SpringCloud微服务全家桶
SpringCloud微服务全家桶
- 1、单体架构
-
- 单体架构示意图
- 单体架构的优缺点
-
- 优点
- 缺点
- 2、微服务概述
-
- 微服务
- 微服务架构
- 技术维度理解
- 微服务的优缺点
- 微服务技术栈有哪些?
- 3、springcloud入门
-
- 官网说明
- SpringCloud=分布式微服务架构下的一站式解决方案
- SpringCloud和SpringBoot是什么关系
- Dubbo和SpringCloud
- CAP理论
- SpringCloud国内使用情况
-
- 国内
- 4、Rest微服务构建案例工程模块
-
- 创建工程
-
- pom父工程
- Eureka
- 微服务注册与发现
- 注册中心Eureka
-
- 原理
- Eureka服务搭建
- 创建search服务
- 通过restTemplate访问服务
- Eureka安全性
-
- 实现安全认证
- 什么是自我保护模式?
- Eureka的高可用
- Eureka启动细节:
- 作为服务注册中心,Eureka比Zookeeper好在哪里
- 5、Ribbon负载均衡
-
- Ribbon概述
- 能干什么?
- Ribbon配置初步
- Ribbon配置自定义负载均衡策略:
-
- 注解方式
- 配置文件制定方式—制定具体服务的负载均衡策略
- 6、服务间的调用-Feign
-
- 引言
- 快速入门
- Feign传递参数
-
- 注意事项
- 示例
- Callback机制
-
- 引言
- 实现
- Customer没有报错信息?使用FallbackFactory
- 7、服务隔离及断路器-hystrix
-
- 引言
- 降级机制实现:
- 线程隔离
- 断路器原理
- 8、新一代网关-Gateway
-
- 关于zuul和Gateway
- Gateway基本介绍
- Gateway配置
- 动态路由
- 断言-predicates
- 路由过滤器-filter
1、单体架构
一个归档包(可以是JAR、WAR、EAR或其它归档格式)包含所有功能的应用程序,通常称为单体应用是将开发好的项目打成war包,然后发布到tomcat等容器中的应用。
单体架构示意图
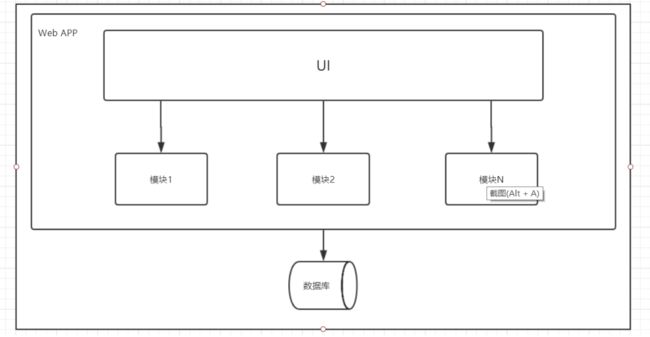
单体架构的优缺点
优点
便于共享:单个归档文件包含所有功能,便于在团队之间以及不同的部署阶段之间共享。
易于测试:单体应用一旦部署,所有的服务或特性就都可以使用了,这简化了测试过程,因为没有额外的依赖,每项测试都可以在部署完成后立刻开始。
易于部署:只需将单个归档文件复制到单个目录下。
缺点
复杂性高:由于是单个归档文件,所以整个项目文件包含的模块非常多,导致模块的边界模糊、依赖关系不清晰、代码的质量参差不齐,混乱的堆在一起,使得整个项目非常复杂。以致每次修改代码,都非常小心,可能添加一个简单的功能,或者修改一个Bug都会带来隐藏的缺陷。
技术债务:随着时间的推移、需求的变更和技术人员的更替,会逐渐形成应用程序的技术债务,并且越积越多。
扩展能力受限:单体应用只能作为一个整体进行扩展,无法根据业务模块的需要进行伸缩。
阻碍技术创新:对于单体应用来说,技术是在开发之前经过慎重评估后选定的,每个团队成员都必须使用相同的开发语言、持久化存储及消息系统。
2、微服务概述

