pytorch实战
pytorch实战
anaconda历史版本
1 pytorch安装
1换源教程
找到C:\Users\用户名下的这个文件
.condarc文件,更换一下内容
ssl_verify: true
show_channel_urls: true
channels:
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/
创建虚拟环境
conda create -n pytorch python=3.6
conda init
2激活虚拟环境
conda activate pytorch
检查torch是否按照成功
import torch
torch.cuda.is_available()
3虚拟环境和base的切换
conda info --envs 查看环境目录
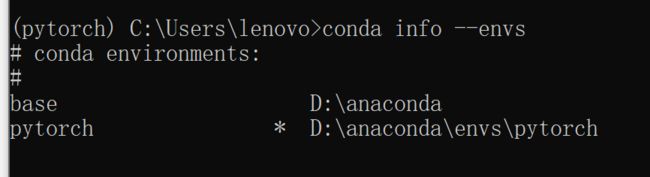
conda activate base 切换到基础环境

停止环境变量的激活
conda deactivate

2 torch基础使用
主要以卷积神经网络为例,对卷积神经网络不了解的可以看上一篇文章传送
pytorch可以想象成一个工具箱,
dir() # 打开
help() # 说明书
首先在控制台,

在python控制台,也是可以多行运行的,按住shift+回车
查看torch中有哪些模块
可以继续进行查看
dir('Tensor')
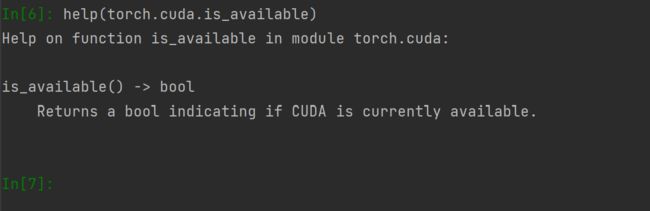
help查看使用方法
help(torch.cuda.is_available)
2.1 pytorch加载数据
Dataset
DataLoader
Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作(迭代器,方便我们去多线程地读取数据,并且可以实现batch以及shuffle的读取等)。Dataset抽象类,要进行继承后重写
len和getitem这两个函数,前者给出数据集的大小,后者是用于查找数据和标签。
项目目录结构如下,数据
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import os
import torchvision
class Mydata(Dataset):
# 初始化,定义数据路径和标签
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
self.path=os.path.join(root_dir,label_dir)
self.path_list=os.listdir(self.path)
def __getitem__(self, item):
name=self.path_list[item]
img_name=os.path.join(self.root_dir,self.label_dir,name)
img=Image.open(img_name)
label=self.label_dir
return img,label
def __len__(self):
return len(self.path_list)
root_path="../../data/train"
ant_path="ants"
bees_path="bees"
ant_dataset=Mydata(root_path,ant_path)
bees_dataset=Mydata(root_path,bees_path)
train_dataset=ant_dataset+bees_dataset
print(train_dataset[0])
print(train_dataset.__getitem__(0))
print(train_dataset.__len__())
print(train_dataset[167])
"""
(, 'ants')
(, 'ants')
245
(, 'bees')
"""
3 tensorboard
.add_scalar() # 添加数据
.add_image() # 添加图像
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
for i in range(100):
writer.add_scalar("y=x",i,i) # 将标量数据添加到tensorboard中
writer.close()

打开
tensorboard --logdir=logs
更改窗口
tensorboard --logdir=logs --port=6007
注意:必须要切换到logs的上一级目录,输入以上指令才能打开
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer=SummaryWriter("logs")
# img_path="../练手数据集/train/ants_image/0013035.jpg"
img_path="../练手数据集/train/bees_image/16838648_415acd9e3f.jpg"
img_PIL=Image.open(img_path)
img_array=np.array(img_PIL)
print(img_array.shape)
writer.add_image("test",img_array,2,dataformats='HWC')
for i in range(100):
writer.add_scalar("y=3x",3*i,i)
writer.close()
tensorboard中上一次的数据可能会影响下一次,建议每次运行完毕,删除logs下的文件
.add_image()

numpy中的数据格式是(H,W,C)高度宽度和通道,所以要改一下参数设置
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer=SummaryWriter("logs")
# img_path="../练手数据集/train/ants_image/0013035.jpg"
img_path="../../练手数据集/train/bees_image/16838648_415acd9e3f.jpg"
img_PIL=Image.open(img_path)
img_array=np.array(img_PIL)
print(img_array.shape)
"""
(450, 500, 3) H W C
"""
writer.add_image("test",img_array,2,dataformats='HWC')
writer.close()
更换路径,加载第二张
img_path="../../练手数据集/train/ants_image/0013035.jpg"
writer.add_image("test",img_array,3,dataformats='HWC') # .("test1")
如果修改参数tag,那么图片会在另一个区域显示
4 transforms的使用
transforms种有许多好用的工具,进行数据类型转换,改变size等
from torchvision import transforms
from PIL import Image
img_path="../练手数据集/train/ants_image/0013035.jpg"
img=Image.open(img_path)
# img.show() #
print(img)
tensor_trans=transforms.ToTensor() # 实例化工具
tensor_img=tensor_trans(img)
print(tensor_img)
"""
tensor([[[0.3137, 0.3137, 0.3137, ..., 0.3176, 0.3098, 0.2980],
[0.3176, 0.3176, 0.3176, ..., 0.3176, 0.3098, 0.2980],
[0.3216, 0.3216, 0.3216, ..., 0.3137, 0.3098, 0.3020],
...,
"""
安装opencv
pip install opencv-python
不同的图片打开方式,对应的存储类型

