详解pytorch之tensor的拼接
tensor经常需要进行拼接、拆分与调换维度,比如通道拼接,比如通道调至最后一个维度等,本文的目的是详细讨论一下具体是怎么拼接的。如果本来就理解这其中的原理的童鞋就不用往下看了,肯定觉得啰嗦了~~
拼接即两个tensor按某一维度进行拼接,分两种情况,一个是不新增维度,一个是新增维度。
1.torch.cat(tensors, dim=0, *, out=None) ---不新增维度
tensors即要拼接的tensor列表或元组,按dim指定的维度进行拼接。
如下分别为按第0维拼接与按第1维拼接:
import torch
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
result = torch.cat([a, b], 0)
print(result)结果:
tensor([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
result = torch.cat([a, b], 1)
print(result)结果:
tensor([[1, 2, 5, 6],
[3, 4, 7, 8]])
二维的情况其实还是蛮好理解的,不过还是先以二维的情况来讨论一下为什么是这样拼接。
注,本文全文讨论的维度都是从0维开始算的
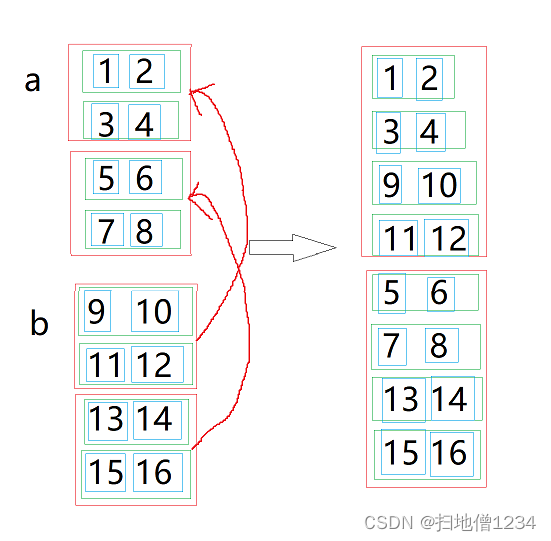
如下图,一共是两个张量,红框表示按第0维排列的元素,a的0维有两个元素,b的0维也有两个元素。绿色表示按第1维排列的元素(自然是在第0维的某个元素里面来数了,比如a[0]),a[0],a[1],b[0],b[1]都有两个元素
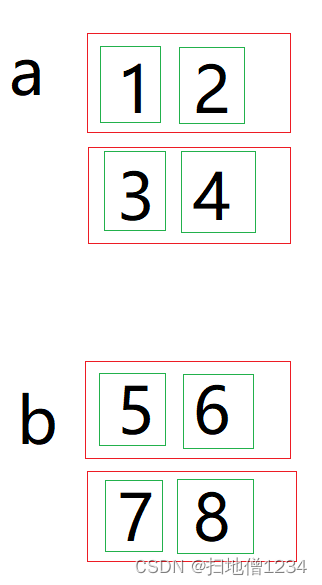
接下来就是讨论怎么拼接,如果是按第0维拼接,即按照第0个维度把a、b的数据拼接起来,怎么拼呢,就是b的两个红框依次移到a的末尾就行了,可以理解为直接将两个黑框合成一个。
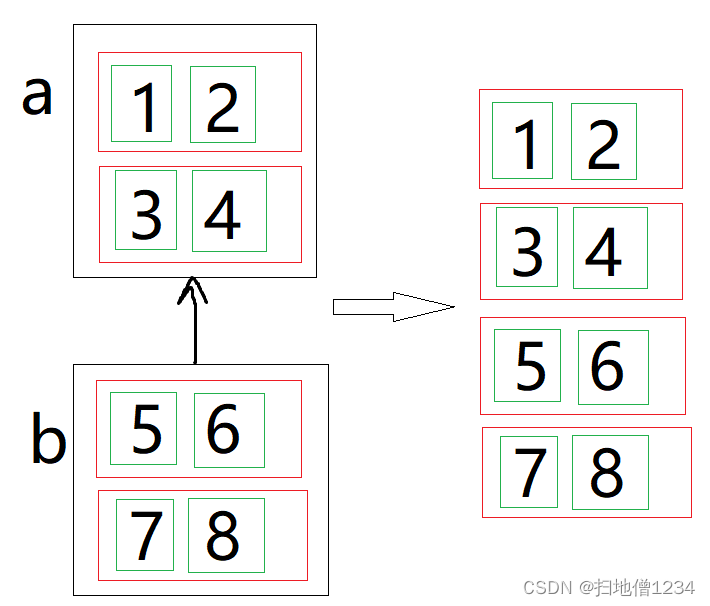
如果是按第1维拼接呢。那就是把a的第1个红框与b的第1个红框拼成一个,把a的第2个红框与b的第2个红框拼成一个。如下图: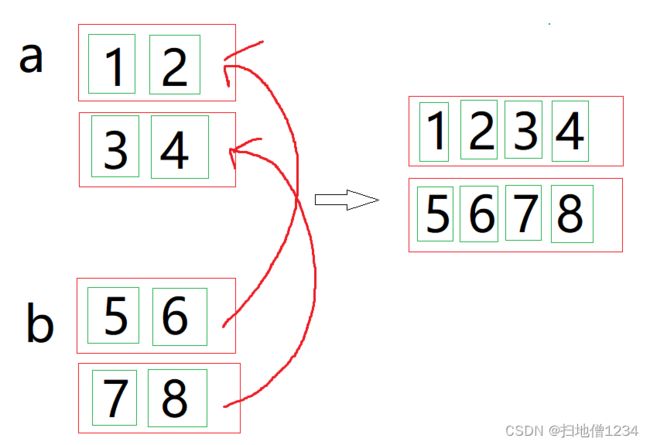
按照如上的拼法,自然会有一个要求,a有两个红框,b就必须有两个红框,不然的话就不能按第1维拼接了。
接着来个稍微复杂一点的,下面这个结果是什么呢?
