更换目标检测的backbone(以Faster RCNN为例)
本博客以Faster RCNN为例,介绍如何更换目标检测的backbone。
对于更换目标检测backbone,主要难点是:如何获取分类网络中间某一个特征层的输出,在该特征层输出的基础上构建我们的目标检测模型。这里简单讲一下如何利用pytorch官方给的方法构建我们新的backbone,关于构建新的backbone,其实它的方法有很多。我们这讲一个比较简单的方法,对于该方法的前提是:torch>1.10
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch
不带FPN结构更换backbone
本博客利用到的Faster-RCNN源码的项目结构如下:
这里直接将train_res50_fpn.py复制两分份,分别命名为change_backbone_with_fpn.py和change_backbone_without_fpn.py,拷贝后的文件中,唯一改的地方就是create_model函数。先讲change_backbone_without_fpn.py
change backbone without fpn(只有一个预测特征层)
没有更改backbone,对应train_res50_fpn.py中create_model函数代码:
def create_model(num_classes, load_pretrain_weights=True):
# 注意,这里的backbone默认使用的是FrozenBatchNorm2d,即不会去更新bn参数
# 目的是为了防止batch_size太小导致效果更差(如果显存很小,建议使用默认的FrozenBatchNorm2d)
# 如果GPU显存很大可以设置比较大的batch_size就可以将norm_layer设置为普通的BatchNorm2d
# trainable_layers包括['layer4', 'layer3', 'layer2', 'layer1', 'conv1'], 5代表全部训练
# resnet50 imagenet weights url: https://download.pytorch.org/models/resnet50-0676ba61.pth
backbone = resnet50_fpn_backbone(pretrain_path="./backbone/resnet50.pth",
norm_layer=torch.nn.BatchNorm2d,
trainable_layers=3)
# 训练自己数据集时不要修改这里的91,修改的是传入的num_classes参数
model = FasterRCNN(backbone=backbone, num_classes=91)
if load_pretrain_weights:
# 载入预训练模型权重
# https://download.pytorch.org/models/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
weights_dict = torch.load("./backbone/fasterrcnn_resnet50_fpn_coco.pth", map_location='cpu')
missing_keys, unexpected_keys = model.load_state_dict(weights_dict, strict=False)
if len(missing_keys) != 0 or len(unexpected_keys) != 0:
print("missing_keys: ", missing_keys)
print("unexpected_keys: ", unexpected_keys)
# get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
更改backbone
(1) 首先在create_model函数中导入两个包
import torchvision
from torchvision.models.feature_extraction import create_feature_extractor
可以在pytorch官网上查看create_feature_extractor。通过Docs->torchvision找到文档。
并检索create_feature_extractor,检索结果如下:

可以查看完整的函数说明。
示例1: backbone更换为vgg16_bn
这里使用官方提供的vgg16_bn,并设置pretrained=True ,就会自动下载模型的预训练权重,这些预训练权重主要是针对ImageNet数据集进行预训练的。下载后自动载入,实例化bakbone。
#vgg16
backbone=torchvision.models.vgg16_bn(pretrained=True)
在我们使用过程我们并不需要使用完整的vgg16模型架构。

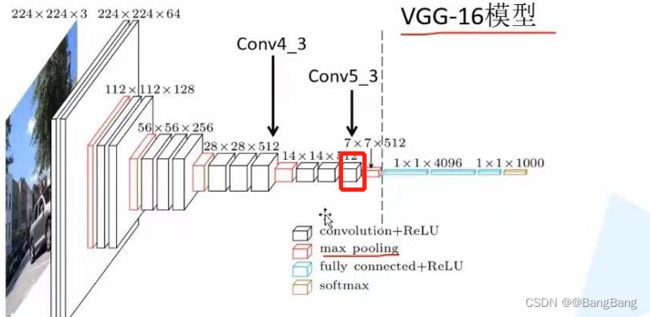
完整的vgg16分类模型是包含了一系列卷积、下采样(max pooling)和全连接层。在目标检测中,我们只需要它中间某一层的特征输出就可以了。通过IDE查看VGG16的源码:

代码中的self.features(x)对应VGG架构开始到画虚线位置,对应features最后一个结构为max pooling层。直接拿self.features的输出对应就是max pooling层输出后的结果。这里建议使用下采样16倍的特征层,不要使用下采样32倍的特征层。因为下采样过大,特征过于抽象,丢失原图中精细化的特征,就比较难检测一些尺度比较小的目标了。
通过VGG架构可以知道,如果直接拿self.features输出的结果,下采样为32倍(224 x224变为7x7)。如果我们要下采样16倍的特征层的话,我们就需要得到max pooling前一层的输出。
关于如何得到中间特征层的节点名称,主要有两种方法:第一种是通过源码查看,第二种通过print(backbone)进行查看。通过查看源码很容易找到我们需要的特征层的node名称,我这里就不介绍了. 介绍下如何通过设置断点print(backbone).

