python创建分类器小结
优质资源分享
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| Python实战微信订餐小程序 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| Python量化交易实战 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
简介:分类是指利用数据的特性将其分成若干类型的过程。
监督学习分类器就是用带标记的训练数据建立一个模型,然后对未知数据进行分类。
一、简单分类器
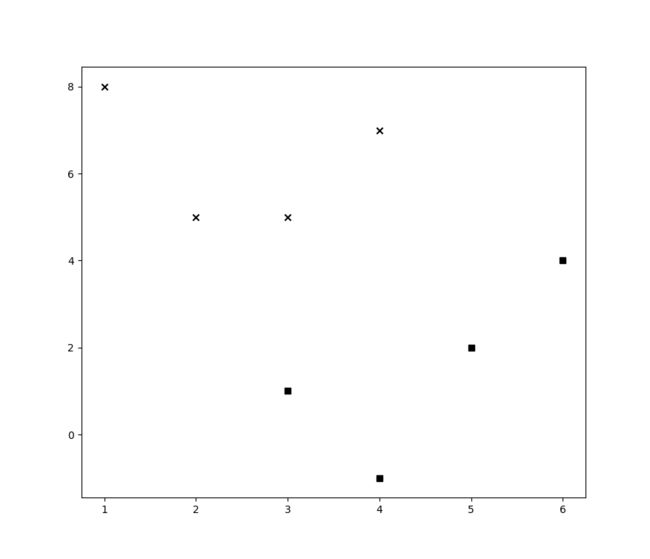
首先,用numpy创建一些基本的数据,我们创建了8个点;
查看代码
X = np.array([[3, 1], [2, 5], [1, 8], [6, 4], [5, 2], [3, 5], [4, 7], [4, -1]])
给这8个点的数据赋予默认的分类标签
查看代码
y = [0, 1, 1, 0, 0, 1, 1, 0]
class_0 = np.array([X[i] for i in range(len(X)) if y[i] == 0])
class_1 = np.array([X[i] for i in range(len(X)) if y[i] == 1])
我们将这些数据画出来看看
查看代码
plt.figure()
# 画散点图 (scatterplot)
plt.scatter(class_0[:, 0], class_0[:, 1], color='black', marker='s')
plt.scatter(class_1[:, 0], class_1[:, 1], color='black', marker='x')
plt.show()
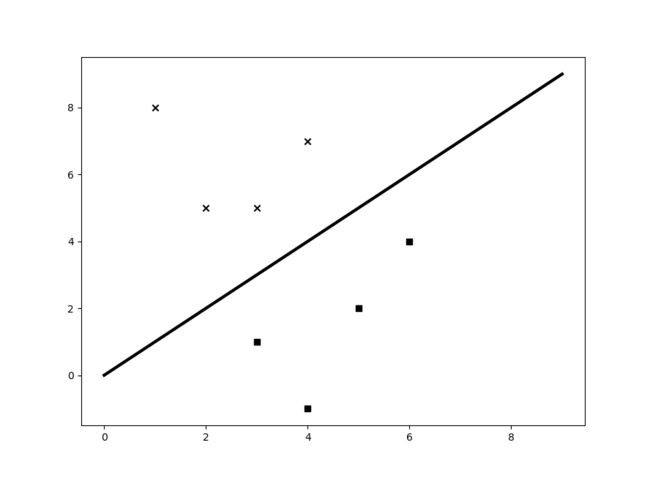
如果我们要对数据加以区分,怎么做呢?让我们增加一条直线,我们用数学公式y=x画出一条直线,构成我们的简单分类器;
查看代码
line_x = range(10)
line_y = line_x
plt.plot(line_x, line_y, color='black', linewidth=3)
plt.show()
二、逻辑回归分类器
逻辑回归虽然名字叫回归,但是其实是一种分类方法,常用于二分类。
逻辑回归利用Sigmoid函数做了分类转换,将结果转换成0和1两类,利用这个性质实现了分类的功能。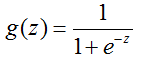
Sigmoid函数是一个S型的函数,当自变量z趋近正无穷时,因变量g(z)趋近于1,而当z趋近负无穷时,g(z)趋近于0,它能够将任何实数映射到(0,1)区间,使其可用于将任意值函数转换为更适合二分类的函数。

下面总结如何用python实现逻辑回归。
首先导入需要的包,包括numpy(计算),matplotlib(画图), sklearn(建模)
查看代码
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import datasets
from sklearn import linear_model
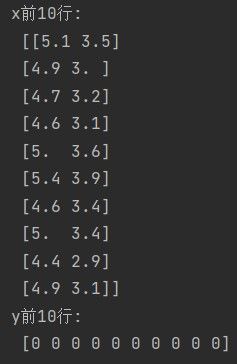
获取鸢尾花数据集(sklarn中自带数据集),指定特征x和目标y,查看数据的前10行
查看代码
iris = datasets.load_iris()
x = iris.data[:, :2]
y = iris.target