微服务
强调的是服务的大小,它关注的是某一个点,是具体解决某一个问题/提供落地对应服务的一个服务应用,
狭意的看,可以看作Eclipse里面的一个个微服务工程/或者Module。
(医院里有骨科就只看骨科的病,外科只看外科,它强调的单个)
微服务架构
微服务架构是⼀种架构模式,它提倡将单⼀应⽤程序划分成⼀组⼩的服务,服务之间互相协调、互相配合,为⽤户提供最终价值。每个服务运⾏在其独⽴的进程中,服务与服务间采⽤轻量级的通信机制互相协作(通常是基于HTTP协议的RESTful API)。每个服务都围绕着具体业务进⾏构建,并且能够被独⽴的部署到⽣产环境、类⽣产环境等。另外,应当尽量避免统⼀的、集中式的服务管理机制,对具体的⼀个服务⽽⾔,应根据业务上下⽂,选择合适的语⾔、⼯具对其进⾏构建。
(骨科—外科—眼鼻手科–。。。。形成了一医院的架构模式,它强调的是一个整体)

技术维度理解
微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底 地去耦合,每一个微服务提供单个业务功能的服务,一个服务做一件事, 从技术角度看就是一种小而独立的处理过程,类似进程概念,能够自行单独启动 或销毁,拥有自己独立的数据库。
微服务的优缺点


微服务技术栈有哪些?

