Lesson 16.14&16.15 GoogLeNet:思想与具体框架&GoogLeNet复现
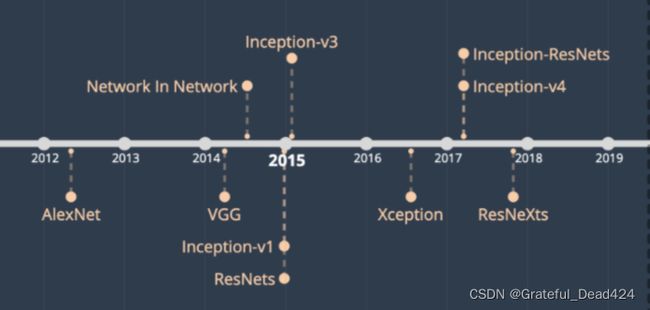
在深度学习的领域,最前沿、最先进的架构被称为state-of-the-art models,简写为SOTA,我将其翻译为“前沿网络”。每个学者都希望自己论文中的模型是SOTA model,也有不少人声称自己的工作成功达到了SOTA level,甚至为了达到SOTA level对数据进行一些微妙的操作,但真正能够进入人们的视野、并被广泛认可为优质架构的架构其实只是凤毛麟角。我们之前提到的VGG可以算是准SOTA level的架构,也是所有接近或达到SOTA level的架构中唯一一个只使用普通卷积层的架构,可以说是将思路的简洁性发挥到了极致。当然,简单的思路也导致VGG的参数量过于巨大,在VGG诞生的同时,学者们本着“网络更深、参数更少”的基本思路,创造了众多优质架构和模型,我们将在本节中仔细介绍他们。
1 GoogLeNet(Inception V1)
1.1 动机与思路
VGG非常优秀,但它在ILSVRC上拿到的最高名次是亚军,在VGG登场的2014年,力压群雄拿到冠军的是在ImageNet数据集上达到6.7%错误率的GoogLeNet。GoogLeNet由谷歌团队与众多大学合作研发,发表于论文《Going deeper with convolutions》,整篇论文语言精练简单,从标题到内容都彰显着谷歌团队加深卷积网络结构的决心,读起来非常有趣。受到NiN网络的启发,谷歌引入了一种全新的网络架构:Inception block,并将使用Inception V1的网络架构称为GoogLeNet(虽然从名字上来看致敬了LeNet5算法,但GoogLeNet已经基本看不出LeNet那种经典的卷积+池化+全连接的结构了)。
Inception直译是“起始时间”,也是电影《盗梦空间》的英文名称。或许谷歌团队是无心插柳,但Inception块的出现成为了深度视觉发展历史上的一个新的起点。从2014年的竞赛结果来看,Inception V1的效果只比VGG19好一点点(只比VGG降低了0.6%的错误率),两个架构在深度上也没有差太多,但在之后的研究中,Inception展现出比VGG强大许多的潜力——不仅需要的参数量少很多,架构可以达到的上限也更高。随着架构的迭代更新,Inception V3和V4已经是典型的SOTA模型,可以在ImageNet数据集上达到3%的错误率,但VGG在ILSVRC上的表现基本就是模型的极限了。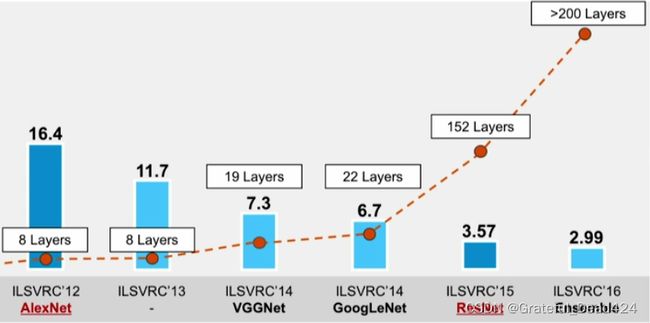
接下来,让我们来认识一下GoogLeNet和Inception V1。GoogLeNet在设计之初就采用了一种与传统CNN完全不同的构建思路。自从LeNet5定下了卷积、池化、线性层串联的基本基调,研究者们在相当长的一段时间内都在这条道路上探索,最终抵达的终点就是VGG。VGG找出了能够最大程度加大模型深度、增强模型学习能力的架构,并且利用巧妙的参数设计让特征图的尺寸得以控制,但VGG以及其他串联架构的缺点也是显而易见的,最关键的(甚至有些老生常谈的)一点就是参数过多,各层之间的链接过于“稠密”(Dense),计算量过大,并且很容易过拟合。为了解决这个问题,我们之前已经提出了多种方法,其中最主流的是:
1、使用我们在上一节中提出的分组卷积、舍弃全连接层等用来消减参数量的操作,让神经元与神经元之间、或特征图与特征图之间的连接数变少,从而让网络整体变得“稀疏”
2、引入随机的稀疏性。例如,使用类似于Dropout的方式来随机地让特征矩阵或权重矩阵中的部分数据为0
3、引入GPU进行计算
在2014年之前,以上操作就是我们目前为止接触的所有架构在减少参数量、防止过拟合上做出的努力。其中NiN主要使用方法1,AlexNet和VGG主要使用方法2和3,但这些方法其实都存在一定的问题:
首先,分组卷积等操作虽然能够有效减少参数量,却也会让架构的学习水平变得不稳定。在神经网络由稠密变得稀疏(Sparse)的过程中,网络的学习能力会波动甚至会下降,并且网络的稀疏性与学习能力之间的下降关系是不明确的,即我们无法精确控制稀疏的程度来把握网络的学习能力,只能靠孜孜不倦的尝试来测试学习能力较强的架构。