代码爆红,alt+回车会显示小灯泡
介绍一些transforms里常见的类Compose(),按住ctrl点击查看源码

这里有许多属性,简单介绍一下__call__该方法的功能类似于在类中重载 () 运算符,使得类实例对象可以像调用普通函数那样,以“对象名()”的形式使用。
class Person:
def __call__(self, name):
print('__call__'+'hello' ,name)
def hello(self,name):
print('hello',name)
person=Person()
person.hello('zhansan')
person('zhansan')
"""
hello zhansan
__call__hello zhansan
"""
# 实际上“名称()”可以理解为是“名称.__call__()”的简写
def say():
print("pytorch")
say()
say.__call__()
"""
pytorch
pytorch
"""
Totensor使用,tensorboard输入必须是tensor类型
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
img=Image.open('../练手数据集/train/ants_image/0013035.jpg')
print(img)
writer = SummaryWriter("logs")
# 转成tensor类型
trans=transforms.ToTensor()
img_tens=trans(img)
writer.add_image("tensor",img_tens)
Normalize归一化

需要指定均值和标准差
print("img_tensor:",img_tens[1][1][1])
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) # rgb是3通道,因此指定三个均值,三个标准差
img_norm=trans_norm(img_tens)
print(img_norm[1][1][1])
writer.add_image("nor_img:",img_norm,3) # step改,1,2,3
writer.close()
"""
img_tensor: tensor(0.5961)
tensor(0.1922)
"""
可以看出,归一化后的变化
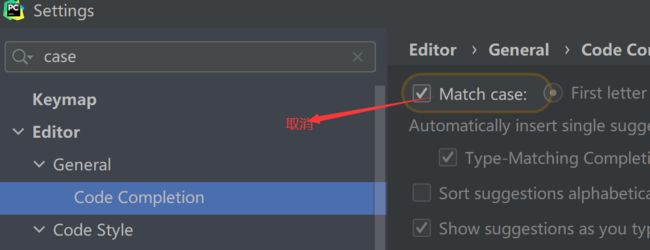
Resize修改尺寸大小,你如果想写代码的时候忽略大小写的匹配(提升代码时不区分大小写),这样你输入torch.r就会提示torch.Resize
print(img.size)
trans_size=transforms.Resize((300,300))
img_resize=trans_size(img)
print(img_resize)
img_resize=trans(img_resize)
writer.add_image("resize",img_resize,0)
"""
(768, 512)
"""
这样一步步的处理太麻烦了,可以不可直接写在一起呢?答案是可以的,使用Compose
# Compose-resize
trans_size2=transforms.Resize(512)
# PIL -> PIL
trans_compose=transforms.Compose([trans_size2,trans]) # resize,totensor
img_resize2=trans_compose(img)
writer.add_image("compose",img_resize2,1)
随机裁剪
trans_random=transforms.RandomCrop(100)
# trans_random=transforms.RandomCrop((500,1000))
trans_compose2=transforms.Compose([trans_random,trans])
for i in range(10): # 随机裁剪10个
img_rand=trans_compose2(img)
writer.add_image("rand",img_rand,i)
writer.close()
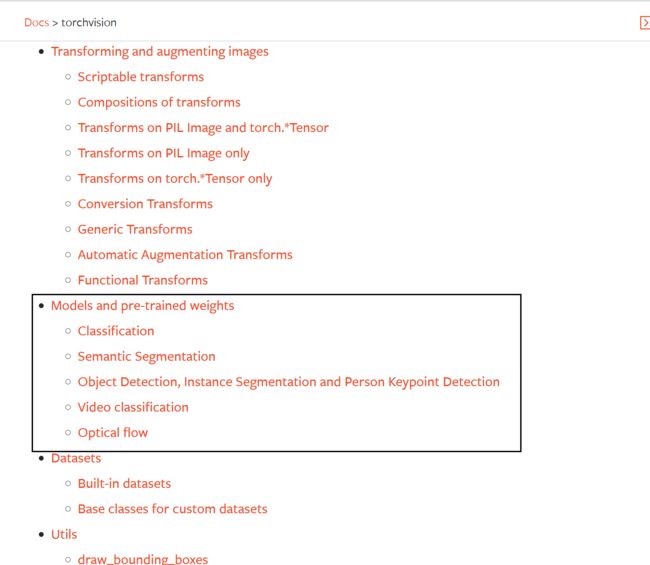
5 torchvision中的数据集
该torchvision软件包由流行的数据集、模型架构和用于计算机视觉的常见图像转换组成
Dataloader
数据加载器。组合数据集和采样器,并提供给定数据集上的迭代。DataLoader 支持具有单进程或多进程加载、自定义加载顺序以及可选的自动批处理
import torchvision
import torchvision.transforms
from torch.utils.tensorboard import SummaryWriter
data_transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=data_transform,download=True)
"""
root 下载路径,train训练集
"""
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=data_transform,download=True)
img,label=test_set[0]
print(img)
print(label)
print(test_set.classes) # 标签的名称
writer=SummaryWriter("logs")
for i in range(10):
img,label=train_set[i]
writer.add_image("test_set",img,i)
writer.close()
data中取数据dataloader
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data=torchvision.datasets.CIFAR10(root='./dataset',
train=False,transform=torchvision.transforms.ToTensor())
test_loader=DataLoader(dataset=test_data,batch_size=100,shuffle=True,num_workers=0) # batch_size一次取几张
# drop_last=True 最后的数据集不够会直接舍弃
# shuffle=True 下一轮会进行打乱洗牌
img,label=test_data[0]
print(img.shape)
print(label)
writer=SummaryWriter("dataloader")
for each in range(2):
step = 0
for data in test_loader:
imgs,labels=data
print(imgs.shape)
print(labels)
writer.add_images("each{}".format(each),imgs,step)
step+=1
writer.close()
# drop_last=True 最后的数据集不够会直接舍弃
# shuffle=True 下一轮会进行打乱洗牌
6 深度学习框架
import torch
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
def forward(self, input):
output=input+1
return output
test = Model()
x=torch.tensor(1.0)
out_put=test(x)
print(out_put)
7 卷积层
在Pytorch中,张量默认采用[N, C, H, W]的顺序
import torch
import torch.nn.functional as F
input_ = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input_=torch.reshape(input_,(1,1,5,5))
kernel=torch.reshape(kernel,(1, 1,3,3))
output=F.conv2d(input_, kernel, stride=1)
print(output)
print(F.conv2d(input_, kernel, stride=2))
stride=1

