MAE同期工作,MSRA新作SimMiM:掩码图像建模,赶在内卷前的新方向!

ArXiv链接: https://arxiv.org/abs/2111.09886
Open Code: https://github.com/microsoft/SimMIM
目录
- 摘要
- 1、介绍
- 2、相关工作
- 3、方法
-
- MIM架构
- 可视化
- 结论
摘要
这篇文章提出了一个新的图像掩码建模的框架SimMiM。我们简单化了最近提出的相关方法,不需要特别的设计需要,例如通过离散VAE或聚类的块掩码和令牌化。为了调查是什么使得掩码图像建模学习到表征,我们系统调研了我们框架内的主要成分,发现每一个成分的简单设计揭露了一个强大的表征学习性能:1、带有中等大小的掩码块尺度例如32去随机遮挡输入图像,能够获得强大的前置任务;2、预测原始像素的RGB值通过直接地回归操作,没有比复杂设计的块分类方法更差;3、预测头,通过一个浅层的线性层,不比一个重量级的多层网络差。使用ViT-B,我们的方法能够在ImageNet-1K上获得83.8%的微调识别率,超过当前最好的方法0.6%;当使用约650M参数的更大模型SwinV2-H时,在仅使用ImageNet-1K上获得87.1%的识别率。我们同样使用这个方法去定位对于数据渴望的问题,在规模的模型训练中,我们以比以前最领先的方法少接近40倍的标记数据,获得了在四个标准集上领先的性能。
1、介绍
理查德*费曼说过:我不能理解我不能创造的东西。
遮挡标记建模是这样一种学会去创造的任务:输入信号按照比例遮挡并试图去预测遮挡的信号。在NLP中,跟随这种哲学思想,自监督学习方法在遮挡语言建模任务上建立起来的,已经很大程度上刷新这个领域,例如通过使用海量的未标记数据去学习非常大规模的语言模型,已经在很多的NLP任务上泛化良好。
在计算机视觉中,尽管有不少先驱工作使用自监督表征学习的哲学思路,但在前几年,这几项工作几乎被对比学习所掩盖。应用这项任务到语言和视觉领域的不同难点可以通过这两种模态的区别来解释。第一个不同点是图像展示了很强的局部性:相邻的像素趋向于高度关联,因此这个任务能够通过复制相邻的像素而不是通过语义推断来完成。另一个不同点是视觉信号是原始的,低级的,而文本标记是人来产生的高级的概念。这将引发一个问题:低级信号的预测是否对高级视觉识别任务有帮助。第三个不同点是视觉信号是连续的,而文本标记是离散的。目前不清楚基于分类的掩码语言建模方法如何适用于去处理连续的视觉信号。
直到最近,有一些尝试去连接形态间的鸿沟,解决了这些障碍,通过介绍一些特别的设计,例如,通过将连续的信号转变成颜色聚类,或使用额外的网络去标记化图像块,或者通过一个块掩码策略去打破短距离的连接等。通过这些设计,学习到的表征被证明在其他视觉任务上迁移良好。
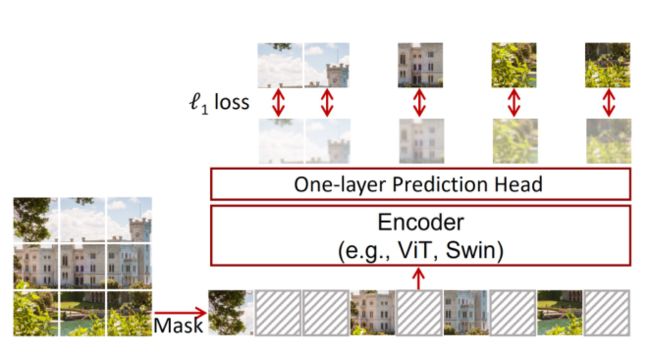 Figure 1. An illustration of our simple framework for masked language modeling, named SimMIM. It predicts raw pixel values of the randomly masked patches by a lightweight one-layer head, and performs learning using a simple ℓ1 loss.
Figure 1. An illustration of our simple framework for masked language modeling, named SimMIM. It predicts raw pixel values of the randomly masked patches by a lightweight one-layer head, and performs learning using a simple ℓ1 loss.
