深度学习(十二):经典CNN
这是一系列深度学习的介绍,本文不会涉及公式推导,主要是一些算法思想的随笔记录。
适用人群:深度学习初学者,转AI的开发人员。
编程语言:Python
参考资料:吴恩达老师的深度学习系列视频
吴恩达老师深度学习笔记整理
深度学习500问
笔记下载:深度学习个人笔记完整版
CNN网络发展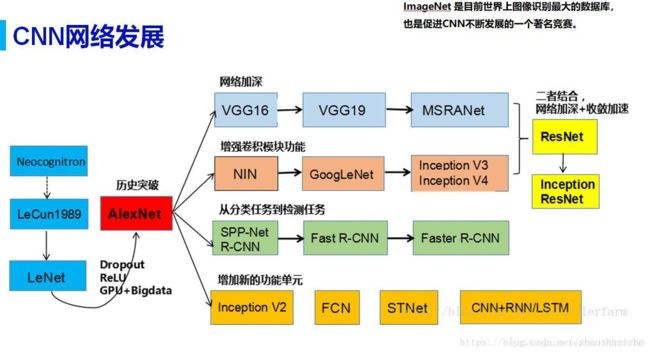

CNN受生物自然视觉认知机制启发而来。1959年,Hubel & Wiesel 发现,动物视觉皮层细胞负责检测光学信号。受此启发,1980年 Kunihiko Fukushima 提出了CNN的前身——Neocognitron ;
20世纪 90 年代,LeCun et al. 等人发表论文,确立了CNN的现代结构,后来又对其进行完善。1998年,他们设计了一种多层的人工神经网络,取名叫做LeNet-5,可以对手写数字做分类。和其他神经网络一样, LeNet-5 也能使用 backpropagation 算法训练;
2012年,在 ImageNet比赛,ALexNet大放异彩,将错误率由25%降至16%,从此CNN大火,从此计算机视觉开始重视深度学习;
2014年,VGGNet :深度更深,有两种版本,将错误率由25%降至7%,一种16层,一种19层,filter较小,更细粒度提取 ,常使用;
2014年,GoogleNet:将错误率由25%降至6%;
2015年,ResNet:残差网络。
CNN 的演化路径可以总结为以下几个方向:
- 进化之路一: 网络结构加深
- 进化之路二: 加强卷积功能
- 进化之路三: 从分类到检测
- 进化之路四: 新增功能模块
CNN常见网络结构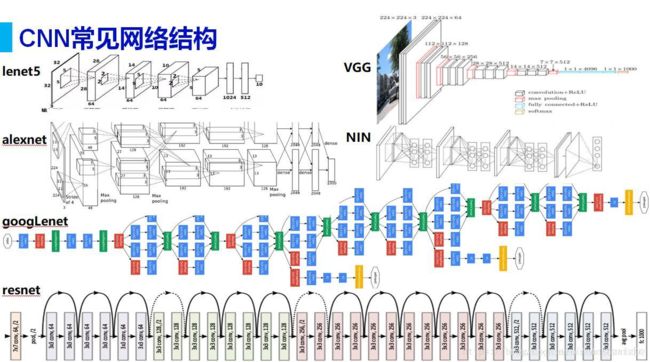
为什么现在的CNN模型都是在GoogleNet、VGGNet或者AlexNet上调整的?