print('x前10行:\n', x[:10])
print('y前10行:\n', y[:10])
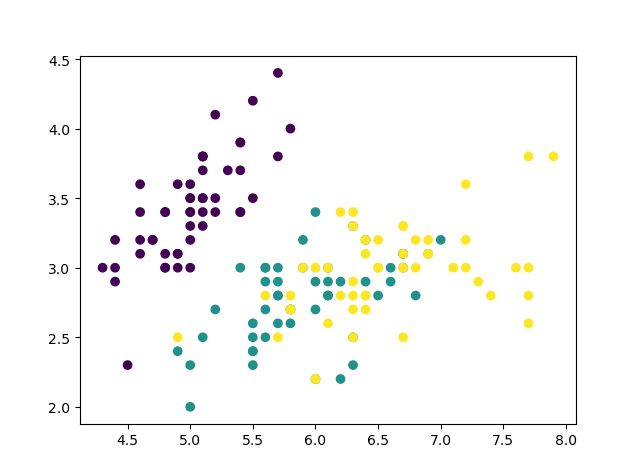
画图查看数据的分布情况,c=y表示使用颜色的顺序,用y中的不同个数来定义不同颜色的数量,这里y总共有3类,所以有3种不同的颜色。
查看代码
plt.figure()
plt.scatter(x[:, 0], x[:, 1], c=y)
plt.show()
初始化逻辑回归分类器,用sklearn中的LogisticRegression模型(简称LR)。其中的重要参数包括, solver 设置求解系统方程的算法类型, C表示正则化强度,值越小正则化强度越高
查看代码
clf = linear_model.LogisticRegression(solver='liblinear', C=1000)
训练分类器,直接用fit方法,传入特征x和目标y
查看代码
clf.fit(X, y)
画出数据的边界。首先定义图形的取值范围,通常是从最小值到最大值,增加了一些余量(buffer),如代码中最小值-1,最大值+1。
画边界的时候用到了网格(grid)数据求解方程的值,然后把边界画出来。
np.c_方法是按行连接两个矩阵,要求两个矩阵的行数相等。(扩展一下,同理,np.r_ 方法就是按列连接两个矩阵,要求两个矩阵的列数相等)
查看代码
x_min, x_max = min(X[:, 0]) - 1.0, max(X[:, 0]) + 1.0
y_min, y_max = min(X[:, 1]) - 1.0, max(X[:, 1]) + 1.0
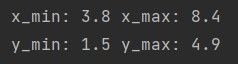
print('x\_min:', x_min, 'x\_max:', x_max)
print('y\_min:', y_min, 'y\_max:', y_max)
# 设置网格步长
step_size = 0.05
# 定义网格
x_values, y_values = np.meshgrid(np.arange(x_min, x_max, step_size), np.arange(y_min, y_max, step_size))
# 展平,连接
x_, y_ = np.c_[x_values.ravel(), y_values.ravel()][:, 0], np.c_[x_values.ravel(), y_values.ravel()][:, 1]
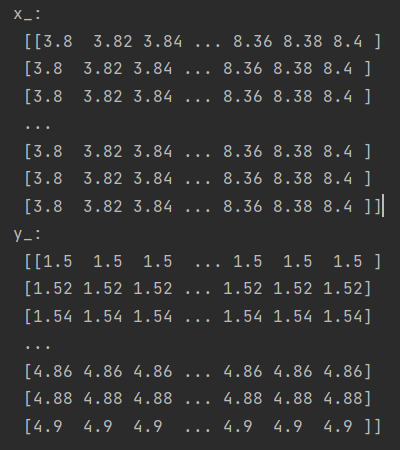
print('x\_: \n', x_)
print('y\_: \n', y_)
查看x_min, x_max 和 y_min, y_max的分布情况:
查看x_ 和 y_ 的数据:
用分类器预测所有点的分类结果
查看代码
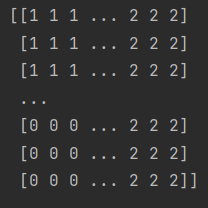
y_pred = clf.predict(np.c_[x_.ravel(), y_.ravel()]).reshape(x_.shape)
print(y_pred)
查看预测结果:
用matplotlib画出各个类型的边界:
查看代码
cmap_light = ListedColormap(['#AAAAFF','#AAFFAA','#FFAAAA'])
plt.figure()
plt.pcolormesh(x_, y_, y_pred, cmap=cmap_light)
plt.xlim(x_.min(), x_.max())
plt.ylim(y_.min(), y_.max())
