MySQL InnoDB内存结构之Buffer Pool
InnnoDB的数据都是放在磁盘上的,而磁盘的速度和CPU的速度之间有难以逾越的鸿沟,为了提升效率,就引入了缓冲池技术,在InnoDB中称之为Buffer Pool。
https://blog.csdn.net/zwx900102/article/details/106741454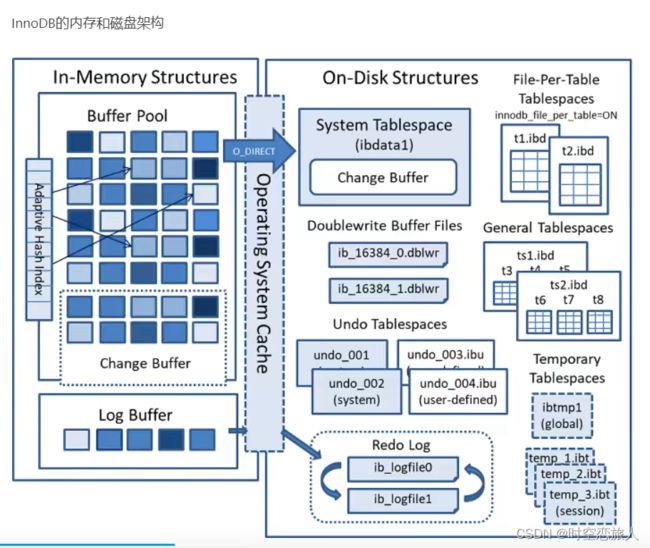
1.什么是buffer pool?
缓冲池是主内存中的一个区域,InnoDB 在访问时缓存表和索引数据。 缓冲池允许直接从内存中访问经常使用的数据,从而加快处理速度。 在专用服务器上,高达 80% 的物理内存通常分配给缓冲池。为了提高大容量读取操作的效率,缓冲池被划分为可能包含多行的页面。 为了缓存管理的效率,缓冲池被实现为页链表; 很少使用的数据使用最近最少使用 (LRU) 算法的变体从缓存中老化。了解如何利用缓冲池将频繁访问的数据保存在内存中是 MySQL 调优的一个重要方面。
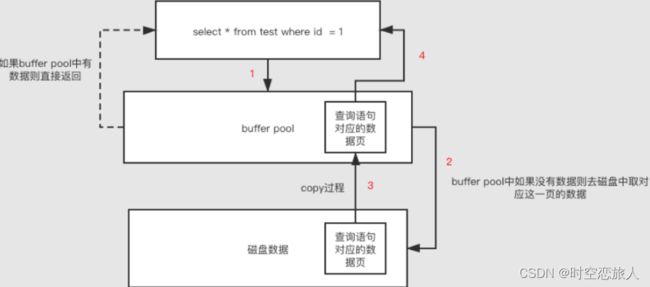
咱们在使用mysql的时候,比如很简单的select * from table;这条语句,具体查询数据其实是在存储引擎中实现的,(这里要注意了和缓存不一样,缓存实在Mysql Server层面实现的)大家都知道mysql数据其实是放在磁盘里面的,如果每次查询都直接从磁盘里面查询,这样势必会很影响性能,所以一定是先把数据从磁盘中取出,然后放在内存中,下次查询直接从内存中来取。但是一台机器中往往不是只有mysql一个进程在运行的,很多个进程都需要使用内存,所以mysql中会有一个专门的区域来处理这些数据,这个专门为mysql准备的区域,就叫buffer pool。buffer pool里面采用的是页链表实现的,也就是放在里面的数据都是一页一页的。当首次加载的时候是将从磁盘中取出来的数据放到了空白页面的,被称为Free Page.
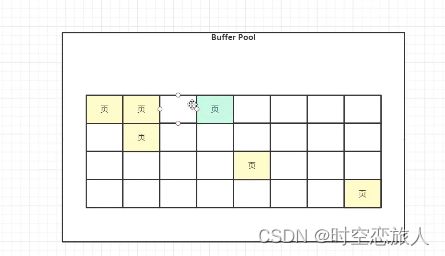
free链表的结构:free链表里面每个节点的控制块指向buffer pool里面的一个Free Page.
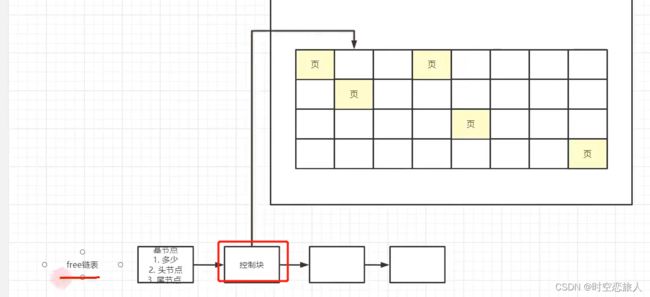
我们在对数据库执行增删改操作的时候,不可能直接更新磁盘上的数据的,因为如果你对磁盘进行随机读写操作,那速度是相当的慢,随便一个大磁盘文件的随机读写操作,可能都要几百毫秒。如果要是那么搞的话,可能你的数据库每秒也就只能处理几百个请求了! 在对数据库执行增删改操作的时候,实际上主要都是针对内存里的Buffer Pool中的数据进行的,对数据库的内也就是实际上主要是存里的数据结构进行了增删改,修改后的页被称为Dirty Page,那么这个脏页是要刷进磁盘的,这时mysql的后台里面会起一个线程,定时的去找这个脏页,然后刷新到磁盘中.
