机器学习-特征工程中的特征降维
对于一个机器学习问题,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。由此可见,数据和特征在模型的整个开发过程中是比较重要。特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,以设计更高效的特征以刻画求解的问题与预测模型之间的关系。
在实际的模型应用中并不是特征越多越好,特征越多固然会给我们带来很多额外的信息,但是与此同时,一方面,这些额外的信息也增加实验的时间复杂度和最终模型的复杂度,造成的后果就是特征的“维度灾难”,使得计算耗时大幅度增加;另一方面,可能会导致模型的复杂程度上升而使得模型变得不通用。所以我们就要在众多的特征中选择尽可能相关的特征和有效的特征,使得计算的时间复杂度大幅度减少来简化模型,并且保证最终模型的有效性不被减弱或者减弱很少,这也就是我们特征选择的目的。
特征工程主要包括以下方面:
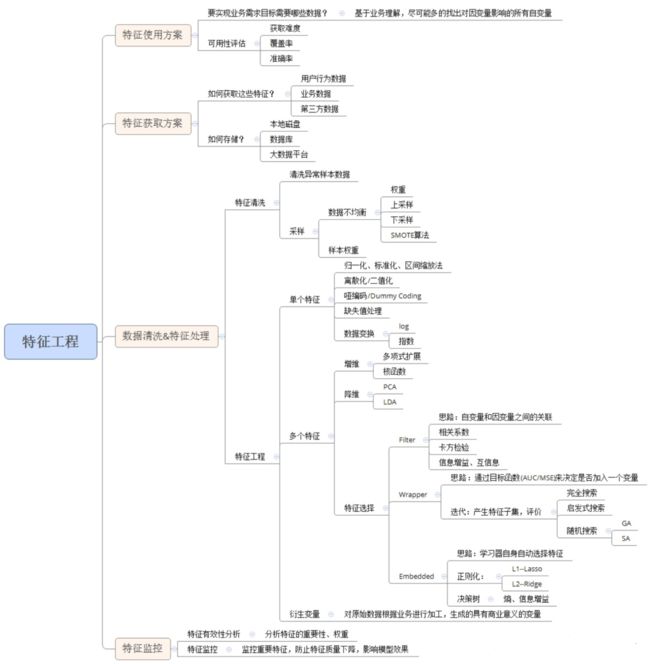
我们重点从3个方面来详细说明特征工程的具体操作:
机器学习-特征工程中的数据预处理
机器学习-特征工程中的特征选择
机器学习-特征工程中的特征降维
特征过多会可能出现特征之间具有多重共线性,即相互之间具有关联关系,导致解空间不稳定,模型泛化能力弱,过多特征也会妨碍模型学习规律,因为诸如此类的问题,一般来说,如果特征过多,我们都会在特征工程里面减少输入的特征。
简单来说,特征降维就是指可以用更少维度的特征替代更高维度的特征,同时保留有用的信息。可以降维的主要原因是数据冗余,包含了一些重复或者无用的信息,例如一张512*512的图片,只有中心的100*100区域内有非0值,这时候我们就可以把这张图片的矩阵降维到100*100。
但是实际机器学习中处理成千上万甚至几十万维的情况也并不罕见,在这种情况下,机器学习的资源消耗是不可接受的,因此我们必须对数据进行降维。降维当然意味着信息的丢失,不过鉴于实际数据本身常常存在的相关性,我们可以想办法在降维的同时将信息的损失尽量降低。
机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。降维的本质是学习一个映射函数 f : x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。 y是数据点映射后的低维向量表达,通常y的维度小于x的维度(当然提高维度也是可以的)。f可能是显式的或隐式的、线性的或非线性的。
目前大部分降维算法处理向量表达的数据,也有一些降维算法处理高阶张量表达的数据。之所以使用降维后的数据表示是因为:①在原始的高维空间中,包含有冗余信息以及噪音信息,在实际应用例如图像识别中造成了误差,降低了准确率;而通过降维,我们希望减少冗余信息所造成的误差,提高识别(或其他应用)的精度。 ②又或者希望通过降维算法来寻找数据内部的本质结构特征。
在很多算法中,降维算法成为了数据预处理的一部分,如PCA。事实上,有一些算法如果没有降维预处理,其实是很难得到很好的效果的。
针对不同的训练目标有不同的降维算法:
•最小化重构误差(主成分分析,PCA)
•最大化类别可分性(线性判别分析,LDA)