plt.show()
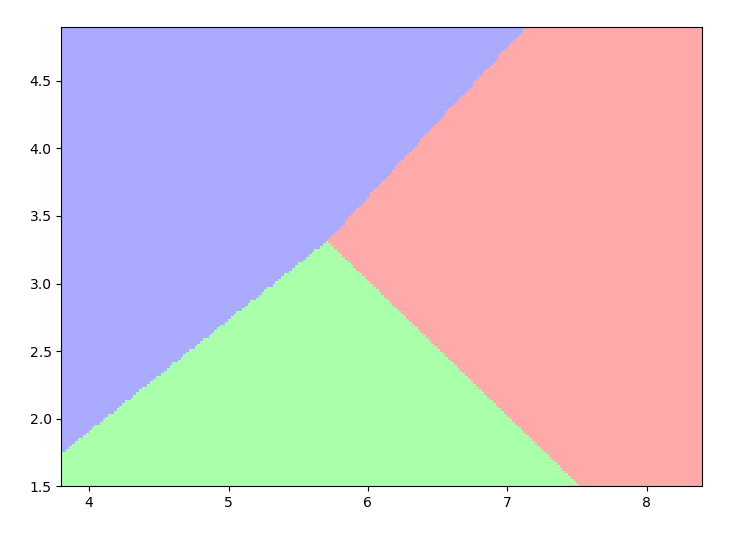
更多的颜色选择可以从颜色清单中找到:https://matplotlib.org/2.0.2/examples/pylab_examples/colours.html
再把训练的数据点也画到图上:
查看代码
plt.scatter(x[:, 0], x[:, 1], c=y)
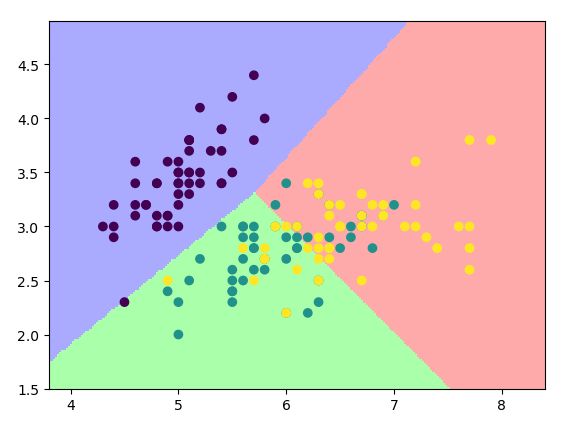
我们把参数C(对错误的惩罚值)调整一下,设置成1,看看效果
查看代码
clf = linear_model.LogisticRegression(solver='liblinear', C=1)
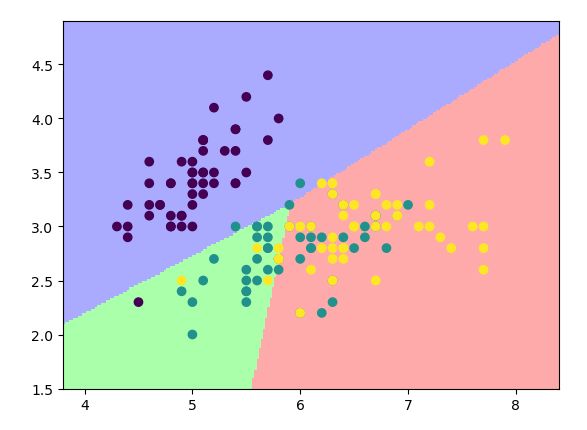
可以看到,分类的效果没有之前的那么好,很多的绿色区域的分类都错误了。
我们可以总结,随着参数C的不断增大,分类错误的惩罚值越高,因此,各个类型的边界更优。
三、朴素贝叶斯分类器
朴素贝叶斯是基于概率论的分类器,利用先验概率推导出后验概率,通过概率值的阈值设定来区分类别。比如将概率>=0.5的定义为类别1,概率<0.5的定义为类别0,这样就通过概率的计算方式实现了分类目的。
朴素贝叶斯分为高斯贝叶斯,伯努利贝叶斯,多项式贝叶斯。不同的贝叶斯基于数据的分布不同进行选择。
高斯贝叶斯用于正式分布的数据,适用于连续数据,例如温度,高度。
伯努利贝叶斯用于二项分布的数据(例如,抛硬币),二项分布又叫做伯努利分布。
多项式贝叶斯用于多项分布的数据(例如,掷骰子)。
下面,我们开始总结用python实现朴素贝叶斯的方法。
首先,导入需要用的包。主要是sklearn中的一些类,包括建模用到的包,构造数据用到的包,数据集划分,交叉验证等。
查看代码
from sklearn.naive_bayes import GaussianNB
from utils.views import plot_classifier, plot_confusion_matrix
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import confusion_matrix, classification_report
我们开始导入数据,使用的是sklarn自带的构造数据的方法(make_classification)。
查看代码
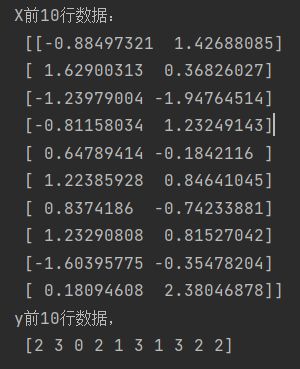
X, y = make_classification(n_samples=2000, n_features=2, n_redundant=0, n_classes=4, n_clusters_per_class=1, random_state=0)
print('X前10行数据: \n', X[: 10])
print('y前10行数据, \n', y[:10])
介绍一下,里面用到的常用参数,包括:
n_samples: 2000个样本
n_features:2个特征
n_redundant:冗余特征数0个
n_classes: 4个类别
n_clusters_per_class:每个簇1个类
random_state: 随机数种子,随便定义,确定随机数种子后,多次反复执行该语句,生成的数据结果是一样的。如果不确定的话,每次生成的数据随机。
查看数据的前10行情况:
查看一下数据的分布情况:
查看代码
plt.Figure()
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
