特征工程之降维
什么是降维
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
为什么降维
在实际的机器学习项目中,降维是必须进行的,因为在数据中存在以下几个方面的问题:
(1)数据的多重共线性:特征属性之间存在着相互关联关系。多重共线性会导致解的空间不稳定, 从而导致模型的泛化能力弱;
(2)高纬空间样本具有稀疏性,导致模型比较难找到数据特征;
(3)过多的变量会妨碍模型查找规律;
(4) 仅仅考虑单个变量对于目标属性的影响可能忽略变量之间的潜在关系。
这些问题直接的后果就是过拟合现象,可以从如下方法判断是否过拟合:
(1)设阀值(模型训练完毕): 如果模型训练完毕后,发现模型在样本集上表现良好,但在新数据上准确率低于或高于某阈值,可基本判定发生了过拟合。例如在新数据上准确率低于50%或高于90%。
(2)交叉验证法(模型训练阶段): 将训练数据分为一个或多个数据集,用一部分数据集训练模型,另一部分验证模型准确度。如果分类结果在训练集合和测试集合上相差很多,那么就是产生了过拟合。
降维的目的
减少特征属性的个数,确保特征属性之间的相互独立性,最终目的就是解决过拟合现象。
特征降维的方法简介
特征降维分为两种:特征选择和特征抽取
1、特征选择 (Feature Selection)
(1)本质: 选择有效的特征子集,即去掉不相关或冗余的特征。目的是减少特征个数,提高模型精度,减少运行时间。特征选择后留下的特征值的数值在选择前后没有变化。
(2)特征选择依据:
特征是否发散: 如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用;
特征与目标的相关性:与目标相关性高的特征,应当优选选择。
(3)特征选择方法简介:
(过滤法)Filter:按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
(包装法)Wrapper:根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
(嵌入法)Embedded:先使用机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。
2、特征抽取(Feature Extraction)
(1)本质: 特征抽取是指改变原有的特征空间,并将其映射到一个新的特征空间。
(2)特征抽取算法
主成分分析(PCA): 通过线性变换将原始数据变换为一组各维度线性无关的表示,本质就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。
线性判别式分析(LDA):一种监督学习的降维方法,它的数据集的每个样本有类别输出。 其本质是将数据在低维度上进行投影,投影后希望每一种类别的数据的投影点 尽可能的接近,不同类别的数据的类别中心之间的距离尽可能的大。
Filter(过滤式)
主要探究特征本身特点、特征与特征和目标值之间关联
1、低方差特征过滤
(1)方法简介:
先要计算各个特征的方差,然后根据阈值,移除方差小于阈值的特征,默认设置下移除所有方差为0的特征,即样本中数值完全相同的特征。
该类变量的方差为:Var(x)=p(1-p) p 阈值threshold=p(1-p) [p为一样的数据占总数的百分比]
(2)Scikit-learn中API介绍
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
* 删除所有低方差特征
* Variance.fit_transform(X)
* X:numpy array格式的数据[n_samples,n_features]
* 返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
(3)案例
#删除低方差特征from sklearn.feature_selection import VarianceThresholdimport pandas as pddef variance_demo(): data = pd.read_csv("factor_returns.csv") print("原始数据:\n",data) #1、实例化一个转换器 transfer = VarianceThreshold(threshold=1) #2、调用fit_transform data = transfer.fit_transform(data.iloc[:,1:10]) print("删除低方差特征的结果:\n", data) print("形状:\n", data.shape) return None
原始数据:
index pe_ratio pb_ratio market_cap \
0 000001.XSHE 5.9572 1.1818 8.525255e+10
1 000002.XSHE 7.0289 1.5880 8.411336e+10
2 000008.XSHE -262.7461 7.0003 5.170455e+08
3 000060.XSHE 16.4760 3.7146 1.968046e+10
... ... ... ... ...