其次,随机的稀疏性与GPU计算之间其实是存在巨大矛盾的。现代硬件不擅长处理在随机或非均匀稀疏的数据上的计算,并且这种不擅长在矩阵计算上表现得尤其明显。这与现代硬件查找、缓存的具体流程有关,当数据表现含有不均匀的稀疏性时(即数据中0的分布不太均匀时),即便实际需要的计算量是原来的1/100,也无法弥补数据查找(finds)和缓存缺失(cache misses)所带来的时间延迟。简单来说,GPU擅长的是简单大量的计算操作,不同计算之间的相似性越高,GPU的计算性能就越能发挥出来,这种“相似性”表现在数据的分布相似(例如,都是偏态分布)、计算方式相似(例如,都是先相乘再相加)等方方面面。卷积操作本来就是一种涉及到大量矩阵运算的计算方式,当随机的稀疏性被放入权重矩阵或特征矩阵当中,每次计算时的数据分布都会迥然不同,这会严重拉长权重或特征相关计算所需要的时间。
相对的,稠密的连接却可以以更快的速度被计算。这并不是说稀疏的网络整体计算时间会更长,而是说在相同参数量/连接数下,稠密的结构比稀疏的结构计算更快。
此时就需要权衡了——稠密结构的学习能力更强,但会因为参数量过于巨大而难以训练。稀疏结构的参数量少,但是学习能力会变得不稳定,并且不能很好地利用现有计算资源。在2013年的时候,按分布让权重为0的Dropout刚刚诞生(2012年发表论文),在每层输出之后调整数据分布的Batch Normlization还没有诞生(2015年发表论文),创造VGG架构的团队选择了传统道路,即在学习能力更强的稠密架构上增加Dropout,但GoogLeNet团队的思路是:使用普通卷积、池化层这些稠密元素组成的块去无限逼近(approximate)一个稀疏架构,从而构造一种参数量与稀疏网络相似的稠密网络。这种思路的核心不是通过减少连接、减少扫描次数等“制造空隙”的方式来降低稠密网络的参数量,而是直接在架构设计上找出一种参数量非常少的稠密网络。
在数学中,我们常常使用稀疏的方式去逼近稠密的结构(这种操作叫做稀疏估计 sparse
approximation),但反过来用稠密结构去近似稀疏架构的情况却几乎没有,因此能否真正实现这种“逼近”是不得而知的,不过这种奇思妙想正是谷歌作为一个科技公司能够持续繁荣的根基之一。在GoogLeNet的论文中,作者们表示,在拓扑学中,几何图形或空间在连续改变形状后还能保持性状不变,这说明不同的结构可以提供相似的属性。同时,也有论文表示,稀疏数据可以被聚类成携带高度相似信息的密集数据来加速硬件计算,考虑到神经元和特征图的本质其实都是数据的组合,那稀疏的神经元应该也可以被聚类成携带高度相似信息的密集神经元,如果神经元可以被聚类,那这很可能说明稀疏架构在一定程度上应该可以被稠密架构所替代。虽然从数学上很难证明这种替代是否真的能“严格等价”,但从直觉上来说是可以说得通的。不得不说,比起之前诞生的传统网络,GoogLeNet的这个思路切入点是在大气层。
基于这样的基本理念,GoogLeNet团队使用了一个复杂的网络架构构造算法,并让算法向着“使用稠密成分逼近稀疏架构”的方向进行训练,产出了数个可能有效的密集架构。在进行了大量的实验后,他们选出了学习能力最强的密集架构及其相关参数,这个架构就是Inception块和GoogLeNet。鉴于Inception块诞生的过程,我们很难以个人身份对GoogLeNet进行“改变卷积核尺寸”或“改变输出特征图数量”这个层面的调参。基于架构构造算法以及大量的实验,其架构的精妙程度已经远远超出个人可以对卷积神经网络做的任何操作,因此也不再需要更多的调参了。
1.2 InceptionV1
我们来看Inception V1的具体结构。与之前VGG和AlexNet中从上向下串联卷积层的方式不同,Inception块使用了卷积层、池化层并联的方式。在一个Inception块中存在4条线路,每条线路可以被叫做一个分枝(branch):第一条线路上只有一个1x1卷积层,只负责降低通道数;第二条路线由一个1x1卷积层和一个3x3卷积层组成,本质上是希望使用3x3卷积核进行特征提取,但先使用1x1卷积核降低通道数以此来降低参数量和计算量(降低模型的复杂度);第三条线路由一个1x1卷积层和一个5x5卷积层组成,其基本思路与第二条线路一致;最后一条线路由一个3x3池化层和一个1x1卷积层组成,将池化也当做一种特征提取的方式,并在池化后使用1x1卷积层来降低通道数。不难注意到,所有的线路都使用了巧妙的参数组合,让特征图的尺寸保持不变,因此在四条线路分别输出结果之后,Inception块将四种方式生成的特征图拼接在一起,形成一组完整的特征图,这组完整的特征图与普通卷积生成的特征图在结构、计算方式上并无区别,因此可以被轻松地输入任意卷积、池化或全连接的结构。在论文中,GoogLeNet自然是使用了224x224的ImageNet数据集,不过在下面的架构图中我们使用了尺寸较小的特征图进行表示。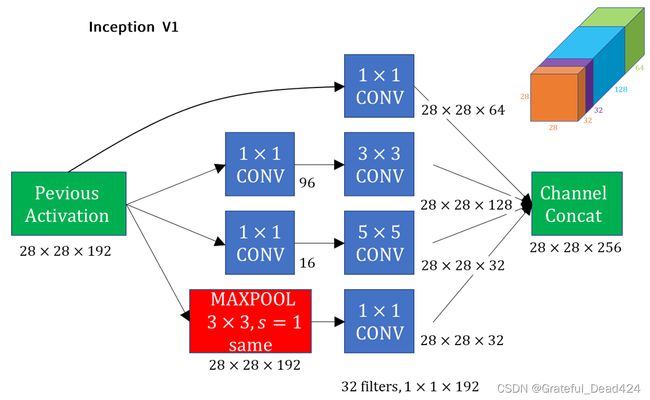
