爬取豆瓣电影Top250和数据分析
目录
一、 爬取
1. 爬取主页面
2. BeautifulSoup查找元素
3. 爬取每部电影信息
二、 数据分析
1. 对上映时间分析
绘制直方图
绘制饼图
绘制折线图
2. 对电影类型分析
绘制词云图
分析某种电影类型随时间变化的折线图
3. 分析演员或者导演
排名前十的演员
对某个演员出演的电影得分分析
三、完整代码
1. 爬取代码
2. 数据分析代码
爬取豆瓣电影内容,并将其写入excel,对数据进行数据分析
方法:requests,BeautifulSoup,pandas
一、 爬取
爬取豆瓣电影内容方法是:先在主页面(每页25部电影,一共10页)上爬取每部电影的网址,然后依次进入每部电影的网址爬取内容。
1. 爬取主页面
在爬取之前,需要找到headers和url。
headers主要是由User-Agent构成,其作用是告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本。在爬取一般的网站只需要一个User-Agent就够了。
url 第一页主页网站https://movie.douban.com/top250?start=0&filter= ,每页的网站就是前一页start=后面加上25。
接下来就是运用requests开始访问网站了。requests一般有两种方法get和post,如下图就是确定使用get或者使用post。在这里就是使用get。

下面就开始访问网站了。输出response如果得到的是200那么就是访问成功了,反之可以根据错误的编号找到错误源 点击查看错误代码大全 。
response = requests.get(url=url, headers=headers)下一步就是运用BeautifulSoup开始解析网页。
soup = BeautifulSoup(response.text, 'html.parser')这里的html.parser,是四种解析器中的一种,也是经常使的。得到的soup就是HTML。所以后面我们可以直接使用soup找到我们需要的属性。
做到了这里就完成了爬虫工作的一半。

2. BeautifulSoup查找元素
俗话说磨刀不误砍柴工,在我们进行查找元素时,我们先对BeautifulSoup查找元素方法了解一下。
接下来就介绍以下soup的使用方法,功能强大的CSS选择器能完成我们绝大多数的功能,下面我们就着重介绍一下:

1. find_all
格式为:soup.find_all('标签',attrs={'属性名':'属性值'}) 这种格式可以运用绝大多数的情况下,重点记忆!
例如对主页电影名进行爬取,可以看到,标签为span,属性名为class,属性值为title,那么就可以应用find_all了。

list_name = soup.find_all('span',attrs={'class':'title'}) # 结果为一个列表
for i in list_name:
print(i.get_text()) # 类型为Tag,需要用get_text()得到的部分结果为:

可以看到得到的结果是在一个网页中的所有的标签为span,属性名为class,属性值为title。所以这里引出find_all就是查找网页中所有满足条件的内容。
2. find
find_all是找所有满足条件的内容,那么可想而知find也就是查找第一个满足条件的。
name = soup.find('span',attrs={'class':'title'})
print(name.get_text())
print(name.string) # string与get_text()一样
还可以直接find或者find_all 字符串,只会找到满足条件的,例如:
name = soup.find('span',attrs={'class':'title'},string='肖申克的救赎')
print(name.get_text())
print(name.string) # string与get_text()一样
3. select
select一般有两种方法爬取内容,第一,复制selector。第二,查找标签。
select可以直接在找到所要爬取的内容,复制selector,如下所示:
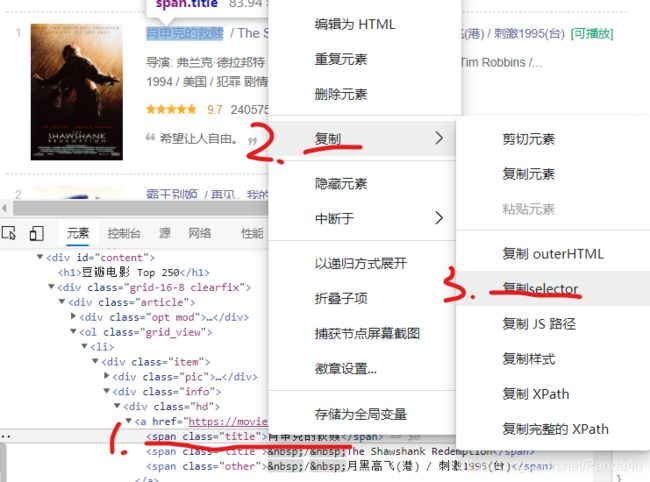
names = soup.select('#content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)')
for name in names:
print(name.get_text())