2288 600893.XSHG 40.8656 2.6827 1.103738e+10
2289 600895.XSHG 16.3415 1.5508 9.477980e+09
2290 600900.XSHG 10.4802 1.4497 1.049400e+11
2291 600999.XSHG 28.2384 1.5721 3.864052e+10
return_on_asset_net_profit du_return_on_equity ev \
0 0.8008 14.9403 1.211445e+12
1 1.6463 7.8656 3.002521e+11
2 -0.5678 -0.5943 7.705178e+08
3 5.6036 14.6170 2.800916e+10
... ... ... ...
2288 2.1550 4.7236 1.709767e+10
2289 0.9668 2.4190 2.099918e+10
2290 5.4443 12.2884 1.902480e+11
2291 1.6908 4.8682 9.582884e+10
earnings_per_share revenue total_expense date return
0 2.0100 2.070140e+10 1.088254e+10 2012-01-31 0.027657
1 0.3260 2.930837e+10 2.378348e+10 2012-01-31 0.082352
2 -0.0060 1.167983e+07 1.203008e+07 2012-01-31 0.099789
3 0.3500 9.189387e+09 7.935543e+09 2012-01-31 0.121595
... ... ... ... ... ...
2288 0.1800 4.807351e+09 4.591748e+09 2012-11-30 0.246801
2289 0.1000 9.909288e+08 1.012814e+09 2012-11-30 0.147055
2290 0.5237 2.003511e+10 1.091727e+10 2012-11-30 0.080191
2291 0.2611 3.586083e+09 2.121595e+09 2012-11-30 0.272618
[2318 rows x 12 columns]
删除低方差特征的结果:
[[ 5.95720000e+00 1.18180000e+00 8.52525509e+10 ... 1.21144486e+12
2.07014010e+10 1.08825400e+10]
[ 7.02890000e+00 1.58800000e+00 8.41133582e+10 ... 3.00252062e+11
2.93083692e+10 2.37834769e+10]
[-2.62746100e+02 7.00030000e+00 5.17045520e+08 ... 7.70517753e+08
1.16798290e+07 1.20300800e+07]
...
[ 3.95523000e+01 4.00520000e+00 1.70243430e+10 ... 2.42081699e+10
1.78908166e+10 1.74929478e+10]
[ 5.25408000e+01 2.46460000e+00 3.28790988e+10 ... 3.88380258e+10
6.46539204e+09 6.00900728e+09]
[ 1.42203000e+01 1.41030000e+00 5.91108572e+10 ... 2.02066110e+11
4.50987171e+10 4.13284212e+10]]
形状:
(2318, 8)
2、单变量特征选择
(1)原理
单独计算每个变量的某个统计指标,根据该指标来判断哪些特征重要,剔除不重要的特征
(2)方法简介
对于离散型的分类问题:卡方检验、互信息
对于连续性的回归问题:皮尔森相关系数、最大信息系数
(3)scikit-learn中API介绍
#SelectKBest 删除除最高得分特征外的所有特征
#特征选择前处理的一步,选择前k个分数较高的特征,去掉其他的特征
sklearn.feature_selection.SelectKBest(score_func=,k=10)
#SelectPercentile 删除除用户指定的最高得分百分比的其他所有特征
sklearn.feature_selection.SelectPercentile(score_func=,percentlie=10)
sklearn.feature_selection.chi2 #用于分类问题,计算非负特征和类之间的卡方统计
sklearn.feature_selection.f_classif #用于分类问题,计算所提供的样本方差F值
sklearn.feature_selection.f_regresssion #用于回归问题,单变量线性回归检验
(4)卡方检验
卡方检验是检验定性自变量对定性因变量的相关性,关于卡方检验的介绍参考网址:https://wiki.mbalib.com/wiki/卡方检验#.E5.8D.A1.E6.96.B9.E6.A3.80.E9.AA.8C.E7.9A.84.E5.9F.BA.E6.9C.AC.E5.8E.9F.E7.90.86.07UNIQ2c3814ad48027e6d-nowiki-0000002E-QINU1.07UNIQ2c3814ad48027e6d-nowiki-0000002F-QINU