•最小化分类误差(判别训练,discriminative training)
•保留最多细节的投影(投影寻踪,projection pursuit)
•最大限度的使各特征之间独立(独立成分分析,ICA)
线性映射
线性映射方法的代表方法有:PCA(Principal Component Analysis),LDA(Discriminant Analysis)
主成分分析算法(PCA)
主成分分析( Principal ComponentAnalysis,PCA)或者主元分析,是最常用的线性降维方法。对于一系列的特征组成的多维向量,多维向量里的某些元素本身没有区分性,比如某个元素在所有的数值都为1,或者与1差距不大,那么这个元素本身就没有区分性,用它做特征来区分,贡献会非常小。
所以将它的目标通过某种线性投影,将高维的数据映射到低维的空间中表示,即把原先的n个特征用数目更少的m个特征取代,新特征是旧特征的线性组合。并期望在所投影的维度上数据的方差最大,尽量使新的m个特征互不相关。从旧特征到新特征的映射捕获数据中的固有变异性,以此使用较少的数据维度,同时保留住较多的原数据的特性。
另外我们在处理有关数字图像处理方面的问题时,比如经常用的图像的查询问题,在一个几万或者几百万甚至更大的数据库中查询一幅相近的图像。这时,我们通常的方法是对图像库中的图片提取响应的特征,如颜色,纹理,sift,surf,vlad等等特征,然后将其保存,建立响应的数据索引,然后对要查询的图像提取相应的特征,与数据库中的图像特征对比,找出与之最近的图片。
这里,如果我们为了提高查询的准确率,通常会提取一些较为复杂的特征,如sift,surf等,一幅图像有很多个这种特征点,每个特征点又有一个相应的描述该特征点的128维的向量,设想如果一幅图像有300个这种特征点,那么该幅图像就有300*vector(128维)个,如果我们数据库中有一百万张图片,这个存储量是相当大的,建立索引也很耗时,如果我们对每个向量进行PCA处理,将其降维为64维,是不是很节约存储空间啊?类似这样的PCA处理应用还有:
(1)比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余。
(2)拿到一个数学系的本科生期末考试成绩单,里面有三列,一列是对数学的兴趣程度,一列是复习时间,还有一列是考试成绩。我们知道要学好数学,需要有浓厚的兴趣,所以第二项与第一项强相关,第三项和第二项也是强相关。那是不是可以合并第一项和第二项呢?
(3)拿到一个样本,特征非常多,而样例特别少,这样用回归去直接拟合非常困难,容易过度拟合。比如北京的房价:假设房子的特征是(大小、位置、朝向、是否学区房、建造年代、是否二手、层数、所在层数),搞了这么多特征,结果只有不到十个房子的样例。要拟合房子特征->房价的这么多特征,就会造成过度拟合。
(4)这个与第二个有点类似,假设在IR中我们建立的文档-词项矩阵中,有两个词项为“learn”和“study”,在传统的向量空间模型中,认为两者独立。然而从语义的角度来讲,两者是相似的,而且两者出现频率也类似,是不是可以合成为一个特征呢?
(5)在信号传输过程中,由于信道不是理想的,信道另一端收到的信号会有噪音扰动,那么怎么滤去这些噪音呢?