3、springcloud入门
官网说明

SpringCloud,基于SpringBoot提供了一套微服务解决方案,包括服务注册与发现,配置中心,全链路监控,服务网关,负载均衡,熔断器等组件,除了基于NetFlix的开源组件做高度抽象封装之外,还有一些选型中立的开源组件。
SpringCloud利用SpringBoot的开发便利性巧妙地简化了分布式系统基础设施的开发,SpringCloud为开发人员提供了快速构建分布式系统的一些工具,包括配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等,它们都可以用SpringBoot的开发风格做到一键启动和部署。
SpringBoot并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过SpringBoot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
SpringCloud=分布式微服务架构下的一站式解决方案
是各个微服务架构落地技术的集合体,俗称微服务全家桶;
SpringCloud和SpringBoot是什么关系
SpringBoot专注于快速方便的开发单个个体微服务。
SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来,
为各个微服务之间提供,配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等集成服务
SpringBoot可以离开SpringCloud独立使用开发项目,但是SpringCloud离不开SpringBoot,属于依赖的关系.
SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架。
Dubbo和SpringCloud
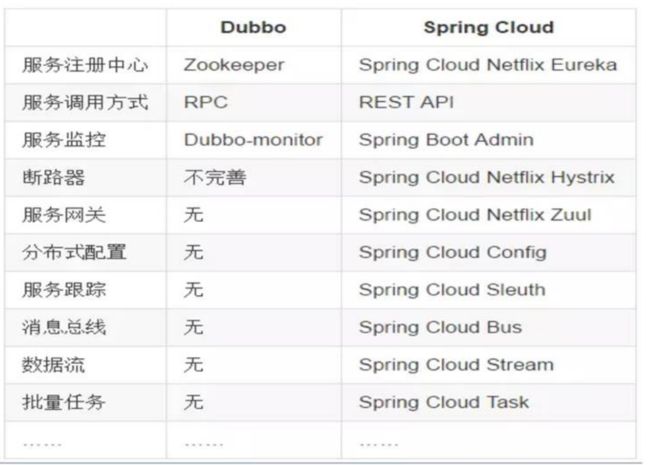
最大区别:SpringCloud抛弃了Dubbo的RPC通信,采用的是基于HTTP的REST方式。
严格来说,这两种方式各有优劣。虽然从一定程度上来说,后者牺牲了服务调用的性能,但也避免了上面提到的原生RPC带来的问题。而且REST相比RPC更为灵活,服务提供方和调用方的依赖只依靠一纸契约,不存在代码级别的强依赖,这在强调快速演化的微服务环境下,显得更加合适。
CAP理论
CAP理论作为分布式系统的基础理论,它描述的是一个分布式系统在以下三个特性中:
一致性(Consistency)
可用性(Availability)
分区容错性(Partition tolerance)
最多满足其中的两个特性。也就是下图所描述的。分布式系统要么满足CA,要么CP,要么AP。无法同时满足CAP。
I. 什么是 一致性、可用性和分区容错性
分区容错性:指的分布式系统中的某个节点或者网络分区出现了故障的时候,整个系统仍然能对外提供满足一致性和可用性的服务。也就是说部分故障不影响整体使用。
事实上我们在设计分布式系统是都会考虑到bug,硬件,网络等各种原因造成的故障,所以即使部分节点或者网络出现故障,我们要求整个系统还是要继续使用的
(不继续使用,相当于只有一个分区,那么也就没有后续的一致性和可用性了)
可用性: 一直可以正常的做读写操作。简单而言就是客户端一直可以正常访问并得到系统的正常响应。用户角度来看就是不会出现系统操作失败或者访问超时等问题。
一致性:在分布式系统完成某写操作后的任何读操作,都应该获取到该写操作写入的那个最新的值。相当于要求分布式系统中的各节点时时刻刻保持数据的一致性。
Zookeeper—>CP: 不能保证每次服务请求都是可达的。在使用 Zookeeper 获取服务列表时,如果 Zookeeper 集群中的 Leader 宕机了,该集群就要进行 Leader 的选举,选举是需要时间的,期间无法处理请求。又或者 Zookeeper 集群中半数以上服务器节点不可用,那么将无法处理该请求。所以说,Zookeeper 不能保证服务可用性。
Eureka—>AP: Eureka Server 采用的是Peer to Peer 对等通信。这是一种去中心化的架构,无 master/slave 之分,每一个 Peer 都是对等的。在这种架构风格中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的 serviceUrl 指向其他节点。每个节点都可被视为其他节点的副本。在集群环境中如果某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点上,当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会在节点间进行复制(replicate To Peer)操作,将请求复制到该 Eureka Server 当前所知的其它所有节点中。Eureka牺牲了其一致性来保证系统服务的高可用性。
SpringCloud国内使用情况
国内

4、Rest微服务构建案例工程模块
创建工程
pom父工程
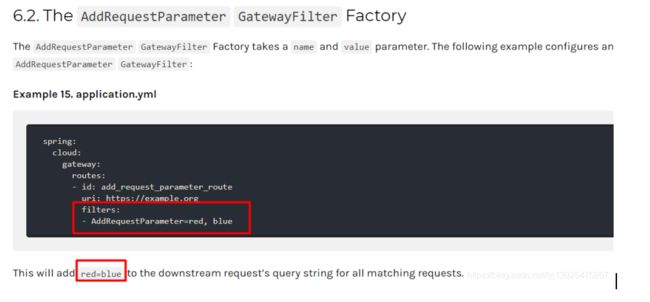
添加最新版依赖:Hoxton.SR8,暂时不加入其他任何依赖和插件
<properties>
<java.version>1.8java.version>
<spring.cloud-version>Hoxton.SR8spring.cloud-version>
properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-dependenciesartifactId>
<version>${spring.cloud-version}version>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
Eureka

微服务注册与发现

由上图可以看出:
1、服务提供者将服务注册到注册中心
2、服务消费者通过注册中心查找服务
3、查找到服务后进行调用(这里就是无需硬编码url的解决方案)
4、服务的消费者与服务注册中心保持心跳连接,一旦服务提供者的地址发生变更时,注册中心会通知服务消费者
注册中心Eureka