以下粗略地介绍一下各个经典网络,想详细了解并实现其网络结构的朋友,可以阅读相关论文,或参考如下博文:
详解深度学习之经典网络架构(十):九大框架汇总
LeNet-5
参考:深度学习 CNN卷积神经网络 LeNet-5详解
LeNet-5是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。
LenNet-5训练的灰度图像,共有7层(不包括输入层),每层都包含不同数量的训练参数,如下图所示。
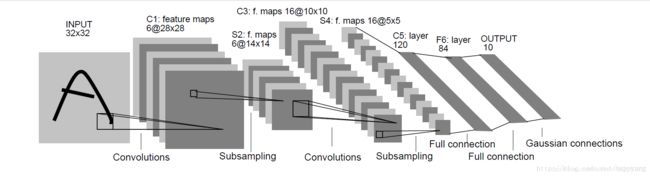
卷积后的激活函数未采用ReLU,人们使用sigmod函数,而不是ReLu函数,池化层采用的Mean Pooling。
6w左右个参数。
局限性:由于当时缺乏大规模训练数据,计算机的计算能力也跟不上,LeNet-5 对于复杂问题的处理结果并不理想。
AlexNet
AlexNet是2012年ILSVRC(Image Large Scale Visual Recognition Challenge)比赛分类项目的冠军,远超第二名(top5错误率15.3%,第二名26.2%),AlexNet包含5个卷积层,3个全连接层,使用多层小卷积叠加代替单个大卷积,使用2个GPU并行加速训练,结构如下:
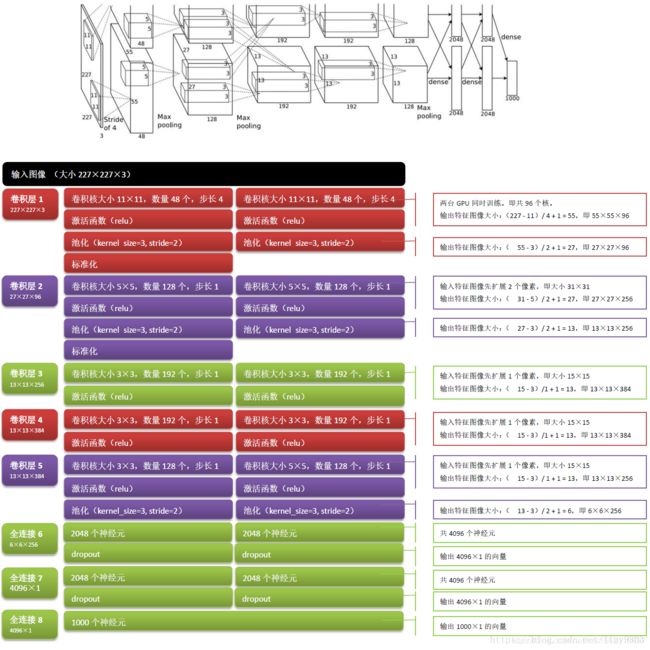
AletNet需要注意的几点:
- 使用ReLU作为激活函数,并验证了其在较深网络中的有效性,避免了sigmoid梯度弥散的问题;
- 全部池化层使用Max Pooling,避免平均池化的模糊效果;并提出步长比池化核的尺寸小,这样池化层的输出之间会有重叠覆盖,特升了特征的丰富性;
- 在最后几个全连接层使用dropout,随机忽略一部分神经元以避免模型过拟合;
- 提出LRN(Local Response Normalization,局部响应归一化,在之后的网络中很少应用),对局部神经元的活动创建了竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力;
- 使用了数据增强(Data Augmentation):人工增加训练集的大小——通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据,后续篇章会详细讲解;
- 使用了双GPU。
6000w左右个参数。
VGGNet
参考:详解深度学习之经典网络架构(四):VGG-Net
VGG全称是Visual Geometry Group属于牛津大学科学工程系,其发布了一些列以VGG开头的卷积网络模型,可以应用在人脸识别、图像分类等方面,分别从VGG16~VGG19。VGG在加深网络层数同时为了避免参数过多,在所有层都采用3x3或者1x1的filter,卷积步长被固定1。
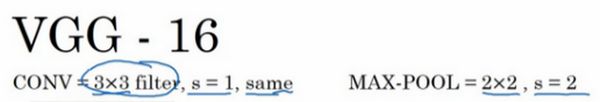
VGG全连接层有3层,根据卷积层+全连接层总数目的不同可以从VGG11 ~ VGG19,最少的VGG11有8个卷积层与3个全连接层,最多的VGG19有16个卷积层+3个全连接层,此外VGG网络并不是在每个卷积层后面跟上一个池化层,还是总数5个池化层,分布在不同的卷积层之下。

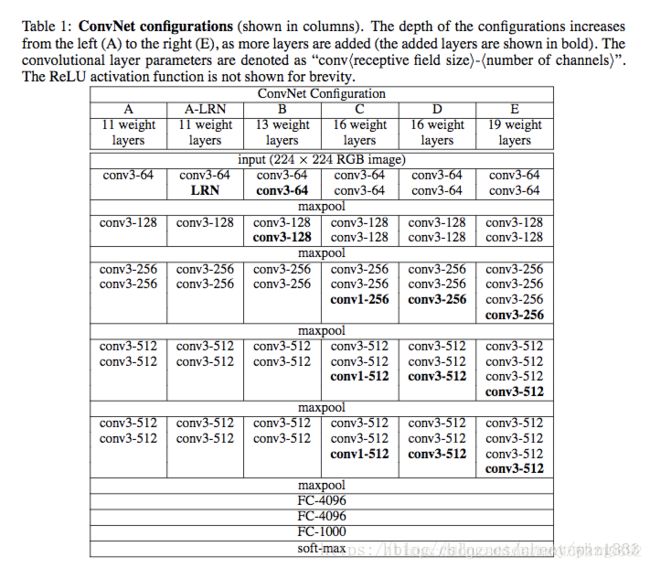
卷积层的过滤器数量变化存在一定的规律,由64翻倍变成128,再到256和512。作者可能认为512已经足够大了,所以后面的层就不再翻倍了。
由于VGG-16的表现几乎和VGG-19不分高下,所以很多人还是会使用VGG-16。
论文中,作者指出,虽然LRN(Local Response Normalisation)在AlexNet对最终结果起到了作用,但在VGG网络中没有效果,并且该操作会增加内存和计算,从而作者在更深的网络结构中,没有使用该操作。
1x1卷积核:降维,增加非线性