接着向右移动
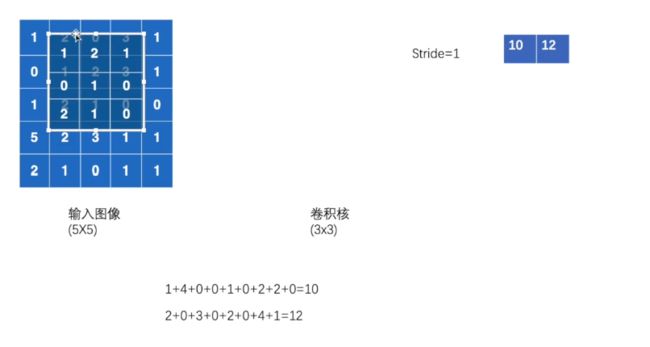
最后
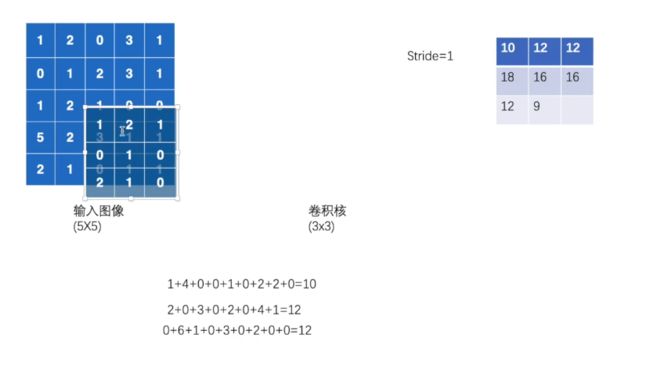
padding=1

使用tensorboard查看
from torch.utils.data import DataLoader
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10(root='./dataset',train=False,download=True,
transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=64)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.cov1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self, x):
x=self.cov1(x)
return x
net=Network()
print(net)
writer=SummaryWriter("logs")
step=0
for data in dataloader:
imgs,labels=data
output=net(imgs)
print(imgs.shape)
# torch.Size([64, 3, 32, 32])
print(output.shape)
writer.add_images("input",imgs,step)
# torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]
output=torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step+=1
8 池化层
最大池化

默认的stride=kernel_size(3)
最大池化:保留主要的特征,减少数据量,加快训练速度
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import MaxPool2d
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# input=torch.tensor([[1, 2, 0, 3, 1],
# [0, 1, 2, 3, 1],
# [1, 2, 1, 0, 0],
# [5, 2, 3, 1, 1],
# [2, 1, 0, 1, 1]],dtype=torch.float32)
data=torchvision.datasets.CIFAR10(root='./dataset',train=False,download=True,
transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(data,batch_size=64)
# print(input.shape)
# input=torch.reshape(input,(-1,1,5,5)) # input (x,x,x,x)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,x):
return self.maxpool1(x)
kk=Network()
# output=kk(input)
# print(output)
writer=SummaryWriter('./logs')
step=0
for data in dataloader:
imgs,labels=data
writer.add_images("input",imgs,step)
output=kk(imgs)
writer.add_images("pool",output,step)
step+=1
writer.close()
9 非线性激活
# -*- coding:utf-8 -*-
import torch
import torch.nn as nn
import torchvision
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
# input_=torch.tensor([[1, -0.5],
# [-1, 3]])
#
# input_=torch.reshape(input_,(-1,1,2,2))
from torch.utils.tensorboard import SummaryWriter
data=torchvision.datasets.CIFAR10(root='./dataset',train=False,download=True,
transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(data,batch_size=64)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.ReLu1=ReLU()
self.sigmoid=Sigmoid()
def forward(self,x):
output_=self.sigmoid(x)
return output_
kk=Network()
# out_=kk(input_)
# print(out_)
writer=SummaryWriter('./logs')
step=0
for data in dataloader:
imgs,labels=data
writer.add_images("input",imgs,global_step=step)
out=kk(imgs)
writer.add_images("out",out,step)
step+=1
writer.close()
10 实战
例子CIFAR-10