feature_selection库的SelectKBest类
参数:
1、score_func : callable,函数取两个数组X和y,返回一对数组(scores, pvalues)或一个分数的数组。默认函数为f_classif,默认函数只适用于分类函数。
2、k:int or "all", optional, default=10。所选择的topK个特征。“all”选项则绕过选择,用于参数搜索。
属性:
1、scores_ : array-like, shape=(n_features,),特征的得分
2、pvalues_ : array-like, shape=(n_features,),特征得分的p_value值,如果score_func只返回分数,则返回None。
方法:
1、fit(X,y),在(X,y)上运行记分函数并得到适当的特征。
2、fit_transform(X[, y]),拟合数据,然后转换数据。
3、get_params([deep]),获得此估计器的参数。
4、get_support([indices]),获取所选特征的掩码或整数索引。
5、inverse_transform(X),反向变换操作。
6、set_params(**params),设置估计器的参数。
7、transform(X),将X还原为所选特征。
更多参考官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectKBest.html#sklearn.feature_selection.SelectKBest.set_params
案例:
#基于卡方检验的特征选择
from sklearn.datasets import load_iris
from sklearn.feature_selection import chi2 #卡方检验
from sklearn.feature_selection import SelectKBest # 根据 k个最高分选择功能。
Data = load_iris()
X, y = Data.data, Data.target
print(X.shape)
X_new = SelectKBest(chi2, k=2).fit_transform(X, y)
X_index = SelectKBest(chi2,k=2).fit(X,y).get_support(indices=True)
print(X_new.shape)
print(X_index)
"""
(150, 4)
(150, 2)
特征选择后的特征索引: [2 3]
"""
(5)Pearson相关系数
定义:皮尔森相关系数反映变量之间相关关系密切程度的统计指标,结果取值的区间为[-1,1]。
公式:

特点:
相关系数的值介于–1与+1之间,即–1≤ r ≤+1。其性质如下:
(1)当r>0时,表示两变量正相关,r<0时,两变量为负相关
(2)当|r|=1时,表示两变量为完全相关,当r=0时,表示两变量间无相关关系
(3)当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近于0,表示两变量的线性相关越弱
一般可按三级划分:|r|<0.4为低度相关;0.4≤|r|<0.7为显著性相关;0.7≤|r|<1为高度线性相关
API介绍:
Pearson Correlation速度快、易于计算,经过清洗和特征提取之后的数据第一时间就执行
(1)scipy.stats.pearsonr
该方法能够同时计算相关系数和p-value(注: p-value就是为了验证假设和实际之间一致性的统计学意义的值,即假设检验。有些地方叫右尾概率,根据卡方值和自由度可以算出一个固定的p-value。)
#pearson相关系数
import numpy as np
from scipy.stats import pearsonr
np.random.seed(0)#使得随机数可预测
size = 500
x = np.random.normal(0, 1, size)
print( "Lower noise", pearsonr(x, x + np.random.normal(0, 1, size)))
print( "Higher noise", pearsonr(x, x + np.random.normal(0, 10, size)))
"""
Lower noise (0.7011559047597686, 3.527031872259905e-75)
Higher noise (0.05708691831482315, 0.20254054576476258)
"""
注: 比较了变量在加入噪音之前和之后的差异,当噪音比较小的时候,相关性很强,p-value很低。
案例:
#pearson相关系数计算
import pandas as pd
from scipy.stats import pearsonr
def pearsonr_demo():
data = pd.read_csv("factor_returns.csv")
factor = ['pe_ratio', 'pb_ratio', 'market_cap', 'return_on_asset_net_profit', 'du_return_on_equity', 'ev',
'earnings_per_share', 'revenue', 'total_expense']
for i in range(len(factor)):
for j in range(i,len(factor)-1):