SimMiM,遮挡图像建模的框架。它通过一个轻量的单层预测头去预测随机遮挡块的原始像素值,并且使用简单的 l 1 l1 l1损失去执行学习。
对比需要特别复杂的设计,我们提出了一个简单的框架能够与视觉信号的本质对齐好,如图所示;并且能够学习相似甚至更好的表征,相对比以前更加复杂的方法:对输入图像块随机掩码,并使用一个线性层以 l 1 l1 l1损失去回归遮挡区域的原始的像素值。这个关键的设计和洞察包括:
- 随机遮挡使用在图像块上,这对于ViT来说很简单和方便。对于遮挡的像素,要么更大的图像块或者更高的掩码比例,能够导致寻找相邻可见像素机会更低。对于一个大的遮挡块尺度如32,能够获得类似的性能在10-70%的掩码比例范围内;对于小的遮挡块尺度如8,掩码比例需要高达80%才能表现良好。注意到优先的掩码比例与语言领域存在很大的不同,语言中默认的遮挡比例为0.15。我们建设两种模态中不同程度的信息冗余导致了不同的行为。
- 一个原始像素的回归任务被使用。回归任务对于连续的视觉信号的本质很吻合,视觉信号具有有序性。这个简单的任务操作,不比其他复杂的分类操作效果差。
- 一个极其轻量级的预测头,例如一个线性层被采用,获得了相似或者更好的迁移性能,相对于其他重量级的预测头而言,例如一个反转的Swin-B。这个极其简单的轻量级预测头带来了预训练时超乎想象的加速。此外,我们注意到从 1 2 2 − 19 2 2 12^2-192^2 122−1922范围内的目标分辨率与最高的 19 2 2 192^2 1922分辨率的性能一样有竞争力。虽然更重的头或者更高的分辨率能够导致更好的性能,但这种更大的能力对于下游的微调的任务不一定有用。
通过这个简单的SimMiM方法,对于表征学习非常有效。使用ViT-B,能够在ImageNet-1K上取得了最好的83.8%的识别率。也展示出对于更大模型的可扩展性,在ImageNet-1K上使用SwinV2-H获得最好的87.1%的角度,并且在ImageNet-V2,COCO object detection,ADE20K语义分割和Kinetics-400动作识别上都取得了新的记录。
最近我们见证了NLP和CV一个交叉增长在基础建模和学习算法方面,同样有多模态应用等,这些与人脑如何获得通用知识的能力是吻合的,我们希望我们的掩码信号建模能够推动这个领域一点发展,启发AI不同领域的更深层次的交互。
2、相关工作
Masked Ianguage Modeling (MLM)掩码语言建模
MLM和它的自回归变体是NLP领域的主要自监督学习方法。给出一个句子或者词组的可见部分标签,这个方法尝试去学习表征,通过预测输入中不可见的标签。自从三年前,这系列方法已经刷新了这个领域,它借助海量数量,使得大语言模型学习变得可能,在宽泛的语言理解和生成任务上泛化良好。
Masked image modeling (MIM)掩码图像建模
掩码图像建模与MLM任务并行推进,但长期处在非主流位置。这个上下文编码的方法是这个方向的先驱工作,它通过遮挡原始图像的矩形块,进而预测遮挡部分的像素。CPC通过对比预测编码损失,在每个批次中通过验证任务预测图像块。最近,iGPT,ViT,BEiT重新召唤这类学习方法在现代ViT上,通过设计特殊的组件例如像素聚类,中值颜色预测,标签化等取得了强大的表征能力。与这些复杂的设计对比,我们提出了一个极其简单的SimMiM框架,能够取得轻胜的性能。
Reconstruction based methods基于重构的方法
这类方法与我们的处理相关,特别是自编码类的方法。与我们的方法相似,他们采取了一个重构的任务去复原原始的像素。但是,他们是基于可见信号重构的哲学思想,而不是像我们的方法那样去创建或者预测不可见的信号。因此,他们进展的路径不一样,通过合适的归一化或者架构模块来有效规整这个任务的学习。
还有一些相关任务,如图像复原,压缩和其他自监督学习的方法,这里就不展开论述了。
3、方法
MIM架构
我们的SimMiM方法通过遮挡图像建模来学习表征,它通过遮挡输入图像的部分比例,去预测遮挡部分的原始信号。这个框架包含4个主要成分:
- 遮挡策略:输入一张图片,这个模块设计如何选取区域去遮挡,以及如何实现选中区域的遮挡,遮挡过后的图像将会作为输入。
- 编码架构:它为遮挡的图像提取隐含的特征表征,然后将会被用于预测遮挡部分的原始像素。学习后的编码器被期待能够迁移到不同视觉任务上。在这篇文章中,我们主要考虑两个视觉Transformer架构:原始的ViT和SwinT。
- 预测头网络:预测头将会被应用到学习到的隐含的特征表征上去产生遮挡部分的原始信号的一种形式。
- 预测目标。这个部分定义要预测的原始信号的形式。它可以是原始的像素值或者它的变换形式。这个成分主要定义损失类型,包含典型的交叉熵分类损失和 l 1 l1 l1或 l 2 l2 l2回归损失。
在接下来的部分,我们展示每个组成的细节。这些细节的选择然后被系统学习,通过组合每个组成的简单设计,我们能够获取强大的表征学习性能。
这里重点讲下预测目标。
Prediction Targets:Raw pixel value regression.