为了方便我这里将models.vgg16_bn的pretrained设置为False,这样就不会下载预训练权重了 。
调试打印出print(backbone), 打印结果如下:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace=True)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace=True)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace=True)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(26): ReLU(inplace=True)
(27): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace=True)
(33): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(36): ReLU(inplace=True)
(37): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(38): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(39): ReLU(inplace=True)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace=True)
(43): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
从打印出来的结构看出,vgg16_bn由features,avgpool,classifier三个模块组成,我们想要的特征输出是在feature模块下的某一个子模块的输出,对应就是feature模块中Maxpool的前一层的输出. 可以看到features模块下,索引为43的位置对应的为MaxPool2d的node名称.其前一个节点索引为42就是我们想要的节点features.42特征输出.
backbone=create_feature_extractor(backbone,return_nodes={"features.42":"0"})
此时还需要为backbone设置一个参数,就是out_channels ,因为在后面faster-rcnn的搭建过程,它需要用到backbone的输出channels. 关于backbone.out_channels它的输出数值是多少呢, 我这边提供一个非常简单的办法. 首先创建一个backbone的输入tensor,比如:batch=1,3 通道,224 x 224大小的图片. 然后将数据传入backbone,查看输出.
backbone=create_feature_extractor(backbone,return_nodes={"features.42":"0"})
out=backbone(torch.rand(1,3,224,224))
print(out["0"].shape)
设置一个断点,查看输出结果
可以看到out是一个字典`` ,key是"0"是我们在return_nodes={"features.42":"0"}中设置的key ,另外print(out["0"].shape)的输出结果如下:
torch.Size([1, 512, 14, 14])
可以看到输出的channels=512., 因此设置 backbone.out_channels=512
backbone=create_feature_extractor(backbone,return_nodes={"features.42":"0"})
#out=backbone(torch.rand(1,3,224,224))
#print(out["0"].shape)
backbone.out_channels=512
此时就完成了backbone的更换.
示例2: 更换backbone为resnet50
其实过程跟示例1是一模一样的. 完整的更换代码如下:
# resnet50 backbone
backbone=torchvision.models.resnet50(pretrained=True)
#print(backbone)
backbone=create_feature_extractor(backbone,return_nodes={"layer3":"0"})
#out=backbone(torch.rand(1,3,224,224))
#print(out["0"].shape)
backbone.out_channels=1024
这里return_nodes={"layer3":"0"}),为什么是layer3呢,
点击backbone=torchvision.models.resnet50(pretrained=True)查看resnet50源码. 其中forward部分的代码如下:
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
这里的layer3对应的是resnet网络结构中的conv4.x对应的一系列残差结构,通过该层网络结构输出14x14的特征图,刚好是下采样16倍,所以对应的key是layer3
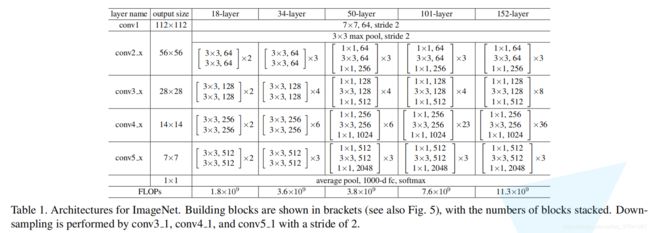
如果不确定的话,可以通过调试打印输出的特征尺寸,进行验证.