print( "指标%s与指标%s之间的相关性大小为%f" % (factor[i], factor[j + 1], pearsonr(data[factor[i]], data[factor[j + 1]])[0]))
return None
"""
指标pe_ratio与指标pb_ratio之间的相关性大小为-0.004389
指标pe_ratio与指标market_cap之间的相关性大小为-0.068861
指标pe_ratio与指标return_on_asset_net_profit之间的相关性大小为-0.066009
指标pe_ratio与指标du_return_on_equity之间的相关性大小为-0.082364
指标pe_ratio与指标ev之间的相关性大小为-0.046159
指标pe_ratio与指标earnings_per_share之间的相关性大小为-0.072082
指标pe_ratio与指标revenue之间的相关性大小为-0.058693
指标pe_ratio与指标total_expense之间的相关性大小为-0.055551
指标pb_ratio与指标market_cap之间的相关性大小为0.009336
指标pb_ratio与指标return_on_asset_net_profit之间的相关性大小为0.445381
指标pb_ratio与指标du_return_on_equity之间的相关性大小为0.291367
指标pb_ratio与指标ev之间的相关性大小为-0.183232
指标pb_ratio与指标earnings_per_share之间的相关性大小为0.198708
指标pb_ratio与指标revenue之间的相关性大小为-0.177671
指标pb_ratio与指标total_expense之间的相关性大小为-0.173339
指标market_cap与指标return_on_asset_net_profit之间的相关性大小为0.214774
指标market_cap与指标du_return_on_equity之间的相关性大小为0.316288
指标market_cap与指标ev之间的相关性大小为0.565533
指标market_cap与指标earnings_per_share之间的相关性大小为0.524179
指标market_cap与指标revenue之间的相关性大小为0.440653
指标market_cap与指标total_expense之间的相关性大小为0.386550
指标return_on_asset_net_profit与指标du_return_on_equity之间的相关性大小为0.818697
指标return_on_asset_net_profit与指标ev之间的相关性大小为-0.101225
指标return_on_asset_net_profit与指标earnings_per_share之间的相关性大小为0.635933
指标return_on_asset_net_profit与指标revenue之间的相关性大小为0.038582
指标return_on_asset_net_profit与指标total_expense之间的相关性大小为0.027014
指标du_return_on_equity与指标ev之间的相关性大小为0.118807
指标du_return_on_equity与指标earnings_per_share之间的相关性大小为0.651996
指标du_return_on_equity与指标revenue之间的相关性大小为0.163214
指标du_return_on_equity与指标total_expense之间的相关性大小为0.135412
指标ev与指标earnings_per_share之间的相关性大小为0.196033
指标ev与指标revenue之间的相关性大小为0.224363
指标ev与指标total_expense之间的相关性大小为0.149857
指标earnings_per_share与指标revenue之间的相关性大小为0.141473
指标earnings_per_share与指标total_expense之间的相关性大小为0.105022
指标revenue与指标total_expense之间的相关性大小为0.995845
In [ ]:
"""
分析:从中可以看出 指标revenue与指标total_expense之间的相关性大小为0.995845;指标return_on_asset_net_profit与指标du_return_on_equity之间的相关性大小为0.818697。这两对数据相关性较大,可以做后续的处理比如合并指标。
(2)sklearn.feature_selection.f_regresssion
Scikit-learn提供的f_regrssion方法能够批量计算特征的p-value
sklearn.feature_selection.f_regresssion(X,y,center=True)
Parameters:
X : {array-like, sparse matrix} shape = (n_samples, n_features)
The set of regressors that will be tested sequentially.
y : array of shape(n_samples).
The data matrix
center : True, bool,
If true, X and y will be centered.
Returns:
F : array, shape=(n_features,)
F values of features.
pval : array, shape=(n_features,)
p-values of F-scores.
