今年30找工作,还被问的IO序列化底层原理……
一、序列化定义
协议,一套标准,一套目的 要做的事情是数据传输!!!
本质上来讲:对象,其实可以转换成底层的一组字节数据010101.
序列化就是大家来定义一套 将我们的特殊数据(特定数据)转换成一组基本的二进制字节数据的实现.
反序列化就是将这组字节数据恢复成特定数据的实现
1.序列化本质上其实就是将数据结构或对象转换成二进制串的过程。
2.反序列化本质是将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
二、序列化的作用
三、优点
四、序列化协议特性
每种序列化协议都有优点和缺点,它们在设计之初有自己独特的应用场景。在系统设计的过程中,需要考虑序列化需求的方方面面,综合对比各种序列化协议的特性,最终给出一个折衷的方案。
通用性
通用性有两个层面的意义:
第一、技术层面,序列化协议是否支持跨平台、跨语言。如果不支持,在技术层面上的通用性就大大降低了。
第二、流行程度,序列化和反序列化需要多方参与,很少人使用的协议往往意味着昂贵的学习成本;
另一方面,流行度低的协议,往往缺乏稳定而成熟的跨语言、跨平台的公共包。
强健性/鲁棒性
以下两个方面的原因会导致协议不够强健:
第一、成熟度不够,一个协议从制定到实施,到最后成熟往往是一个漫长的阶段。协议的强健性依赖于大量而全面的测试,对于致力于提供高质量服务的系统,采用处于测试阶段的序列化协议会带来很高的风险。
第二、语言/平台的不公平性。为了支持跨语言、跨平台的功能,序列化协议的制定者需要做大量的工作;但是,当所支持的语言或者平台之间存在难以调和的特性的时候,协议制定者需要做一个艰难的决定--支持更多人使用的语言/平台,亦或支持更多的语言/平台而放弃某个特性。
当协议的制定者决定为某种语言或平台提供更多支持的时候,对于使用者而言,协议的强健性就被牺牲了。
可调试性/可读性
序列化和反序列化的数据正确性和业务正确性的调试往往需要很长的时间,良好的调试机制会大大提高开发效率。序列化后的二进制串往往不具备人眼可读性,为了验证序列化结果的正确性,写入方不得同时撰写反序列化程序,或提供一个查询平台–这比较费时;另一方面,如果读取方未能成功实现反序列化,这将给问题查找带来了很大的挑战–难以定位是由于自身的反序列化程序的bug所导致还是由于写入方序列化后的错误数据所导致。
对于跨公司间的调试,由于以下原因,问题会显得更严重:
第一、支持不到位,跨公司调试在问题出现后可能得不到及时的支持,这大大延长了调试周期。
第二、访问限制,调试阶段的查询平台未必对外公开,这增加了读取方的验证难度。
如果序列化后的数据人眼可读,这将大大提高调试效率, XML和JSON就具有人眼可读的优点。
五、序列化几种方式
3.1、Java 原生序列化:
Java 默认通过 Serializable 接口实现序列化,只要实现了该接口,该类就会自动实现序列化与反序列化,该接口没有任何方法,只起标识作用。Java序列化保留了对象类的元数据(如类、成员变量、继承类信息等),以及对象数据等,兼容性最好,但不支持跨语言,而且性能一般。
实现 Serializable 接口的类在每次运行时,编译器会根据类的内部实现,包括类名、接口名、方法和属性等自动生成一个 serialVersionUID,serialVersionUID 主要用于验证对象在反序列化过程中,序列化对象是否加载了与序列化兼容的类,如果是具有相同类名的不同版本号的类,在反序列化中是无法获取对象的,显式地定义 serialVersionUID 有两种用途:
- 在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的 serialVersionUID;
- 在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的 serialVersionUID;
如果源码改变,那么重新编译后的 serialVersionUID 可能会发生变化,因此建议一定要显示定义 serialVersionUID 的属性值。
3.2、Hessian 序列化:
Hessian 序列化是一种支持动态类型、跨语言、基于对象传输的网络协议。Java 对象序列化的二进制流可以被其他语言反序列化。 Hessian 协议具有如下特性:
- 自描述序列化类型。不依赖外部描述文件或接口定义, 用一个字节表示常用
- 基础类型,极大缩短二进制流
- 语言无关,支持脚本语言
- 协议简单,比 Java 原生序列化高效
Hessian 2.0 中序列化二进制流大小是 Java 序列化的 50%,序列化耗时是 Java 序列化的 30%,反序列化耗时是 Java 反序列化的20% 。
Hessian 会把复杂对象所有属性存储在一个 Map 中进行序列化。所以在父类、子类存在同名成员变量的情况下, Hessian 序列化时,先序列化子类 ,然后序列化父类,因此反序列化结果会导致子类同名成员变量被父类的值覆盖。
3.3、Json 序列化:
JSON 是一种轻量级的数据交换格式。JSON 序列化就是将数据对象转换为 JSON 字符串,在序列化过程中抛弃了类型信息,所以反序列化时需要提供类型信息才能准确地反序列化,相比前两种方式,JSON 可读性比较好,方便调试。 JSON 是一种轻量级的数据交换格式。JSON 序列化就是将数据对象转换为 JSON 字符串,在序列化过程中抛弃了类型信息,所以反序列化时需要提供类型信息才能准确地反序列化,相比前两种方式,JSON 可读性比较好,方便调试。
六、序列化与反序列化
我们知道,当两个进程进行远程通信时,可以相互发送各种类型的数据,包括文本、图片、音频、视频等, 而这些数据都会以二进制序列的形式在网络上传送。
那么当两个Java进程进行通信时,能否实现进程间的对象传送呢?答案是可以的!如何做到呢?这就需要Java序列化与反序列化了!