虽然我们不知道谷歌使用的网络架构构造算法具体是如何得出Inception架构的,但这种架构的优势是显而易见的:
首先,同时使用多种卷积核可以确保各种类型和层次的信息都被提取出来。在普通的卷积网络中,我们必须选择不同尺寸的过滤器(卷积核、池化核)对图像进行特征提取。1x1卷积核可以最大程度提取像素与像素之间的位置信息,尺寸较大的卷积核则更多可以提取相邻像素之间的联系信息,最大池化层则可以提取出局部中最关键的信息,但在串联结构中,对同一张图片/特征图,我们只能选择一个过滤器来使用,这意味着我们很可能会损失其他过滤器可以提取出的信息。而在Inception中,我们一次性使用了全部可能的方式,因此无需再去考虑究竟哪一种提取方式才是最好的,在输出的时候,Inception将所有核提取出来的特征图堆积整合,确保提取出的信息是最全面的。
其次,并联的卷积池化层计算效率更高。串联的卷积计算必须一层一层进行,但并联的卷积/池化层可以同时进行计算,这种将特征提取的过程并行处理的方式可以极速加快计算的运行效率。同时,由于每个元素之间都是稠密连接,并不存在任何类似于分组卷积那样减少连接数量的操作,使得inception可以高效利用现有硬件在稠密矩阵上的计算性能。
大量使用1x1卷积层来整合信息,既实现了“聚类信息”又实现了大规模降低参数量,让特征图数量实现了前所未有的增长。出现在每一条线路的1x1卷积层承担了调整特征图数目的作用,它可以自由将特征图上的信息聚合为更少的特征图,让特征图信息之间的聚合更加“密集”。同时,每个1x1卷积核之后都跟着ReLU激活函数,这增加了一次使用非线性方式处理数据的机会,某种程度上也是增加了网络的“深度”。除此之外,1x1卷积层最重要的作用是控制住了整体的参数量,从而解放了特征图的数量。这一点可以从VGG和GoogLeNet整体架构的参数量上轻松看出来。
下面分别展示了VGG16的架构和GoogLeNet的完整架构。不难发现,在VGG中,当特征图的尺寸是14x14,输入特征图数量是512,输出特征图数量也是512时,一个卷积层的参数量大约是230万。而在GoogLeNet中,相同特征图尺寸、相同输入与输出特征图数量下的inception的参数量大约是45万上下,普通卷积层的1/5还少。考虑到inception中使用了5x5卷积核,而VGG中一直都是3x3卷积核,这种参数差异是不可思议的。巨大的参数量让VGG中可以使用的最大特征图数量是512,但在GoogLeNet中这个数量却达到了1024,并且还有数个输出832个特征图的inception块。这些差异毫无疑问都是使用1x1卷积核带来的。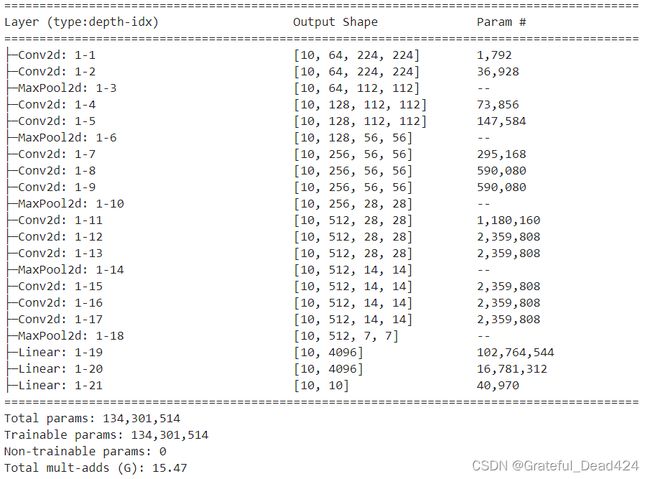
(上图,VGG16架构;下图,GoogLeNet主体架构)
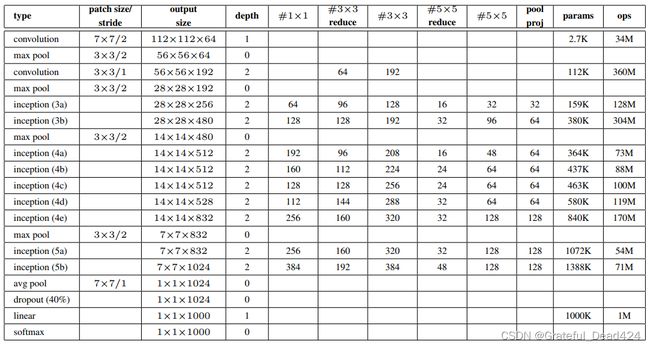
上图是GoogLeNet的主体架构。Inception内部是稠密部件的并联,而整个GoogLeNet则是数个Inception块与传统卷积结构的串联。这张架构图来自GoogLeNet的原始论文,其中patch_size就是过滤器的尺寸,3x3 reduce和5x5 reduce就是指inception块中3x3和5x5卷积层之前的1x1卷积层的输出量,pool proj中写的数字实际上是池化层后的1x1卷积层的输出量。与其他架构图相似,虽然没有被展示出来,但在每一个卷积层之后都有ReLU激活函数;同样的,从输出层的特征图尺寸来看,应该有不少卷积层中都含有padding,但无论在论文或架构中都没有被展示出来。当我们来查看GoogLeNet的架构图时,可能很容易就注意到以下几点:
1、在inception的前面有着几个传统的卷积层,并且第一个卷积层采用了和LeNet相似的处理方法:先利用较大的卷积核大幅消减特征图的尺寸,当特征图尺寸下降到28x28后再使用inception进行处理。如果将卷积+池化看做一个block(块),那inception之前已有两个blocks了,所以Inception的编号是从3开始。其中,block3、4、和5分别有2个、5个、2个Inception。
2、Inception中虽然已经包含池化层,但inception之后还是有用来让特征图尺寸减半的池化层,并且和VGG一样,让特征图尺寸减半的池化层也是5个,最终将特征图尺寸缩小为7x7。不难发现,在GoogLeNet的主体架构中,Inception实际上取代了传统架构中卷积层的地位,不过inception中有2层卷积层,因此网络总体有22层,比VGG19多了三层。