案例:
from sklearn.datasets import load_iris
from sklearn.feature_selection import f_regression
X,y = load_iris(return_X_y=True)
F,pval = f_regression(X,y,center=True)
print("F:",F)
print("pval:",pval)
"""
F: [ 233.8389959 31.59750825 1342.15918918 1589.55920433]
pval: [2.89047835e-32 9.15998497e-08 4.15547758e-76 4.77500237e-81]
"""
结合feature_selection库的SelectKBest类的案例
#基于pearson相关系数的特征选择
from sklearn.datasets import load_boston
from sklearn.feature_selection import f_regression #卡方检验
from sklearn.feature_selection import SelectKBest # 根据 k个最高分选择功能。
Data = load_boston()
X, y = Data.data, Data.target
print(X.shape)
X_new = SelectKBest(f_regression, k=5).fit_transform(X, y)
X_index = SelectKBest(f_regression,k=5).fit(X,y).get_support(indices=True)
print(X_new.shape)
print("特征选择后的特征索引:",X_index)
"""
(506, 13)
(506, 5)
特征选择后的特征索引: [ 2 5 9 10 12]
"""
相关系数法缺陷:
pearson相关系数的一个明显的缺陷是只对线性关系敏感,对于非线性的,可以采用接下来介绍的互信息。
(6)互信息和最大信息系数
定义:
互信息是用于评价离散特征对离散目标变量的相关性。https://www.cnblogs.com/gatherstars/p/6004075.html
方法简介:
互信息是用来评价一个事件的出现对于另一个事件的出现所贡献的信息量,利用公式形式化表示出来,经典的互信息公式如下。其与相关系数不同的它依赖的不是数据序列,而是数据的分布。
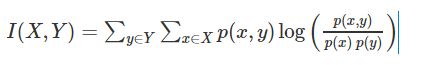
但是把互信息直接用于特征有些不足:
<1>互信息不属于度量方式,也无法归一化,在不同数据集上的结果无法比较;
<2>对于连续变量的计算不便(X、Y是离散集合,x、y是离散值),互信息的结果对离散化的方式很敏感,通常变量需要先离散化。
克服这两个问题的方案:
最大信息系数(MIC)克服了这两个问题,首先寻找一种最优的离散化方式,然后把互信息的取值转换成一种度量的方式,取值期间在[0,1]。
minepy包提供了MIC功能:
#1、导入minepy中的MINE
from minepy import MINE
#2、定义MINE对象
m = MINE()
#调用compute_score方法,传入离散型数据想,x,y
m.compute_score(x,y)
#计算mic
Mic = m.mic()
注:在有些数据集中,如果0不成立,MIC的统计结果会受到影响。
案例:
from sklearn.feature_selection import SelectKBest
from sklearn.datasets import load_iris
from minepy import MINE
import numpy as np
iris = load_iris()
#由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5
def mic(x, y):
m = MINE()
m.compute_score(x, y)
return (m.mic(), 0.5)
'''
compute_score(x, y)
Computes the maximum normalized mutual information scores between x and y.
计算x和y之间的最大标准化互信息分数。
'''
#选择K个最好的特征,返回特征选择后的数据
SelectKBest(lambda X, Y: list(np.array([pearsonr(x, Y) for x in X.T]).T), k=2).fit_transform(iris.data, iris.target)
# 或
#SelectKBest(lambda X, Y: np.array(list(map(lambda x:mic(x, Y), X.T))).T[0], k=2).fit_transform(iris.data, iris.target)
"""
array([[1.4, 0.2],
[1.4, 0.2],
[1.3, 0.2],
[1.5, 0.2],
.......
[5. , 1.9],
[5.2, 2. ],
[5.4, 2.3],
[5.1, 1.8]])
"""
包裹型(Wrapper)
1、递归特征消除法RFE(Recursive feature elimination)
sklearn官方文档解释:
给出了一个为特征分配权重的外部估计量(例如线性模型的系数),递归特征消除(RFE)的目标是通过递归地考虑更小的特征集来选择特征。首先,对估计量的初始特征集进行训练,通过一个coef_属性或一个
feature_importances_ 属性获得每个特征的重要性(权重值)。然后,从当前的一组特征中删除最不重要的特征。该过程在修剪集上递归地重复,直到最终达到所需的功能数。
sklearn中API介绍RFE:
sklearn.feature_selection.RFE(estimator, n_features_to_select=None, step=1, verbose=0)
基于回归模型的案例:
#递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
from sklearn.feature_selection import RFE
# from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_iris
iris = load_iris()
#递归特征消除法,返回特征选择后的数据
print(iris.data[0:5])
print(iris.target[0:5])