得到的结果只是每个主页的第一部的第一个名字。所以我们要删除第一个:nth-child(1),才会爬取全部的信息,因为selector是精确定位某个元素的,所以我们要想爬取全部内容就必须删除一部分定位。
删除之后得到的部分结果为:

select的第二种方法和find类似,重点就是class 换成点(因为class是类),id换成#。但是我们完全可以不用直接去找标签,以下方法就是确定标签的,如图:
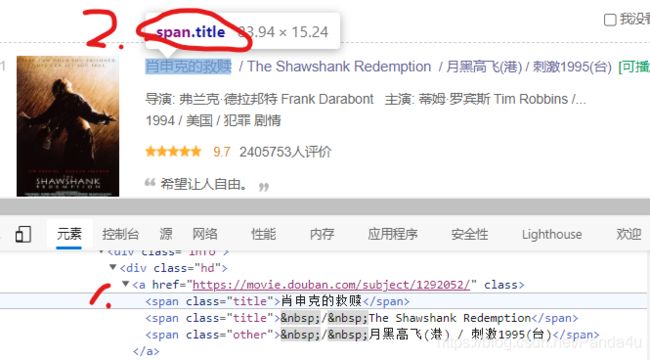
这里我们看见了电影名的标签为“span.title”,所以查找网页中符合标签的全部内容,如下:
names = soup.select('span.title')
for name in names:
print(name.get_text())
总结:BeautifulSoup查找元素主要运用find_all和select这两种方法,查找元素注意找到爬取内容的标签和这两种方法的优缺点。
下面我们就正式开始爬取元素信息:
首先,在每页的主页面将每部电影的网址爬取下来,我们可以直接去每部电影中分析。

找到含有电影网址的标签href,这里使用的方法就是复制selector爬取
分析:如果用find_all会得到很多的并且不是需要的href,十分的麻烦,所以我们可以精确定位。
url_mv_list = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a')
print(url_mv_list)
输出url_mv_list 得到的是一个列表,列表里面的元素都是一部电影的所有信息,如下图,

所以我们只需要对每一个元素的href读取就行了
for index_url in range(len(url_mv_list)):
url_mv = url_mv_list[index_url]['href']
list_url_mv.append(url_mv)
print(url_mv)得到的结果就是每部电影网址