后台线程根据flush List去寻找脏页
flush链表的结构:
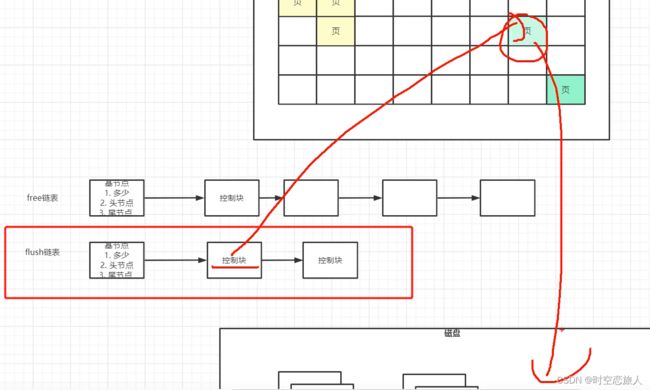
当buffer pool缓存池中的数据都装满了,我们就会基于LRU链表进行淘汰
,用的最多的就会放到最前面

但是直接这样去设计是有问题的昂,有什么问题呢?当然会有问题
预读失效:
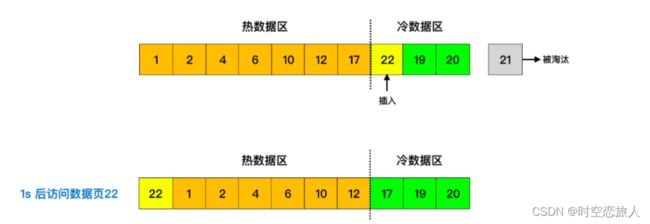
上面我们提到了缓冲池的预读机制可能会预先加载相邻的数据页。假如加载了 20、21 相邻的两个数据页,如果只有页号为 20 的缓存页被访问了,而另一个缓存页却没有被访问。此时两个缓存页都在链表的头部,但是为了加载这两个缓存页却淘汰了末尾的缓存页,而被淘汰的缓存页却是经常被访问的。这种情况就是预读失效,被预先加载进缓冲池的页,并没有被访问到,这种情况是不是很不合理。
缓冲池污染 :
还有一种情况是当执行一条 SQL 语句时,如果扫描了大量数据或是进行了全表扫描,此时缓冲池中就会加载大量的数据页,从而将缓冲池中已存在的所有页替换出去,这种情况同样是不合理的。这就是缓冲池污染,并且还会导致 MySQL 性能急剧下降。
基于以上的两种问题:
Msyql 基于 LRU 设计了冷热数据分离的处理方案。也就是将 LRU 链表分为两部分,一部分为热数据区域,一部分为冷数据区域。
当数据页第一次被加载到缓冲池中的时候,先将其放到冷数据区域的链表头部,1s(由 innodb_old_blocks_time 参数控制) 后该缓存页被访问了再将其移至热数据区域的链表头部。
查询 缓冲池的大小:
show variables like 'innodb_buffer_pool_size';调整缓冲池的大小,调整为2G
SET GLOBAL innodb_buffer_pool_size = 2147483648
2.页链表:三种Page
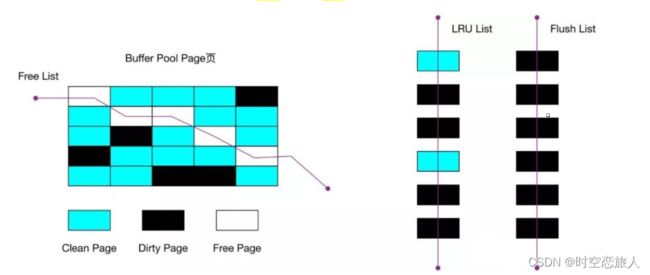
1.1Free Page(空闲页)
表示此Page 未被使用,位于 Free 链表。
1.2. Clean Page(干净页)
此Page 已被使用,但是页面未发生修改,位于LRU 链表。
1.3. Dirty Page(脏页)
此Page 已被使用,页面已经被修改,其数据和磁盘上的数据已经不一致。当脏页上的数据写入磁盘后,内存数据和磁盘数据一致,那么该Page 就变成了干净页。脏页 同时存在于LRU 链表和Flush 链表。
3..redo log
其实每个人都担心一个事,就是你在数据库的内存里执行了一堆增删改的操作,内存数据是更新了,但是这个时候如果数据库突然崩溃了,那么内存里更新好的数据不是都没了吗? MySQL就怕这个问题,所以引入了一个redo log机制,你在对内存里的数据进行增删改的时候,他同时会把增删改对应的日志写入redo log中, 万一你的数据库突然崩溃了,没关系,只要从redo log日志文件里读取出来你之前做过哪些增删改操作,瞬间就可以重新把这些增删改操作在你的内存里执行一遍,这就可以恢复出来你之前做过哪些增删改操作了。 当然对于数据更新的过程,他是有一套严密的步骤的,还涉及到undo log、binlog、提交事务、buffer pool脏数据刷回磁盘,等等。
Buffer Pool就是数据库的一个内存组件,里面缓存了磁盘上的真实数据,然后我们的系统对数据库执行的增删改操作,其实主要就是对这个内存数据结构中的缓存数据执行的。通过这种方式,保证每个更新请求,尽量就是只更新内存,然后往磁盘顺序写日志文件。
更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是比较高的,因为顺序写磁盘文件,他的性能要远高于随机读写磁盘文件。
刷盘是随机 I/O,而记录日志是顺序 I/O,顺序 I/O 效率更高。因此先把修改写入日 志,可以延迟刷盘时机,进而提升系统吞吐 这是为什么要使用重写日志的原因,并且这个重写日志的空间早就给你开辟好了 默认单个文件是48M.