当我们明晰了为什么需要Java序列化和反序列化后,我们很自然地会想Java序列化的好处。其好处一是实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上(通常存放在文件里),二是,利用序列化实现远程通信,即在网络上传送对象的字节序列。
总的来说可以归结为以下几点:
(1)永久性保存对象,保存对象的字节序列到本地文件或者数据库中;
(2)通过序列化以字节流的形式使对象在网络中进行传递和接收;
(3)通过序列化在进程间传递对象;
3、序列化算法一般会按步骤做如下事情:
(1)将对象实例相关的类元数据输出。
(2)递归地输出类的超类描述直到不再有超类。
(3)类元数据完了以后,开始从最顶层的超类开始输出对象实例的实际数据值。
(4)从上至下递归输出实例的数据
原理:
为了更好地理解Java序列化与反序列化,举一个简单的示例如下:
序列化代码
// Employee.java
class Employee implements Serializable {
public String name;
public String address;
//该属性为不可序列化的,所以声明为短暂的
public transient int SSN;
public Number number;
}
// 测试类
public class DeserializeTest
{
public static void main(String[] args) {
Employee e = new Employee();
e.name = "MikeHuang";
e.address = "XXXXXXXXXXXX";
e.SSN = 12345678;
e.number = 110;
try
{
FileOutputStream fileOut =
new FileOutputStream("/tmp/employee.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
out.writeObject(e);
out.close();
fileOut.close();
System.out.printf("Serialized data is saved in /tmp/Employee.ser");
}catch(IOException i)
{
i.printStackTrace();
}
}
}
上面测试代码执行后会在/tmp目录下多出一个employee.ser文件,我于是好奇打开了这文件,看里面都是什么内容。里面还是能够看出一些信息的比如说类名、可序列化的属性名、可序列化属性的值与类型。你可以自行打开查看。
那么通过上面的代码我们总结一下,如何实现对象序列化:
a.必须实现 java.io.Serializable,所有属性必须是可序列化的,属性不是可序列化的,则该属性必须注明是短暂的
b.通过ObjectOutputStream对象的writeObject方法将对象转换为字节序列。writeObject的源码,会在5.源码上贴出。
反序列化代码
public static void main(String[] args) {
Employee e = null;
try
{
FileInputStream fileIn = new FileInputStream("/tmp/employee.ser");
ObjectInputStream in = new ObjectInputStream(fileIn);
e = (Employee) in.readObject();
in.close();
fileIn.close();
}catch(IOException i)
{
i.printStackTrace();
return;
}catch(ClassNotFoundException c)
{
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
System.out.println("Deserialized Employee...");
System.out.println("Name: " + e.name);
System.out.println("Address: " + e.address);
System.out.println("SSN: " + e.SSN);
System.out.println("Number: " + e.number);
}
通过上面的代码,执行后SSN的值输出为0,这是因为该属性声明为暂时的,所以它是不可序列化的属性,也就没有保存在employee.ser中,你可以通过打开搜索SSN关键字来确认。在反序列化时,该属性的值110也就没有,而是0.通过上面的代码我们可以知道
要将字节序列转化为对象,需要使用ObjectInputStream的readObject方法,具体readObject源码我们会在5处进行贴出来。
序列化图示:

反序列化图示:
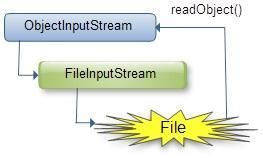
七、序列化与反序列化底层是如何实现的?
这一节,我们带着问题去一个一个的解开谜团,看到代码的最终本质,从而加深我们队序列化反序列化的理解。
a.为什么一定要实现这个java.io.Serializable才能序列化?
我们可以通过去除Employee的Serializable实现,你会发现执行报异常,
异常如下:
登录后复制
java.io.NotSerializableException: Employee
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1180)
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:346)
at DeserializeDemo.saveSer(DeserializeDemo.java:25)
at DeserializeDemo.main(DeserializeDemo.java:64)
那么我们就去看下writeObject0中的代码片段如下:
// remaining cases
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
会判断要被序列化的类是否是String、Enum、Array和Serializable类型,如果不是则直接抛出NotSerializableException。
b.String、Enum、Array都实现了Serializable为啥要单独拿出来进行序列化呢?