原理
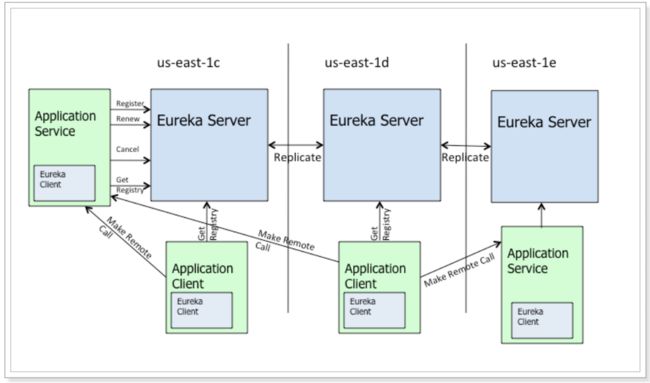
Eureka包含两个组件:Eureka Server和Eureka Client。
Eureka Server提供服务注册服务,各个节点启动后,会在Eureka Server中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。
Eureka Client是一个java客户端,用于简化与Eureka Server的交互,客户端同时也就别一个内置的、使用轮询(round-robin)负载算法的负载均衡器。
在应用启动后,将会向Eureka Server发送心跳,默认周期为30秒,如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把这个服务节点移除(默认90秒)。
Eureka Server之间通过复制的方式完成数据的同步,Eureka还提供了客户端缓存机制,即使所有的Eureka Server都挂掉,客户端依然可以利用缓存中的信息消费其他服务的API。综上,Eureka通过心跳检查、客户端缓存等机制,确保了系统的高可用性、灵活性和可伸缩性。
Eureka服务搭建
创建子模块:pom
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-serverartifactId>
dependency>
dependencies>

创建application.yml,添加配置:
server:
port: 8761 #服务端口号
eureka:
instance:
hostname: localhost #服务主机
client:
#当前的Eureka服务是单机版的
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
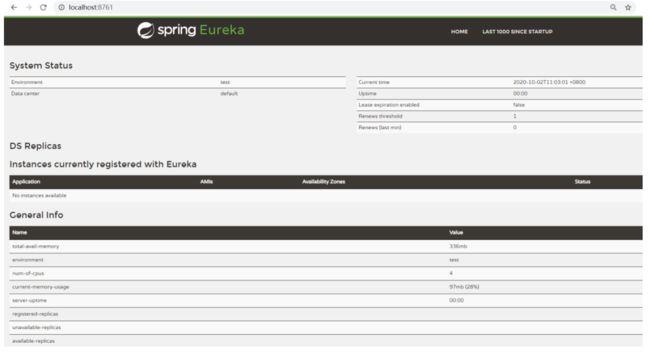
启动服务,看到这个效果表示服务注册中心可以用:
创建Eureka client:
1.创建maven工程,改为springboot
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
2.导入依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
3.启动类添加注解
@EnableEurekaClient
4.编写配置文件
#指定Eureka服务地址
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
#指定服务的名称
spring:
application:
name: CUSTOMER
刷新服务页面:

创建search服务

通过restTemplate访问服务
1.search模块添加SearchController接口,通过customer模块调用该接口

2.customer模块添加CustomerController接口,使用restTemplate访问search接口
简单化,在启动类中注入bean
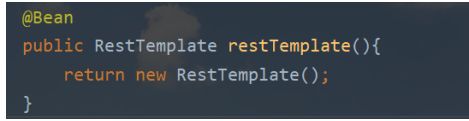
使用eurekaClient拿到search服务信息,再使用restTemplate访问:


Eureka安全性
实现安全认证
1.Eureka模块导入依赖
>
>org.springframework.boot >
>spring-boot-starter-security >
>
2.编写配置类
@EnableWebSecurity
class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http.csrf().ignoringAntMatchers("/eureka/**");//忽略eureka服务的同源控制
super.configure(http);
}
}
3.编写配置文件
spring:
security:
user:
name: root
password: root
重启Eureka服务,访问页面:



什么是自我保护模式?
默认情况下,如果EurekaServer在一定时间内没有接收到某个微服务实例的心跳,EurekaServer将会注销该实例(默认90秒)。但是当网络分区故障发生时,微服务与EurekaServer之间无法正常通信,以上行为可能变得非常危险了——因为微服务本身其实是健康的,此时本不应该注销这个微服务。Eureka通过“自我保护模式”来解决这个问题——当EurekaServer节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。一旦进入该模式,EurekaServer就会保护服务注册表中的信息,不再删除服务注册表中的数据(也就是不会注销任何微服务)。当网络故障恢复后,该Eureka Server节点会自动退出自我保护模式。
在自我保护模式中,Eureka Server会保护服务注册表中的信息,不再注销任何服务实例。当它收到的心跳数重新恢复到阈值以上时,该Eureka Server节点就会自动退出自我保护模式。它的设计哲学就是宁可保留错误的服务注册信息,也不盲目注销任何可能健康的服务实例。一句话讲解:好死不如赖活着
综上,自我保护模式是一种应对网络异常的安全保护措施。它的架构哲学是宁可同时保留所有微服务(健康的微服务和不健康的微服务都会保留),也不盲目注销任何健康的微服务。使用自我保护模式,可以让Eureka集群更加的健壮、稳定
在Spring Cloud中,可以使用eureka.server.enable-self-preservation = false 禁用自我保护模式。
![]()
Eureka的高可用

Eureka启动细节:

作为服务注册中心,Eureka比Zookeeper好在哪里
作为服务注册中心,Eureka比Zookeeper好在哪里
著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)。由于分区容错性P在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。
因此
Zookeeper保证的是CP,
Eureka则是AP。
4.1 Zookeeper保证CP
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
4.2 Eureka保证AP
Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
因此, Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
5、Ribbon负载均衡
Ribbon概述
比如我们作为消费方去买东西结帐,1号收银台10个 ,2号收银台8人,3号收银台2人 ,那这个消费者自己会去3号收银台排队,实现负载均衡
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。
简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法,将Netflix的中间层服务连接在一起。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。简单的说,就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。
能干什么?
LB,即负载均衡(Load Balance),在微服务或分布式集群中经常用的一种应用。
负载均衡简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA(高可用)。
常见的负载均衡有软件Nginx,LVS,硬件 F5等。
相应的在中间件,例如:dubbo和SpringCloud中均给我们提供了负载均衡,SpringCloud的负载均衡算法可以自定义。
Ribbon配置初步
1.启动两个search模块
复制一个启动配置,vmoption加入参数:-Dserver.port=8082

2.Customer模块导入ribbon依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-ribbonartifactId>
dependency>
3.配置整合RestTemplate和ribbon
启动类RestTemplate的@Bean下添加注解:@LoadBalance;
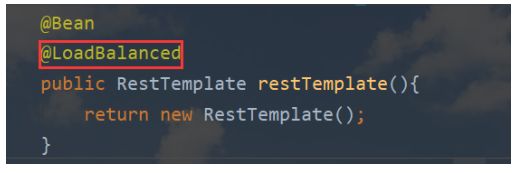
4.Customer中访问search,查看效果
调用不再需要EurekaClient,直接使用服务名获取服务信息
@GetMapping("/customer")
public String customer() {
String result = restTemplate.getForObject("http://SEARCH/search",String.class);
return result;
}

Ribbon配置自定义负载均衡策略:
1.RandomRule:随机策略
2.RoundRobbinRule:轮询策略
3.WeightedResourceTimeRule:默认采用轮询,后续会根据服务的响应时间,自动分配权重
4.BestAvailableRule:根据被调用方并发最小的分配
注解方式
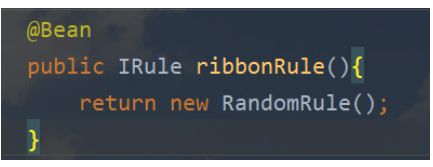
配置文件制定方式—制定具体服务的负载均衡策略