# -*- coding:utf-8 -*-
import torch
import torch.nn as nn
from torch.nn import Conv2d, Flatten, Linear
from torch.nn import MaxPool2d
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1=Conv2d(3,32,5,padding=2)
self.maxpool1=MaxPool2d(kernel_size=2)
self.conv2=Conv2d(32,32,5,padding=2)
self.maxpool2=MaxPool2d(kernel_size=2)
self.conv3=Conv2d(32,64,5,padding=2)
self.maxpool3=MaxPool2d(kernel_size=2)
self.flatten=Flatten() # 展平
self.linear1=Linear(1024,64)
self.linear2=Linear(64,10) # 分成十类
def forward(self,x):
x=self.conv1(x)
x=self.maxpool1(x)
x=self.conv2(x)
x=self.maxpool2(x)
x=self.conv3(x)
x=self.maxpool3(x)
x=self.flatten(x)
x=self.linear1(x)
x=self.linear2(x)
return x
nn = Network()
print(nn)
input_=torch.ones((64,3,32,32))
out=nn(input_)
print(out.shape)
也可以直接用Sequential来简化代码
# -*- coding:utf-8 -*-
import torch
import torch.nn as nn
from torch.nn import Conv2d, Flatten, Linear, Sequential
from torch.nn import MaxPool2d
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.model1=Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
nn = Network()
print(nn)
input_=torch.ones((64,3,32,32))
out=nn(input_)
print(out.shape)
也可以用tensorboard展示
writer=SummaryWriter("./logs_seq")
writer.add_graph(nn,input_)
writer.close()
在Terminal输入
tensorboard --logdir=logs_seq
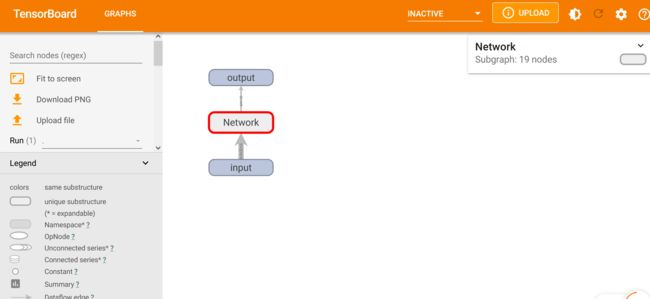
双击Nework可以查看详细内容
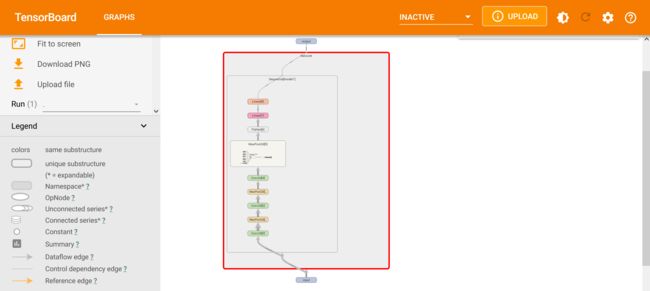
11 损失函数和反向传播
比如nn.L1Loss(相当于机器学习里的MAE)
# -*- coding:utf-8 -*-
import torch
from torch.nn import L1Loss
y=torch.tensor([1.0,2.0,3.0]) # 真实值
y_=torch.tensor([1.1,2.1,3.9]) # 预测值
y=torch.reshape(y,(1,1,1,3)) # 1 batch_size,1 channel 1 行 3 列
y_=torch.reshape(y_,(1,1,1,3))
loss=L1Loss()
res=loss(y,y_)
print(res)
"""
tensor(0.3667)
"""
MSE
loss1=nn.MSELoss()
res=loss1(y,y_)
print(res)
"""
tensor(0.2767)
"""
前面的评估指标都是针对回归问题,下面看一个分类问题
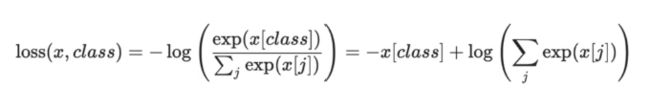
x=torch.tensor([0.1,0.2,0.3])
y=torch.tensor([1])
x = torch.reshape(x,(1,3))
loss_class=nn.CrossEntropyLoss()
res_class=loss_class(x,y)
print(res_class)
"""
tensor(1.1019)
"""

计算网络中的loss
# -*- coding:utf-8 -*-
import torch
import torch.nn as nn
from torch import nn
from torch.nn import Conv2d, Flatten, Linear, Sequential
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
import torchvision
dataset=torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=1)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.model1=Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
nn_w = Network()
loss_class=nn.CrossEntropyLoss()
for data in dataloader:
imgs,labels=data
out=nn_w(imgs)
# print(labels)
# print(out)
res=loss_class(out,labels)
print(res)
有了lossfation接下来就要反向传播了
# -*- coding:utf-8 -*-
import torch
import torch.nn as nn
from torch import nn
from torch.nn import Conv2d, Flatten, Linear, Sequential
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
import torchvision
dataset=torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=1)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.model1=Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
nn_w = Network()
loss_class=nn.CrossEntropyLoss()
for data in dataloader:
imgs,labels=data
out=nn_w(imgs)
# print(labels)
# print(out)
res=loss_class(out,labels)
res.backward() # 在这一行设置断点,debug会发现grad会变化
print("ok")
有了各个节点的梯度,接下来选择合适的优化器,使loss降低