3. 爬取每部电影信息
然后就是进入根据得到的每部电影网址,解析网页,然后爬取元素。方法和爬取主页面方法一样,这里就直接贴代码了。
在此之前,需要考虑爬取内容输出格式,因为我们最后要将爬取得到的结果输入到Excel中,运用到的方法是先将数据换成dataframe,然后写入Excel。举个例子就能很好说明怎样转换成dataframe。
a = [['a', '1', '2'], ['b', '3', '4'], ['c', '5', '6']]
df = pd.DataFrame(a, columns=['pan', 'panda', 'fan'])
print(df)
根据上面的例子得到的结果,我们需要将每一部电影的信息做成一个列表,作为函数的返回值,然后再将返回值添加到一个列表中,这样就可以转换成dataframe了。
# 对每部电影进行处理
def loading_mv(url,number):
list_mv = [] # 将爬取每部电影信息加入到其中
print('-----正在处理第{}部电影-----'.format(number+1))
list_mv.append(number+1) # 排名
# 解析网页
response_mv = requests.get(url=url,headers=headers)
soup_mv = BeautifulSoup(response_mv.text,'html.parser')
# 爬取电影名
mv_name = soup_mv.find_all('span',attrs={'property':'v:itemreviewed'}) # 电影名
mv_name = mv_name[0].get_text()
list_mv.append(mv_name)
# print(mv_name)
# 爬取电影的上映时间
mv_year = soup_mv.select('span.year') # 电影上映时间
mv_year = mv_year[0].get_text()[1:5]
list_mv.append(mv_year)
# print(mv_year)
# 爬取导演信息
list_mv_director = [] # 导演
mv_director = soup_mv.find_all('a',attrs={'rel':"v:directedBy"})
for director in mv_director:
list_mv_director.append(director.get_text())
string_director = '/'.join(list_mv_director) # 重新定义格式
list_mv.append(string_director)
# print(list_mv_director)
# 爬取主演信息
list_mv_star = [] # 主演
mv_star = soup_mv.find_all('span',attrs={'class':'actor'})
if mv_star == []: # 在第210部时没有主演
list_mv.append(None)
else :
mv_star = mv_star[0].get_text().strip().split('/')
mv_first_star = mv_star[0].split(':')
list_mv_star.append(mv_first_star[-1].strip())
del mv_star[0] # 去除'主演'字段
for star in mv_star:
list_mv_star.append(star.strip())
string = '/'.join(list_mv_star) # 重新定义格式
list_mv.append(string)
# 爬取电影类型
list_mv_type = [] # 电影类型
mv_type = soup_mv.find_all('span',attrs={'property':'v:genre'})
for type in mv_type:
list_mv_type.append(type.get_text())
string_type = '/'.join(list_mv_type)
list_mv.append(string_type)
# print(list_mv_type)
# 爬取电影评分
mv_score = soup_mv.select('strong.ll.rating_num') # 评分
mv_score = mv_score[0].get_text()
list_mv.append(mv_score)
# 爬取评价人数
mv_evaluation_num = soup_mv.select('a.rating_people') # 评价人数
mv_evaluation_num = mv_evaluation_num[0].get_text().strip()
list_mv.append(mv_evaluation_num)
# 爬取剧情简介
mv_plot = soup_mv.find_all('span',attrs={"class":"all hidden"}) # 剧情简介
if mv_plot == []:
list_mv.append(None)
else:
string_plot = mv_plot[0].get_text().strip().split()
new_string_plot = ' '.join(string_plot)
list_mv.append(new_string_plot)
# 加入电影网址
list_mv.append(url)
return list_mv定义了个爬取每部电影内容,下面就开始调用函数:
先创建了一个list_all_mv的列表,用来存储调用函数的返回值,即存储每部电影的信息,如下图,
list_all_mv = []
dict_mv_info = {}
for number in range(len(list_url_mv)):
mv_info = loading_mv(list_url_mv[number],number)
list_all_mv.append(mv_info)
print('-----运行结束-----')
pd = DataFrame(list_all_mv,columns=['电影排名','电影名','上映时间','导演','主演','电影类型','电影评分','评价人数','电影简介','电影链接'])
# print(pd)
pd.to_excel(r'C:\Users\86178\Desktop\豆瓣电影Top250.xlsx')最后得到了豆瓣电影Top250excel表,如下图:

附:当你用同一个IP 访问次数过多时,网站可能会将你的IP封了,类似于:
HTTPSConnectionPool(host='movie.douban.com', port=443): Max retries exceeded with url: /subject/1292052/ (Caused by NewConnectionError(': Failed to establish a new connection: [Errno 11001] getaddrinfo failed')) 解决办法:
1. 换一个WiFi,就能够解决,因为不同的WiFi会有不同的外部IP,所以当我们的IP被封了,换一个WiFi或者热点就好了。
2. 代建代理IP池。代理IP池原理就是找到一些可用的IP加入在requests中,也就是指定一个IP去访问网站
IP格式为 : 'http':'http://IP:端口' , 如: 'http':'http://119.14.253.128:8088'
response = requests.get(url=url,headers=headers,proxies=ip,timeout=3) # 在0.1秒之内请求百度的服务器
获取IP有很多种途径
免费代理IP http://ip.yqie.com/ipproxy.htm
66免费代理网 http://www.66ip.cn/
89免费代理 http://www.89ip.cn/
无忧代理 http://www.data5u.com/
云代理 http://www.ip3366.net/
快代理 https://www.kuaidaili.com/free/
极速专享代理 http://www.superfastip.com/
HTTP代理IP https://www.xicidaili.com/wt/
小舒代理 http://www.xsdaili.com
西拉免费代理IP http://www.xiladaili.com/
小幻HTTP代理 https://ip.ihuan.me/
全网代理IP http://www.goubanjia.com/
飞龙代理IP http://www.feilongip.com/
搭建代理IP池就是爬取这些网站上面的IP和端口,然后将爬取得到的内容做成标准格式。后续我会出一搭建代理IP池的博客。
二、 数据分析
有句话说得好,数据就是金钱,我们得到了数据,还需要进一步的分析,才能发挥更大的作用。读取excel和写入的方法一样,得到的结果就是dataframe。
def excel_to_dataframe(excel_path):
df = pd.read_excel(excel_path,keep_default_na=False) # keep_default_na=False 得到的结果是'',而不是nan
return df
excel_path = r'C:\Users\86178\Desktop\豆瓣电影Top250.xlsx'
data_mv = excel_to_dataframe(excel_path)下面就对爬取的内容进行处理,如上映时间,电影类型,主演或者导演。
1. 对上映时间分析
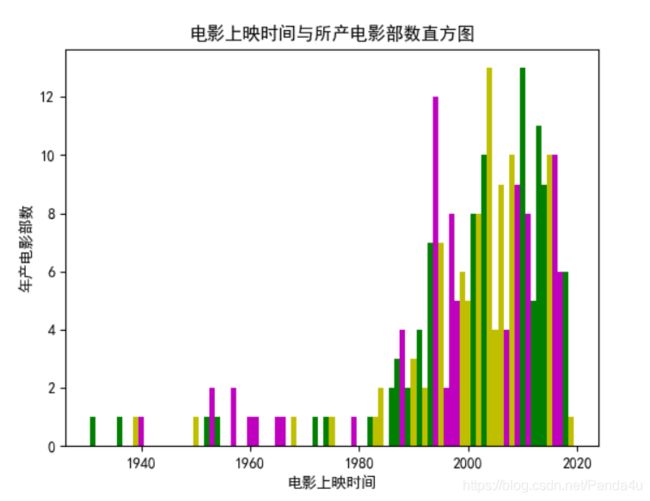
绘制直方图
绘制饼图

绘制折线图

1. 综合以上三个图得到主要上榜的电影集中在1993-2016左右。
2. 可以得出在1994、2004、2010这三年上映的电影上榜次数达12部及以上。
3. 不能得出随时间的增长,上榜的电影就越多。
2. 对电影类型分析
绘制词云图
将所有电影类型统计记数,绘制词云图,如下图

分析某种电影类型随时间变化的折线图
对“剧情”分析

对”科幻“分析

综合以上得出结论:
1. 电影类型为”剧情“一直都是人们所爱好的,特别是在1994年的电影达到了巅峰12部,结合上一步对时间的分析可以得出1994上映的全部电影都是”剧情“类型的,并且直到现在为止,仍然堪称经典。
2. ”科幻”类型的电影,在早期科技不发达时,拍摄不到那么好的效果。但是随时间的发展,科技的进步,“科技”类型的电影得到了发展。
3. 分析演员或者导演
判断演员或者导演的排名主要是根据电影评分为依据,因为在Top250榜上,都是人们所认可的,所以我们粗略的根据总的评分高低判断演员排名。
1. 排名前十的演员