6、服务间的调用-Feign
引言
Feign可以实现让我们面向接口编程,直接调用其他服务,简化开发
快速入门
1.Customer模块导入依赖
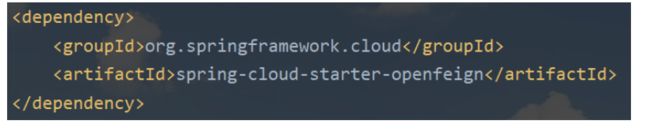
2.添加一个注解

3.创建一个接口,和search模块映射

4.测试
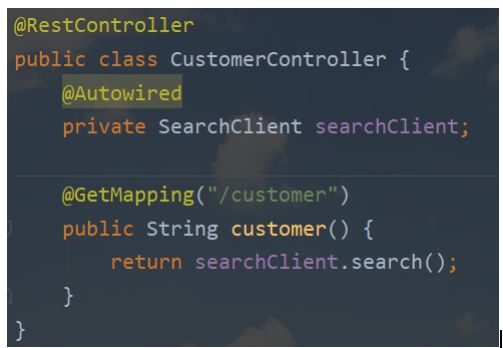
Feign传递参数
注意事项
1.如果是复杂类型参数,默认采用post方式
2.传递单个参数,推荐使用@PathVariable;多个参数,可以使用@RequestParam,不省略value属性
3.传递对象信息,统一采用json方式,要添加@RequestBody注解
4.Client接口要使用@RequestMapping注解
示例
1.Search模块添加几个接口:
先创建一个pojo
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Customer {
private Integer id;
private String name;
private Integer age;
}
添加几个接口:
@GetMapping("/search/{id}")
public Customer findById(@PathVariable Integer id){
return new Customer(id,"张三",22);
}
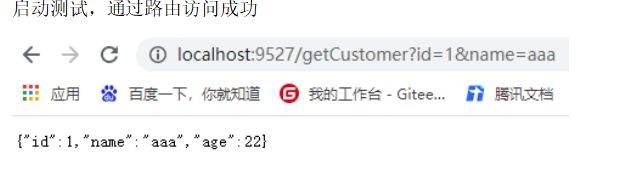
@GetMapping("/getCustomer")
public Customer getCustomer(@RequestParam Integer id,@RequestParam String name){
return new Customer(id,name,22);
}
@GetMapping("/save") //会自动转为post请求 405
public Customer save(Customer customer){
return customer;
}
测试访问没有问题。
Customer封装client
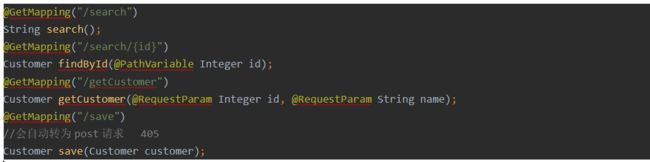
修改为client访问:

测试三个接口,前两个没有问题,第三个出错:
feign.FeignException$MethodNotAllowed: [405] during [GET] to [http://SEARCH/save] [SearchClient#save(Customer)]: [{“timestamp”:“2021-11-14T06:17:12.023+00:00”,“status”:405,“error”:“Method Not Allowed”,“message”:"",“path”:"/save"}]
请求类型不匹配,search接口修改为:
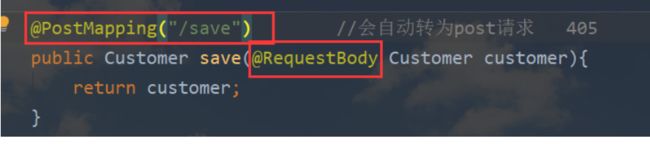
Callback机制
引言
使用Feign可以完成服务间调用,但是总存在一种情况:服务提供方没有注册到注册中心、服务提供方还没开发完成(因此也就无法调用)、服务内部错误等等。此时如果我们需要完成服务间调用该如何做呢?
Feign提供了fallback机制,也就是当对方服务存在问题,可以返回一些信息供服务进行下去,也就是服务降级。
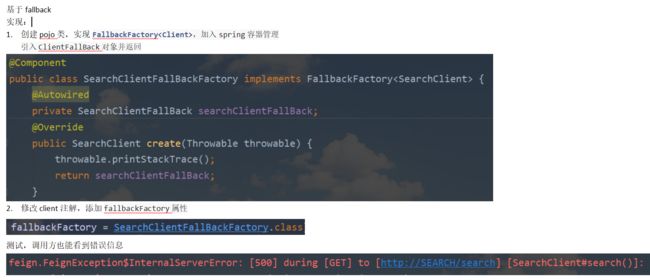
实现