PCA降维致力于解决以下问题:
- 缓解维度灾难:PCA 算法通过舍去一部分信息之后能使得样本的采样密度增大(因为维数降低了),这是缓解维度灾难的重要手段;
- 降噪:当数据受到噪声影响时,最小特征值对应的特征向量往往与噪声有关,将它们舍弃能在一定程度上起到降噪的效果;
- 过拟合:PCA 保留了主要信息,但这个主要信息只是针对训练集的,而且这个主要信息未必是重要信息。有可能舍弃了一些看似无用的信息,但是这些看似无用的信息恰好是重要信息,只是在训练集上没有很大的表现,所以 PCA 也可能加剧了过拟合;
- 特征独立:PCA 不仅将数据压缩到低维,它也使得降维之后的数据各特征相互独立;
- 降低算法开销;
- 相关特征容易在数据中明确的显示出来,例如:两维、三维数据,能进行可视化展示;
PCA具体的计算步骤
- 去除平均值
- 计算协方差矩阵
- 计算协方差矩阵的特征值和特征向量
- 将特征值排序
- 保留前N个最大的特征值对应的特征向量
- 将数据转换到上面得到的N个特征向量构建的新空间中(实现了特征压缩)
1. 原始数据
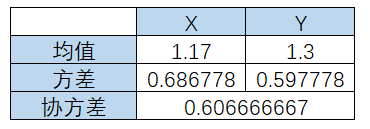
为了方便,我们假定数据是二维的,借助网络上的一组数据,如下:
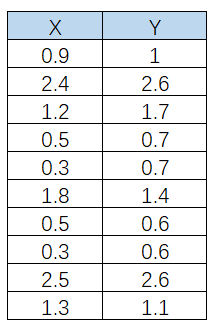
2. 计算协方差矩阵
首先我们给你一个含有n个样本的集合,依次给出数理统计中的一些相关概念:
既然我们都有这么多描述数据之间关系的统计量,为什么我们还要用协方差呢?我们应该注意到,标准差和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集,最简单的大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解这几科成绩之间的关系,这时,我们就要用协方差,协方差就是一种用来度量两个随机变量关系的统计量,其定义为:
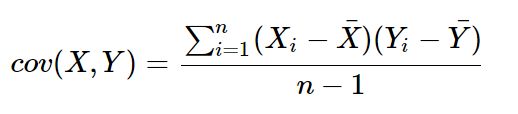
从协方差的定义上我们也可以看出一些显而易见的性质,如:
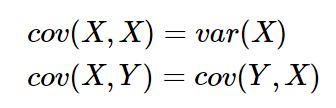
需要注意的是,协方差也只能处理二维问题,那维数多了自然就需要计算多个协方差,比如n维的数据集就需要计算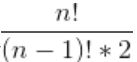 个协方差,那自然而然的我们会想到使用矩阵来组织这些数据。给出协方差矩阵的定义:
个协方差,那自然而然的我们会想到使用矩阵来组织这些数据。给出协方差矩阵的定义:
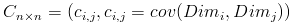
这个定义还是很容易理解的,我们可以举一个简单的三维的例子,假设数据集有三个维度{x,y,z},则协方差矩阵为
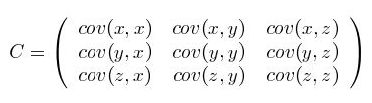
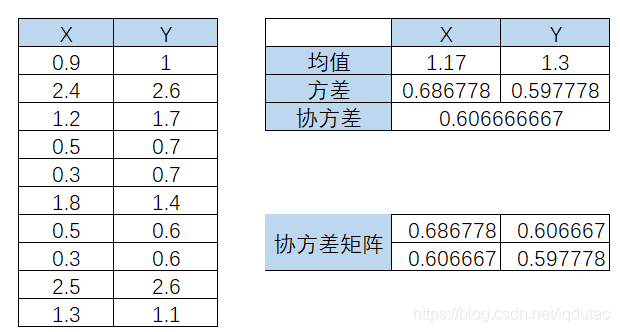
可见,协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方差。