3、在架构的最后,使用了核尺寸为7x7的平均池化层。考虑到此时的特征图尺寸已经是7x7,这个池化层实际上一个用来替代全连接层的全局平均池化层,这和NiN中的操作一样。在全局平均池化层的最后,又跟上了一个线性层,用于输出softmax的结果。如果将inception看做卷积层,那GoogLeNet的主体架构也不是标新立异的类型。不过,除了主体架构之外,GoogLeNet还使用了“辅助分类器”(auxiliary classifier)以提升模型的性能。辅助分类器是除了主体架构中的softmax分类器之外,另外存在的两个分类器。在整体架构中,这两个分类器的输入分别是inception4a和inception4d的输出结果,他们的结构如下: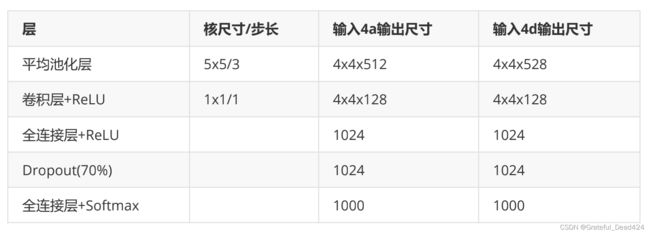
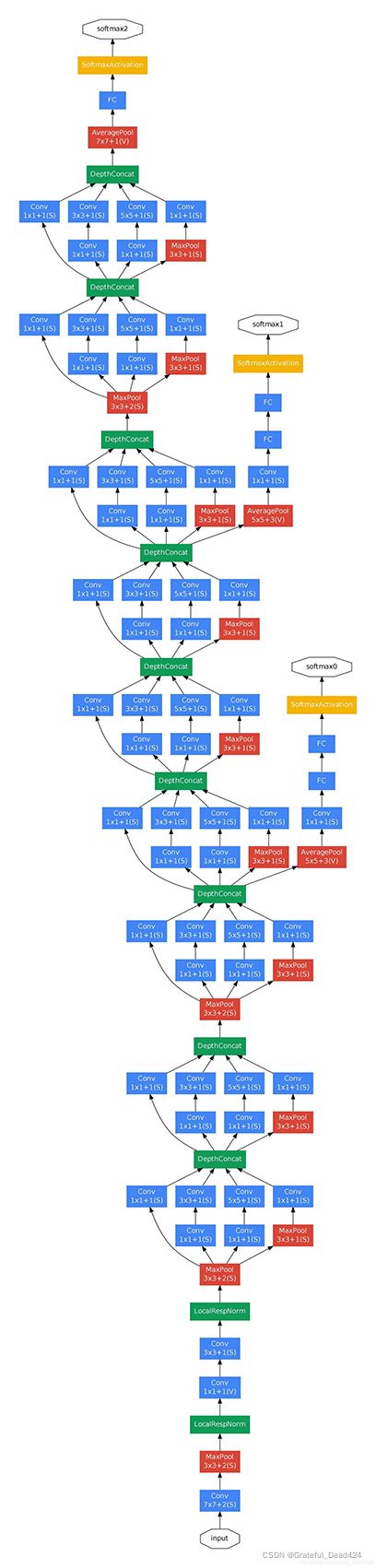
将主体架构与辅助分类器结合,我们可以得到GoogLeNet的完整架构(见下图,该架构同样来自于原始论文,注意该架构下方是输入,上方是输出)。如果架构图不足够清晰,可以看附件中的单独的图片文件。
在谷歌团队测试GoogLeNet网络性能的实验中,他们注意到稍微浅一些的GoogLeNet也有非常好的表现,因此他们认为位于中层的inception输出的特征应该对分类结果至关重要,如果能够在迭代中加重这些中层inception输出的特征的权重,就可能将模型引导向更好的反向。因此,他们将位于中间的inceptions的结果使用辅助分类器导出,并让两个辅助分类器和最终的分类器一共输出三个softmax结果、依次计算三个损失函数的值,并将三个损失加权平均得到最终的损失。如此,只要基于最终的损失进行反向传播,就可以加重在训练过程中中层inceptions输出结果的权重了。这种思想有点类似于传统机器学习算法中的“集成”思想,一个GoogLeNet实际上集成了两个浅层网络和一个深层网络的结果来进行学习和判断,在一个架构中间增加集成的思想,不得不说GoogLeNet的一大亮点。
值得一提的是,在论文的架构图中包含了一种叫做局部响应归一化(Local Response Normalization,LRN)的功能,这个功能最初是在AlexNet的架构中被使用,但我们从来没有说明过它的细节。主要是因为LRN是一个饱受争议、又对模型效果提升没有太多作用的功能,现在已基本被BN所替代(使用BN的inception被称为Inception V2)。同时,GoogLeNet的论文中也并没有给出LRN的具体细节,因此现在实现GoogLeNet的各个深度学习框架也基本上不考虑LRN的存在了。相对的,我们把所有的LRN层删掉后,在每个卷积层的后面加上了BN层,以确保更好的拟合效果。
1.3 GoogLeNet的复现
现在,我们来实现一下这个完整架构。GoogLeNet是我们遇见的第一个串联元素中含有更多复杂成分的网络,因此我们需要先单独定义几个单独的元素,之后才能够使用我们熟悉的建立类的方式来复现架构。首先,能够在主体网络中省略掉所有的激活函数,我们需要定义新的基础卷积层。这个卷积层是包含激活函数以及BN层的卷积层。这样定义能够帮助我们大幅度减少最后在整合好的GoogLeNet中会出现的ReLU函数以及BN层。
import torch
from torch import nn
from torchinfo import summary
class BasicConv2d(nn.Module):
def __init__(self,in_channels, out_channels,**kwargs):
super().__init__()
self.conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
,nn.BatchNorm2d(out_channels)
,nn.ReLU(inplace=True))
def forward(self,x):
x = self.conv(x)
return x
BasicConv2d(2,10,kernel_size=3)
#BasicConv2d(
