吴恩达机器学习课程-第六周(part1)
1.应用机器学习的建议
1.1 下一步做什么
假如说在预测房价时产生了巨大的误差,现在要想改进这个算法,接下来应该怎么办?
- 获得更多的训练样本
- 尝试减少特征的数量
- 尝试获得更多的特征
- 尝试增加多项式特征
- 尝试减少正则化程度 λ \lambda λ
- 尝试增加正则化程度 λ \lambda λ
但是如果随机选择上面的某种方法来改进我们的算法会浪费很多事件,所以需要运用一些机器学习诊断法来帮助判断哪些方法对算法是有效的
1.2 评估一个假设
当确定学习算法的参数的时候,需要考虑的是选择参数来使训练误差最小化。但是前面提到假设函数有着很小的训练误差可能是因为过拟合。当特征数目只有一个的时候,还可以画出假设函数 h ( x ) h(x) h(x)的图像,通过观察图像的趋势判断是否过拟合:
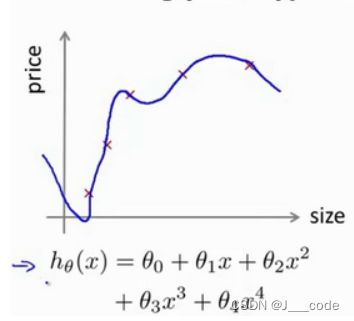
但是如果特征数很多就无法画出图像了。此时需要将数据分为训练集和测试集来验证算法是否过拟合,下图将原训练集按 7 : 3 7:3 7:3分为训练集和测试集:
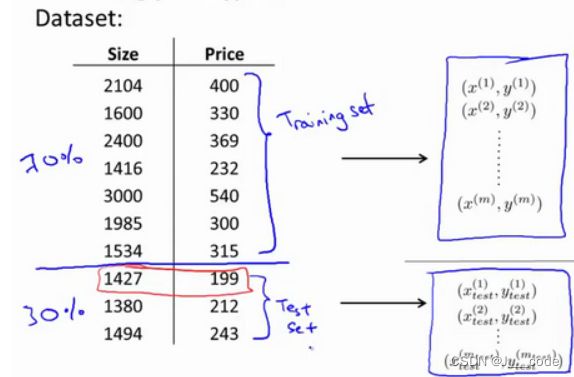
通过训练集学习到模型的参数后,再将测试集运用到该模型上。对于线性回归还是使用原来的代价函数计算误差 J t e s t ( θ ) = 1 2 m t e s t ∑ i = 1 m t e s t ( h θ ( x t e s t ( i ) ) − y t e s t ( i ) ) 2 J_{test}(\theta)=\frac{1}{2m_{test}}\sum_{i=1}^{m_{test}}(h_\theta(x^{(i)}_{test})-y_{test}^{(i)})^2 Jtest(θ)=2mtest1∑i=1mtest(hθ(xtest(i))−ytest(i))2;对于逻辑回归模型,可以采用不同方式计算误差:
-
代价函数: m t e s t m^{test} mtest表示测试集的数目
J t e s t ( θ ) = − 1 m t e s t ∑ i = 1 m t e s t y t e s t ( i ) l o g ( h θ ( x t e s t ( i ) ) ) + ( 1 − y t e s t ( i ) ) l o g ( 1 − h θ ( x t e s t ( i ) ) ) J_{test}(\theta)=-\frac{1}{m_{test}}\sum_{i=1}^{m_{test}}y_{test}^{(i)}log(h_\theta(x_{test}^{(i)}))+(1-y_{test}^{(i)})log(1-h_\theta(x_{test}^{(i)})) Jtest(θ)=−mtest1∑i=1mtestytest(i)log(hθ(xtest(i)))+(1−ytest(i))log(1−hθ(xtest(i)))
-
误分类的比例:对于每一个测试集样本使用下面公式,然后对计算结果求平均