# resnet50 backbone
backbone=torchvision.models.resnet50(pretrained=True)
#print(backbone)
backbone=create_feature_extractor(backbone,return_nodes={"layer3":"0"})
out=backbone(torch.rand(1,3,224,224))
print(out["0"].shape)
输出
>> torch.Size([1, 1024, 14, 14])
可以看到layer3节点的输出是14x14, 符合16倍下采样,同时可以看到out_channels=1024 ,因此设置 backbone.out_channels=1024
示例3: 更换backbone为EfficientNetB0
方法也是和前面介绍的是一样的,完整代码如下:
backbone=torchvision.models.efficientnet_b0(pretrained=False)
#print(backbone)
backbone=create_feature_extractor(backbone,return_nodes={"features.5":"0"})
out=backbone(torch.rand(1,3,224,224))
print(out["0"].shape)
backbone.out_channels=112
这里的return_nodes={"features.5":"0"}),对应的key为features.5
参考博客:EfficientNet网络详解
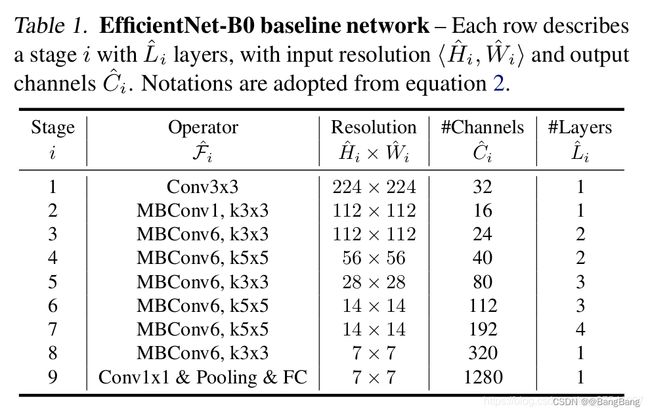
可以看到stage 6输出的特征为14x14,对于stage 7 输入为14x14 ,但是 对应的stride为2输出7x7 下采样32倍.
通过print(backbone)打印网络结构图.
EfficientNet(
(features): Sequential(
(0): ConvNormActivation(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(32, 8, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(8, 32, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(2): ConvNormActivation(
(0): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.0, mode=row)
)
)
(2): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(16, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=96, bias=False)
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(96, 4, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(4, 96, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(96, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.0125, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(144, 6, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(6, 144, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(144, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.025, mode=row)
)
)
(3): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(144, 144, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=144, bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(144, 6, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(6, 144, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(144, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.037500000000000006, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(40, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(240, 240, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=240, bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(240, 10, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(10, 240, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(240, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.05, mode=row)
)
)
(4): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(40, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(240, 240, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=240, bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(240, 10, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(10, 240, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(240, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.0625, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(480, 20, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(20, 480, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(480, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.07500000000000001, mode=row)
)
(2): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(480, 20, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(20, 480, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(480, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.08750000000000001, mode=row)
)
)
(5): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(480, 480, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(480, 20, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(20, 480, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(480, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(672, 672, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=672, bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(672, 28, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(28, 672, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(672, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1125, mode=row)
)
(2): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(672, 672, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=672, bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(672, 28, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(28, 672, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(672, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.125, mode=row)
)
)
(6): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(672, 672, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=672, bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(672, 28, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(28, 672, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(672, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1375, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.15000000000000002, mode=row)
)
(2): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1625, mode=row)
)
(3): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.17500000000000002, mode=row)
)
)
(7): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(1152, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1875, mode=row)
)
)
(8): ConvNormActivation(
(0): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1280, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=1)
(classifier): Sequential(
(0): Dropout(p=0.2, inplace=True)
(1): Linear(in_features=1280, out_features=1000, bias=True)
)
)
网络结构stage 6,对于与features模块下,索引为5的子模块,所以对应的节点为"features.5"
构建 Faster RCNN代码讲解
构建backbone
创建好backbone后,接下来讲解如何构建Faster RCNN模型,这里介绍的是不带FPN结构的,也就是说只有一个预测特征层.
