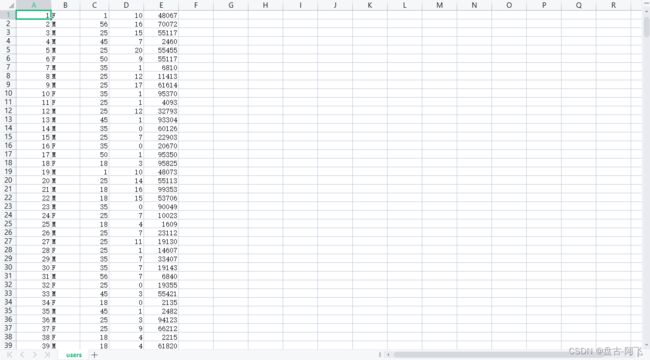
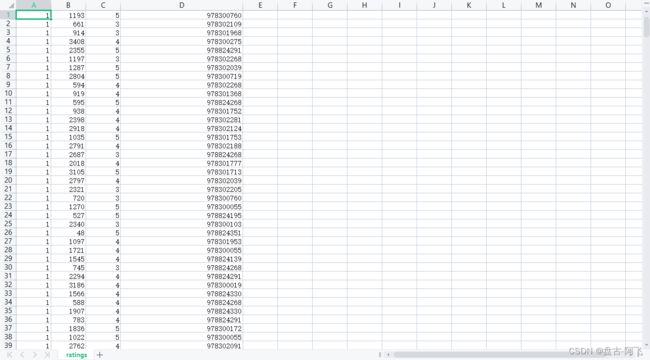
ratings.csv文件为用户为电影的评分数据。分别为用户id,电影id,评分,时间。
代码实现:
package com.example.ai;
import lombok.SneakyThrows;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.IDRescorer;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
@SpringBootApplication
public class AiApplication {
@SneakyThrows
public static void main(String[] args) {
//1)准备数据 这里是电影评分数据
File file = new File("D:\\ratings.csv");
//2)将数据加载到内存中,GroupLensDataModel是针对开放电影评论数据的
DataModel dataModel = new FileDataModel(file);
//3)计算相似度,相似度算法有很多种,欧几里得、皮尔逊等等。
UserSimilarity Similarity = new PearsonCorrelationSimilarity(dataModel);
//4) 计算最近邻域,邻居有两种算法,基于固定数量的邻居和基于相似度的邻居,这里使用基于固定数量的邻居
UserNeighborhood userNeighborhood = new NearestNUserNeighborhood(50, Similarity, dataModel);
//5)构建推荐器,协同过滤推荐有两种,分别是基于用户的和基于物品的,这里使用基于用户的协同过滤推荐
GenericUserBasedRecommender recommender = new GenericUserBasedRecommender(dataModel, userNeighborhood, Similarity);
//加载用户信息数据模型,过滤性别后的用户id数据。
Set userids = getMale("D:\\users.csv");
IDRescorer rescorer = new FilterRescorer(userids);
//通过recommender.recommend实现过滤推荐,为用户id为9的推荐10个电影
List recommend = recommender.recommend(9, 10, rescorer);
//开始计算处理时间
long start = System.currentTimeMillis();
//打印推荐的结果
for (RecommendedItem recommendedItem : recommend) {
System.out.println(recommendedItem);
}
//结束时间
System.out.println(System.currentTimeMillis() -start);
}
/**
* 获得男性用户ID
*/
public static Set getMale(String file) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(new File(file)));
Set userids = new HashSet();
String s = null;
while ((s = br.readLine()) != null) {
String[] cols = s.split(",");
if (cols[1].equals("M")) {// 判断男性用户
userids.add(Long.parseLong(cols[0]));
}
}
br.close();
return userids;
}
}
class FilterRescorer implements IDRescorer {
final private Set userids;
public FilterRescorer(Set userids) {
this.userids = userids;
}
@Override
public double rescore(long id, double originalScore) {
return isFiltered(id) ? Double.NaN : originalScore;
}
@Override
public boolean isFiltered(long id) {
return userids.contains(id);
}
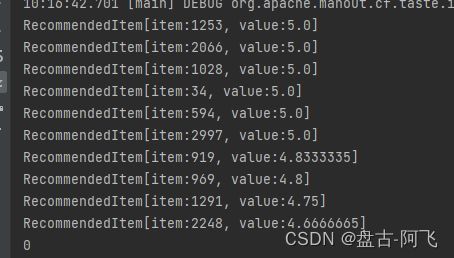
} 过滤只留男性的结果:
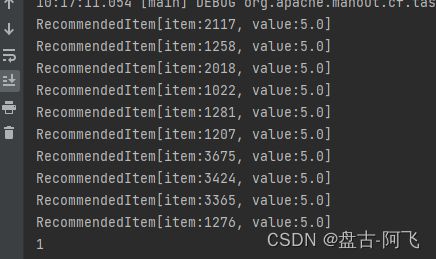
过滤只留女性的结果:
2、基于物品属性数据实现:
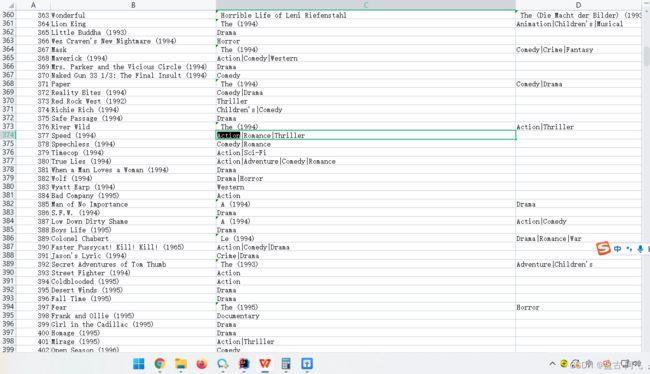
分析数据,movies.csv这个文件是电影的信息数据,它包含了电影id,电影名称,电影分类等。
ratings.csv文件为用户为电影的评分数据。分别为用户id,电影id,评分,时间。
代码实现:
package com.example.ai;
import lombok.SneakyThrows;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.IDRescorer;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
@SpringBootApplication
public class AiApplication {
@SneakyThrows
public static void main(String[] args) {
//1)准备数据 这里是电影评分数据
File file = new File("D:\\ratings.csv");
//2)将数据加载到内存中,GroupLensDataModel是针对开放电影评论数据的
DataModel dataModel = new FileDataModel(file);
//3)计算相似度,相似度算法有很多种,欧几里得、皮尔逊等等。
ItemSimilarity Similarity = new PearsonCorrelationSimilarity(dataModel);
//4)构建推荐器,协同过滤推荐有两种,分别是基于用户的和基于物品的,这里使用基于物品的协同过滤推荐
GenericItemBasedRecommender recommender = new GenericItemBasedRecommender(dataModel, Similarity);
