Spark案例之WordCount
目录
IntelliJ IDEA
一、编写WordCount程序
1.创建一个Maven项目WordCount并导入依赖
2.编写代码
3.打包插件
4.创建数据,打包完,导入包
5.集群测试(在包的路径下输入)
hdfs的方式:
本地方式:
6.查看结果
二、远程调用Spark
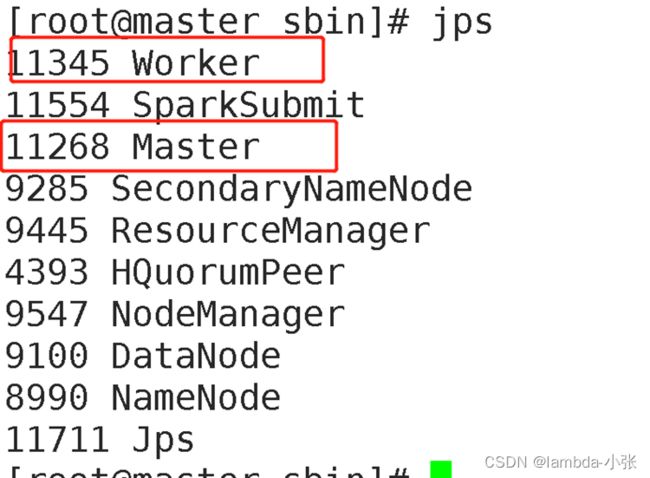
1.启动Spark下的start-all.sh
Jps查看进程:
2.导入依赖
3.编写代码
4.打包
5.在把代码加到创建sparkConf的后面
原代码
修改后,加上包的路径
6.运行输出
IntelliJ IDEA
一、编写WordCount程序
1.创建一个Maven项目WordCount并导入依赖
4.0.0
org.example
0607
1.0-SNAPSHOT
org.apache.spark
spark-core_2.11
2.1.1
WordCount
net.alchim31.maven
scala-maven-plugin
3.2.2
compile
testCompile
2.编写代码
import org.apache.spark.{SparkConf, SparkContext}
/**
* @program: IntelliJ IDEA
* @description: 编写spark版本的WordCount
* @create: 2022-06-08 11:27
*/
object WordCount {
def main(args: Array[String]): Unit = {
//1.读取配置
val sparkConf = new SparkConf().setAppName("WordCount")
//2.获取到SparkContext
val sc = new SparkContext(sparkConf)
//3.执行操作
sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _, 1).sortBy(_._2, false).saveAsTextFile(args(1))
//4.关闭连接
sc.stop()
}
}3.打包插件
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
WordCount
jar-with-dependencies
make-assembly
package
single
4.创建数据,打包完,导入包
[root@hadoop ~]# cd /usr/input
[root@hadoop input]# ls
WordCount.jar
[root@hadoop input]# vim wc.txt
java hadoop java hadoop
php hadoop scala scala
python java hive java
5.集群测试(在包的路径下输入)
hdfs的方式:
spark-submit --class WordCount --master yarn WordCount.jar hdfs://192.168.17.151:9000/wc.txt hdfs://192.168.17.151:9000/out本地方式:
spark-submit --class WordCount --master yarn WordCount.jar file:///usr/input/word.txt hdfs://192.168.17.151:9000/06086.查看结果
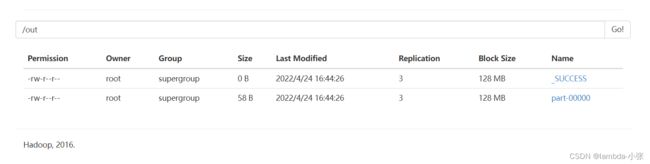
[root@hadoop input]# hdfs dfs -cat /out/part-00000
(java,4)
(hadoop,3)
(scala,2)
(hive,1)
(php,1)
(python,1)
二、远程调用Spark
1.启动Spark下的start-all.sh

Jps查看进程:
2.导入依赖
4.0.0
org.example
0607
1.0-SNAPSHOT
UTF-8
1.8
1.8
2.11.11
2.1.1
2.7.3
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_2.11
${spark.version}
org.apache.spark
spark-streaming_2.11
${spark.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.spark
spark-hive_2.11
${spark.version}
org.apache.spark
spark-hive-thriftserver_2.11
${spark.version}
org.apache.spark
spark-mllib_2.11
${spark.version}
org.apache.hadoop
hadoop-client
2.7.3
com.hankcs
hanlp
portable-1.7.7
src/main/scala
org.apache.maven.plugins
maven-compiler-plugin
3.6.0
net.alchim31.maven
scala-maven-plugin
3.2.2
compile
testCompile
-dependencyfile
${project.build.directory}/.scala_dependencies
org.apache.maven.plugins
maven-surefire-plugin
2.18.1
false
true
**/*Test.*
**/*Suite.*
org.apache.maven.plugins
maven-shade-plugin
2.3
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
3.编写代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @program: IntelliJ IDEA
* @description: ming
* @create: 2022-06-08 19:54
*/
object sparkTest {
def main(args: Array[String]): Unit = {
//1.创建sparkConf
val sparkConf = new SparkConf().setMaster("spark://192.168.17.151:7077").setAppName("WordCount")
//2.创建sparkContext
val sc = new SparkContext(sparkConf)
//3.读取数据
var rdd0:RDD[String] = sc.textFile("hdfs://192.168.17.151:9000/word.txt")
//4.拆分数据
var rdd1:RDD[String] = rdd0.flatMap(_.split(" "))
//5.map
var rdd2:RDD[(String,Int)] = rdd1.map((_,1))
//6.
var rdd3:RDD[(String,Int)] = rdd2.reduceByKey(_+_).sortBy(_._2, false)
//7.转数组
var result:Array[(String,Int)] = rdd3.collect()
//8.打印结果
result.foreach(println(_))
}
}4.打包

5.在把代码加到创建sparkConf的后面
原代码
val sparkConf = new SparkConf().setMaster("spark://192.168.17.151:7077").setAppName("WordCount")修改后,加上包的路径
val sparkConf = new SparkConf().setMaster("spark://192.168.17.151:7077").setAppName("WordCount").setJars(Seq("D:\\worksoft\\demo\\0607\\target\\0607-1.0-SNAPSHOT.jar"))