实例化AnchorGenerator 和 roi_pooler
实例化AnchorGenerator
anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
传入两个参数,一个是sizes,一个是aspect_ratios. size 和aspect_ratios都是元祖类型,并且都是一个元素,因为我们是构建不带FPN的结构,只有一个预测特征层,对应sizes和aspect_ratios元祖都只有一个元素
如果我们这里不去定义AnchorGenerator,在Faster RCNN内部它会自动去构建针对具有FPN结构的AnchorGenerator 以及roi_pooler,因此需要我们事先去构建 AnchorGenerator和roi_pooler
anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], # 在哪些特征层上进行RoIAlign pooling
output_size=[7, 7], # RoIAlign pooling输出特征矩阵尺寸
sampling_ratio=2) # 采样率
这里用的MutiScaleRoIAlign ,这个相对Faster RCNN论文所讲的RoiPooler而言会更加精确一些. 由于这里只有一个key为0的预测特征层,所以在MultiScaleRoIAlign中传入featmap_names=['0']
模型构建
构建模型:
model = FasterRCNN(backbone=backbone,
num_classes=num_classes,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
完整代码如下:
def create_model(num_classes, load_pretrain_weights=True):
import torchvision
from torchvision.models.feature_extraction import create_feature_extractor
# vgg16
backbone=torchvision.models.vgg16_bn(pretrained=False)
print(backbone)
backbone=create_feature_extractor(backbone,return_nodes={"features.42":"0"})
#out=backbone(torch.rand(1,3,224,224))
#print(out["0"].shape)
backbone.out_channels=512
# resnet50 backbone
# backbone=torchvision.models.resnet50(pretrained=False)
# #print(backbone)
# backbone=create_feature_extractor(backbone,return_nodes={"layer3":"0"})
# out=backbone(torch.rand(1,3,224,224))
# print(out["0"].shape)
# backbone.out_channels=1024
# efficientnet_b0 backbone
# backbone=torchvision.models.efficientnet_b0(pretrained=False)
# print(backbone)
# backbone=create_feature_extractor(backbone,return_nodes={"features.5":"0"})
# out=backbone(torch.rand(1,3,224,224))
# print(out["0"].shape)
# backbone.out_channels=112
anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], # 在哪些特征层上进行RoIAlign pooling
output_size=[7, 7], # RoIAlign pooling输出特征矩阵尺寸
sampling_ratio=2) # 采样率
model = FasterRCNN(backbone=backbone,
num_classes=num_classes,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
return model
带FPN结构更换backbone
对应的代码在change_backbone_with_fpn.py文件中,同样我们来看下 create_model这部分代码.
首先在create_model函数中导入两个包
import torchvision
from torchvision.models.feature_extraction import create_feature_extractor
我们使用的pytorch版本必须是1.10或以上,torchvision也要按照和pytorch对应的版本
更换backbone
以 mobienet_v3_large backbone 为例
# --- mobilenet_v3_large fpn backbone --- #
backbone = torchvision.models.mobilenet_v3_large(pretrained=True)
设置pretrained=True,在创建模型的过程会自动下载在ImageNet预训练好的权重.
构建带fpn结构的backbone,参考目标检测FPN结构的使用,
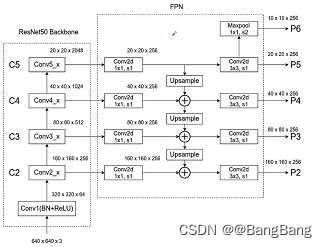
主要难点是要知道我们要获取哪些特征层,并且这些特征层对应的是哪一个模块的输出.
return_layers = {"features.6": "0", # stride 8
"features.12": "1", # stride 16
"features.16": "2"} # stride 32
创建了一个return_layers字典,字典中每一对键值对对应的就是某一个特征层,和不带FPN的backbone比较类似,只是带FPN结构的backbone需要抽取多个特正层.
- key对应的是抽取特征层,在网络中的节点位置
- value, 默认设置从"0"开始递增
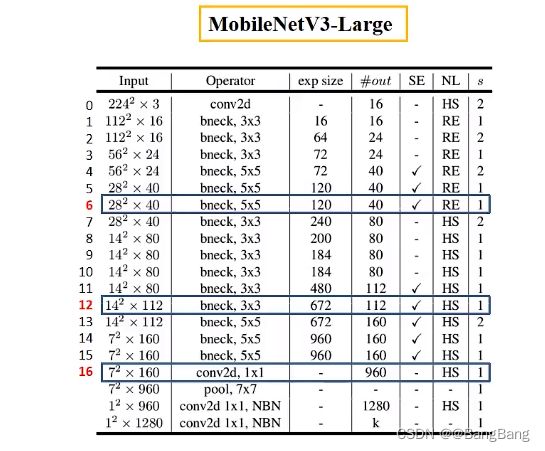
这个图是原论文为给MobileNetV3-Large网络的一个结构,假设我这边想获取图中用蓝色框框出来的这3个模块所对应的输出,可以看到对于第一个模块我们下采样了8倍,第二个模块下采样了16倍,第三个模块下采样了32倍. 当然也可以按自己的想法选择合适的模块抽取特征.