4. update语句的执行流程
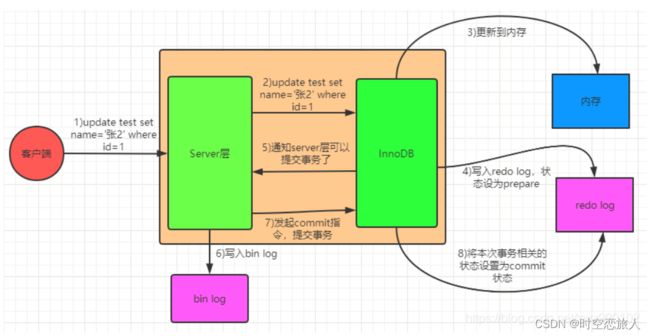
上图可以大概概括为以下几步:
1、先根据更新语句的条件,查询出对应的记录,如果有缓存,也会用到缓存
2、Server端调用InnoDB引擎API接口,InnoDB引擎将这条数据写到内存,同时写入redo log,并将redo log状态设置为prepare
3、通知Server层,可以正式提交数据了
4、Server层收到通知后立刻写入bin log,然后调用InnoD对应接口发出commit请求
5、InnoDB收到commit请求后将数据设置为commit状态
上面的步骤中,我们注意到,redo log会经过两次提交,这就是两阶段提交。
两阶段提交
两阶段提交是分布式事务的设计思想,就是首先会有请求方发出请求到各个服务器,然后等其他各个服务器都准备好之后再通知请求方可以提交了,请求方收到请求后再发出指令,通知所有服务器一起提交。
而我们这里redo log是属于存储引擎层的日志,bin log是属于Server层日志,属于两个独立的日志文件,采用两阶段提交就是为了使两个日志文件逻辑上保持一致
5.什么时候redo log会往数据库的磁盘上面刷呢?
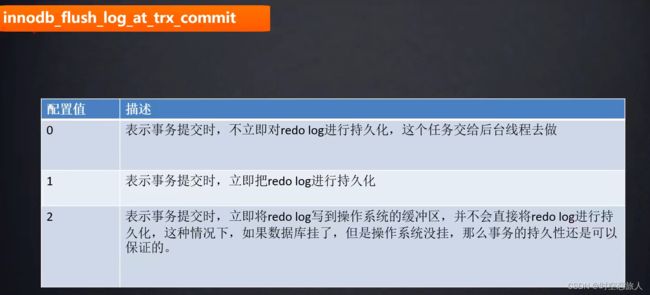
默认的值是2
6.bin log
MySQL整体来看,其实就有两块:一块是 Server 层,它主要做的是 MySQL功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。上面讲的redo log是InnoDB 引擎特有的日志,而Server 层也有自己的日志,称为 binlog(归档日志),也叫做二进制日志。
可能有人会问,为什么会有两份日志呢?
因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM是不支持事物的,也没有崩溃恢复(crash-safe)的能力,binlog日志只能用于归档。那么既然InnoDB是需要支持事务的,那么就必须要有崩溃恢复(crash-safe)能力,所以就使用另外一套自己的日志系统,也就是基于redo log 来实现 crash-safe 能力。
bin log和redo log的区别
1、redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的Server层实现的,所有引擎都可以使用。
2、redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给id=2 这一行的c字段加 1 ”。
3、redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
来源:
Mysql buffer pool详解 - 奕锋博客 - 博客园
【MySQL系列6】详解一条查询select语句和一条更新update语句的执行流程_双子孤狼的博客-CSDN博客