可以看到grad目前是None
12 优化器
基础使用,在torch.optim下
for input, target in dataset:
optimizer.zero_grad() # 梯度重新设置为0,防止上一次的结果的影响
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
要使用torch,必须构造一个优化器对象,该对象将保持当前状态,并根据计算的梯度更新参数
# -*- coding:utf-8 -*-
import torch
import torch.nn as nn
from torch import nn
from torch.nn import Conv2d, Flatten, Linear, Sequential
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
import torchvision
dataset=torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=1)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.model1=Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
nn_w = Network()
loss_class=nn.CrossEntropyLoss()
optim=torch.optim.SGD(nn_w.parameters(),lr=0.01)
for echo in range(20):
running_loss=0.0
for data in dataloader:
imgs,labels=data
out=nn_w(imgs)
# print(labels)
# print(out)
res=loss_class(out,labels)
optim.zero_grad() # 梯度设为0
res.backward()
optim.step()
running_loss += res
print(running_loss)
"""
tensor(18693.3516, grad_fn=)
tensor(16138.8145, grad_fn=)
tensor(15454.3359, grad_fn=)
"""
13 现有网络模型的使用
pytorch为我们提供了一些现有的模型
我们这里使用torchvison里的模型
# -*- coding:utf-8 -*-
import torch
import torch.nn as nn
import torchvision
vgg16_false=torchvision.models.vgg16(pretrained=False) # 不下载权重等参数
vgg16_ture=torchvision.models.vgg16(pretrained=True) # 下载以及在数据集上取得比较好效果的参数w,b
# 保存到C:\Users\lenovo/.cache\torch\hub\checkpoints\vgg16-397923af.pth
print(vgg16_ture)
"""
修改网络模型
"""
vgg16_ture.add_module('add_linear',nn.Linear(1000,10)) # 添加一层
添加到classifier
vgg16_ture.classifier.add_module('linear')
修改某一层
vgg16_ture.classifier[6]=nn.Linear(4096,10)
14 网络模型的读取与保存
import torch
import torchvision
import torch.nn as nn
vgg16=torchvision.models.vgg16(pretrained=False)
# 保存方式1
torch.save(vgg16,"./vgg16_model1.pth")
# 加载模型
model=torch.load("vgg16_model1.pth")
print(model)
第二种方式
torch.save(vgg16.state_dict(),"vgg16_model2.pth") # 只保存网络模型中的参数,以字典的形式
# 加载模型
vgg16=torchvision.models.vgg16(pretrained=False)
dict_=torch.load("vgg16_model2.pth")
vgg16.load_state_dict(dict_)
print(vgg16)
注意保存自己的模型时,如果使用torch.save(),加载模型的时候要导入你之前模型的类,
比如模型写在save_model文件中,加载模型的文件叫read_model,那么要在read_model开头加上
from save_model import *
不然会报错
AttributeError: Can’t get attribute ‘NetWork’ on
15 完整的模型训练流程
以CIFAR10数据集为例,首先准备数据
# -*- coding:utf-8 -*-
import torch
import torchvision
from torch.utils.data import DataLoader
# 准备数据集
train_data=torchvision.datasets.CIFAR10('./dataset',train=True,download=True,
transform=torchvision.transforms.ToTensor())
test_data=torchvision.datasets.CIFAR10('./dataset',train=False,download=True,
transform=torchvision.transforms.ToTensor())
# 数据集的长度
train_data_len=len(train_data)
test_data_len=len(test_data)
print('训练集的数据量:{}'.format(train_data_len))
print("测试集的数据量:{}".format(test_data_len))
"""
训练集的数据量:50000
测试集的数据量:10000
"""
加载数据集
# 利用DataLoader加载数据集
train_data_loader=DataLoader(train_data,batch_size=64)
test_data_loader=DataLoader(test_data,batch_size=64)
搭建神经网络