err ( h θ ( x ) , y ) = { 1 if h ( x ) ≥ 0.5 and y = 0 , or if h ( x ) < 0.5 and y = 1 0 Otherwise \operatorname{err}\left(h_{\theta}(x), y\right)=\left\{\begin{array}{c}1 \text { if } h(x) \geq 0.5 \text { and } y=0, \text { or if } h(x)<0.5 \text { and } y=1 \\ 0 \text { Otherwise }\end{array}\right. err(hθ(x),y)={1 if h(x)≥0.5 and y=0, or if h(x)<0.5 and y=10 Otherwise
1.3 模型选择和交叉验证集
假设此时有多个不同项数的模型 h θ ( x ) = θ 0 + θ 1 x 、 h θ ( x ) = θ 0 + θ 1 x + θ 2 x 2 . . . h_{\theta}(x)=\theta_0+\theta_1x、h_{\theta}(x)=\theta_0+\theta_1x+\theta_2x^2... hθ(x)=θ0+θ1x、hθ(x)=θ0+θ1x+θ2x2...。要获得一个泛化能力最好的模型,可以分为以下两步:
- 最小化每个模型的训练误差 J ( θ ) t r a i n J(\theta)_{train} J(θ)train,得到每个模型的参数
- 对所有模型求测试集误差 J ( θ ) t e s t J(\theta)_{test} J(θ)test,选择 J ( θ ) t e s t J(\theta)_{test} J(θ)test最小的一个模型
- 通过测试集求得选取模型的泛化能力
上述过程中一个问题是模型是通过测试集选取的,最后检测模型的泛化能力还是使用测试集,明显该模型对测试集的拟合是很好的,依此评价泛化能力很不合理
为了解决上述问题,需要使用交叉验证集(CV)来帮助选择模型。 下图中使用60%的数据作为训练集,20%的数据作为交叉验证集,剩余20%的数据作为测试集:

模型选择的步骤如下:
- 使用训练集将上述所有模型进行训练,得到每个模型的参数
- 分别对交叉验证集计算得出所有模型的交叉验证误差 J c v ( θ ) = 1 2 m c v ∑ i = 1 m c v ( h θ ( x c v i − y c v i ) ) 2 J_{cv}(\theta)=\frac{1}{2m_{cv}}\sum_{i=1}^{m_{cv}}(h_\theta(x_{cv}^{{i}}-y_{cv}^{{i}}))^2 Jcv(θ)=2mcv1∑i=1mcv(hθ(xcvi−ycvi))2
- 选取交叉验证误差值最小的模型
- 使用测试集对步骤3选出的模型计算测试集误差 J t e s t ( θ ) J_{test}(\theta) Jtest(θ)
1.4 诊断偏差和方差
当算法的表现不理想是,要么是偏差较大(欠拟合),要么是方差较大(过拟合),判断算法是偏差还是方差有问题对于改进学习算法的效果非常重要。通常会通过将训练集和交叉验证集的代价函数误差与多项式的次数进行绘制:

通过上图可以看出,当 d d d很小时,模型欠拟合(高偏差),此时训练集和验证集的误差都比较大,且二者数值相近;当 d d d较大时,模型过拟合(高方差),训练集的误差较小但是验证集的误差较大