//加载电影信息数据模型,过滤分类后的电影id数据。
Set movieids = getMale("D:\\movies.csv");
//打印过滤后的物品id
System.out.println(movieids.toString());
IDRescorer rescorer = new FilterRescorer(movieids);
//通过recommender.recommend实现过滤推荐,为用户id为2的推荐10个电影
List recommend = recommender.recommend(2,10, rescorer);
//开始计算处理时间
long start = System.currentTimeMillis();
//打印推荐的结果
for (RecommendedItem recommendedItem : recommend) {
System.out.println(recommendedItem);
}
//结束时间
System.out.println(System.currentTimeMillis() -start);
}
/**
* 获得过滤后的物品ID
*/
public static Set getMale(String file) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(new File(file)));
Set movieids = new HashSet();
String s = null;
while ((s = br.readLine()) != null) {
String[] cols = s.split(",");
// 判断电影类型
if (cols[2].indexOf("Crime")!=-1) {
movieids.add(Long.parseLong(cols[0]));
}
}
br.close();
return movieids;
}
}
class FilterRescorer implements IDRescorer {
final private Set userids;
public FilterRescorer(Set userids) {
this.userids = userids;
}
@Override
public double rescore(long id, double originalScore) {
return isFiltered(id) ? Double.NaN : originalScore;
}
@Override
public boolean isFiltered(long id) {
return userids.contains(id);
}
}
推荐结果
通过上述实现了过滤后,根据网上大家写的示例综合封装一下。如下:
RecommendFactory.java
封装各个算法及模型 处理,还有评估方法。
package com.example.ai;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.*;
import org.apache.mahout.cf.taste.impl.common.FastByIDMap;
import org.apache.mahout.cf.taste.impl.eval.AverageAbsoluteDifferenceRecommenderEvaluator;
import org.apache.mahout.cf.taste.impl.eval.GenericRecommenderIRStatsEvaluator;
import org.apache.mahout.cf.taste.impl.eval.RMSRecommenderEvaluator;
import org.apache.mahout.cf.taste.impl.model.GenericBooleanPrefDataModel;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.neighborhood.ThresholdUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericBooleanPrefItemBasedRecommender;
import org.apache.mahout.cf.taste.impl.recommender.GenericBooleanPrefUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.recommender.svd.Factorizer;
import org.apache.mahout.cf.taste.impl.recommender.svd.SVDRecommender;
import org.apache.mahout.cf.taste.impl.similarity.*;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class RecommendFactory {
/**
*构造数据模型
*/
public static DataModel buildDataModel(String file) throws TasteException, IOException {
return new FileDataModel(new File(file));
}
public static DataModel buildDataModelNoPref(String file) throws TasteException, IOException {
return new GenericBooleanPrefDataModel(GenericBooleanPrefDataModel.toDataMap(new FileDataModel(new File(file))));
}
public static DataModelBuilder buildDataModelNoPrefBuilder() {
return new DataModelBuilder() {
@Override
public DataModel buildDataModel(FastByIDMap trainingData) {
return new GenericBooleanPrefDataModel(GenericBooleanPrefDataModel.toDataMap(trainingData));
}
};
}
/**
*构造相似度算法模型
*/
public enum SIMILARITY {
PEARSON, EUCLIDEAN, COSINE, TANIMOTO, LOGLIKELIHOOD, FARTHEST_NEIGHBOR_CLUSTER, NEAREST_NEIGHBOR_CLUSTER
}