Customer没有报错信息?使用FallbackFactory
7、服务隔离及断路器-hystrix
引言

降级机制实现:
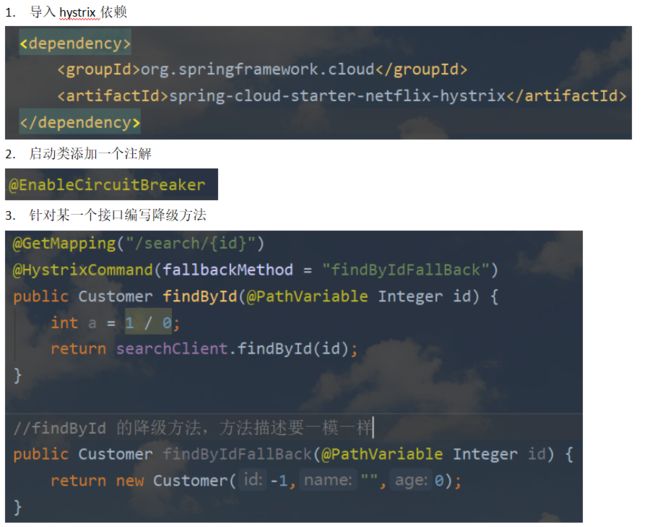

线程隔离



断路器原理
在调用指定服务时,如果失败率达到你输入的一个阈值,断路器会从closed状态转为open状态,此时指定服务是无法访问的,如果访问就直接走fallback方法。在一定时间内,open状态会再次转为half open状态,允许一个请求发送到指定服务,如果成功,断路器转为closed状态,如果失败,再次转为open状态,过一段时间再次转为half open,循环往复,直到最终回到closed状态。

8、新一代网关-Gateway
关于zuul和Gateway
spring-cloud-Gateway是spring-cloud的一个子项目。而zuul则是netflix公司的项目,只是spring将zuul集成在spring-cloud中使用而已。
因为zuul2.0连续跳票和zuul1的性能表现不是很理想,所以催生了spring团队开发了Gateway项目。
Zuul:
使用的是阻塞式的 API,不支持长连接,比如 websockets。
底层是servlet,Zuul处理的是http请求
没有提供异步支持,流控等均由hystrix支持。
依赖包spring-cloud-starter-netflix-zuul。
Gateway:
Spring Boot和Spring Webflux提供的Netty底层环境,不能和传统的Servlet容器一起使用,也不能打包成一个WAR包。
依赖spring-boot-starter-webflux和/ spring-cloud-starter-gateway
提供了异步支持,提供了抽象负载均衡,提供了抽象流控,并默认实现了RedisRateLimiter
Gateway基本介绍
Spring Cloud GateWay 是基于WebFlux框架 ,使用Reactor模式, 而WebFlux框架底层使用的Netty
GateWay作用
反向代理
鉴权
流量控制
熔断
日志监控
…
微服务网关所处的位置
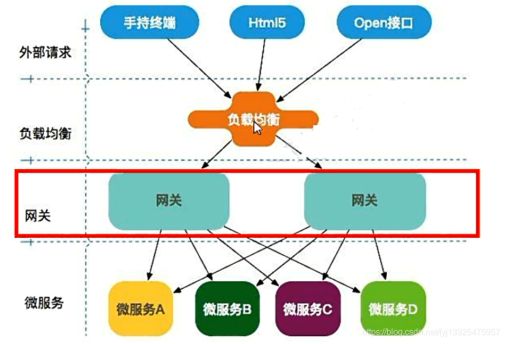
工作流程:


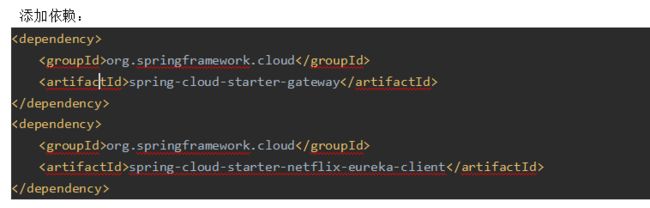
Gateway配置
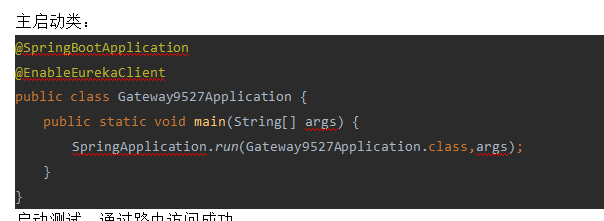
新建一个springboot模块:gateway-9527
动态路由
通过微服务名实现动态路由
默认情况下Gateway 会根据注册中心注册的服务列表,以注册中心上的微服务名为路径创建动态路由进行转发,从而实现动态路由功能(能负载均衡)
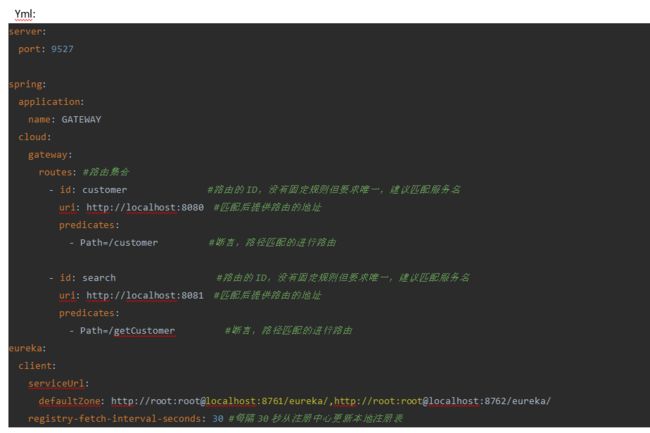
修改配置,只需要修改yml文件:
需要注意的是uri的协议为lb,表示启用Gateway的负载均衡功能。
lb://serviceName
gateway在微服务中自动为我们创建负载均衡uri
注意添加
discovery.locator.enabled=true表示开启从注册中心动态创建路由的功能,利用微服务名进行路由

断言-predicates
除了路径匹配,官网还提供了其他断言规则:

常用的 Route Predicate:

注意predicates: 下面可以配置多个断言规则

路由过滤器-filter
路由过滤器可用于修改进入的http请求和返回的http响应,路由过滤器只能指定路由进行使用
Spring cloud Gateway内置了多种路由过滤器,他们都由GatewayFilter的工厂类产生
路由过滤器只能在业务逻辑之前,和业务逻辑之后
单一过滤器配置:
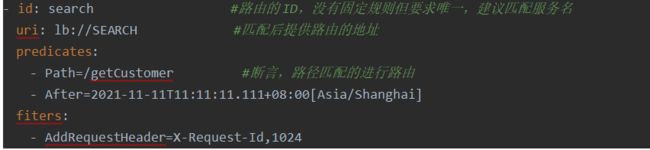
过滤器工厂会在匹配的请求头上加上一对值,键是:X-Request-Id,值是:1024
官网示例: