手工简单复现经典CNN网络测试(LeNet5、AlexNet、VGG16、GoogLeNet、ResNe)
手工简单复现经典CNN网络测试
**前言:**突然想把看到的机器视觉的经典网络(LeNet5、AlexNet、VGG16、GoogLeNet、ResNet)手工复现一遍,运气好的可以看到效果时逐渐趋于完美的,但现实是残酷的,这里把遇到的问题和部分结果记录以下(真心认为解决问题的过程就是成长的过程)
1、导入相关包
import torchvision
from torchvision.datasets import FashionMNIST
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.nn import CrossEntropyLoss
from torch.optim import SGD
from torch.utils.data import DataLoader
from torchinfo import summary
from sklearn.model_selection import train_test_split
2、导入图像数据集
# 加载Fashion-MNIST图像数据集
datasets_train = FashionMNIST(root=r"./MINST-FASHION数据集"
,train=True
,transform=torchvision.transforms.ToTensor()
,target_transform=None)
datasets_test = FashionMNIST(root=r"./MINST-FASHION数据集"
,train=False
,transform=None
,target_transform=torchvision.transforms.ToTensor())
datasets_train.data.shape
datasets_test.data.shape
datasets_test.targets
'''
torch.Size([60000, 28, 28])
torch.Size([10000, 28, 28])
tensor([9, 2, 1, ..., 8, 1, 5])
'''
# 形成fashion-mnist批数据
dataloader = DataLoader(dataset=datasets_train, batch_size=5000, shuffle=True)
for i in dataloader:
print(i[0].shape, i[1])
break
#-------------------------------------------------------------------------------
## 第一个小问题
# Fashion-MNIST数据集尺寸(28*28)太小,支撑不了像alexnet、vgg这样深层的网络,so从网上下载了水果数据集,并将图片尺寸缩放至227*227
# ------------------------------------------------------------------------------
transform = transforms.Compose([transforms.Resize(size=(227,227))
,transforms.ToTensor()])
data = torchvision.datasets.ImageFolder(root=r"./fruit" # 图像数据集根目录,里面包含各种类型图片的文件夹
,transform=transform)
# 拆分训练和测试集(其实这一步,最好使用os模块提前把图片文件各文件夹,拆分成训练集和测试集,直接使用torchvision读取完,再拆分像下面展示,太过麻烦,而且太费CPU)
x,y = [i[0].tolist() for i in data],[i[1] for i in data]
X_train, X_test, y_train, y_test = train_test_split(x,y,test_size=0.2,shuffle=True,random_state=240)
X_train, X_test, y_train, y_test = (torch.tensor(X_train,dtype=torch.float32), torch.tensor(X_test,dtype=torch.float32),torch.tensor(y_train,dtype=torch.long), torch.tensor(y_test,dtype=torch.long))
X_train.shape
X_test.shape
y_train.shape
y_test.shape
'''
torch.Size([1615, 3, 227, 227])
torch.Size([404, 3, 227, 227])
torch.Size([1615])
torch.Size([404])
'''
3、数据集展示
# 展示Fashion-MNIST数据集(10分类)
fig,ax = plt.subplots(2,5)
fig.set_size_inches(w=18,h=8)
plt.subplots_adjust(wspace=0.1,hspace=0)
for i in range(10):
if i <= 4:
ax[0,i].imshow(datasets_train.data[i],cmap='YlOrRd')
ax[0,i].xaxis.set_ticks([])
ax[0,i].yaxis.set_ticks([])
else:
ax[1,i-5].imshow(datasets_train.data[i],cmap='YlOrRd')
ax[1,i-5].xaxis.set_ticks([])
ax[1,i-5].yaxis.set_ticks([])
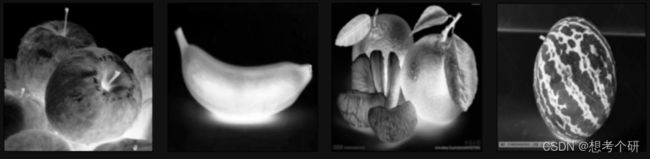
# 展示水果数据集(4分类)
# 水果数据集共2000各左右,四种类型(苹果、香蕉、橘子、西瓜) 单色通道图像如下
fig,ax = plt.subplots(1,4)
fig.set_size_inches(w=12,h=4)
plt.subplots_adjust(wspace=0.1,hspace=0)
ax[0].imshow(data[0][0][0],cmap='Greys')
ax[1].imshow(data[504][0][2],cmap='Greys')
ax[2].imshow(data[1404][0][1],cmap='Greys')
ax[3].imshow(data[2000][0][1],cmap='Greys')
for i in range(4):
ax[i].xaxis.set_ticks([]
ax[i].yaxis.set_ticks([])
Fashion-MNIST

fruit(单通道亮度显示)
4、创建网络
'''
# 第二个小问题
创建 CNN网络 网络有很多不完善的地方,
1.刚开始使用的fashion-MNIST数据集,图像尺寸太小,除了LeNet5浅层架构能使用,其他深层的网络就不适应了,这里使用从和鲸社区下载水果数据集;
2.深层网络通道数随卷积层数增加而增加,参数量个人电脑cpu和GPU内存提示超出,(Error:data. DefaultCPUAllocator: not enough memory: you tried to allocate 496334720 bytes. Buy new RAM!)