# (conv): Sequential(
# (0): Conv2d(2, 10, kernel_size=(3, 3), stride=(1, 1), bias=False)
# (1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (2): ReLU(inplace=True)
# )
#)
接下来,我们需要定义Inception块。由于Inception块中是并联的结构,存在4个branchs,所以我们不能使用nn.Sequential进行打包,而是要使用原始的self.的形式。在Inception块中,所有卷积、池化层的输入、输出以及核大小都需要我们进行输入,因此我们可以使用原论文中架构图上的英文作为参数的名称,如此,在填写架构中具体的数字时,我们只需要照着架构图一行一行填就可以了。
class Inception(nn.Module):
def __init__(self
,in_channels : int
,ch1x1 : int
,ch3x3red : int
,ch3x3 : int
,ch5x5red : int
,ch5x5 : int
,pool_proj : int
):
super().__init__()
#1x1
self.branch1 = BasicConv2d(in_channels,ch1x1,kernel_size=1)
#1x1 + 3x3
self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1)
,BasicConv2d(ch3x3red, ch3x3, kernel_size=3,padding=1))
#1x1 + 5x5
self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch5x5red, kernel_size=1)
,BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2))
#pool + 1x1
self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3,stride=1, padding=1,ceil_mode=True)
,BasicConv2d(in_channels,pool_proj,kernel_size=1))
def forward(self,x):
branch1 = self.branch1(x) #28x28,ch1x1
branch2 = self.branch2(x) #28x28,ch3x3
branch3 = self.branch3(x) #28x28,ch5x5
branch4 = self.branch4(x) #28x28,pool_proj
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1) #合并
#测试
'''
in_channels : int
,ch1x1 : int
,ch3x3red : int
,ch3x3 : int
,ch5x5red : int
,ch5x5 : int
,pool_proj : int
'''
in3a = Inception(192,64,96,128,16,32,32)
data = torch.ones(10,192,28,28)
in3a(data).shape
#torch.Size([10, 256, 28, 28])
接下来,还需要单独定义的是辅助分类器(Auxiliary Classifier)的类。辅助分类器的结构其实与我们之前所写的传统卷积网络很相似,因此我们可以使用nn.Sequential来进行打包,并将分类器分成.features_和.clf_两部分来进行构建:
class AuxClf(nn.Module):
def __init__(self,in_channels : int, num_classes : int, **kwargs):
super().__init__()
self.feature_ = nn.Sequential(nn.AvgPool2d(kernel_size=5,stride=3)
,BasicConv2d(in_channels,128, kernel_size=1))
self.clf_ = nn.Sequential(nn.Linear(4*4*128, 1024)
,nn.ReLU(inplace=True)
,nn.Dropout(0.7)
,nn.Linear(1024,num_classes))
def forward(self,x):