3. 计算协方差矩阵的特征向量和特征值
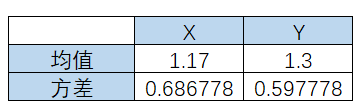
因为协方差矩阵为方阵,我们可以计算它的特征向量和特征值,特征值是1.25057433和0.03398123,单位特征向量是:
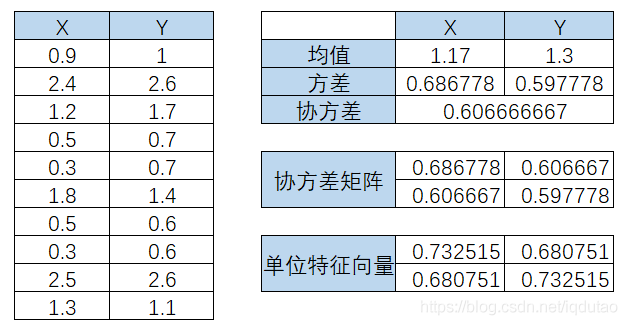
根据矩阵计算它的特征向量和特征值的公式为:

4. 选择成分组成模式矢量
求出协方差矩阵的特征值及特征向量之后,按照特征值由大到小进行排列,这将给出成分的重要性级别。现在可以忽略那些重要性很小的成分,当然这会丢失一些信息,但是如果对应的特征值很小,你不会丢失很多信息。如果你已经忽略了一些成分,那么最后的数据集将有更少的维数,精确地说,如果你的原始数据是n维的,你选择了前p个主要成分,那么你现在的数据将仅有p维。现在我们要做的是组成一个模式矢量,这只是几个矢量组成的矩阵的一个有意思的名字而已,它由你保持的所有特征矢量构成,每一个特征矢量是这个矩阵的一列。
5. 得到降维后的数据
下面我们把数据映射到主成分上。第一主成分是最大特征值对应的特征向量,因此我们要建一个转换矩阵,它的每一列都是主成分的特征向量。如果我们要把5维数据降成3维,那么我们就要用一个3维矩阵做转换矩阵。在本例中,我们将把我们的二维数据映射成一维,因此我们只需要用特征向量中的第一主成分作为转换矩阵。最后,我们用数据矩阵右乘转换矩阵。下面就是第一主成分映射的结果:
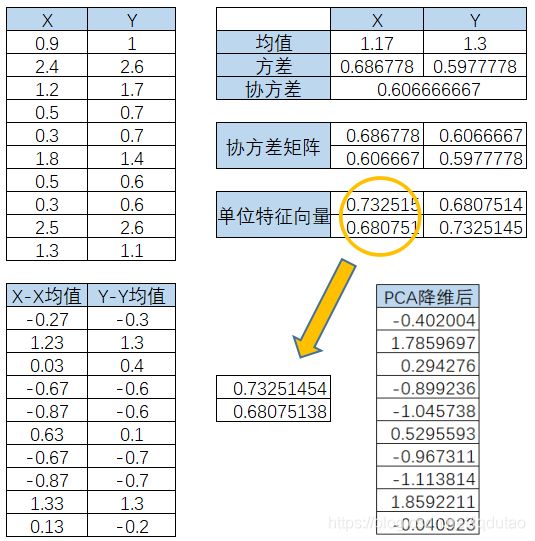
最后总结一下,设有m条n维数据,PCA的计算步骤:

通过Python代码实现:
import numpy as np
x = np.mat([[ 0.9, 2.4, 1.2, 0.5, 0.3, 1.8, 0.5, 0.3, 2.5, 1.3],
[ 1, 2.6, 1.7, 0.7, 0.7, 1.4, 0.6, 0.6, 2.6, 1.1]])
x = x.T
T = x - x.mean(axis=0)
C = np.cov(x.T)
w,v = np.linalg.eig(C)
v_ = np.mat(v[:,0]) #每个特征值对应的是特征矩阵的每个列向量
v_ = v_.T #默认以行向量保存,转换成公式中的列向量形式
y = T * v_
print(y) 根据上面对PCA的数学原理的解释,我们可以了解到一些PCA的能力和限制。PCA本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同正交方向上没有相关性。
因此,PCA也存在一些限制,例如它可以很好的解除线性相关,但是对于高阶相关性就没有办法了,对于存在高阶相关性的数据,可以考虑Kernel PCA,通过Kernel函数将非线性相关转为线性相关,关于这点就不展开讨论了。另外,PCA假设数据各主特征是分布在正交方向上,如果在非正交方向上存在几个方差较大的方向,PCA的效果就大打折扣了。
最后需要说明的是,PCA是一种无参数技术,也就是说面对同样的数据,如果不考虑清洗,谁来做结果都一样,没有主观参数的介入,所以PCA便于通用实现,但是本身无法个性化的优化。