import torch
a = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
b = torch.tensor([[[9, 10], [11, 12]], [[13, 14], [15, 16]]])
result = torch.cat([a, b], 1)
print(result)
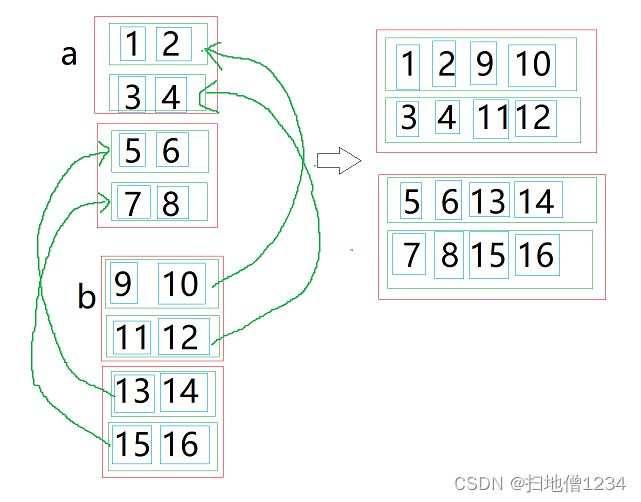
下面还是按照上面的分析方法来看。首先画图如下,红框表示第0维的元素,绿框是第1维的元素,蓝框是第2维的元素。
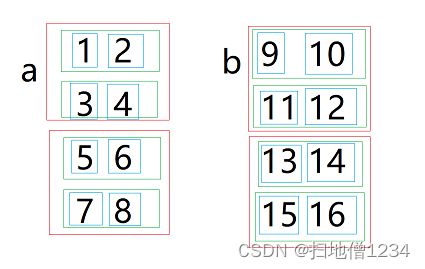
接下来按照第1维拼接,突然发现,这跟之前那个按照第1维拼接是一模一样的啊,还是把a的第1个红框与b的第1个红框拼成一个,把a的第2个红框与b的第2个红框拼成一个。
运行结果即:
tensor([[[ 1, 2],
[ 3, 4],
[ 9, 10],
[11, 12]],
[[ 5, 6],
[ 7, 8],
[13, 14],
[15, 16]]])
这里说明一下,上面1,2,3,4的红框与9,10,11,12的红框拼接,为啥不是下面这样的拼接结果呢?