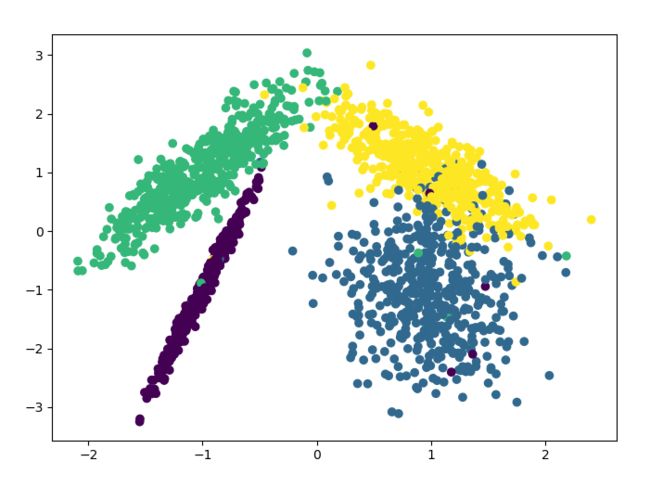
用train_test_split对数据集进行训练集和测试集的划分。
查看代码
X_train, X_test, y_tran, y_test = train_test_split(X, y, test_size=0.25)
其中,test_size = 0.25表示测试集数据占25%,训练集数据占75%。
开始建立朴素贝叶斯模型。
查看代码
clf = GaussianNB()
模型训练,传入特征x和目标值y,这里用的数据都是训练集
查看代码
clf.fit(X_train, y_tran)
预测结果,传入测试集:
查看代码
y_pred = clf.predict(X_test)
将数据划分的结果可视化
查看代码
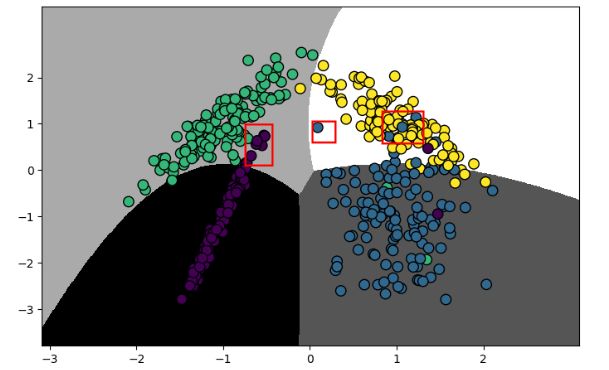
plot_classifier(clf, X_test, y_test)
def plot\_classifier(clf, X, y):
# 定义图形取值范围
x_min, x_max = min(X[:, 0]) - 1.0, max(X[:, 0]) + 1.0
y_min, y_max = min(X[:, 1]) - 1.0, max(X[:, 1]) + 1.0
print('x\_min:', round(x_min, 2), 'x\_max:', round(x_max, 2))
print('y\_min:', round(y_min, 2), 'y\_max:', round(y_max, 2))
# 网格(grid) 数据求解方程的值,画出边界
# 设置网格步长
step_size = 0.01
# 定义网格
x_values, y_values = np.meshgrid(np.arange(x_min, x_max, step_size), np.arange(y_min, y_max, step_size))
# 展平,连接
x_, y_ = np.c_[x_values.ravel(), y_values.ravel()][:, 0], np.c_[x_values.ravel(), y_values.ravel()][:, 1]
# 预测结果
mesh_output = clf.predict(np.c_[x_values.ravel(), y_values.ravel()])
# 数组维度变形
mesh_output = mesh_output.reshape(x_values.shape)
plt.figure()
# 选择配色方案‘
plt.pcolormesh(x_values, y_values, mesh_output, cmap=plt.cm.gray)
plt.scatter(X[:, 0], X[:, 1], c=y, s=80, edgecolors='black', linewidths=1) # cmap=plt.cm.Paired
# 设置图形的取值范围
plt.xlim(x_values.min(), x_values.max())
plt.ylim(y_values.min(), y_values.max())
# 设置x轴与y轴
plt.xticks((np.arange(int(min(X[:, 0]) - 1), int(max(X[:, 0]) + 1), 1.0)))
plt.yticks((np.arange(int(min(X[:, 1]) - 1), int(max(X[:, 1]) + 1), 1.0)))
plt.show()