# coding=utf-8
from sklearn.decomposition import PCA
from pandas.core.frame import DataFrame
import pandas as pd
import numpy as np
l=[]
with open('test.csv','r') as fd:
line= fd.readline()
while line:
if line =="":
continue
line = line.strip()
word = line.split(",")
l.append(word)
line= fd.readline()
data_l=DataFrame(l)
print (data_l)
dataMat = np.array(data_l)
pca_sk = PCA(n_components=2)
newMat = pca_sk.fit_transform(dataMat)
data1 = DataFrame(newMat)
data1.to_csv('test_PCA.csv',index=False,header=False)另外,需要注意的是PCA降维,需要提前做标准化。PCA(主成分分析)所对应的数学理论是SVD(矩阵的奇异值分解)。而奇异值分解本身是完全不需要对矩阵中的元素做标准化或者去中心化的。
但是对于机器学习,我们通常会对矩阵(也就是数据)的每一列先进行标准化。PCA通常是用于高维数据的降维,它可以将原来高维的数据投影到某个低维的空间上并使得其方差尽量大。如果数据其中某一特征(矩阵的某一列)的数值特别大,那么它在整个误差计算的比重上就很大,那么可以想象在投影到低维空间之后,为了使低秩分解逼近原数据,整个投影会去努力逼近最大的那一个特征,而忽略数值比较小的特征。
因为在建模前我们并不知道每个特征的重要性,这很可能导致了大量的信息缺失。为了“公平”起见,防止过分捕捉某些数值大的特征,我们会对每个特征先进行标准化处理,使得它们的大小都在相同的范围内,然后再进行PCA。
此外,从计算的角度讲,PCA前对数据标准化还有另外一个好处。因为PCA通常是数值近似分解,而非求特征值、奇异值得到解析解,所以当我们使用梯度下降等算法进行PCA的时候,我们最好先要对数据进行标准化,这是有利于梯度下降法的收敛。
PCA算法优点
- 仅仅需要以方差衡量信息量,不受数据集以外的因素影响
- 各主成分之间正交,可消除原始数据成分间的相互影响的因素
- 计算方法简单,主要运算时特征值分解,易于实现
PCA算法缺点
- 主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强
- 方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
线性判别分析(LDA)
判别分析(Discriminant Analysis) 就是根据研究对象的各种特征值,判别其类型归属问题的一种多变量统计分析方法。
根据判别标准不同,可以分为距离判别、Fisher 判别、Bayes 判别法等。例如,在 KNN 中用的是距离判别,朴素贝叶斯分类用的是 Bayes 判别,线性判别分析用的是 Fisher 判别式。