新建一个model.py文件
# -*- coding:utf-8 -*-
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class NetWork(nn.Module):
def __init__(self):
super(NetWork, self).__init__()
self.model=Sequential(
Conv2d(3,32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,64,kernel_size=5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4,64),
Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
if __name__ =='__main__':
nn_=NetWork()
x=torch.ones((64,3,32,32)) # 64 batch_size,3 channel,32×32
out=nn_(x)
print(out.shape)
在原来的文件开头加上下面这段话,导入model下的NetWork
from model import *
设置优化器
# 优化器
learn_rate=0.01
optimzier=torch.optim.SGD(wan.parameters(),lr=learn_rate) # 要优化的参数, 学习速率
搭建训练流程
# 设置训练网络的一些参数
total_train_step=0 # 训练次数
total_test_step=0 # 测试次数
epoch=10 # 训练的轮数
for i in range(epoch):
print("------------第{}轮训练开始-------------".format(i+1))
# 训练步骤开始
for data in train_data_loader:
imgs,labels=data
out=wan(imgs)
loss=loss_function(out,labels)
# 优化器优化模型
optimzier.zero_grad() # 梯度清0
loss.backward()
optimzier.step()
total_train_step+=1
print("训练次数{},loss={}".format(total_train_step,loss.item()))
item的作用
a=torch.tensor(5)
print(type(a))
print(type(a.item()))
在测试集上验证
for i in range(epoch):
print("------------第{}轮训练开始-------------".format(i+1))
# 训练步骤开始
for data in train_data_loader:
imgs,labels=data
out=wan(imgs)
loss=loss_function(out,labels)
# 优化器优化模型
optimzier.zero_grad() # 梯度清0
loss.backward()
optimzier.step()
total_train_step+=1
if total_train_step % 100==0: # 每训练一百次打印一次loss
print("训练次数{},loss={}".format(total_train_step,loss.item()))
# 测试步骤开始
test_total_loss=0
with torch.no_grad():
for data in test_data_loader:
imgs,labels=data
out=wan(imgs)
loss=loss_function(out,labels)
test_total_loss+=loss
print("整体测试集上的loss={}".format(test_total_loss))
至此模型的训练就基本完成了,下面添加tensorboard观察训练的情况
# -*- coding:utf-8 -*-
import torch
import torchvision
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10('./dataset',train=True,download=True,
transform=torchvision.transforms.ToTensor())
test_data=torchvision.datasets.CIFAR10('./dataset',train=False,download=True,
transform=torchvision.transforms.ToTensor())
# 数据集的长度
train_data_len=len(train_data)
test_data_len=len(test_data)
print('训练集的数据量:{}'.format(train_data_len))
print("测试集的数据量:{}".format(test_data_len))
# 利用DataLoader加载数据集
train_data_loader=DataLoader(train_data,batch_size=64)
test_data_loader=DataLoader(test_data,batch_size=64)
# 搭建神经网络
wan=NetWork()
# 损失函数
loss_function=nn.CrossEntropyLoss()
# 优化器
learn_rate=0.01
optimzier=torch.optim.SGD(wan.parameters(),lr=learn_rate) # 要优化的参数, 学习速率
# 设置训练网络的一些参数
total_train_step=0 # 训练次数
total_test_step=0 # 测试次数
epoch=10 # 训练的轮数
writer=SummaryWriter("./log_model")
for i in range(epoch):
print("------------第{}轮训练开始-------------".format(i+1))
# 训练步骤开始
for data in train_data_loader:
imgs,labels=data
out=wan(imgs)
loss=loss_function(out,labels)
# 优化器优化模型
optimzier.zero_grad() # 梯度清0
loss.backward()
optimzier.step()
total_train_step+=1
if total_train_step % 100==0: # 每训练一百次打印一次loss
print("训练次数{},loss={}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
test_total_loss=0
with torch.no_grad():
for data in test_data_loader:
imgs,labels=data
out=wan(imgs)
loss=loss_function(out,labels)
test_total_loss+=loss
print("整体测试集上的loss={}".format(test_total_loss))
writer.add_scalar("test_loss",test_total_loss,total_test_step)
total_test_step+=1
torch.save(wan,"model_{}.pth".format(i+1)) # 保存每一轮的训练模型
print("模型{}已保存".format(i+1))
writer.close()
可以看出loss一直在减小
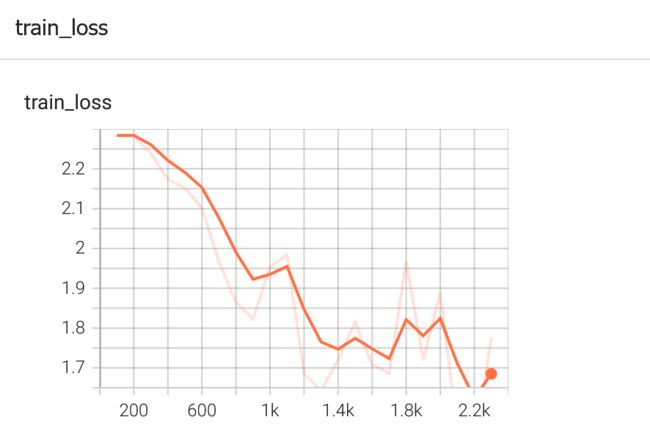
需要注意的一点是pytorch的output是
假设是二分类问题,2 个input
[0.1,0.2] # 第一个样本属于1类和2类的概率分别是多少
[0.3,0.1]
如果你想要计算准确率,可以通过以下方式
out=torch.tensor([[0.5,0.1],
[0.3,0.2]])
print(out.argmax(0)) # 每列最大的下标
# tensor([0, 1])
print(out.argmax(1)) # 每行最大的下标
# tensor([0, 0])
pred=out.argmax(1)
label=torch.tensor([0,1]) # 真实的标签
print((pred==label).sum()/len(label))
完整的代码就是
# -*- coding:utf-8 -*-
import torch
import torchvision
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10('./dataset',train=True,download=True,
transform=torchvision.transforms.ToTensor())
test_data=torchvision.datasets.CIFAR10('./dataset',train=False,download=True,
transform=torchvision.transforms.ToTensor())
# 数据集的长度
train_data_len=len(train_data)
test_data_len=len(test_data)
print('训练集的数据量:{}'.format(train_data_len))
print("测试集的数据量:{}".format(test_data_len))
# 利用DataLoader加载数据集
train_data_loader=DataLoader(train_data,batch_size=64)
test_data_loader=DataLoader(test_data,batch_size=64)
# 搭建神经网络
wan=NetWork()
# 损失函数
loss_function=nn.CrossEntropyLoss()
# 优化器
learn_rate=0.01
optimzier=torch.optim.SGD(wan.parameters(),lr=learn_rate) # 要优化的参数, 学习速率
# 设置训练网络的一些参数
total_train_step=0 # 训练次数
total_test_step=0 # 测试次数
epoch=10 # 训练的轮数
writer=SummaryWriter("./log_model")
for i in range(epoch):
print("------------第{}轮训练开始-------------".format(i+1))
# 训练步骤开始
for data in train_data_loader:
imgs,labels=data
out=wan(imgs)
loss=loss_function(out,labels)
# 优化器优化模型
optimzier.zero_grad() # 梯度清0
loss.backward()
optimzier.step()
total_train_step+=1
if total_train_step % 100==0: # 每训练一百次打印一次loss
print("训练次数{},loss={}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
test_total_loss=0
total_acc=0
with torch.no_grad():
for data in test_data_loader:
imgs,labels=data
out=wan(imgs)
loss=loss_function(out,labels)
test_total_loss+=loss
acc=(out.argmax(1)==labels).sum()
total_acc+=acc
print("整体测试集上的loss={}".format(test_total_loss))
print("整体测试集上的acc={}".format(total_acc/test_data_len))
writer.add_scalar("test_loss",test_total_loss,total_test_step)
total_test_step+=1
torch.save(wan,"model_{}.pth".format(i+1)) # 保存每一轮的训练模型
print("模型{}已保存".format(i+1))
writer.close()
我们发现有些人在训练模型前喜欢加上
wan.train() # 将模块设置为训练模式。
测试模型前加上
wan.eval() #