和逻辑回归时画图的方法一样,借助于网格来确定数据的界限,这里,直接把这个过程提取成一个plot_classifier方法,每次传入模型clf和x,y的值即可。
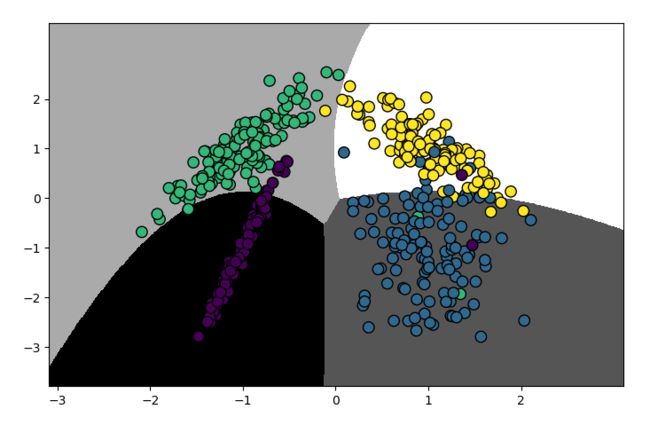
用肉眼查看,感觉分类结果还不错,那么具体结果值是多少呢?我们查看一下准确率,用预测结果和测试集(即真实结果)进行比对
查看代码
accuracy = clf.score(X_test, y_test)
print('accuracy:---', accuracy)
![]()
可以看到准确率有92%,还是不错的。当然这只是训练一次的结果,可能存在一定的偶然性,如果想让结果更具说服力,减少数据切分带来的偶然性,那么,我们可以使用十折交叉验证。
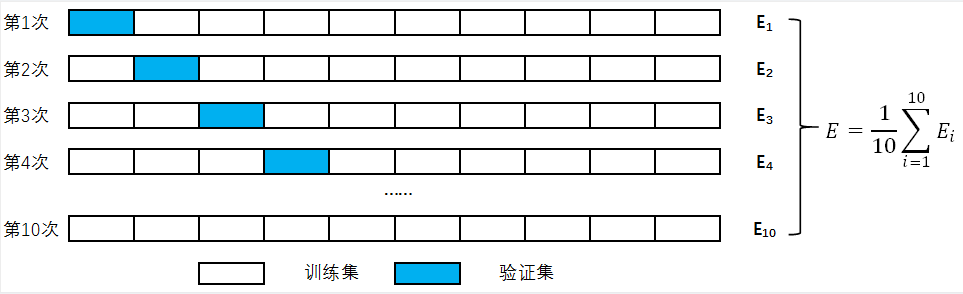
十折交叉验证即每次取训练集中的一份做验证集,其余9份做训练集,然后取最后的结果平均值,作为最终结果的输出。
查看代码
accuracy_cv = cross_val_score(clf, X, y, scoring='accuracy', cv=10)
print('accuracy\_cv:---', round(accuracy_cv.mean(), 2))
f1 = cross_val_score(clf, X, y, scoring='f1\_weighted', cv=10)
print('f1:', round(f1.mean(), 4))
precision = cross_val_score(clf, X, y, scoring='precision\_weighted', cv=10)
print('precision:', round(precision.mean(), 4))
recall = cross_val_score(clf, X, y, scoring='recall\_weighted', cv=10)
print('recall:', round(recall.mean(), 4))
其中cv=10,表示交叉验证10次。scoring=‘accuracy’ 表示输出的结果是准确率,其他的参数还有,f1_weighted(f1分数),precision_weighted(精准率), recall_weighted(召回率)。
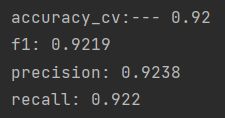
可以看到十次交叉验证的结果准确率也能达到92%,精准率,召回率,f1-score也都在92%左右,表现还是不错的。
我们可以通过混淆矩阵进一步查看,在哪些类别上出错的多一些。
查看代码
confusion_mat = confusion_matrix(y_test, y_pred)
print('confusion\_mat: \n', confusion_mat)
plot_confusion_matrix(confusion_mat)
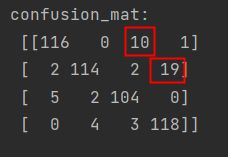
从矩阵中可以看出,第3类和第4类被误判的结果稍多一些,这和从可视化的图上看到的结果是一致的。
对于混淆矩阵,还可以进行可视化
查看代码
plt.imshow(confusion_mat, interpolation='nearest', cmap='gray') # 亮色: cmap=plt.cm.Paired
plt.title('Confusion matrix')
plt.colorbar()
tick_marks = np.arange(4)
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