3x3卷积核:多个卷积核叠加,增加空间感受野,减少参数
VGG-16,1.38亿左右个参数。
vgg 16模型的内存和参数量的计算
GoogLeNet
2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名、VGG获得了第二名,这两类模型结构的共同特点是层次更深了。VGG继承了LeNet以及AlexNet的一些框架结构,而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多,GoogLeNet参数为500万个,AlexNet参数个数是GoogLeNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogLeNet是比较好的选择;从模型结果来看,GoogLeNet的性能却更加优越。
GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
Inception有四个版本,主要是在网络宽度上进行了改进,在同一层中使用了多个不同尺寸的卷积,以获得不同的视野,最后级联(直接叠加通道数量),这就是Inception module从v2开始,进一步简化把Inception module中的n×n模块分解为1×n和n×1的组合,减少了参数数量,v3进一步把最开始的7×7卷积和其他非3×3进行分解,v4引入了ResNet残差的思想。
Inception v1结构:
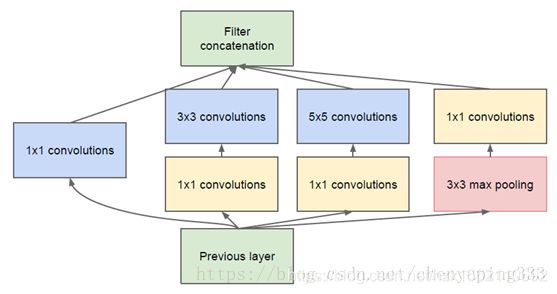
GoogLeNet网络结构(22层):
(1)GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
(2)网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。
GoogLeNet,500w左右个参数。
ResNet
通过实验可以发现:随着网络层级的不断增加,模型精度不断得到提升,而当网络层级增加到一定的数目以后,训练精度和测试精度迅速下降,这说明当网络变得很深以后,深度网络就变得更加难以训练了。这是由于梯度消失造成的。
ResNet首次提出了引入了残差网络结构(residual network),解决了网络过深而导致的梯度消失的问题,为更深的网络提供了有力的方向。
通过这种残差网络结构,可以把网络层弄的很深(据说目前可以达到1000多层),并且最终的分类效果也非常好,残差网络的基本结构如下图所示,很明显,该图是带有跳跃结构的:
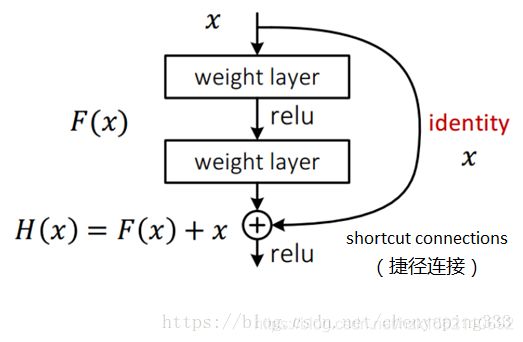
跳跃连接(Skip connection),它可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。
ResNet有 两代(ResNet v1和ResNet v2),如下是ResNet v1中34层的深度残差网络的结构图:

残差网络的跨层连接的计算方式和GoogLeNet中的级联不同,这里是每个通道进行相加操作,如果的通道数和的通道数不同,则对用1×1的卷积操作,使得维度一样。
v2版本只是引入了BN(batch normalization),并讨论的BN放置位置的问题,其他思想一样。
其他网络
CNN发展迅猛,除了上述网络结构外,近几年又有新型网络结构出现:
- DenseNet:比ResNet来的更加彻底,即当前的每一层都和前面的每一层连接。
- ResNeXt:在ResNet的基础上,借鉴GoogLeNet的思想,增加了网络的宽度,同时,为了简化设计的复杂度,不像Inception module里面采用了不同尺寸的卷积,这里使用相同的的卷积,并用了32个,最后每个通道相加,和Inception module的级联不同。
- DPN:一种双通道网络,结合了ResNet和DenseNet的优点,具有一定的参考价值。