public static UserSimilarity userSimilarity(SIMILARITY type, DataModel m) throws TasteException {
switch (type) {
case PEARSON:
return new PearsonCorrelationSimilarity(m);
case COSINE:
return new UncenteredCosineSimilarity(m);
case TANIMOTO:
return new TanimotoCoefficientSimilarity(m);
case LOGLIKELIHOOD:
return new LogLikelihoodSimilarity(m);
case EUCLIDEAN:
default:
return new EuclideanDistanceSimilarity(m);
}
}
public static ItemSimilarity itemSimilarity(SIMILARITY type, DataModel m) throws TasteException {
switch (type) {
case LOGLIKELIHOOD:
return new LogLikelihoodSimilarity(m);
case TANIMOTO:
default:
return new TanimotoCoefficientSimilarity(m);
}
}
/**
*构造近邻算法模型
*/
public enum NEIGHBORHOOD {
NEAREST, THRESHOLD
}
public static UserNeighborhood userNeighborhood(NEIGHBORHOOD type, UserSimilarity s, DataModel m, double num) throws TasteException {
switch (type) {
case NEAREST:
return new NearestNUserNeighborhood((int) num, s, m);
case THRESHOLD:
default:
return new ThresholdUserNeighborhood(num, s, m);
}
}
/**
*构造推荐算法模型
*/
public enum RECOMMENDER {
USER, ITEM
}
public static RecommenderBuilder userRecommender(final UserSimilarity us, final UserNeighborhood un, boolean pref) throws TasteException {
return pref ? new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel model) throws TasteException {
return new GenericUserBasedRecommender(model, un, us);
}
} : new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel model) throws TasteException {
return new GenericBooleanPrefUserBasedRecommender(model, un, us);
}
};
}
public static RecommenderBuilder itemRecommender(final ItemSimilarity is, boolean pref) throws TasteException {
return pref ? new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel model) throws TasteException {
return new GenericItemBasedRecommender(model, is);
}
} : new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel model) throws TasteException {
return new GenericBooleanPrefItemBasedRecommender(model, is);
}
};
}
public static RecommenderBuilder svdRecommender(final Factorizer factorizer) throws TasteException {
return new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel dataModel) throws TasteException {
return new SVDRecommender(dataModel, factorizer);
}
};
}
/**
* 构造算法评估模型
*/
public enum EVALUATOR {
AVERAGE_ABSOLUTE_DIFFERENCE, RMS
}
public static RecommenderEvaluator buildEvaluator(EVALUATOR type) {
switch (type) {
case RMS:
return new RMSRecommenderEvaluator();
case AVERAGE_ABSOLUTE_DIFFERENCE:
default:
return new AverageAbsoluteDifferenceRecommenderEvaluator();
}
}
public static void evaluate(EVALUATOR type, RecommenderBuilder rb, DataModelBuilder mb, DataModel dm, double trainPt) throws TasteException {
System.out.printf("%s Evaluater Score:%s\n", type.toString(), buildEvaluator(type).evaluate(rb, mb, dm, trainPt, 1.0));
}
public static void evaluate(RecommenderEvaluator re, RecommenderBuilder rb, DataModelBuilder mb, DataModel dm, double trainPt) throws TasteException {
System.out.printf("Evaluater Score:%s\n", re.evaluate(rb, mb, dm, trainPt, 1.0));
}