print("-----------------------------------")
# selector = RFE(estimator=LogisticRegression(), n_features_to_select=2).fit(iris.data, iris.target)
selector = RFE(estimator=LinearRegression(), n_features_to_select=2).fit(iris.data, iris.target)
#参数estimator为基模型,参数n_features_to_select为选择的特征个数
data = selector.transform(iris.data)
print(data[0:5])
print("-----------------------------------")
#特征排序,使排序与第i个特征的排序位置相对应。所选(即估计的最佳)功能被分配到1级。
print("特征排序",selector.ranking_)
"""
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
[0 0 0 0 0]
-----------------------------------
[[1.4 0.2]
[1.4 0.2]
[1.3 0.2]
[1.5 0.2]
[1.4 0.2]]
-----------------------------------
特征排序 [2 3 1 1]
"""
2、RFECV(通过递归特征消除和最佳特征数量的交叉验证选择进行特征排序。)
主要思想:RFECV主要通过交叉验证的方式执行RFE选择最佳数量的特征。例:对于一个数量为n的feature集合,其所有子集的个数是(2^n-1)含空集,指定一个机器学习算法如SVM,通过算法计算所有子集的误差(validation error),选择误差最小的子集作为挑选出的特征。
sklearn中RFECV:
sklearn.feature_selection.RFECV(estimator, step=1, min_features_to_select=1, cv=’warn’, scoring=None, verbose=0, n_jobs=None)
案例:
from sklearn.feature_selection import RFECV
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import StratifiedKFold
from sklearn.datasets import load_iris
#递归特征消除法,返回特征选择后的数据
iris = load_iris()
print(iris.data[0:5])
print(iris.target[0:5])
print("-----------------------------------")
selector = RFECV(LogisticRegression(),cv= StratifiedKFold(iris.target,3)).fit(iris.data, iris.target)
"""
cv:int,交叉验证生成器或一个不可重复、可选
确定交叉验证拆分策略。cv的可能输入为:
无:要使用默认的3倍交叉验证,
整数:指定折叠数。
CV分离器:一个不可重复的收益率(训练,测试)被分割成一组索引。
对于integer/none输入,如果y是二进制或多类,则使用sklearn.model_selection.stratiedfold。
如果估计量是分类器,或者y既不是二进制也不是多类,则使用sklearn.model_selection.kfold。
"""
data = selector.transform(iris.data)
print(data[0:5])
print("-----------------------------------")
#特征排序,使排序与第i个特征的排序位置相对应。所选(即估计的最佳)功能被分配到1级。
print("特征排序",selector.ranking_)
"""
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
[0 0 0 0 0]
-----------------------------------
[[3.5 1.4 0.2]
[3. 1.4 0.2]
[3.2 1.3 0.2]
[3.1 1.5 0.2]
[3.6 1.4 0.2]]
-----------------------------------
特征排序 [2 1 1 1]
"""
(嵌入法)Embedded
单变量特征选择方法独立的衡量每个特征与响应变量之间的关系,另一种主流的特征选择方法是基于机器学习模型的方法。有些机器学习方法本身就具有对特征进行打分的机制,或者很容易将其运用到特征选择任务中,例如回归模型,SVM,决策树,随机森林等等。其实Pearson相关系数等价于线性回归里的标准化回归系数。
1、SelectFromModel
官方文档介绍:
SelectFromModel是一个meta-transformer(元转换器),可以用来处理任何带有coef_或者feature_imoportances_属性的预测模型训练之后的评估器。如果特征对应的coef_或者feature_importances_属性值低于预先设置的阀值,这些特征将被认定为不重要的数据被删除。对于阀值的设定,处理设置数值型阀值,还可以通过给定字符串参数来使用内置的启发式方法(如mean、median以及他们 与浮点数的乘 积0.1*mean)来设置阀值。
sklearn.feature_selection.SelectFromModel(estimator, threshold=None, prefit=False, norm_order=1, max_features=None)
2、基于惩罚项的特征选择法
(1)L1
使用L1范数作为惩罚项的线性模型(Linear models)会得到稀疏解:大部分特征对应的系数为0。可以通过 feature_selection.SelectFromModel 来选择不为0的系数达到减少特征的维度的目的,以用于其它分类器。
使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型,来选择特征的代码如下:
#带L1惩罚项的逻辑回归作为及模型的特征选择
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
iris = load_iris()
X,y = iris.data,iris.target