目前就只能不符合常理的压缩输出通道数了,网络宽度浅,全连接贡献参数量也尤为显著;
3.到此(网络有些畸形)、只能练习各种经典网络的架构(水果原始图像尺寸 3*227*227)了,先看效果对比,有些费劲。
'''
# 4.1 LeNet5网络 (卷积 +平均池化 --> 卷积 +平均池化 --> fc*2 激活函数 tanh)
class LeNet5(nn.Module):
def __init__(self):
super().__init__()
self.con1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=11, stride=2, padding=0) # 图像尺寸太大,大的卷积核和步长=2强行缩减特征图尺寸
self.avg1 = nn.AvgPool2d(kernel_size=2,stride=2)
self.con2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=7, stride=2, padding=0)
self.avg2 = nn.AvgPool2d(kernel_size=2,stride=2)
self.fc1 = nn.Linear(in_features=32*12*12,out_features=64,bias=True)
self.fc2 = nn.Linear(in_features=64,out_features=4,bias=True)
def forward(self, x):
x = self.avg1(torch.tanh(self.con1(x)))
x = self.avg2(torch.tanh(self.con2(x)))
x = x.reshape(-1,32*12*12)
z1 = self.fc1(x)
z2 = self.fc2(z1)
return z2
# 4.2 AlexNet网络 ((卷积 + 最大池化)*2 --> 卷积*3+最大池化 --> fc*3 激活函数 relu)
class AlexNet(nn.Module):
def __init__(self):
super().__init__()
self.con1 = nn.Conv2d(in_channels=3, out_channels=8, kernel_size=11, stride=2, padding=0)
self.maxp1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.con2 = nn.Conv2d(in_channels=8, out_channels=16, kernel_size=5, stride=1, padding=0)
self.maxp2 = nn.MaxPool2d(kernel_size=2,stride=2)
self.con3 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=0)
self.con4 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=0)
self.con5 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.maxp3 = nn.MaxPool2d(kernel_size=2,stride=2)
self.fc1 = nn.Linear(in_features=64*9*9,out_features=64,bias=True)
self.fc2 = nn.Linear(in_features=64,out_features=64,bias=True)
self.fc3 = nn.Linear(in_features=64,out_features=4,bias=True)
def forward(self, x):
x = self.maxp1(torch.relu(self.con1(x))) # 目前没有加BN层,实际应用中应该加的
x = self.maxp2(torch.relu(self.con2(x)))
x = self.maxp3(torch.relu(self.con5(torch.relu(self.con4(torch.relu(self.con3(x)))))))
x = x.reshape(-1,64*9*9)
z1 = self.fc1(x)
z2 = self.fc2(z1)
z3 = self.fc3(z2)
return z3
# 4.3 VGG16网络 ((卷积 *2+ 最大池化)*2 --> (卷积*3+最大池化)*3 --> fc*3 激活函数 relu 全连接层含dropout)
class VGG16(nn.Module):
def __init__(self):
super().__init__()
self.con1 = nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, stride=1, padding=0)
self.con2 = nn.Conv2d(in_channels=8, out_channels=8, kernel_size=3, stride=1, padding=0)
self.maxp1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.con3 = nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, stride=1, padding=0)
self.con4 = nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=0)
self.maxp2 = nn.MaxPool2d(kernel_size=2,stride=2)
self.con5 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=0)
self.con6 = nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=0)
self.con7 = nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=0)
self.maxp3 = nn.MaxPool2d(kernel_size=2,stride=2)
self.con8 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=0)
self.con9 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.con10 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.maxp4 = nn.MaxPool2d(kernel_size=2,stride=2)