像素值是图像空间的连续的,一个直接的选择是预测遮挡区域的原始像素,通过回归。通常,ViT架构经常产生下游任务的特征图。为了预测输入图像的全分辨率的所有像素值,我们将特征图的每一个特征向量映射回到原始的分辨率,让这个向量承担对应像素的预测任务。
例如,通过SwinT编码器后下采样的 32 × 32 \times 32×特征图,我们使用了一个 1 × 1 1 \times 1 1×1卷积层即线性去产生 3072 = 32 × 32 × 3 3072=32 \times 32 \times 3 3072=32×32×3个维度去代表 32 × 32 32 \times 32 32×32像素的RGB值。我们童颜考虑更低分辨率的目标通过采样原始图像采样率为{ 32 × , 16 × , 8 × , 4 × , 2 × 32 \times, 16 \times, 8 \times, 4 \times, 2\times 32×,16×,8×,4×,2×}。
一个 l 1 l1 l1loss被用于遮挡像素上:
1 Ω ( x M ) ∥ y M − x M ∥ 1 \frac{1}{\Omega(\mathrm {x}_M) } {\left \| \mathrm {y}_M -\mathrm {x}_M \right \| }_1 Ω(xM)1∥yM−xM∥1
其中, x , y ∈ R 3 H W × 1 \mathrm {x}, \mathrm {y} \in R^{3HW \times 1} x,y∈R3HW×1是输入RGB值和预测值,对应地;M指代遮挡像素的集合; Ω ( ) ˙ \Omega(\dot) Ω()˙是元素的数量。我们同样考虑 l 2 l2 l2和平滑 l 1 l1 l1损失在实验中执行取得类似效果, l 1 l1 l1损失被默认采用。
可视化
在这部分,我们考虑去理解这个提出来的方法,同样一些关键的设计,通过可视化的方法。
学习到了什么能力
下图展示了几个人为设计的掩码的复原图像,通过MIM去了解学习到了什么能力。人为设计的遮挡方式,从左到右,包含:随机掩码,一个移去主要目标大部分的掩码,和一个移去主要目标所有部分的掩码。我们能够得到以下观察:

Recovered images using three different mask types (from left to right): random masking, masking most parts of a major object, and masking the full major object.
- 通过随机遮挡主要目标的中等部分,遮挡部分的形状和纹理都能够很好地复原,如图所示这个企鹅,山体,帆船和人物等。在没有遮挡的区域,存在严重的棋盘格子伪影,是由于在训练过程中,未遮挡部分的复原没有被学习。
- 通过遮挡主题目标的大部分,例如90%,这个模型仍然能够预测物体的存在,通过微不足道的线索。
- 当整个物体都被遮挡掉了,这个遮挡区域将会被背景纹理修复。
这些观察表明这个方法已经学习到了目标的强大推理能力,这个能力不是用于图像身份的记忆或者附件像素的简单复制。
Prediction & reconstruction
我们展示了遮挡预测任务(我们的方法)与联合遮挡预测和可见信号重构任务,去学习表征的对比,发现纯粹的遮挡预测任务效果明显更好。下图显示了两种不同方法的复原效果。后者会看起来更好看,但是模型容量可能被浪费在回复未遮挡区域的复原上,这个对于微调没有太多用处。

Recovered images by two different losses of predicting only the masked area or reconstructing all image area, respectively. For each batch, images from left to right are raw image, masked image, prediction of masked patches only, and reconstruction of all patches, respectively.
Effects of masked patch size
下图展示了带有不同遮挡块尺度的图像,在固定遮挡比例为0.6情况下的复原效果。可以看出,遮挡块尺度更小,细节能够更好复原。但是,学习到的表征迁移更差。可能地,在尺度更小的patch块上,预测任务能够更轻松被相邻像素或者纹理所完成。

An example of recovered image using masked patch sizes of 4, 8, 16, 32 and 64, and a fixed masked ratio of 0.6.
结论
这篇文章展示了一个简单有效的自监督学习框架,SimMiM,去利用遮挡图像建模进行表征学习。这个框架尽可能简单:
- 使用一个中等大小的遮挡图像块尺度去随机遮挡;
- 通过直接回归任务去预测RGB值的原始像素;
- 预测头网络是一个尽可能浅层的单层线性网络。
我们希望这个强大的结果以及这个简单的网络能够促进该方向上的未来研究,同时鼓励AI领域的深度互动。