其实只对一些特定的层有作用,当你的代码里出现这些层时,调用这句
16 利用GPU加速训练
网络模型
数据(输入,标注)
损失函数
.cuda() 再返回即可
比如模型就是wan=wan.cuda()
使用GPU加速的代码
# -*- coding:utf-8 -*-
import torch
import torchvision
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10('./dataset',train=True,download=True,
transform=torchvision.transforms.ToTensor())
test_data=torchvision.datasets.CIFAR10('./dataset',train=False,download=True,
transform=torchvision.transforms.ToTensor())
# 数据集的长度
train_data_len=len(train_data)
test_data_len=len(test_data)
print('训练集的数据量:{}'.format(train_data_len))
print("测试集的数据量:{}".format(test_data_len))
# 利用DataLoader加载数据集
train_data_loader=DataLoader(train_data,batch_size=64)
test_data_loader=DataLoader(test_data,batch_size=64)
# 搭建神经网络
class NetWork(nn.Module):
def __init__(self):
super(NetWork, self).__init__()
self.model=Sequential(
Conv2d(3,32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,64,kernel_size=5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4,64),
Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
wan=NetWork()
if torch.cuda.is_available():
wan=wan.cuda()
# 损失函数
loss_function=nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_function=loss_function.cuda()
# 优化器
learn_rate=0.01
optimzier=torch.optim.SGD(wan.parameters(),lr=learn_rate) # 要优化的参数, 学习速率
# 设置训练网络的一些参数
total_train_step=0 # 训练次数
total_test_step=0 # 测试次数
epoch=10 # 训练的轮数
writer=SummaryWriter("./log_model")
for i in range(epoch):
print("------------第{}轮训练开始-------------".format(i+1))
# 训练步骤开始
wan.train() # 将模块设置为训练模式。
for data in train_data_loader:
imgs,labels=data
if torch.cuda.is_available():
imgs=imgs.cuda()
labels=labels.cuda()
out=wan(imgs)
loss=loss_function(out,labels)
# 优化器优化模型
optimzier.zero_grad() # 梯度清0
loss.backward()
optimzier.step()
total_train_step+=1
if total_train_step % 100==0: # 每训练一百次打印一次loss
print("训练次数{},loss={}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
wan.eval() #
test_total_loss=0
total_acc=0
with torch.no_grad():
for data in test_data_loader:
imgs,labels=data
if torch.cuda.is_available():
imgs=imgs.cuda()
labels=labels.cuda()
out=wan(imgs)
loss=loss_function(out,labels)
test_total_loss+=loss
acc=(out.argmax(1)==labels).sum()
total_acc+=acc
print("整体测试集上的loss={}".format(test_total_loss))
print("整体测试集上的acc={}".format(total_acc/test_data_len))
writer.add_scalar("test_loss",test_total_loss,total_test_step)
total_test_step+=1
torch.save(wan,"model_{}.pth".format(i+1)) # 保存每一轮的训练模型
print("模型{}已保存".format(i+1))
writer.close()
没有GPU的可以使用google Colab ,具体怎么打开这个网站,需要某种方法
使用CPU
训练次数100,loss=2.2980024814605713
训练时间8.45753264427185
使用GPU加速
训练次数100,loss=2.294966459274292
训练时间4.0068957805633545
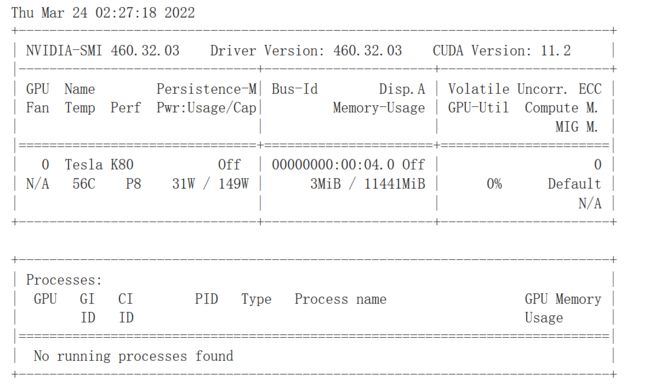
!nvidia-smi 查看显卡的情况
第二种使用使用GPU的方式
.to(device)
device=torch.device(“cuda”)
device=torch.device(“cuda:0”) 指定第一块显卡
device=torch.device(“cuda:1”) 指定第二块显卡
# -*- coding:utf-8 -*-
import torch
import torchvision
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
import time
# 准备数据集
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
# 定义训练的设备
# device=torch.device("cpu")
device=torch.device("cuda:0")
print(device)
train_data=torchvision.datasets.CIFAR10('./dataset',train=True,download=True,
transform=torchvision.transforms.ToTensor())
test_data=torchvision.datasets.CIFAR10('./dataset',train=False,download=True,
transform=torchvision.transforms.ToTensor())
# 数据集的长度
train_data_len=len(train_data)
test_data_len=len(test_data)
print('训练集的数据量:{}'.format(train_data_len))