self.con11 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.con12 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.con13 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.maxp5 = nn.MaxPool2d(kernel_size=2,stride=2)
self.fc14 = nn.Linear(in_features=64,out_features=128,bias=True)
self.fc15 = nn.Linear(in_features=128,out_features=128,bias=True)
self.fc16 = nn.Linear(in_features=128,out_features=4,bias=True)
# 网络太深,还是偷偷加BN层,标准化一下吧(每个重复块加一个)
self.bn1 = nn.BatchNorm2d(num_features=8)
self.bn2 = nn.BatchNorm2d(num_features=16)
self.bn3 = nn.BatchNorm2d(num_features=32)
self.bn4 = nn.BatchNorm2d(num_features=64)
self.bn5 = nn.BatchNorm2d(num_features=64)
self.dropout = nn.Dropout(p=0.5)
def forward(self, x):
x = self.maxp1(torch.relu(self.bn1(self.con2(torch.relu(self.con1(x))))))
x = self.maxp2(torch.relu(self.bn2(self.con4(torch.relu(self.con3(x))))))
x = self.maxp3(torch.relu(self.bn3(self.con7(torch.relu(self.con6(torch.relu(self.con5(x))))))))
x = self.maxp4(torch.relu(self.bn4(self.con10(torch.relu(self.con9(torch.relu(self.con8(x))))))))
x = self.maxp5(torch.relu(self.bn5(self.con13(torch.relu(self.con12(torch.relu(self.con11(x))))))))
x = x.reshape(-1,64)
z1 = self.dropout(self.fc14(x))
z2 = self.dropout(self.fc15(z1))
z3 = self.fc16(z2)
return z3
# 4.4 GoogLeNet网络架构
'''待定'''
# 4.5 ResNet 网络架构
'''有空在写'''
5、网络参数量和内存计算问题
# 第三个小问题
# 当我以为改变通道数和全连接层神经元,减少网络参数量,就能使像VGG16这样深层网络正常训练了,万事有但是,但是参数量少了,还是提示会提示内存溢出,原因在下面
# 查看网络结构,网络参数量和内存占用量,参数多内存不一定占用多
summary(LeNet5(),X_train.shape,device='cpu')
summary(AlexNet(),X_train.shape,device='cpu')
summary(VGG16(),input_size=(500,3,227,227),device='cpu')
'''
# LeNet5
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
LeNet5 -- --
├─Conv2d: 1-1 [500, 16, 109, 109] 5,824
├─AvgPool2d: 1-2 [500, 16, 54, 54] --
├─Conv2d: 1-3 [500, 32, 24, 24] 25,120
├─AvgPool2d: 1-4 [500, 32, 12, 12] --
├─Linear: 1-5 [500, 64] 294,976
├─Linear: 1-6 [500, 4] 260
==========================================================================================
Total params: 326,180
Trainable params: 326,180
Non-trainable params: 0
Total mult-adds (G): 41.98
==========================================================================================
Input size (MB): 309.17
Forward/backward pass size (MB): 834.38
Params size (MB): 1.30
Estimated Total Size (MB): 1144.86
==========================================================================================
# AleNet
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
AlexNet -- --
├─Conv2d: 1-1 [500, 8, 109, 109] 2,912
├─MaxPool2d: 1-2 [500, 8, 54, 54] --
├─Conv2d: 1-3 [500, 16, 50, 50] 3,216
├─MaxPool2d: 1-4 [500, 16, 25, 25] --
├─Conv2d: 1-5 [500, 32, 23, 23] 4,640
├─Conv2d: 1-6 [500, 64, 21, 21] 18,496
├─Conv2d: 1-7 [500, 64, 19, 19] 36,928
├─MaxPool2d: 1-8 [500, 64, 9, 9] --
├─Linear: 1-9 [500, 64] 331,840
├─Linear: 1-10 [500, 64] 4,160
├─Linear: 1-11 [500, 4] 260
==========================================================================================