public static void statsEvaluator(RecommenderBuilder rb, DataModelBuilder mb, DataModel m, int topn) throws TasteException {
RecommenderIRStatsEvaluator evaluator = new GenericRecommenderIRStatsEvaluator();
IRStatistics stats = evaluator.evaluate(rb, mb, m, null, topn, GenericRecommenderIRStatsEvaluator.CHOOSE_THRESHOLD, 1.0);
// System.out.printf("Recommender IR Evaluator: %s\n", stats);
System.out.printf("Recommender IR Evaluator: [Precision:%s,Recall:%s]\n", stats.getPrecision(), stats.getRecall());
}
/**
*输出结果
*/
public static void showItems(long uid, List recommendations, boolean skip) {
if (!skip || recommendations.size() > 0) {
System.out.printf("uid:%s,", uid);
for (RecommendedItem recommendation : recommendations) {
System.out.printf("(%s,%f)", recommendation.getItemID(), recommendation.getValue());
}
System.out.println();
}
}
}
使用示例:
package com.example.ai;
import lombok.SneakyThrows;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.IDRescorer;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
@SpringBootApplication
public class AiApplication {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 10;
@SneakyThrows
public static void main(String[] args) {
String file = "D:\\ratings.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
RecommenderBuilder r1 = userEuclidean(dataModel);
RecommenderBuilder r2 = userLoglikelihood(dataModel);
RecommenderBuilder r3 = userEuclideanNoPref(dataModel);
RecommenderBuilder r4 = itemEuclidean(dataModel);
RecommenderBuilder r5 = itemLoglikelihood(dataModel);
RecommenderBuilder r6 = itemEuclideanNoPref(dataModel);
Set userids = getMale("D:\\users.csv");
//计算男性用户打分过的电影
Set bookids = new HashSet();
for (Long uids : userids) {
LongPrimitiveIterator iter = dataModel.getItemIDsFromUser(uids).iterator();
while (iter.hasNext()) {
long bookid = iter.next();
bookids.add(bookid);
}
}
IDRescorer rescorer = new FilterRescorer(bookids);
List recommend1 = r1.buildRecommender(dataModel).recommend(1, RECOMMENDER_NUM, rescorer);
for (RecommendedItem recommendedItem : recommend1) {
System.out.println(recommendedItem);
}
System.out.println("-----------------------");
List recommend2 = r2.buildRecommender(dataModel).recommend(1, RECOMMENDER_NUM, rescorer);
for (RecommendedItem recommendedItem : recommend2) {
System.out.println(recommendedItem);
}
System.out.println("-----------------------");
List recommend3 = r3.buildRecommender(dataModel).recommend(1, RECOMMENDER_NUM, rescorer);
for (RecommendedItem recommendedItem : recommend3) {
System.out.println(recommendedItem);
}
System.out.println("-----------------------");
List recommend4 = r4.buildRecommender(dataModel).recommend(1, RECOMMENDER_NUM, rescorer);
for (RecommendedItem recommendedItem : recommend4) {
System.out.println(recommendedItem);
}
System.out.println("-----------------------");
List recommend5 = r5.buildRecommender(dataModel).recommend(1, RECOMMENDER_NUM, rescorer);
for (RecommendedItem recommendedItem : recommend5) {
System.out.println(recommendedItem);
}
System.out.println("-----------------------");