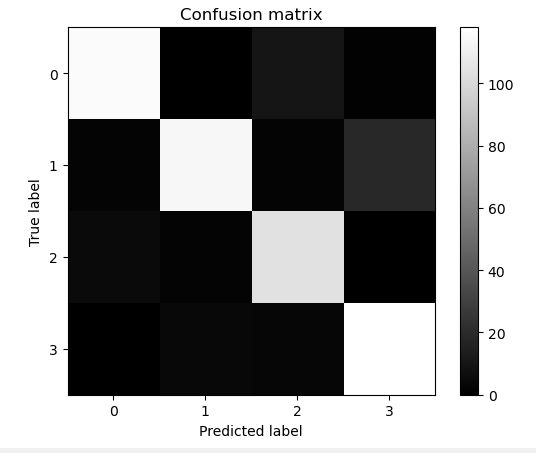
从图中,我们可以看出,对角线的颜色很亮,我们希望的是对角线的颜色越亮越好,在非对角线的区域如果全部是黑色,表示没有错误;如果有灰色区域,那么表示分类错误的样本量。从混淆矩阵的可视化图中,我们可以看到下标2(即第3类)和下标3(即第4类)存在灰色区域,说明第3类和第4类存在分类错误的情况。
sklearn类还内置了性能报告,我们可以直接用classification_report方法进行提取查看算法的分类效果。
查看代码
target_names = ['Class-0', 'Class-1', 'Class-2', 'Class-3']
report = classification_report(y_test, y_pred, target_names=target_names)
print(report)
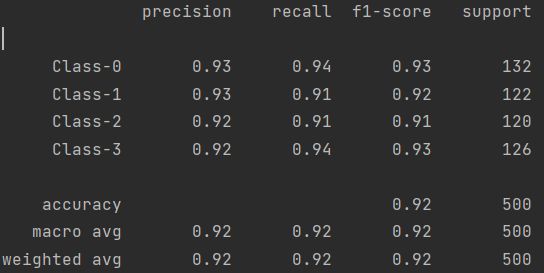
报告中最后一列support表示的是样本数,总的样本数为2000个,我们设置了0.25比例的训练集,那么训练数就有500个,132,122,120,126则表示每一类的样本数,加起来总共也是500个。
以上,用的是高斯叶斯分类器的训练和预测结果,我们也可以用伯努利贝叶斯看看结果如何。
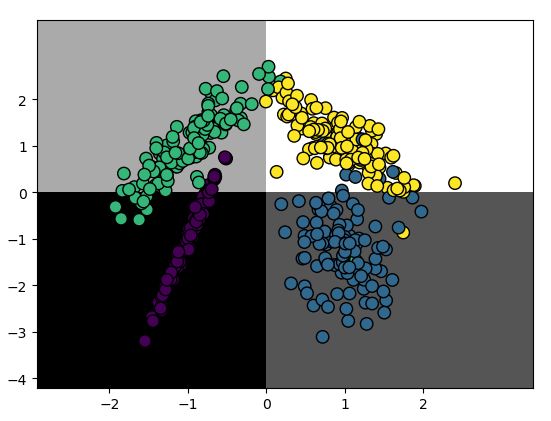
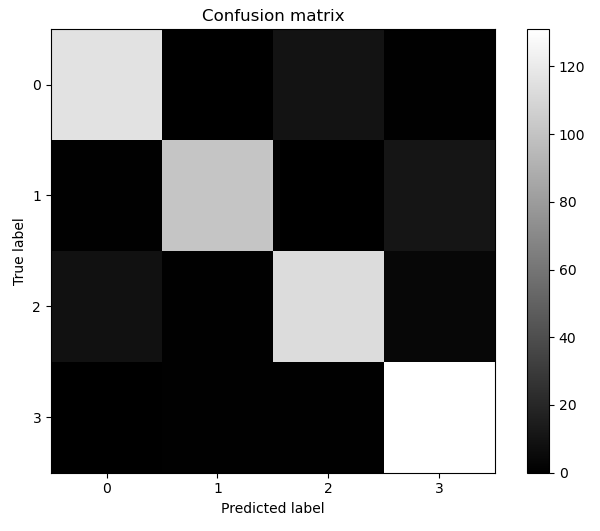
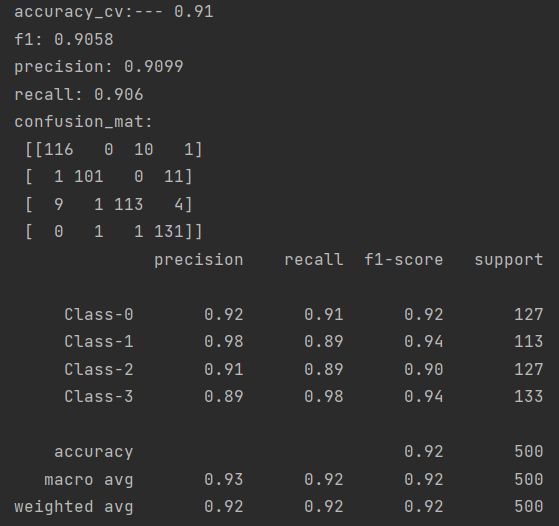
我们可以看到,对于这个数据集,第1类分错的情况变多了,从混淆矩阵的可视化图中,看到有灰色的矩阵出现,从报告中看出precision从93%降低到了92%,第4类分类错误也变多,由92%降低到了89%。这样导致整体的平均precision由92%降低到了90%,不过对于第2类的分类准确率是提高了,92%提高到了98%。
四、分类器案例:根据汽车特征评估质量
需求分析:根据汽车的特征进行训练,得到训练模型,用模型预测具体某辆汽车的质量情况。
数据分析:
目标:「汽车质量」,(unacc,ACC,good,vgood)分别代表(不可接受,可接受,好,非常好)
6个属性变量分别为:
「买入价」buying:取值范围是vhigh、high、med、low
「维护费」maint:取值范围是vhigh,high,med,low
「车门数」doors:取值范围 2,3,4,5more
「可容纳人数」persons:取值范围2,4, more
「后备箱大小」lug_boot: 取值范围 small,med,big
「安全性」safety:取值范围low,med,high
值得一提的是6个属性变量全部是有序类别变量,比如「可容纳人数」值可为「2,4,more」,「安全性」值可为「low, med, high」
查看数据分布情况:

导入必要的包,包括sklearn(建模,交叉验证,学习曲线), numpy(计算), matplotlib(画图):
查看代码
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, validation_curve
import numpy as np
from utils.views import plot_curve
import pandas as pd
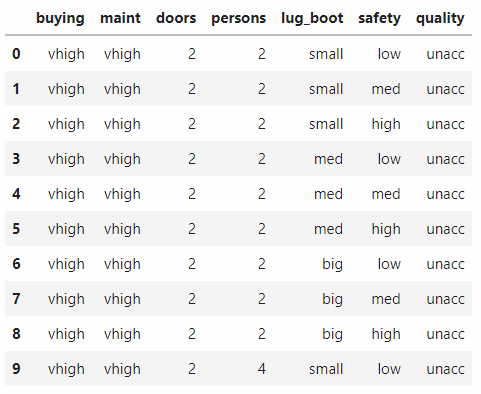
加载数据:
查看代码
input\_file = 'data/car.data.txt'
df = pd.read_table(input_file, header=None, sep=',')