根据判别函数的形式,可以分为线性判别和非线性判别。
线性判别式分析(Linear Discriminant Analysis),简称为 LDA,也称为 Fisher 线性判别。LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。LDA的基本思想:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点中心尽可能远离。更简单的概括为一句话,就是“投影后类内方差最小,类间方差最大”。
PCA是一种无监督的数据降维方法,与之不同的是LDA是一种有监督的数据降维方法。我们知道即使在训练样本上,我们提供了类别标签,在使用PCA模型的时候,我们是不利用类别标签的,而LDA在进行数据降维的时候是利用数据的类别标签提供的信息的。
从几何的角度来看,PCA和LDA都是讲数据投影到新的相互正交的坐标轴上。只不过在投影的过程中他们使用的约束是不同的,也可以说目标是不同的。PCA是将数据投影到方差最大的几个相互正交的方向上,以期待保留最多的样本信息。
样本的方差越大表示样本的多样性越好,在训练模型的时候,我们当然希望数据的差别越大越好。否则即使样本很多但是他们彼此相似或者相同,提供的样本信息将相同,相当于只有很少的样本提供信息是有用的。样本信息不足将导致模型性能不够理想。这就是PCA降维的目标:将数据投影到方差最大的几个相互正交的方向上。这种约束有时候很有用,比如在下面这个例子:
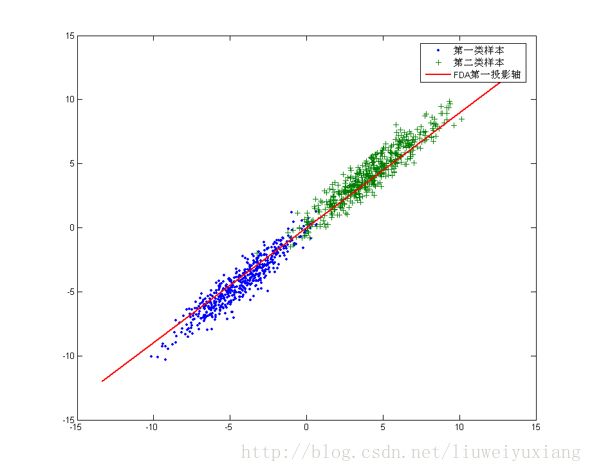
对于这个样本集我们可以将数据投影到x轴或者y轴,但这都不是最佳的投影方向,因为这两个方向都不能最好地反映数据的分布。很明显还存在最佳的方向可以描述数据的分布趋势,那就是图中红色直线所在的方向。也是数据样本做投影,方差最大的方向。向这个方向做投影,投影后数据的方差最大,数据保留的信息最多。但是,对于另外的一些不同分布的数据集,PCA的这个投影后方差最大的目标就不太合适了。比如对于下面图片中的数据集:
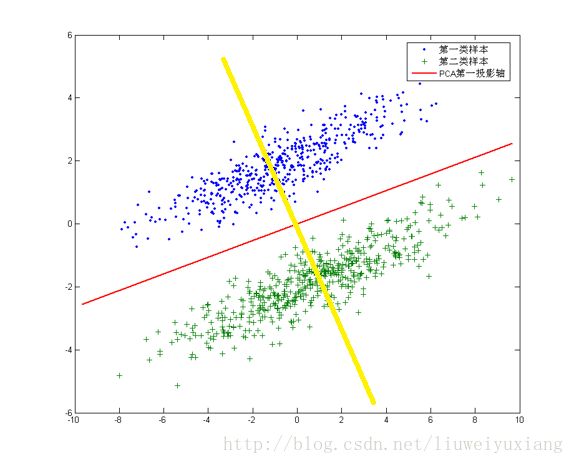
针对这个数据集,如果同样选择使用PCA,选择方差最大的方向作为投影方向,来对数据进行降维。那么PCA选出的最佳投影方向,将是图中红色直线所示的方向。这样做投影确实方差最大,但是是不是有其他问题。聪明的你一定发现了,这样做投影之后两类数据样本将混合在一起,将不再线性可分,甚至是不可分的。
这对我们来说简直就是地狱,本来线性可分的样本被我们亲手变得不再可分。我们发现图中还有一条耀眼的黄色直线,向这条直线做投影即能使数据降维,同时还能保证两类数据仍然是线性可分的。上面的这个数据集如果使用LDA降维,找出的投影方向就是黄色直线所在的方向。
这其实就是LDA的思想,或者说LDA降维的目标:将带有标签的数据降维,投影到低维空间同时满足三个条件:
- 尽可能多地保留数据样本的信息(即选择最大的特征是对应的特征向量所代表的的方向)。
- 寻找使样本尽可能好分的最佳投影方向。