x = self.feature_(x)
x = x.view(-1,4*4*128)
x = self.clf_(x)
return x
#4a后的辅助分类器
AuxClf(512,1000)
#AuxClf(
# (feature_): Sequential(
# (0): AvgPool2d(kernel_size=5, stride=3, padding=0)
# (1): BasicConv2d(
# (conv): Sequential(
# (0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
# (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (2): ReLU(inplace=True)
# )
# )
# )
# (clf_): Sequential(
# (0): Linear(in_features=2048, out_features=1024, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.7, inplace=False)
# (3): Linear(in_features=1024, out_features=1000, bias=True)
# )
#)
在定义好三个单独的类后,我们再依据GoogLeNet的完整架构将所有内容实现。虽然GoogLeNet的主体结构是串联,但由于存在辅助分类器,我们无法在使用nn.Sequential时单独将辅助分类器的结果提取出来。如果按照辅助分类器存在的地方对架构进行划分,又会导致架构整体在层次上与GoogLeNet的架构图有较大的区别,因此我们最终还是使用了self.的形式。在我们自己使用GoogLeNet时,我们不一定总要使用辅助分类器。如果不使用辅助分类器,我们则可以使用nn.Sequential来打包整个代码。包含辅助分类器的具体代码如下:
#(224 + 6 - 7)/2 + 1 = 112.5 自动向下取整数
#pool (112 - 3)/2 + 1 = 55.5 向上取整(需要调节ceil_mode)之后得到56
class GoogLeNet(nn.Module):
def __init__(self,num_classes: int = 1000, blocks = None):
super().__init__()
if blocks is None:
blocks = [BasicConv2d, Inception, AuxClf]
conv_block = blocks[0]
inception_block = blocks[1]
aux_clf_block = blocks[2]
#block1
self.conv1 = conv_block(3,64,kernel_size=7,stride=2,padding = 3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3,stride=2,ceil_mode = True)
#block2
self.conv2 = conv_block(64,64,kernel_size=1)
self.conv3 = conv_block(64,192,kernel_size=3, padding = 1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3,stride=2,ceil_mode = True)
#block3
self.inception3a = inception_block(192,64,96,128,16,32,32)
self.inception3b = inception_block(256,128,128,192,32,96,64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3,stride=2,ceil_mode = True)
#block4
self.inception4a = inception_block(480,192,96,208,16,48,64)
self.inception4b = inception_block(512,160,112,224,24,64,64)
self.inception4c = inception_block(512,128,128,256,24,64,64)