Total params: 402,452
Trainable params: 402,452
Non-trainable params: 0
Total mult-adds (G): 33.46
==========================================================================================
Input size (MB): 309.17
Forward/backward pass size (MB): 813.74
Params size (MB): 1.61
Estimated Total Size (MB): 1124.53
==========================================================================================
# VGG16
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VGG16 -- --
├─Conv2d: 1-1 [500, 8, 225, 225] 224
├─Conv2d: 1-2 [500, 8, 223, 223] 584
├─BatchNorm2d: 1-3 [500, 8, 223, 223] 16
├─MaxPool2d: 1-4 [500, 8, 111, 111] --
├─Conv2d: 1-5 [500, 16, 109, 109] 1,168
├─Conv2d: 1-6 [500, 16, 107, 107] 2,320
├─BatchNorm2d: 1-7 [500, 16, 107, 107] 32
├─MaxPool2d: 1-8 [500, 16, 53, 53] --
├─Conv2d: 1-9 [500, 32, 51, 51] 4,640
├─Conv2d: 1-10 [500, 32, 49, 49] 9,248
├─Conv2d: 1-11 [500, 32, 47, 47] 9,248
├─BatchNorm2d: 1-12 [500, 32, 47, 47] 64
├─MaxPool2d: 1-13 [500, 32, 23, 23] --
├─Conv2d: 1-14 [500, 64, 21, 21] 18,496
├─Conv2d: 1-15 [500, 64, 19, 19] 36,928
├─Conv2d: 1-16 [500, 64, 17, 17] 36,928
├─BatchNorm2d: 1-17 [500, 64, 17, 17] 128
├─MaxPool2d: 1-18 [500, 64, 8, 8] --
├─Conv2d: 1-19 [500, 64, 6, 6] 36,928
├─Conv2d: 1-20 [500, 64, 4, 4] 36,928
├─Conv2d: 1-21 [500, 64, 2, 2] 36,928
├─BatchNorm2d: 1-22 [500, 64, 2, 2] 128
├─MaxPool2d: 1-23 [500, 64, 1, 1] --
├─Linear: 1-24 [500, 128] 8,320
├─Dropout: 1-25 [500, 128] --
├─Linear: 1-26 [500, 128] 16,512
├─Dropout: 1-27 [500, 128] --
├─Linear: 1-28 [500, 4] 516
==========================================================================================
Total params: 256,284
Trainable params: 256,284
Non-trainable params: 0
Total mult-adds (G): 84.89 # 参数计算量
==========================================================================================
Input size (MB): 309.17
Forward/backward pass size (MB): 8603.95
Params size (MB): 1.03
Estimated Total Size (MB): 8914.15
==========================================================================================
'''
'''
在同样数据500样本的情况下,VGG16通过无理地压缩通道数和全连接层总参数量256284,为三个网络中参数量最少,但Total Size(MB)所占内存还是最大,远超AlexNet、LeNet。
原因:Forward/backward pass size (MB) 这个所占内存太大
初步理解:输入数据经过每一次卷积的中特征图结果,也占内存(网络会存储中间结果,用于梯度计算),网络越深,中间结果所占内存越大
计算Forward/backward pass size (MB):
每一层输出数据量求和
500* 8* 225* 225
+500* 8* 223* 223
+500* 8* 223* 223
+500* 8* 111* 111
+500* 16* 109* 109
+500* 16* 107* 107
+500* 16* 107* 107
+500* 16* 53* 53
+500* 32* 51* 51
+500* 32* 49* 49
+500* 32* 47* 47
+500* 32* 47* 47
+500* 32* 23* 23
+500* 64* 21* 21
+500* 64* 19* 19
+500* 64* 17* 17
+500* 64* 17* 17
+500* 64* 8* 8
+500* 64* 6* 6
+500* 64* 4* 4
+500* 64* 2* 2
+500* 64* 2* 2
+500* 64* 1* 1
+500* 128
+500* 128
+500* 128
+500* 128
+500* 4
= 1,157,922,000 个数据
训练时,设置的类型为torch.falot32,一个数占4个字节
so: 1157922000*4/1024/1024(转化为MB) = 4,417.12MB *2(正反向传播)= 8,834.2MB(和8603.95MB差点,也有可能不是这样算的,就当个参考吧)
'''
6、训练
测试过程中,由于上诉种种原因,网络结构层次,已严重变形,
训练结果也就没必要了。
下一步尝试小批量训练,解决因网络过大,电脑内存和显存溢出问题。
参见FashionMNIST_CNN with pytorch (accuracy: 97.58%/90.1%)