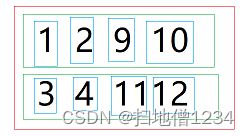
因为上面这个就不是把两个红的合成一个,而是把两个绿的合成一个了,它实际上就是按第2维进行拼接了,接下来我们要讨论的就是:那如果是按第2维拼接呢
import torch
a = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
b = torch.tensor([[[9, 10], [11, 12]], [[13, 14], [15, 16]]])
result = torch.cat([a, b], 2)
print(result)
还是一样的道理,这次就是把a的第1个红框的第1个绿框与b的第1个红框的第1个绿框合成一个,把a的第1个红框的第2个绿框与b的第1个红框的第2个绿框合成一个,以此类推,如下图。
拼接的要求也变成了:a有两个红框,b也得有两个红框,a的红框里有两个绿框,b的红框里也得有两个绿框。
运行结果为:
tensor([[[ 1, 2, 9, 10],
[ 3, 4, 11, 12]],
[[ 5, 6, 13, 14],
[ 7, 8, 15, 16]]])
那可能还有一个问题,如果我想把1和9拼起来,把2和10拼起来呢?cat是没法完成这个操作了,这里先放个答案:运行如下代码即可做到
import torch
a = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
b = torch.tensor([[[9, 10], [11, 12]], [[13, 14], [15, 16]]])
result = torch.stack([a, b], 3)
print(result)
运行结果为:
tensor([[[[ 1, 9],
[ 2, 10]],
[[ 3, 11],
[ 4, 12]]],
[[[ 5, 13],
[ 6, 14]],
[[ 7, 15],
[ 8, 16]]]])
接下来具体说明一个stack。
2.torch.stack(tensors, dim=0, *, out=None) -----新增维度
tensors即要拼接的tensor列表或元组,按dim指定的维度进行拼接。参数看起来跟cat一样,但是这里的维度含义并不一样,cat的拼接即按指定维度把数据拼起来,并不会新增维度。而stack是什么呢,下面结合具体的例子来说明,为了简化,这里只用下面这个例子来进行说明。
(1)在第0维新增维度进行拼接
import torch
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
result = torch.stack([a, b], 0)
print(result)
cat是把两个黑框合成一个,而stack呢,并不会合成一个,它是创建了一个两个黑框,第一个给a,第二个给b,结果就不是2维了,而是3维了,这次黑框就留下来了哦,它表示新的第0维的元素了,红框变成了第1维的元素,绿框变成了第2维的元素。
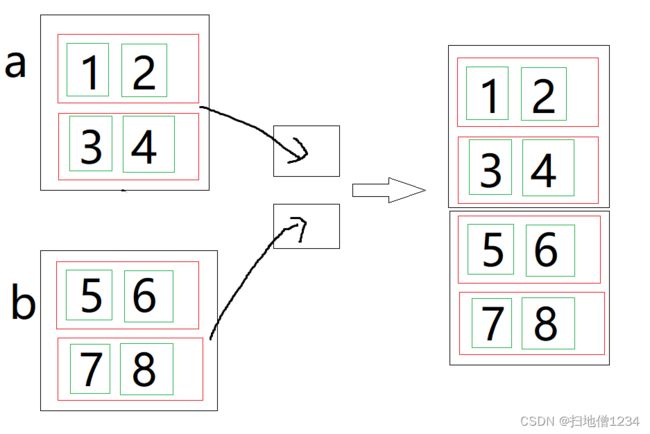
运行结果如下:
tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
(2)在第1维新增维度进行拼接
import torch
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
result = torch.stack([a, b], 1)
print(result) cat是把两个红框合成一个红框,而stack是在红框中新增两个黑框,a的第1个红框里的元素放第1个黑框,b的第1个红框里的元素放第2个黑框,以此类推,如下图。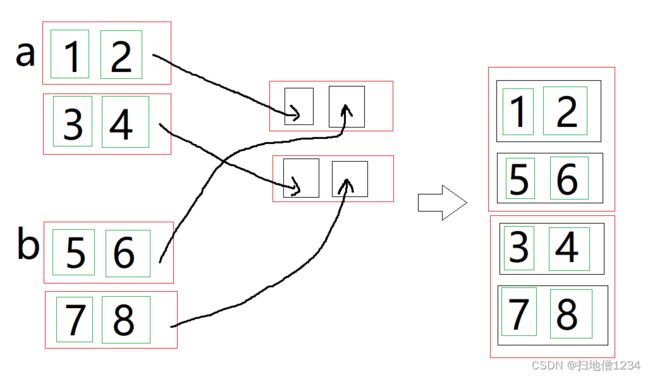
运行结果如下:
tensor([[[1, 2],
[5, 6]],
[[3, 4],
[7, 8]]])
(3)第2维新增维度进行拼接
import torch
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
result = torch.stack([a, b], 2)
print(result)cat是没法按第2维拼接的,因为没有第2维。stack就是在第2维新增一个维度,即在每个绿框里新增两个黑框,分别把a、b对应的绿框里的数据填进去,如下图。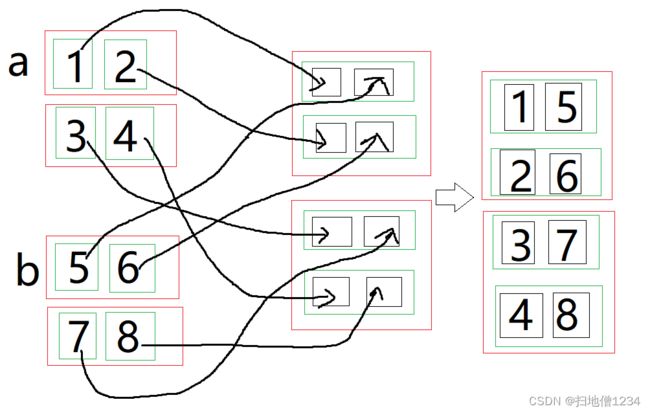
3.补充一下,上述的示例为了方便展示,都是合并两个张量,实际上自然可以合并超过两个张量,只不过上面是把两个框合成一个,那3个张量就是把3个框合成一个了,不详述,可以自行试验。