self.inception4d = inception_block(512,112,144,288,32,64,64)
self.inception4e = inception_block(528,256,150,320,32,128,128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3,stride=2,ceil_mode = True)
#block5
self.inception5a = inception_block(832,256,160,320,32,128,128)
self.inception5b = inception_block(832,384,192,384,48,128,128)
#clf
self.avgpool = nn.AdaptiveAvgPool2d((1,1)) #我需要的输出的特征图尺寸是多少
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024,num_classes)
#auxclf
self.aux1 = aux_clf_block(512, num_classes) #4a
self.aux2 = aux_clf_block(528, num_classes) #4d
def forward(self,x):
#block1
x = self.maxpool1(self.conv1(x))
#block2
x = self.maxpool2(self.conv3(self.conv2(x)))
#block3
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
#block4
x = self.inception4a(x)
aux1 = self.aux1(x)
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
aux2 = self.aux2(x)
x = self.inception4e(x)
x = self.maxpool4(x)
#block5
x = self.inception5a(x)
x = self.inception5b(x)
#clf
x = self.avgpool(x) #在这个全局平均池化之后,特征图尺寸就变成了1x1
x = torch.flatten(x,1)
x = self.dropout(x)
x = self.fc(x)
return x, aux2, aux1
运行不报错,则说明我们的架构建立成功了。使用Summary查看最后的结果,可以看到一个长得不可思议的层次结构。这个层次结构中至少有三层,最内部的是普通卷积层构成的分枝branch,然后是inception块,然后是inception块和其他结构组成的blocks。在这种情况下,依赖于Summary来查看架构层次已经是不太可能的事儿了,因此我们可以使用summary函数自带的参数depth来调整显示层次的深度:
summary(net,(10,3,224,224),device="cpu",depth=1)
#测试
data = torch.ones(10,3,224,224)
net = GoogLeNet(num_classes=1000)
fc2, fc1, fc0 = net(data)
for i in [fc2, fc1, fc0]:
print(i.shape)
#torch.Size([10, 1000])
#torch.Size([10, 1000])
#torch.Size([10, 1000])
summary(net,(10,3,224,224),device="cpu",depth=1)
#==========================================================================================
#Layer (type:depth-idx) Output Shape Param #
#==========================================================================================
#├─BasicConv2d: 1-1 [10, 64, 112, 112] 9,536
#├─MaxPool2d: 1-2 [10, 64, 56, 56] --