print("测试集的数据量:{}".format(test_data_len))
# 利用DataLoader加载数据集
train_data_loader=DataLoader(train_data,batch_size=64)
test_data_loader=DataLoader(test_data,batch_size=64)
# 搭建神经网络
class NetWork(nn.Module):
def __init__(self):
super(NetWork, self).__init__()
self.model=Sequential(
Conv2d(3,32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,64,kernel_size=5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4,64),
Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
wan=NetWork()
wan=wan.to(device) # 这里需要注意,其实是可以写成 wan.to(device) 不需要赋值
# 损失函数
loss_function=nn.CrossEntropyLoss()
loss_function=loss_function.to(device) # 这里也一样 loss_function.to(device)
# 优化器
learn_rate=0.01
optimzier=torch.optim.SGD(wan.parameters(),lr=learn_rate) # 要优化的参数, 学习速率
# 设置训练网络的一些参数
total_train_step=0 # 训练次数
total_test_step=0 # 测试次数
epoch=10 # 训练的轮数
writer=SummaryWriter("./log_model")
start_time=time.time()
for i in range(epoch):
print("------------第{}轮训练开始-------------".format(i+1))
# 训练步骤开始
wan.train() # 将模块设置为训练模式。
for data in train_data_loader:
imgs,labels=data
imgs=imgs.to(device)
labels=labels.to(device)
out=wan(imgs)
loss=loss_function(out,labels)
# 优化器优化模型
optimzier.zero_grad() # 梯度清0
loss.backward()
optimzier.step()
total_train_step+=1
if total_train_step % 100==0: # 每训练一百次打印一次loss
end_time=time.time()
print("训练次数{},loss={}".format(total_train_step,loss.item()))
print("训练时间{}".format(end_time-start_time))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
wan.eval() #
test_total_loss=0
total_acc=0
with torch.no_grad():
for data in test_data_loader:
imgs,labels=data
out=wan(imgs)
loss=loss_function(out,labels)
test_total_loss+=loss
acc=(out.argmax(1)==labels).sum()
total_acc+=acc
print("整体测试集上的loss={}".format(test_total_loss))
print("整体测试集上的acc={}".format(total_acc/test_data_len))
writer.add_scalar("test_loss",test_total_loss,total_test_step)
total_test_step+=1
torch.save(wan,"model_{}.pth".format(i+1)) # 保存每一轮的训练模型
print("模型{}已保存".format(i+1))
writer.close()
只有一块显卡的情况下,下面这两条语句相同
device=torch.device("cuda")
device=torch.device("cuda:0")
你可能会见到这种写法
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
这是为了保证代码可以在各类设备上运行
17 进行测试
# -*- coding:utf-8 -*-
import torch
from PIL import Image
import torchvision
from model import *
path='../imgs/dog.png'
image=Image.open(path)
print(image)
image=image.convert('RGB')
# Compose 将多个变换组合在一起
transform=torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
img=transform(image)
print(img.shape)
img=torch.reshape(img,(1,3,32,32))
model=torch.load("model_1.pth")
model.eval()
with torch.no_grad():
out=model(img)
print(out)
print(out.argmax(1))
"""
tensor([6])
"""
查看标签对应的类别

发现预测的并不准确,这是因为模型训练次数太少了,我们换一个训练30次的模型试试,在Google colab上使用GPU训练30次,并把模型下载到本地
# -*- coding:utf-8 -*-
import torch
from PIL import Image
import torchvision
from model import *
path='../imgs/dog.png'
image=Image.open(path)
print(image)
image=image.convert('RGB')
# Compose 将多个变换组合在一起
transform=torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
img=transform(image)
print(img.shape)
img=torch.reshape(img,(1,3,32,32))
model=torch.load("model_GPU30.pth",map_location=torch.device('cpu')) # 将GPU上训练的映射到CPU上
model.eval()
with torch.no_grad():
out=model(img)
print(out)
print(out.argmax(1))
"""
tensor([5])
"""
就比较准确了,使用的图片链接
18 查看开源代码
登录github

比如看一下 junyanz / pytorch-CycleGAN-and-pix2pix
点击train文件,找到下面这句

点一下 TrainOptions

可以看到里面有很多的参数,比如lr学习速率等


可以直接把required删掉,加上default=’./datasets/maps’ 这样就可以在pycharm中右键运行