如何找到抽取的3个模块的名称呢?主要有两种方式:
- 第一种是通过源码查看
- 第二种通过
print(backbone)进行查看。
通过IDE查看构建MobileNetV3-Large的源代码,我们可以看到官方所实现的features
self.features = nn.Sequential(*layers)
它所存储的就是上图中对应索引0-16的17个模块,在源码中我们可以知道每搭建一层就会增加一个模块,所以对应的索引就是该模块所在位置.图中抽取的模块,对应的是6,12,16 ,如果不清楚的话也可以打印下backbone进行查看.
设定好return_layers之后,我们还需要指定下我们抽取的这几个特征层,他们对应的channels,通过上图中的表格可以看出这个层对应的channels,分别是[40,112,960], 如果不清楚chanel的话,我随机创建一个tensor,输入backbone,然后通过简单的循环打印抽取特征层名称和shape.
backbone = torchvision.models.mobilenet_v3_large(pretrained=False)
print(backbone)
return_layers = {"features.6": "0", # stride 8
"features.12": "1", # stride 16
"features.16": "2"} # stride 32
# 提供给fpn的每个特征层channel
# in_channels_list = [40, 112, 960]
new_backbone = create_feature_extractor(backbone, return_layers)
img = torch.randn(1, 3, 224, 224)
outputs = new_backbone(img)
[print(f"{k} shape: {v.shape}") for k, v in outputs.items()]
打印的信息:
0 shape: torch.Size([1, 40, 28, 28])
1 shape: torch.Size([1, 112, 14, 14])
2 shape: torch.Size([1, 960, 7, 7])
这里的key 0,1,2是我们在retrun_layers中定义的value.其中通道可以看到分别是40,112,960,结合每个特征层输出的高和宽的数值,能够帮助我们分析我们抽取的特征层的下采样倍率是不是对的.
接下来,通过实例化backboneWithFPN来构建带fpn的backbone.
backbone_with_fpn = BackboneWithFPN(new_backbone,
return_layers=return_layers,
in_channels_list=in_channels_list,
out_channels=256,
extra_blocks=LastLevelMaxPool(),
re_getter=False)
-
这里将re_getter设置为False就不会重构模型了,直接利用create_feature_extractor(backbone, return_layers)实例化的new_backbone,因为利用BackboneWithFPN的话它无法获取某个layers下的子模块的输出,因此利用create_feature_extractor(backbone, return_layers)去重构backbone会更方便和灵活. -
传入return_layers,in_channel_list
-
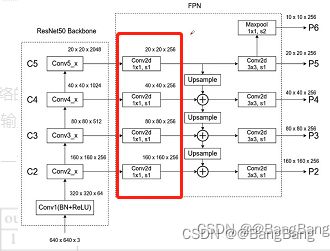
out_channels为256,我们在构建fpn的时候将每个特征层的channel通过1x1的卷积调整为256
-
extra_blocks=LastLevelMaxPool, 它的作用就是图中我们所画的,在最高层的特征层中,在通过一个Maxpool在进行一次上采样.得到尺度更小的特征层.尺度更小的特征层有利于我们检测更大的目标.而且这里还需要注意一个点Maxpool得到的特征层,它只用于我们的RPN部分,不在Fast-RCNN中使用.