2. 对某个演员出演的电影得分分析

综合以上的结果可以得出结论:
1. 前十的演员为:张国荣,梁朝伟........
2. 分析某个演员出演的电影得分
三、完整代码
1. 爬取代码
import requests
from bs4 import BeautifulSoup
from pandas import DataFrame
'''
最后成功提取了
'电影排名','电影名','上映时间','导演','主演','电影类型','电影评分','评价人数','电影链接'
最后将结果输出到了 豆瓣电影Top250.xlsx
但是还存在问题:就是提取语言和制片国家/地区时,出现没有selector的情况。
要解决该问题可能需要xpath
'''
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55'}
start_num = [i for i in range(0,226,25)]
list_url_mv = [] # 所有电影的URL
for start in start_num:
url = 'https://movie.douban.com/top250?start={}&filter='.format(start)
print('正在处理url:',url)
response = requests.get(url=url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
url_mv_list = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a')
# print(url_mv_list)
for index_url in range(len(url_mv_list)):
url_mv = url_mv_list[index_url]['href']
list_url_mv.append(url_mv)
# print(url_mv)
# 对每部电影进行处理
def loading_mv(url,number):
list_mv = []
print('-----正在处理第{}部电影-----'.format(number+1))
list_mv.append(number+1) # 排名
# 解析网页
response_mv = requests.get(url=url,headers=headers)
soup_mv = BeautifulSoup(response_mv.text,'html.parser')
# 爬取电影名
mv_name = soup_mv.find_all('span',attrs={'property':'v:itemreviewed'}) # 电影名
mv_name = mv_name[0].get_text()
list_mv.append(mv_name)
# print(mv_name)
# 爬取电影的上映时间
mv_year = soup_mv.select('span.year') # 电影上映时间
mv_year = mv_year[0].get_text()[1:5]
list_mv.append(mv_year)
# print(mv_year)
# 爬取导演信息
list_mv_director = [] # 导演
mv_director = soup_mv.find_all('a',attrs={'rel':"v:directedBy"})
for director in mv_director:
list_mv_director.append(director.get_text())
string_director = '/'.join(list_mv_director) # 重新定义格式
list_mv.append(string_director)
# print(list_mv_director)
# 爬取主演信息
list_mv_star = [] # 主演
mv_star = soup_mv.find_all('span',attrs={'class':'actor'})
if mv_star == []: # 在第210部时没有主演
list_mv.append(None)
else :
mv_star = mv_star[0].get_text().strip().split('/')
mv_first_star = mv_star[0].split(':')
list_mv_star.append(mv_first_star[-1].strip())
del mv_star[0] # 去除'主演'字段
for star in mv_star:
list_mv_star.append(star.strip())
string = '/'.join(list_mv_star) # 重新定义格式
list_mv.append(string)
# 爬取电影类型
list_mv_type = [] # 电影类型
mv_type = soup_mv.find_all('span',attrs={'property':'v:genre'})
for type in mv_type:
list_mv_type.append(type.get_text())
string_type = '/'.join(list_mv_type)
list_mv.append(string_type)
# print(list_mv_type)
# 爬取电影评分
mv_score = soup_mv.select('strong.ll.rating_num') # 评分
mv_score = mv_score[0].get_text()
list_mv.append(mv_score)
# 爬取评价人数
mv_evaluation_num = soup_mv.select('a.rating_people') # 评价人数
mv_evaluation_num = mv_evaluation_num[0].get_text().strip()
list_mv.append(mv_evaluation_num)
# 爬取剧情简介
mv_plot = soup_mv.find_all('span',attrs={"class":"all hidden"}) # 剧情简介
if mv_plot == []:
list_mv.append(None)
else:
string_plot = mv_plot[0].get_text().strip().split()
new_string_plot = ' '.join(string_plot)
list_mv.append(new_string_plot)
# 加入电影网址
list_mv.append(url)
return list_mv
# url1 = 'https://movie.douban.com/subject/1292052/'
# url2 = 'https://movie.douban.com/subject/26430107/' # 210部
# a = loading_mv(url1,1)
# # b = loading_mv(url2,210)
# # list_all_mv.append(a)
# # list_all_mv.append(b)
list_all_mv = []
dict_mv_info = {}
for number in range(len(list_url_mv)):
mv_info = loading_mv(list_url_mv[number],number)
list_all_mv.append(mv_info)
print('-----运行结束-----')