df.rename(columns={0:'buying', 1:'maint', 2:'doors', 3:'persons', 4:'lug\_boot', 5:'safety', 6:'quality'}, inplace=True)
df.head(10)
将字符串转换成数值:
查看代码
label_encoder = []
for i in range(df.shape[1]):
label_encoder.append(preprocessing.LabelEncoder())
df.iloc[:, i] = label_encoder[-1].fit_transform(df.iloc[:, i])
df.head(10)
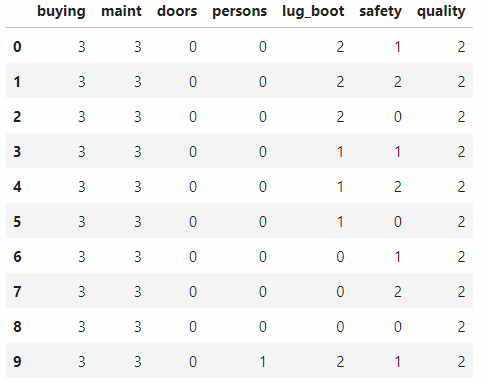
提取特征X和目标值y
查看代码
X = df.iloc[:, :-1]
y = df.iloc[:, -1]
接下来训练分类器,这里我们使用随机森林分类器
查看代码
params = {
'n\_estimators': 200,
'max\_depth': 8,
'random\_state': 7
}
clf = RandomForestClassifier(**params)
clf.fit(X, y)
接下来开始验证模型的效果,采用十折交叉验证。注意,用十折交叉验证的时候就不需要做数据集的划分,直接用全量数据集即可。
查看代码
accuracy = cross_val_score(clf, X, y, scoring='accuracy', cv=10)
print('accuracy:', round(accuracy.mean(), 3))
![]()
建立分类器的目的就是对孤立的未知数据进行分类,下面对单一数据点进行分类。
查看代码
input_data = ['low', 'vhigh', '2', '2', 'small', 'low']
input_data_encoded = [-1] * len(input_data)
for i, item in enumerate(input_data):
input_data_encoded[i] = int(label_encoder[i].transform([input_data[i]]))
input_data_encoded = np.array(input_data_encoded)
print(input_data_encoded)
将单一数据由字符串类型转换成数值类型:
![]()
预测数据点的输出类型:
查看代码
output_class = clf.predict(input_data_encoded.reshape(1, -1))
print('output class:', label_encoder[-1].inverse_transform(output_class)[0])
![]()
用predict进行预测输出,输出的是数值编码,显然是看不懂具体的含义的,需要用inverse_transform对标记编码进行解码,转换成原来的形式。
参数调优
通过生成验证曲线,网格搜索进行参数的调优。
我们对 n_estimators(弱学习器的个数) 这个参数,太小容易欠拟合,太大容易过拟合。
查看代码
parameter_grid = np.linspace(25, 200, 8).astype(int)
train_scores, validation_scores = validation_curve(clf, X, y, param_name='n\_estimators',