然后利用FeaturePyramidNetwork去构建fpn结构
self.fpn = FeaturePyramidNetwork(
in_channels_list=in_channels_list,
out_channels=out_channels,
extra_blocks=extra_blocks,
)
从正向传播可以看到,它利用输入的数据,依次通过boy也就是重构后的backbone,和fpn然后得到我们的输出.
class BackboneWithFPN(nn.Module):
def __init__(self,
backbone: nn.Module,
return_layers=None,
in_channels_list=None,
out_channels=256,
extra_blocks=None,
re_getter=True):
super().__init__()
if extra_blocks is None:
extra_blocks = LastLevelMaxPool()
if re_getter is True:
assert return_layers is not None
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
else:
self.body = backbone
self.fpn = FeaturePyramidNetwork(
in_channels_list=in_channels_list,
out_channels=out_channels,
extra_blocks=extra_blocks,
)
self.out_channels = out_channels
def forward(self, x):
x = self.body(x)
x = self.fpn(x)
return x
从而完成BackboneWithFPN的backbone的构建
AnchorGenerator 和aspect_ratios
anchor_sizes = ((64,), (128,), (256,), (512,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
anchor_generator = AnchorsGenerator(sizes=anchor_sizes,
aspect_ratios=aspect_ratios)
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0', '1', '2'], # 在哪些特征层上进行RoIAlign pooling
output_size=[7, 7], # RoIAlign pooling输出特征矩阵尺寸
sampling_ratio=2) # 采样率
- 这里针对每个特征层,都只设定了一个anchor尺度,比如对于尺度最大的特征层,用于检测小目标,将尺度设置为64,中等大小的特征层将anchor设置为128,相对高层的特征层anchor尺寸设置为256,最后通过maxpool得到的特征层是512
- 针对每个特征层,设置了(0.5,1.0,2.0)这三个比率
- MultiScaleRoIAlign是在Fast-RCNN中使用的,feature_names定义的是将RPN结构生成的perposal映射到哪些的特征层上.,这里为什么maxpool层没用到,因为该层只用在RPN部分,不在Fast-RCNN部分使用.
- output_size 说明我们将采样到多大
- sampling_rate 定义我们的采样率
定义好了带FPN的backbone,以及anchor_generator, roi_pooler,那么我们就可以创建FasterRCNN了
model = FasterRCNN(backbone=backbone_with_fpn,
num_classes=num_classes,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
完整的带有FPN结构的FasterRCNN代码如下:
def create_model(num_classes):
import torchvision
from torchvision.models.feature_extraction import create_feature_extractor
# --- mobilenet_v3_large fpn backbone --- #
backbone = torchvision.models.mobilenet_v3_large(pretrained=False)
print(backbone)
return_layers = {"features.6": "0", # stride 8
"features.12": "1", # stride 16
"features.16": "2"} # stride 32
# 提供给fpn的每个特征层channel
# in_channels_list = [40, 112, 960]
new_backbone = create_feature_extractor(backbone, return_layers)
img = torch.randn(1, 3, 224, 224)
outputs = new_backbone(img)
[print(f"{k} shape: {v.shape}") for k, v in outputs.items()]
# --- efficientnet_b0 fpn backbone --- #
# backbone = torchvision.models.efficientnet_b0(pretrained=True)
# # print(backbone)
# return_layers = {"features.3": "0", # stride 8
# "features.4": "1", # stride 16
# "features.8": "2"} # stride 32
# # 提供给fpn的每个特征层channel
# in_channels_list = [40, 80, 1280]
# new_backbone = create_feature_extractor(backbone, return_layers)
# # img = torch.randn(1, 3, 224, 224)
# # outputs = new_backbone(img)
# # [print(f"{k} shape: {v.shape}") for k, v in outputs.items()]
backbone_with_fpn = BackboneWithFPN(new_backbone,
return_layers=return_layers,
in_channels_list=in_channels_list,
out_channels=256,
extra_blocks=LastLevelMaxPool(),
re_getter=False)
anchor_sizes = ((64,), (128,), (256,), (512,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
anchor_generator = AnchorsGenerator(sizes=anchor_sizes,
aspect_ratios=aspect_ratios)
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0', '1', '2'], # 在哪些特征层上进行RoIAlign pooling
output_size=[7, 7], # RoIAlign pooling输出特征矩阵尺寸
sampling_ratio=2) # 采样率
model = FasterRCNN(backbone=backbone_with_fpn,
num_classes=num_classes,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
return model
注意:改完backbone之后,拿它直接训练自己的数据集的话,一般效果会比较差,因为我们这里只载入backbone部分的预训练权重,对FPN,RPN以及Fast RCNN部分的权重我们都是没有经过任何学习的,直接拿来训练自己的数据集效果一般会比较差.
建议: 先拿自己构建的模型在coco数据集上进行预训练,预训练之后再拿你自己的数据进行迁移学习,就能达到比较好的效果.