- 投影后使得同类样本尽可能近,不同类样本尽可能远。
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的,这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”,如下图所示。 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
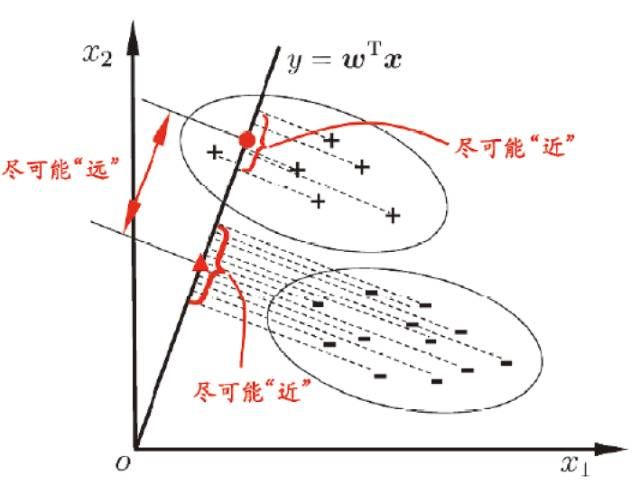
假设我们有两类数据分为 “+”和“-”,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而“+”和“-”数据中心之间的距离尽可能的大。
如下图所示,假设有两类数据,分别为红色和蓝色,这些数据特征是二维的,希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。
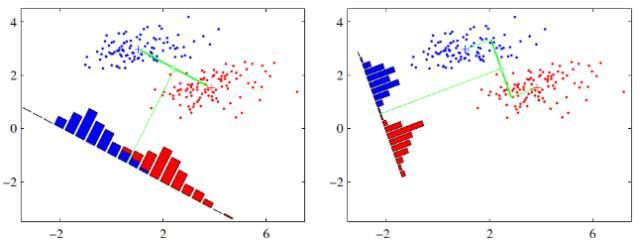
上图中提供了两种投影方式,哪一种能更好的满足我们的标准呢?从直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。以上就是LDA的主要思想了,当然在实际应用中,数据是多个类别的,我们的原始数据一般也是超过二维的,投影后的也一般不是直线,而是一个低维的超平面。
LDA原理与流程




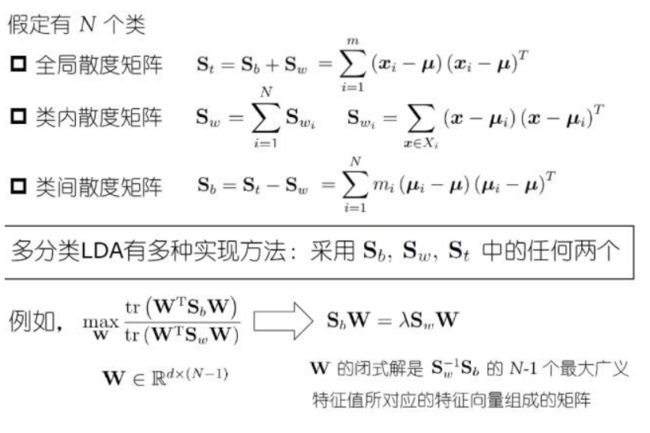

LDA算法既可以用来降维,又可以用来分类,但是目前来说,主要还是用于降维。在进行图像识别相关的数据分析时,LDA是一个有力的工具。下面总结下LDA算法的优缺点。
优点
- 在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
- LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
缺点
- LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
- LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
- LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
- LDA可能过度拟合数据。
PCA与LDA对比
LDA用于降维,和PCA有很多相同,也有很多不同的地方,因此值得好好的比较一下两者的降维异同点。
相同点
- 两者均可以对数据进行降维。
- 两者在降维时均使用了矩阵特征分解的思想。
- 两者都假设数据符合高斯分布。
不同点
- LDA是有监督的降维方法,而PCA是无监督的降维方法
- LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。
- LDA除了可以用于降维,还可以用于分类。
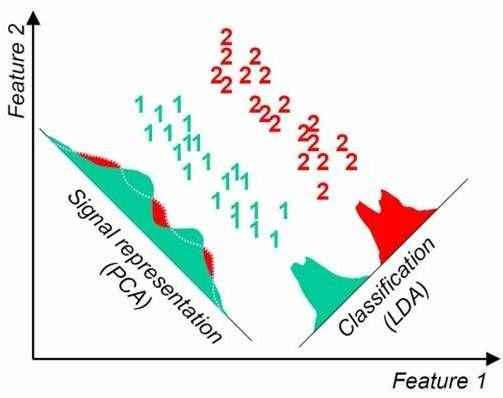
- LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。这点可以从下图形象的看出,在某些数据分布下LDA比PCA降维较优。
具体我们可以通过下面两个图例来对比查看:
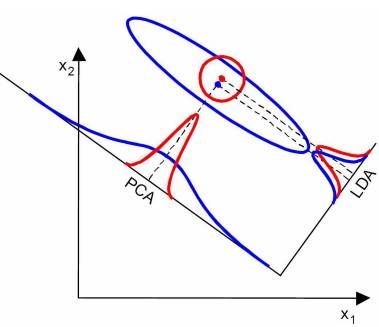
当然,某些某些数据分布下PCA比LDA降维较优,如下图所示:
二、非线性映射
非线性映射方法的代表方法有:核方法(核+线性),二维化和张量化(二维+线性),流形学习(ISOMap,LLE,LPP)
基于核的非线性降维代表方法有:KPCA,KFDA。
KPCA算法
传统线性降维方法(PCA、LDA、MDS等)通过对原有特征线性组合来实现降维,其本质是将数据投影到一个地位的线性子空间,其优点是方法简单计算容易。但如果原始数据无法表示为特征的线性组合则很难使用线性降维方法。例如Helix曲线。此时需要引入非线性的降维方法。
KPCA算法其实很简单,数据在低维度空间不是线性可分的,但是在高维度空间就可以变成线性可分的了。利用这个特点,KPCA只是将原始数据通过核函数(kernel)映射到高维度空间,再利用PCA算法进行降维,所以叫做K PCA降维。因此KPCA算法的关键在于这个核函数。
假设现在有映射函数φ(不是核函数),它将数据从低维度映射到高维度。得到高维度数据后,我们还需要计算协方差矩阵,从前文可以看出,协方差矩阵每个元素都是向量的内积。映射到高维度空间后,向量维度增加,计算量大幅度增大。即便计算量不是问题,那么这个φ应该把数据映射到多少维度呢?怎么求这个φ呢?这些都是很困难的。但是核函数刚好可以解决这个问题,下面我们看一下什么是核函数。
总结一下KPCA算法的计算过程
- 去除平均值,进行中心化。
- 利用核函数计算核矩阵K。
- 计算核矩阵的特征值和特征向量。
- 将特征相量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P。
- P即为降维后的数据。

参考链接:https://blog.csdn.net/mbx8x9u/article/details/7873990
参考链接:https://www.cnblogs.com/jiangkejie/p/11153555.html
参考链接:https://zhuanlan.zhihu.com/p/33742983
参考链接:http://blog.codinglabs.org/articles/pca-tutorial.html
参考链接:https://zhuanlan.zhihu.com/p/77151308
参考链接:http://blog.codinglabs.org/articles/pca-tutorial.html
参考链接:https://www.cnblogs.com/guoyaohua/p/8855636.html
参考链接:https://blog.csdn.net/jesseyule/article/details/95155710
参考链接:https://www.pianshen.com/article/995476822/
参考链接:https://www.jianshu.com/p/708ca9fa3023