1.5 正则化和偏差/方差
在训练模型时一般会使用一些正则化方法来防止过拟合,但是 λ \lambda λ值过大或者过小会使得正则化的程度太大(高偏差,欠拟合)或太小(高方差,过拟合):
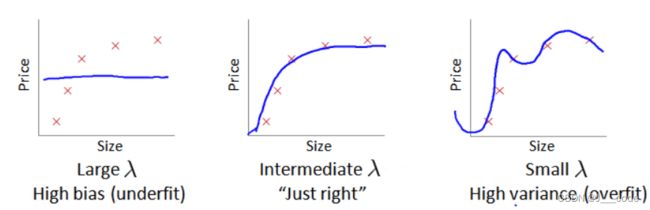
在选择 λ \lambda λ值时,通常是 0 − 10 0-10 0−10之间的呈现2倍关系的值,如 0 , 0.01 , 0.02 , . . . 5.12 , 10 0,0.01,0.02,...5.12,10 0,0.01,0.02,...5.12,10,选择 λ \lambda λ值的过程分为以下步骤:
- 使用训练集训练出不同程度正则化的模型的训练误差(带正则项)
- 用这些模型分别对交叉验证集计算出交叉验证误差(带正则项)
- 选择交叉验证误差最小的模型
- 将选出模型对测试集计算测试误差,可以同时将训练集和交叉验证集模型的代价函数误差与 λ \lambda λ值的关系绘制在图表上(此时的代价函数是不带正则项的,只是为了说明二者关系):
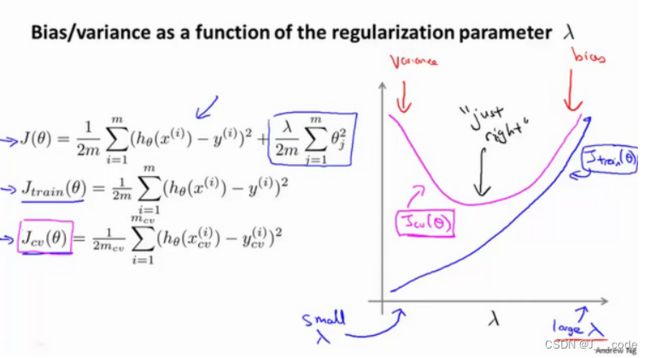
1.6 学习曲线
下图为训练集大小和训练/验证误差的关系,当训练集较小时,模型很容易拟合数据;当数据集增加时,拟合的难度就增加,自然训练误差就变大,但是泛化效果也越好,意味着验证误差减小:
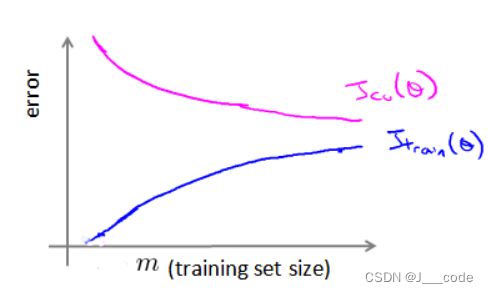
上图便是学习曲线,该曲线用于判断某个学习算法是否处于偏差或方差问题:
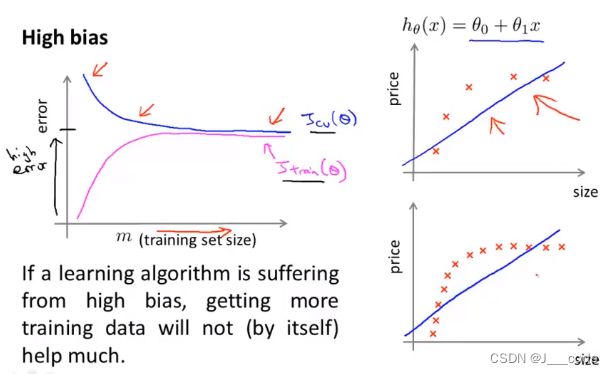
- 处于高偏差时(即模型容量小,如下面图中 h θ ( x ) = θ 0 + θ 1 x h_\theta(x)=\theta_0+\theta_1x hθ(x)=θ0+θ1x),即使训练样本数目增加,最终训练集和验证集的误差也较大且后续变化很小(因为始终采用的是图中直线去拟合数据)
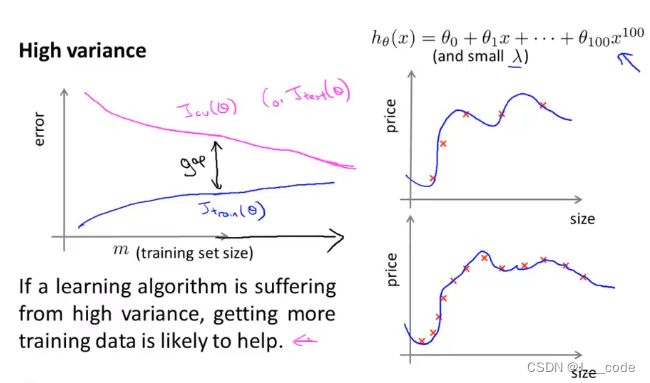
- 处于高方差时(即模型容量小,如下面图中 h θ ( x ) = θ 0 + θ 1 x + . . . + θ 100 x 100 h_\theta(x)=\theta_0+\theta_1x+...+\theta_{100}x^{100} hθ(x)=θ0+θ1x+...+θ100x100),当训练样本数较小时,训练集和验证集的误差相差较大,但是随着样本数的增加,二者间距逐渐减小并且验证集的误差在不断减小,所以增加训练集大小是有效的(即使用更多的数据后泛化能力提升了)
1.7 决定下一步做什么
- 获得更多的训练样本——解决高方差(过拟合)
- 尝试减少特征的数量——解决高方差(过拟合)
- 尝试获得更多的特征——解决高偏差(欠拟合)
- 尝试增加多项式特征——解决高偏差(欠拟合)
- 尝试减少正则化程度λ——解决高偏差(欠拟合)
- 尝试增加正则化程度λ——解决高方差(过拟合)
2.参考
https://www.bilibili.com/video/BV164411b7dx?p=58-64
http://www.ai-start.com/ml2014/html/week6.html