pd = DataFrame(list_all_mv,columns=['电影排名','电影名','上映时间','导演','主演','电影类型','电影评分','评价人数','电影简介','电影链接'])
# print(pd)
pd.to_excel(r'C:\Users\86178\Desktop\豆瓣电影Top250.xlsx')2. 数据分析代码
'''
对爬取得到的豆瓣电影Top250进行数据分析
分析内容:
1. 对时间:对时间分析
绘制直方图
饼图
折线图——电影
2.对类型: 电影类型随时间变化
绘制电影类型随时间变化
电影类型词云图
3.对主演或导演: 以电影评分分析演员或者导演
前十名主演
查询演员/导演出演信息
所有演员导演出演信息
'''
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import wordcloud
import imageio
# csv_path = '豆瓣电影Top250.csv' # 不能用csv进行处理,可能会出现错误
# 读取excel转换成dataframe,方便读取
def excel_to_dataframe(excel_path):
df = pd.read_excel(excel_path,keep_default_na=False) # keep_default_na=False 得到的结果是'',而不是nan
return df
excel_path = r'C:\Users\86178\Desktop\豆瓣电影Top250.xlsx'
data_mv = excel_to_dataframe(excel_path)
dict_time = {}
for time in data_mv['上映时间']:
dict_time[time] = dict_time.get(time,0)+1
list_time = list(dict_time.items())
list_time.sort(key=lambda x:x[1],reverse=True)
list_year = [] # 年份
list_times = [] # 出现次数
for t in list_time:
list_year.append(t[0])
list_times.append(t[1])
# 绘制直方图
def make_Histogram(list_x,list_y,color):
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.bar(list_x,list_y,width=1,color=color)
plt.title('电影上映时间与所产电影部数直方图')
plt.xlabel('电影上映时间')
plt.ylabel('年产电影部数')
plt.show()
# make_Histogram(list_year,list_times,color=['g','y','m']) # 绘制电影年份出现次数直方图
# 绘制饼图
def make_Pie(list_times,list_year):
mpl.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei', 'FangSong'] # 汉字字体,优先使用楷体,如果找不到楷体,则使用黑体
mpl.rcParams['font.size'] = 12 # 字体大小
mpl.rcParams['axes.unicode_minus'] = False # 正常显示负号
plt.figure(figsize=(10,10),dpi=100) # 视图的大小
plt.pie(list_times, # 指定绘图数据
labels=list_year, # 添加饼图圈外的标签
autopct='%1.2f%%', # 设置百分比格式
textprops={'fontsize':10}, # 设置饼图中的属性字体大小、颜色
labeldistance=1.05) # 设置各扇形标签(图例)与圆心的距离
# plt.legend(fontsize=7) # 设置饼图指示
plt.title('年产电影部数占比')
plt.show()
pie_other = len([i for i in list_time if i[1]==1]) # 将年份电影为1的归为其它类
list_pie_year = []
list_pie_times = []
for i in list_time:
if i[1] == 1:
break
else :
list_pie_year.append(i[0])
list_pie_times.append(i[1])
list_pie_year.append('其它电影为1的年份')
list_pie_times.append(pie_other)
#
# make_Pie(list_pie_times,list_pie_year)
# make_Pie(list_times,list_year)
# 绘制折现图
def make_Plot(list_year,list_times):
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('年产电影个数折现图')
plt.xlabel('电影上映时间')
plt.ylabel('年产电影部数')
plt.plot(list_year, list_times)
plt.show()
list_plot_year = []
list_plot_times = []
list_time.sort(key=lambda x:int(x[0]))
for t in list_time:
list_plot_year.append(t[0])
list_plot_times.append(t[1])
# make_Plot(list_plot_year,list_plot_times)
mv_type = data_mv['电影类型']
dict_type = {}
for type in mv_type:
line = type.split('/')
for t in line:
dict_type[t] = dict_type.get(t,0) + 1
list_type = list(dict_type.items())
list_type.sort(key=lambda x:x[1],reverse=True)
# 绘制词云图
def c_wordcloud(ls):
# string1 = ' '.join(ls)
gpc=[]
for i in ls:
gpc.append(i[0])
string1=" ".join('%s' % i for i in gpc)
color_mask=imageio.imread(r"logo.jpg")
wc = wordcloud.WordCloud(random_state=30,
width=600,
height=600,
max_words=30,
background_color='white',
font_path=r'msyh.ttc',
mask=color_mask
)
wc.generate(string1)
plt.imshow(wc)
plt.show()
# wc.to_file(path)
# c_wordcloud(list_type)
# [年份,电影类型]
list_time_type = []
for i in range(250):
line = data_mv['电影类型'][i].split('/')
for j in line:
time_type = []
time_type.append(data_mv['上映时间'][i])
time_type.append(j)
list_time_type.append(time_type)
dict_time_type = {}