List recommend6 = r6.buildRecommender(dataModel).recommend(1, RECOMMENDER_NUM, rescorer);
for (RecommendedItem recommendedItem : recommend6) {
System.out.println(recommendedItem);
}
}
/**
* 获得男性用户ID
*/
public static Set getMale(String file) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(new File(file)));
Set userids = new HashSet();
String s = null;
while ((s = br.readLine()) != null) {
String[] cols = s.split(",");
if (cols[1].equals("M")) {// 判断男性用户
userids.add(Long.parseLong(cols[0]));
}
}
br.close();
return userids;
}
public static RecommenderBuilder userEuclidean(DataModel dataModel) throws TasteException, IOException {
System.out.println("userEuclidean");
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
//评估
// RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
// RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder userLoglikelihood(DataModel dataModel) throws TasteException, IOException {
System.out.println("userLoglikelihood");
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.LOGLIKELIHOOD, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
//评估
// RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
// RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder userEuclideanNoPref(DataModel dataModel) throws TasteException, IOException {
System.out.println("userEuclideanNoPref");
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, false);
//评估
// RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
// RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder itemEuclidean(DataModel dataModel) throws TasteException, IOException {
System.out.println("itemEuclidean");
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, true);
//评估
// RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
// RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder itemLoglikelihood(DataModel dataModel) throws TasteException, IOException {
System.out.println("itemLoglikelihood");
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.LOGLIKELIHOOD, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, true);
//评估
// RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
// RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder itemEuclideanNoPref(DataModel dataModel) throws TasteException, IOException {
System.out.println("itemEuclideanNoPref");
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, false);
//评估
// RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
// RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
}
class FilterRescorer implements IDRescorer {
final private Set userids;
public FilterRescorer(Set userids) {
this.userids = userids;
}
@Override
public double rescore(long id, double originalScore) {
return isFiltered(id) ? Double.NaN : originalScore;
}
@Override
public boolean isFiltered(long id) {
return userids.contains(id);
}
}
测试结果:
看着更简介了呢,常用算法基本都封装好了,至于有一个slopeOne算法在0.9以上版本就已经给取消掉了。所以干脆随大流不用也罢(据说推荐的效果还不错)。
单片机实现智能推荐思路:
建议用文件存储的方式更新数据模型,别用数据库的形式,计算性能需要考虑。通过不断的更新模型数据,配合评估数据来选择更有效的算法进行推荐。数据模型数据会越来越多,算法方式很多,程序也就会越来越聪明。一定要考虑好业务逻辑再去使用,避免灾难。