#├─BasicConv2d: 1-3 [10, 64, 56, 56] 4,224
#├─BasicConv2d: 1-4 [10, 192, 56, 56] 110,976
#├─MaxPool2d: 1-5 [10, 192, 28, 28] --
#├─Inception: 1-6 [10, 256, 28, 28] 164,064
#├─Inception: 1-7 [10, 480, 28, 28] 389,376
#├─MaxPool2d: 1-8 [10, 480, 14, 14] --
#├─Inception: 1-9 [10, 512, 14, 14] 376,800
#├─AuxClf: 1-10 [10, 1000] 3,188,968
#├─Inception: 1-11 [10, 512, 14, 14] 449,808
#├─Inception: 1-12 [10, 512, 14, 14] 510,768
#├─Inception: 1-13 [10, 528, 14, 14] 606,080
#├─AuxClf: 1-14 [10, 1000] 3,191,016
#├─Inception: 1-15 [10, 832, 14, 14] 835,276
#├─MaxPool2d: 1-16 [10, 832, 7, 7] --
#├─Inception: 1-17 [10, 832, 7, 7] 1,044,480
#├─Inception: 1-18 [10, 1024, 7, 7] 1,445,344
#├─AdaptiveAvgPool2d: 1-19 [10, 1024, 1, 1] --
#├─Dropout: 1-20 [10, 1024] --
#├─Linear: 1-21 [10, 1000] 1,025,000
#==========================================================================================
#Total params: 13,351,716
#Trainable params: 13,351,716
#Non-trainable params: 0
#Total mult-adds (G): 184.06
#==========================================================================================
#Input size (MB): 6.02
#Forward/backward pass size (MB): 0.08
#Params size (MB): 53.41
#Estimated Total Size (MB): 59.51
#==========================================================================================
这样架构就清晰多了。虽然架构复杂,但这个网络实际只有22层卷积层,加上池化层只有27层,和几百层的网络们比起来不算什么。并且,GoogLeNet只有1300万参数量(并且从summary的结果可以看出,其中700万参数都是由分类器上的全连接层带来的,如果不使用辅助分类器,则GoogLeNet的参数量大约只有600万左右),而16层的VGG的参数量是1.3亿,两者参数相差超过10倍。从计算量来看,GoogLeNet也全面碾压了VGG本身。如下图所示,GoogLeNet所需的总计算量不足一个G,而VGG却需要15个G。在2014年的ILSVRC上,GoogLeNet只以微小的优势打败了VGG19,但其计算效率以及在架构上带来的革新是VGG19无法替代的。
(上图为GoogLeNet参数量及计算量,下图为VGG16参数量及计算量)

GoogLeNet的架构完美地展现了谷歌团队在设计inception时所忠于的逻辑:使用密集的成分去接近稀疏的架构,不仅能够像稀疏架构一样参数很少,还能够充分利用密集成分在现代硬件上的计算效率。在2014年之后,谷歌团队数次改进了Inception块和GoogLeNet整体的排布。今天,这一族最强大的是InceptionV3。在经过适当训练之后,Inception V3可以在ImageNet2012年数据集上拿到4.2%的错误率,我们自己手写的一个普通的V3模型也能够在ImageNet数据集上拿到6.5%的错误率,是现在视觉届仅次于深层残差网络(100层以上)的架构。