for i in list_time_type:
dict_time_type[tuple(i)] = dict_time_type.get(tuple(i),0) + 1
list_num_time_type = list(dict_time_type.items())
list_num_time_type.sort(key=lambda x:x[1],reverse=True)
# 制作一种电影类型的发展史(以电影类型为单位)
def mv_time_type(type_name):
list_mv_type = []
for num in list_num_time_type:
if num[0][1] == type_name:
list_mv_type.append(num)
list_mv_type.sort(key=lambda x:x[0][0],reverse=False)
list_year = []
list_times = []
for t in list_mv_type:
list_year.append(t[0][0])
list_times.append(t[1])
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('电影类型"{}"的发展史'.format(type_name))
plt.xlabel('年份')
plt.ylabel('每年出现的次数')
plt.plot(list_year,list_times)
plt.show()
# mv_time_type('剧情')
# mv_time_type('科幻') # 主要集中在2000以后
# 计算导演和主演的每部作品的得分和总得分
def people_score(peo_dir_star):
list = []
for num in range(250):
if data_mv[peo_dir_star][num] == '':
continue
else:
peoples = data_mv[peo_dir_star][num].split('/')
for people in peoples:
list_p_s = []
list_p_s.append(people)
list_p_s.append(data_mv['电影评分'][num])
list_p_s.append(data_mv['电影排名'][num])
list_p_s.append(data_mv['电影名'][num])
list.append(list_p_s)
return list
list_director = people_score('导演')
list_star = people_score('主演')
# 最佳导演或者演员----根据总分求得
def best_people(list_people):
dict_people = {}
for i in list_people:
dict_people[i[0]] = dict_people.get(i[0],[]) + [(i[1],i[2],i[3])]
for i in dict_people.items():
i[1].append(float('{:.2f}'.format(sum([j[0] for j in i[1]]))))
# ('巩俐', [(9.6, 2, '霸王别姬'), (9.3, 30, '活着'), (8.7, 109, '唐伯虎点秋香 唐伯虎點秋香'), '27.60'])
list_new_people = list(dict_people.items())
list_new_people.sort(key=lambda x:x[1][-1],reverse=True)
print('搜索结束,请开始您的操作(输入数字)!\n---输入1排名前十的主演---\n---输入2搜索演员的出演情况---\n---输入3输出所有演员---')
print('-----输入enter退出-----')
select_number = input('开始输入操作:')
while select_number != '':
if select_number == '1':
print('前十演员出演信息:')
list_all_score = [] # 总分
list_prople_name = []
for i in list_new_people[0:10]:
print(i)
list_prople_name.append(i[0])
list_all_score.append(i[1][-1])
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# plt.figure(figsize=(10, 10), dpi=100) # 视图的大小
plt.title('前十演员总评分')
plt.xlabel('演员')
plt.ylabel('总评分')
plt.bar(list_prople_name,list_all_score,width=0.5)
plt.show()
elif select_number == '2':
# star_name = input('输入您想要知道的演员名:')
star_name = ' '
while star_name != '':
star_name = input('输入您想要知道的演员名:')
list_mv_name = [] # 电影名
list_mv_score = [] # 电影评分
for number,i in enumerate(list_new_people):
if star_name == i[0]:
all_score = i[1][-1] # 总分
del i[1][-1]
for j in i[1]:
list_mv_name.append(j[2])
list_mv_score.append(j[0])
print('{} 主演豆瓣电影Top250中排名{}的《{}》评分为 {}'.format(star_name,j[1],j[2],j[0]))
print("{}共主演了{}部电影,所有总分为{},在所有演员中排名第{}".format(star_name,len(i[1]),all_score,number+1))
print('查询结束!')
# 计算饼图
def pie_mv_score():
mpl.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei','FangSong'] # 汉字字体,优先使用楷体,如果找不到楷体,则使用黑体
mpl.rcParams['font.size'] = 12 # 字体大小
mpl.rcParams['axes.unicode_minus'] = False # 正常显示负号
plt.figure(figsize=(10,10))
plt.pie(list_mv_score,
labels=list_mv_name,
autopct='%1.2f%%', # 计算百分比,设置及格式
textprops={'fontsize': 10})
plt.title('{}的主演电影总分比---总排名为{}'.format(star_name,number+1))
plt.show()
pie_mv_score()
break
else:
print('查无此人!')
break
elif select_number == '3':
for i in list_new_people:
print(i)
else :
print('无此项操作!')
select_number = input('查询结束,您还可以继续输入查询序号:')
print('-----查询结束-----')
best_people(list_star)