pandas-数据清洗
pandas数据清洗
- 01 | 数据清洗常用方法
- 02 | 数据集
- 03 | 数据清洗
-
- 1.查看基本信息
- 2.处理空格
- 3.处理重复值
- 4.异常值处理
- 5.缺失值处理
- 6.处理文本数据
- 7.转换时间序列
- 8.时间序列切分
- 04 | 数据提取
-
- 1.正则表达式
- 5.数值判断
-
- 1.isin( )
01 | 数据清洗常用方法


02 | 数据集
链接: https://pan.baidu.com/s/153_QvZ-t1E2hykW2Cubg3Q
提取码: s98j
简介
这是一份旅行网站的数据集,数据包括每个行程的具体信息,比如出发地目的地、酒店情况、价格等等。我们利用这份数据集,来操作一次数据清洗的过程
03 | 数据清洗
1.查看基本信息
①一共有5100个数据,包括13个columns
②部分clomns存在空格
# 导入需要的库
import pandas as pd
pd.set_option('display.max_columns',1000)
pd.set_option('display.width',1000)
pd.set_option('display.max_colwidth',1000)
# 读取数据基本信息
df = pd.read_csv(r'C:\Users\Administrator\Documents\Downloads\qunar_freetrip.csv',index_col = 0)
print(df.head())
print(df.info())
print(df.describe())

2.处理空格
① 先将index转array
② 将空格replce or使用 strip()方法
columns = df.columns.values
print(columns)
df.columns = [x.strip() for x in columns]
print(df.columns)
![]()
3.处理重复值
① 先用duplicated()查看是否有重复项
② 利用drop_duplicates(inplace = True)删除
print(df.duplicated().value_counts()) # 共有100个重复值
duplicate = df[df.duplicated()]
print(duplicate) # 打开被定义为重复值的part
# 删除重复值,inplace = True 代表在原数据集上更改,两种方法都可以
# df.drop_duplicates(inplace = True)
df.drop(index = duplicate.index,inplace = True)
print(df.shape)



4.异常值处理
① 通过df.describe()看出部分数值有异常值
② 通过计算标准差来筛选出异常值
③ 删除异常值
print(df.describe().T) # 查看数值类型
# 查找异常值,以标准差的3倍作为标准
sta = (df['价格'] - df['价格'].mean()) / df['价格'].std()
print(df[sta.abs() > 3 ])
print(df[df['节省'] > df['价格']])
df.drop([2792,2938,3147,3720],inplace = True)
'''
方法二
del = pd.concat([df[sta.abs() > 3,df[df['节省'] > df['价格']]).index
df.drop(index = del,inplace = True)
'''
df.reset_index() # 重置索引
print(df.shape)
5.缺失值处理
① df.isnull() 查看缺失值
② df.notnull() 查看不是缺失值
③ df.dropna() 删除缺失值
④ df.fillna() 填充缺失值
⑤ missingno库 可视化缺失值
print(df.isnull().sum())
# 找出出发地缺失值,可以从路线看到出发地
print(df[df.出发地.isnull()])
df.loc[df.出发地.isnull(),'出发地'] = [str(i)[:2] for i in df.loc[df.出发地.isnull(),'路线名']]
print(df.loc[[1864,1930]])
# 找出目的地缺失值
print(df[df.目的地.isnull()])
df.loc[df.目的地.isnull(),'目的地'] = '大连'
print(df.loc[1875])
# 价格跟节省的缺失值为数字类型,用mean来填充
df.价格.fillna(round(df.价格.mean(),0),inplace = True)
df.节省.fillna(round(df.节省.mean(),0),inplace = True)
print(df.isnull().sum())

# missingno 可以可视化缺失值
import missingno as mg
import matplotlib.pyplot as plt
mg.bar(df)
plt.show()
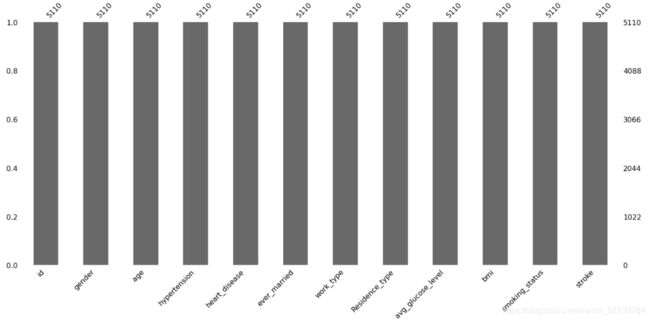
6.处理文本数据
① 利用酒店列,提取数据新增到’酒店评分’列
② 通过正则表达式提取数值
print(df.酒店[:10])
# 利用正则表达式取数值 .str.extract()
# 新建一个酒店评分column,expand为True返回Dataframe,False返回Series
df['酒店评分'] = df.酒店.str.extract('(\d\.\d)分/5分',expand = False)
df['酒店等级'] = df.酒店.str.extract(' (.+) ',expand = False)
df['天数'] = df.路线名.str.extract('(\d)天\d晚',expand = False)
print(df.天数)
7.转换时间序列
import pandas as pd
df = pd.read_csv(r'D:\kc_house_data.csv')
print(df.info()) # 查看数据类型
df['date'] = pd.to_datetime(df['date'],format='%Y/%m/%d')
print(df.date.head(10))
df.to_csv(r'D:\kc_house.csv')
8.时间序列切分
原始数据中,时间有两个数据,分别是2018-05-17,23:59:09
在这里我们先把不需要的钟点去除,先新建一个列,使用函数从时间中取出日期

# 这个函数中,[0],[1]分别代表时间中的2018-05-17与23:59:09,并从x中分割一个数,赋值到新的列data['日期']中
data['日期']=[x.split(' ')[0] for x in data['时间']]
#data['日期']=[x.split(' ')[1] for x in data['时间']],分割出来的是23:59:09
04 | 数据提取
1.正则表达式
import re
content = '个人信息姓名电话13829837584我反对我性别年433432龄就覅都很少能够i南方的弗3243农山大13243佛'
patten = r'1[3-9]\d{9}' # 第一个为1,第二个num为3-9的数字,后面字符有9个数字/d{9}
result = re.findall(patten,content)
result
# 输出结果['13829837584']
5.数值判断
1.isin( )
判断变量是否在目标数据中
# 将DataFrame转换为list
cities = pd.read_excel('目标城市.xlsx')
#读取基本信息,得知cities是一个DataFrame,要判断售货城市是否在目标城市中时,需要采用isin()函数,并将DataFrame转化为list
cities.info()
cities = list(cities['城市'])
'''
用isin()函数来判断是否在目标城市内
新增判断列data['是否在目标城市'],在目标城市为1,不在为0
'''
data['是否在目标城市'] = None
data.loc[data['城市'].isin(cities),'是否在目标城市'] = 1 #在目标城市设置为1
data.loc[data['是否在目标城市'].isnull(),'是否在目标城市'] = 0 #其余设置为0