param_range=parameter_grid, cv=5)
print('\n ##### VALIDATION CURVES #####')
print('\nParam: n\_estimators \n Training scores: \n', train_scores)
print('\nParam: n\_estimators \n Validation scores:\n', validation_scores)
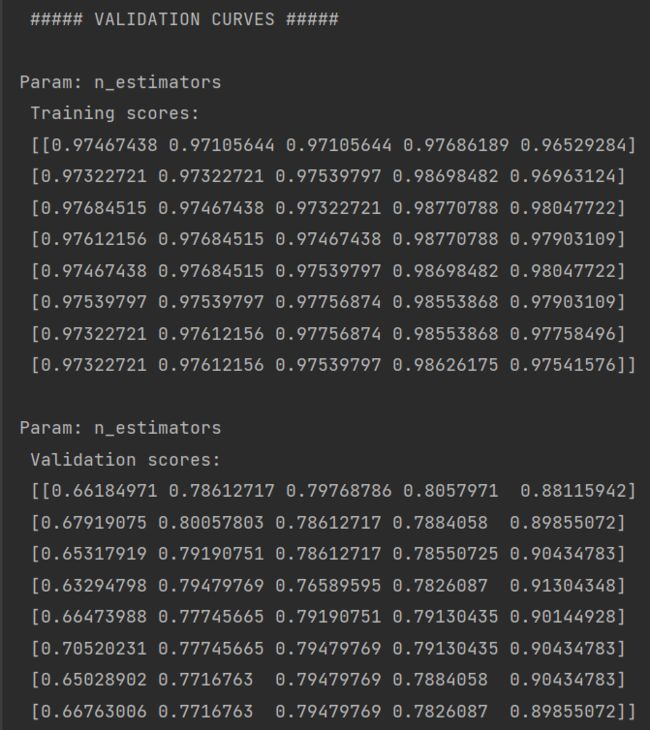
验证曲线画图:
查看代码
plt.figure()
plt.plot(parameter_grid, 100 * np.average(train_scores, axis=1), color='black')
plt.title('Training curve')
plt.xlabel( 'Number of estimators')
plt.ylabel('Accuracy')
plt.show()
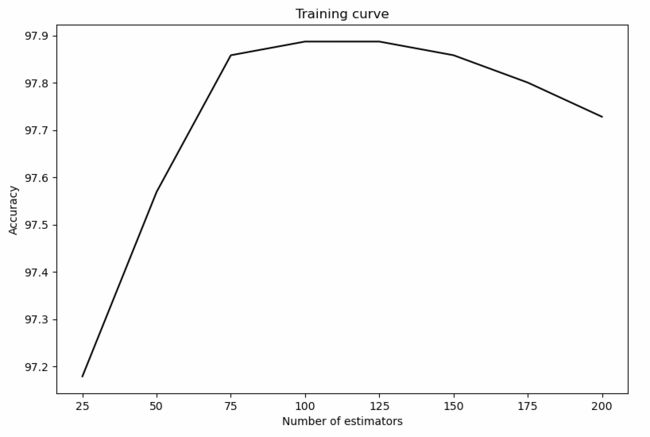
由图可以看出,estimate在100附近,达到最大的准确率。
同理对max_depth生成验证曲线。
查看代码
max_depth_grid = np.linspace(2, 10, 5).astype(int)
train_scores, validation_scores = validation_curve(clf, X, y, param_name='max\_depth',
param_range=max_depth_grid, cv=5)
plot_curve(max_depth_grid, train_scores, 'Validation curve', 'Maximum depth of the tree')
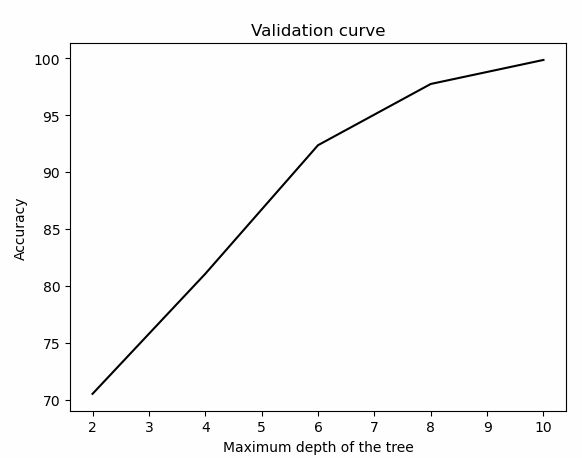
可以看出,max_depth在10附近,准确率达到最大值。
生成学习曲线
学习曲线可以帮助我们理解训练数据集的大小对机器学习模型的影响。当计算能力限制的时候,这点非常有用。下面改变训练数据集的大小,绘制学习曲线。
查看代码
parameter_grid = np.array([200, 500, 800, 1100])
train_size, train_scores, validation_scores = learning_curve(clf, X, y, train_sizes=parameter_grid, cv=10)
print('\n ##### LEARNING CURVES #####')
print('\n Training scores: \n', train_scores)
print('\n Validation scores:\n', validation_scores)
plot_curve(parameter_grid, train_scores, 'Learning curve', 'Number of training samples')
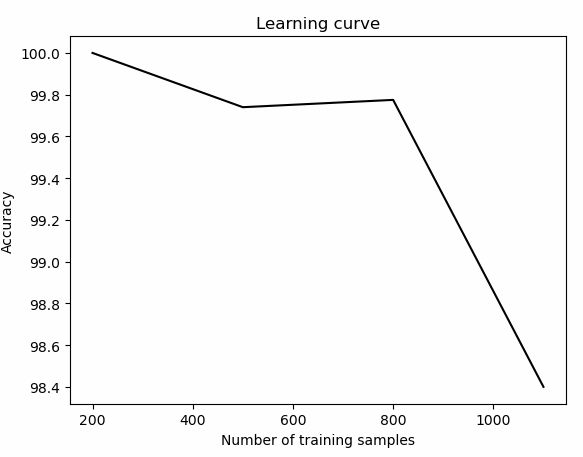
可以看到训练的数据集规模越小,训练的准确率越高。
但是,这样也会容易造成一个问题,那就是过拟合。如果选择规模较大的数据集,会消耗更多的资源,所以训练集的规模选择是一个结合计算能力需要综合考虑的问题。
以上用到数据集下载:
car.data.txt: https://url87.ctfile.com/f/21704187-595799592-6f0749?p=7287 (访问密码: 7287)