print("原始数据维数:",X.shape)
lr = LogisticRegression(penalty='l1',C=0.1).fit(X,y)
model = SelectFromModel(lr,prefit=True)
X_new = model.transform(X)
print("特征选择后维数:",X_new.shape)
(2)L1结合L2
L1惩罚项降维的原理在于保留多个对目标值具有同等相关性的特征中的一个,但是没有选中的特征并不代表不重要,可以结合L2惩罚项来优化: 若一个特征在L1中的权值为1,选择在L2中权值差别不大且在L1中权值为0的特征构成同类集合,将这一集合中的特征平分L1中的权值,故需要构建一个新的逻辑回归模型。
新逻辑回归模型:
#新逻辑回归模型
from sklearn.linear_model import LogisticRegression
class LR(LogisticRegression):
def __init__(self, threshold=0.01, dual=False, tol=1e-4, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver='liblinear', max_iter=100,
multi_class='ovr', verbose=0, warm_start=False, n_jobs=1):
#权值相近的阈值
self.threshold = threshold
LogisticRegression.__init__(self, penalty='l1', dual=dual, tol=tol, C=C,
fit_intercept=fit_intercept, intercept_scaling=intercept_scaling, class_weight=class_weight,
random_state=random_state, solver=solver, max_iter=max_iter,
multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
#使用同样的参数创建L2逻辑回归
self.l2 = LogisticRegression(penalty='l2', dual=dual, tol=tol, C=C, fit_intercept=fit_intercept, intercept_scaling=intercept_scaling, class_weight = class_weight, random_state=random_state, solver=solver, max_iter=max_iter, multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
def fit(self, X, y, sample_weight=None):
#训练L1逻辑回归
super(LR, self).fit(X, y, sample_weight=sample_weight)
self.coef_old_ = self.coef_.copy()
#训练L2逻辑回归
self.l2.fit(X, y, sample_weight=sample_weight)
cntOfRow, cntOfCol = self.coef_.shape
#权值系数矩阵的行数对应目标值的种类数目
for i in range(cntOfRow):
for j in range(cntOfCol):
coef = self.coef_[i][j]
#L1逻辑回归的权值系数不为0
if coef != 0:
idx = [j]
#对应在L2逻辑回归中的权值系数
coef1 = self.l2.coef_[i][j]
for k in range(cntOfCol):
coef2 = self.l2.coef_[i][k]
#在L2逻辑回归中,权值系数之差小于设定的阈值,且在L1中对应的权值为0
if abs(coef1-coef2) < self.threshold and j != k and self.coef_[i][k] == 0:
idx.append(k)
#计算这一类特征的权值系数均值
mean = coef / len(idx)
self.coef_[i][idx] = mean
return self
使用feature_selection库的SelectFromModel类结合带L1以及L2惩罚项的逻辑回归模型,来选择特征的代码如下:
#带L1和L2惩罚项的逻辑回归作为基模型的特征选择
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris()
X,y = iris.data,iris.target
print("原始数据维数:",X.shape)
lr = LR(threshold=0.05, C=0.1)#参数threshold为权值系数之差的阈值
model = SelectFromModel(lr).fit(X,y)
X_new = model.transform(X)
print("特征选择后维数:",X_new.shape)
"""
原始数据维数: (150, 4)
特征选择后维数: (150, 3)
"""
3、基于树的特征选择
基于树的预测模型如sklearn.tree树模块和sklearn.ensemble森林mok,能够用于计算特征的重要程度,可以结合sklearn.feature_selection.SelectFromModel来去除一些不相关的特征,代码案例如下:
#基于树的特征选择
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.feature_selection import SelectFromModel
from sklearn.datasets import load_iris
iris = load_iris()
X,y = iris.data,iris.target
print("原始数据维数:",X.shape)
etc = ExtraTreesClassifier().fit(X,y)
print("特征重要值:",etc.feature_importances_)
model = SelectFromModel(etc,prefit=True)
X_new = model.transform(X)
print("特征选择数据维数:",X_new.shape)
"""
原始数据维数: (150, 4)
特征重要值: [0.09150853 0.05464123 0.33229115 0.52155909]
特征选择数据维数: (150, 2)
"""