其实这个也很简单,因为ObjectOutPutStream给String、Enum、Array对象数据结构已经做了特殊的序列化的方法,
而除了上述三个外,唯一能够实现的就是通过实现Serializable来达到序列化。
c.Serializable这个东西一定要,那必须了解一下,这里面到底是个啥样的?
/**
* 说明文字已经去掉了,如果要看可以自行查看源码,
* 其实这里的说明也说明了如何实现序列化。
* @author unascribed
* @see java.io.ObjectOutputStream
* @see java.io.ObjectInputStream
* @see java.io.ObjectOutput
* @see java.io.ObjectInput
* @see java.io.Externalizable
* @since JDK1.1
*/
public interface Serializable {
}
这只是一个空接口,实现这个接口只是为了标识为可序列化,所有实现了这个接口的对象,都会有一个serialVersionUID,这个东西使用与确定序列化与反序列化是否匹配的一个标识。具体的说明在 Serializable接口
中有说明,我把这部分贴出来如下,如果需查看全部,请进入源码自行查看:
/**
* This readResolve method follows the same invocation rules and
* accessibility rules as writeReplace.
*
* The serialization runtime associates with each serializable class a version
* number, called a serialVersionUID, which is used during deserialization to
* verify that the sender and receiver of a serialized object have loaded
* classes for that object that are compatible with respect to serialization.
* If the receiver has loaded a class for the object that has a different
* serialVersionUID than that of the corresponding sender's class, then
* deserialization will result in an {@link InvalidClassException}. A
* serializable class can declare its own serialVersionUID explicitly by
* declaring a field named "serialVersionUID" that must be static,
* final, and of type long:
*
*
* ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L;
*
*
* If a serializable class does not explicitly declare a serialVersionUID, then
* the serialization runtime will calculate a default serialVersionUID value
* for that class based on various aspects of the class, as described in the
* Java(TM) Object Serialization Specification. However, it is strongly
* recommended that all serializable classes explicitly declare
* serialVersionUID values, since the default serialVersionUID computation is
* highly sensitive to class details that may vary depending on compiler
* implementations, and can thus result in unexpected
* InvalidClassExceptions during deserialization. Therefore, to
* guarantee a consistent serialVersionUID value across different java compiler
* implementations, a serializable class must declare an explicit
* serialVersionUID value. It is also strongly advised that explicit
* serialVersionUID declarations use the private modifier where
* possible, since such declarations apply only to the immediately declaring
* class--serialVersionUID fields are not useful as inherited members. Array
* classes cannot declare an explicit serialVersionUID, so they always have
* the default computed value, but the requirement for matching
* serialVersionUID values is waived for array classes.
* */
举例:String
private static final long serialVersionUID = -6849794470754667710L;
d.Employee类中没有书写,那么它是什么时候加上版本号的呢?
当实现java.io.Serializable接口的类没有显式地定义一个serialVersionUID变量时候,Java序列化机制会根据编译的Class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果Class文件(类名,方法明等)没有发生变化(增加空格,换行,增加注释等等),就算再编译多次,serialVersionUID也不会变化的。如果不显示的去写版本号,那么就可能造成反序列化时,因为类改变了(怎加了方法,修改了方法名等)而生成了不一样的版本号,那么原先序列化的字节序列将无法转成该版本的对象,因为版本不一致嘛。所以一定要显示的去设置版本号。
e.如果定制序列化策略,该如何实现呢?
回答这个问题前,我们先来看下数组(ArrayList)这个类。
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer.
*/
private transient Object[] elementData;
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
}
private transient Object[] elementData;说明这个数据是临时数据,不能序列化的,但实际上操作,我们却能够序列化。这是为什么?
在序列化过程中,如果被序列化的类中定义了writeObject 和 readObject 方法,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化。
如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。
用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。
八、总结
一个对象的 序列化顺序,是按照如下步骤:
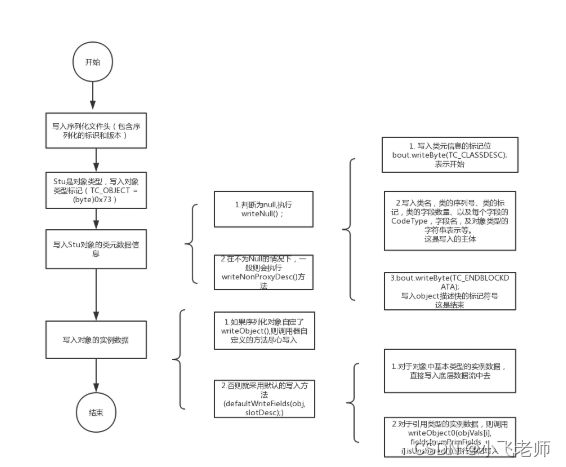
其实这还不算序列化的 全部实现原理,因为在我们学习序列化流的过程中,transient关键字 和 静态成员属性 是无法被序列化的。android核心进阶知识点~获
因此,整个Java体系的 序列化流程,还是非常庞大的,本篇博文仅 介绍其 核心功能 的 实现原理